大家好,又见面了,我是你们的朋友全栈君。
一 真实系统中的概念
| JVM(Java Virtual Machine),顾名思义是对真实计算机系统的模拟,正因如此才能屏蔽物理机器的变化,从而实现“一次编译,到处运行”。
相信很多Java程序员经常听到堆、栈等概念,也会进行设置调优以让Java应用能够更好地运行,但对于JVM与真实计算机系统之间的关系并没有特别清晰的认识。因此,这里先简单介绍下真实计算机系统中的一些概念。 现代计算机系统中,也有寄存器、栈、堆等概念,这些与JVM中的概念相似,但有本质的不同。 现代计算机系统中,内存是由操作系统配合CPU的段寄存器来管理的,主要分为内核空间(内核代码段,内核数据区)、代码段(.text)、数据段(.data 和 .bss)、栈、堆、共享内存区等。 JVM作为进程运行在操作系统之上,那么操作系统也需要为JVM分配栈空间。 所以,JVM中的堆并非操作系统管理的堆,JVM的栈也不是操作系统管理的栈。 聊了聊真实计算机系统,再接着谈谈JVM。 | 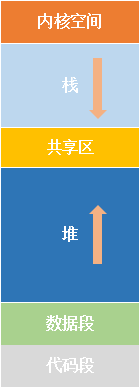  |
二 JVM运行时数据区
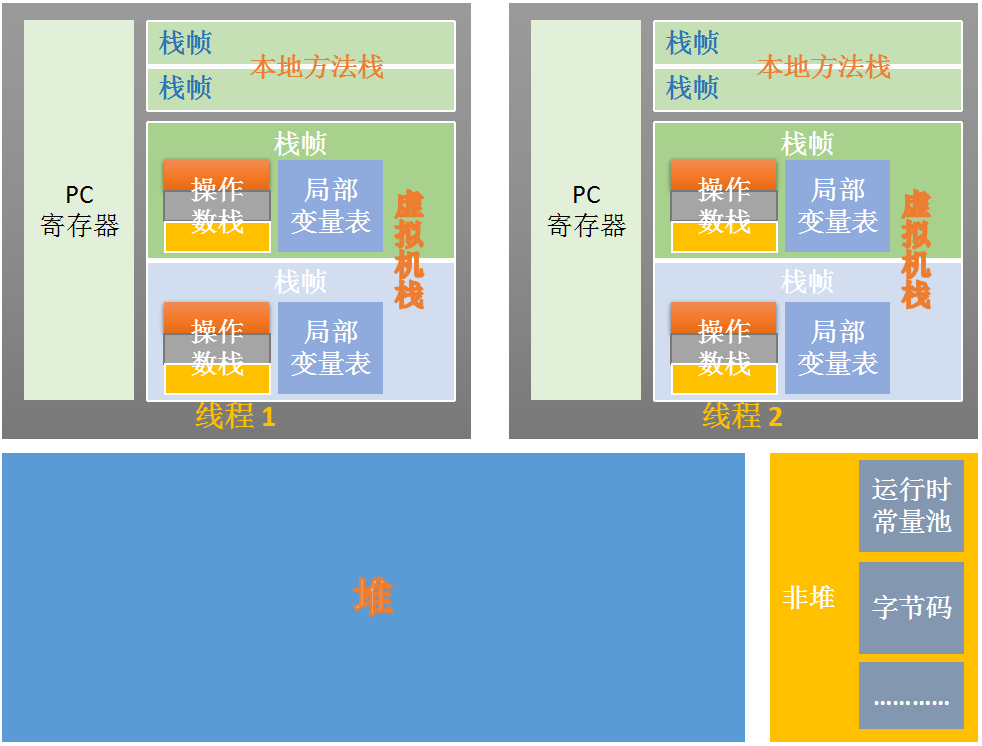 |
㈠ PC寄存器(Program counter register)
PC寄存器又称作程序计数器,其作用类似于cpu中的代码段寄存器:指针寄存器(汇编中CS:EIP总是指向下一条要运行的指令地址)。
线程中正在运行的方法被称为当前方法(current method)。如果当前方法是非native的,PC寄存器保存的是当前方法的字节码指令的地址;否则,值为undefined。
㈢ 堆(Heap)
⑴ 系统堆 与Java堆
这里的堆指的是Java堆,与操作系统管理的堆是两个不同的概念,但作用类似。
C语言中,可以使用malloc()向操作系统申请堆内存,使用完毕后一般需要显式调用free()来释放内存,如果未释放则可能导致内存耗尽。同时,这种内存申请、释放的方式容易产生内存碎片(C/C++程序员有些会使用第三方库来管理内存,有些则自己实现内存池来管理内存)。
但在Java中,这些由JVM来处理,因此避免了复杂繁琐的内存管理。
JVM运行过程中,可以动态地向操作系统申请内存作为Java堆或归还未使用的内存,堆内存可以是非连续的内存空间。当触发预设条件时,JVM会调用垃圾收集器来回收未被使用的对象。
Java堆是垃圾收集器最重要的工作区域,另一个区域是非堆(永久代)。
以下内容中,除非特别说明,堆均指的就是JVM堆。
⑵ 内存分配与垃圾回收
堆保存类实例对象和数组对象,堆是共享数据区,各线程均可使用此区域。
堆内存空间分配和垃圾收集机制会因垃圾收集器不同而不同,这里以Parallel new + CMS垃圾收集器为例。
堆分为新生代(young generation)和老年代(old generation);新生代又可分为Eden, From Survivor, To Survivor。
当Eden空间足够时,大部分新创建对象会被分配在Eden区(部分大对象会被直接分配到老年代)。
当Eden空间不足时,会发生一次Minor GC,未被引用的对象会被回收,Eden中仍然存活的对象会被移动到From Survivor。
Survivor中的对象每熬过1次MinorGC增加1岁,默认超过15岁依然存活的对象会被移入Tenured。
当发生Minor GC时:如果Survivor的空间不足以保存Eden区仍然存活的对象,那么该对象会被直接移入 Tenured;如果Survivor 中同年对象的占用空间的总和达到或超过其中一个Survivor的一半,那么所有同年对象都会被移入Tenured。
通常情况下,只有其中一个Survivor持有对象,另一个在下次GC之前总是为空。当再次发生GC时,Eden中的对象被复制到标记为To的空的Surivivor中,原来From中依然存活的未到达年龄的对象也会复制到To,此时To被标记为From,原来的From置空并被标记为To,轮换是为了避免Surivivor中因没有连续空间而导致对象被直接移入老年代。
当Tenured空间使用达到一定比例时会触发Full GC,并且可能伴随着进行Minor GC。
除了CMS和新的G1垃圾收集器以外,其它的垃圾收集器都会触发Stop The World,所有其它线程暂停。

⑶ 线程本地分配缓冲区(Thread-Local Allocation Buffer, TLAB)
为保证线程安全和避免内存争用,JVM会为每一个线程在Eden中设置一小块私有的缓冲区,称为TLAB。每一个TLAB都只有一个线程可以分配对象,因此可以避免采用全局锁来控制内存分配,而只需要在最后一个分配对象的末端顺序写入即可(指针碰撞),可以快速分配内存。
当一个线程的TLAB的空间不足需扩充内存时,那么就需要多线程方式来保证不会出现数据覆写。
⑷ 注意事项
1.为了减少短期存活的大对象进入老年代,应尽可能缩短其生命周期,一种比较好的方式是在最后使用的地方手动置为null。
幸运的话它会在Eden区被回收,即使进入Survivor也很难熬过15次Minor GC。
2. 数据库查询只获取必要数据,而不是全表查询。
3. 严格限定对象作用域,避免作用域溢出,导致对象总是被引用而无法回收。
4. 多用单例,少用new。
㈣ 非堆(Non-Heap Memory)
非堆也称作永久代(permanent generation),逻辑上属于堆的一部分,但老年代的对象并不会移入永久代。
永久代只用于存储元数据(Metadata),譬如类的数据结构、字符串常量池等数据。
运行时常量池与字符串常量池是完全不同的概念,运行时常量池归属于具体的类,是类数据结构的一部分,是私有的;而字符串常量池保存的是字符串对象的引用,字符串对象本身保存在堆中,是共享的。
永久代也会发生GC,但此区域通常回收效率不高。
㈤ Java虚拟机栈(Java Virtual Machine Stack)
Java虚拟机栈是每一个线程私有的,随线程开始而创建,随线程结束而销毁。
⑴ 栈帧(Frams)
线程在执行每个方法时都会创建一个栈帧,栈帧随方法调用而创建,随方法结束而销毁,无论方法是否正常结束。
栈帧中保存局部变量表、操作数栈和一个指向当前方法所属类的运行时常量池的引用。栈帧同样是线程私有的,一个线程不能访问另一个线程的栈帧。
⑵ 局部变量表(Local Variables)
局部变量表保存的是方法运行期间所需要的数据。数据类型可以分为基本数据类型、对象引用类型和returnAddress类型。long和double会占用两个局部变量空间(slot),其余的数据类型占用一个,局部变量表所需的内存空间在编译期间确定,方法执行期间不会改变。
⑶ 操作数栈(Operand Stack)
操作数栈的长度由编译期间确定,操作数栈初始时为空,每一个操作数栈的成员(Entry)可以保存JVM定义的任意数据类型的值。long和double占用2个栈深单位,其它数据类型占用一个栈深单位。
㈥ 本地方法栈(Native Method Stack)
本地方法栈保存的是native方法的信息,当一个JVM创建的线程调用native方法后,JVM不再为其在虚拟机栈中创建栈帧,JVM只是简单地动态链接并直接调用native方法。
关于本地方法栈的信息内容非常少,HotSpot的说明书也没有找到相关信息,为避免误导,这里就先略过吧。
三 代码说明
这些概念都比较抽象,举个例子说明更直观明了。
㈠ 示例代码
public class HelloWorld {
public static final int a = 10; //声明全局变量a并赋值
public static void main(String[] args){
HelloWorld hw = new HelloWorld(); //实例化对象hw
int b = 15; //声明局部变量b并赋值
int c = hw.add(b); //调用add方法并赋值给c
}
public int add(int b){
b = change(b); //调用change方法并赋值给b
return a + b + 3; //返回计算结果
}
public int change(int b){
return b + 5; //返回计算结果
}
}
㈡ 字节码
/**
* JVM启动时会将类信息保存到永久代(方法区)
*/
public class HelloWorld
minor version: 0 //编译副版本号
major version: 52 //编译主版本号,JVM校验class文件时使用,低版本JVM不能运行高版本编译器编译的class文件
flags: ACC_PUBLIC, ACC_SUPER //ACC_PUBLIC表示可以被包外class访问,ACC_SUPER表示需特殊处理的父类方法
/**
* 常量池:类似于《编译原理》中介绍的符号表;如希望进一步了解,请阅读附录书单的⑴⑵⑶
*/
Constant pool:
#1 = Methodref #6.#22 // java/lang/Object."<init>":()V
#2 = Class #23 // HelloWorld
#3 = Methodref #2.#22 // HelloWorld."<init>":()V
#4 = Methodref #2.#24 // HelloWorld.add:(I)I
#5 = Methodref #2.#25 // HelloWorld.change:(I)I
#6 = Class #26 // java/lang/Object
#7 = Utf8 a
#8 = Utf8 I
#9 = Utf8 ConstantValue
#10 = Integer 10
#11 = Utf8 <init>
#12 = Utf8 ()V
#13 = Utf8 Code
#14 = Utf8 LineNumberTable
#15 = Utf8 main
#16 = Utf8 ([Ljava/lang/String;)V
#17 = Utf8 add
#18 = Utf8 (I)I
#19 = Utf8 change
#20 = Utf8 SourceFile
#21 = Utf8 HelloWorld.java
#22 = NameAndType #11:#12 // "<init>":()V
#23 = Utf8 HelloWorld
#24 = NameAndType #17:#18 // add:(I)I
#25 = NameAndType #19:#18 // change:(I)I
#26 = Utf8 java/lang/Object
{
/** 静态final变量 a */
public static final int a;
descriptor: I //字段类型描述符,表明是一个int整形数
flags: ACC_PUBLIC, ACC_STATIC, ACC_FINAL //字段属性描述符
ConstantValue: int 10 //常量值
/** 构造方法 */
public HelloWorld();
descriptor: ()V //方法描述符,V表明返回值为空
flags: ACC_PUBLIC //方法属性标签
Code:
stack=1, locals=1, args_size=1 // 操作数栈深=1,本地变量数量=1,参数数量=1,0索引总是保存当前方法所属的对象引用(ObjectReference),所以无参构造方法却显示有1个参数
0: aload_0 // 从局部变量表索引为0的地方获取对象引用类型,并压入到操作数栈,新建但未初始化
1: invokespecial #1 // Method java/lang/Object."<init>":()V 调用父类的初始化方法
4: return // 方法返回,返回值为空,栈帧销毁
LineNumberTable: // LineNumberTable是一个数组,记录源代码所在的行。
line 1: 0 // line_number(源文件行号) : start_pc(code[]数组索引)
/** main方法 */
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1 // 操作数栈深=2,本地变量数量=4,参数数量=1
0: new #2 // class HelloWorld 创建HelloWorld对象,堆中分配内存,引用值压入栈顶
3: dup // 复制栈顶保存的对象引用,并将HelloWorld引用值再次压入栈顶
4: invokespecial #3 // Method "<init>":()V 弹出栈顶的一个元素HelloWorld引用,调用HelloWorld对象的初始化方法
7: astore_1 // 弹出栈顶的一个元素HelloWorld引用,将栈顶的HelloWorld引用存入局部变量表的索引1位置
8: bipush 15 // 将byte类型常数15压入栈顶
10: istore_2 // 弹出栈顶的一个元素15,并将其存入局部变量表索引2位置
11: aload_1 // 将局部变量表的索引1位置的HelloWorld引用压入栈顶
12: iload_2 // 将局部变量表的索引2位置的int类型的15压入栈顶
13: invokevirtual #4 // Method add:(I)I 弹出栈顶的两个元素并调用add方法,返回值33压入栈顶
16: istore_3 // 弹出栈顶的一个元素33,并将其存入局部变量表索引3位置
17: return // 方法返回,返回值为空,栈帧销毁,线程结束
LineNumberTable:
line 5: 0
line 6: 8
line 7: 11
line 8: 17
/** add方法 */
public int add(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=2 // 操作数栈深=2,本地变量数量=2,参数数量=2(非静态方法的参数0位置总是为当前方法所属对象的引用,所以只传入了参数b,却显示有2个参数)
0: aload_0 // 将局部变量表的索引0位置的HelloWorld引用压入栈顶
1: iload_1 // 将局部变量表的索引1位置(参数b)的15压入栈顶
2: invokevirtual #5 // Method change:(I)I 弹出栈顶的两个元素并调用change方法,返回值20压入栈顶
5: istore_1 // 弹出栈顶元素20,并将其存入局部变量表的索引1位置
6: bipush 10 // 将byte类型常数10压入栈顶
8: iload_1 // 将局部变量表的索引1位置的20压入栈顶
9: iadd // 弹出栈顶的两个元素并相加:20 + 10,将结果30存入栈顶
10: iconst_3 // 将int类型常数3压入栈顶
11: iadd // 弹出栈顶的两个元素并相加:30 + 3,将结果33存入栈顶
12: ireturn // 返回int类型的数值 33,栈帧销毁
LineNumberTable:
line 11: 0
line 12: 6
/** change方法 */
public int change(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=2
0: iload_1 // 将局部变量表的索引1位置的15压入栈顶
1: iconst_5 // 将int类型常数5压入栈顶
2: iadd // 将栈顶的两个元素弹出并相加:5 + 15,并将结果存入栈顶
3: ireturn // 返回int类型的数值 20,栈帧销毁
LineNumberTable:
line 16: 0
}
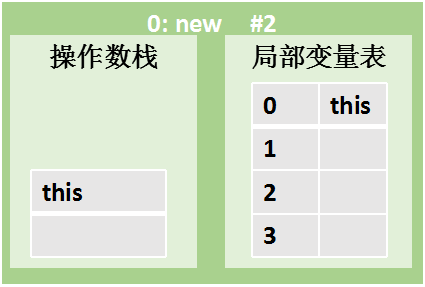
㈢ 构造方法图解
 |
1.操作数栈初始为空,执行0:aload_0指令,局部变量表的当前方法所属对象的引用(this) 复制到操作数栈的栈顶。实例对象保存在java堆,方法引用指向非堆方法区。
2.执行1:invokespecial #1指令,调用父类的初始化方法。父类初始化方法会在当前栈帧上添加一层新的栈帧。父类初始化方法执行完毕后,其对应栈帧销毁。
3.执行4:return指令返回,当前对象实例化完成,当前栈帧销毁。
㈣ main方法图解
为更清楚地看到操作数栈、局部变量表及栈帧的变化,以main方法为例进行描述。
| 栈帧内容变化 |
栈帧创建销毁变化 |
描述 |
 |
 |
创建main方法栈帧
指令 0:new #2 |
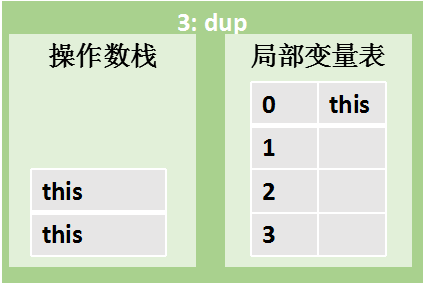 | | 指令 3:dup
复制栈顶的当前对象引用(this),并将其再次压入栈顶 |
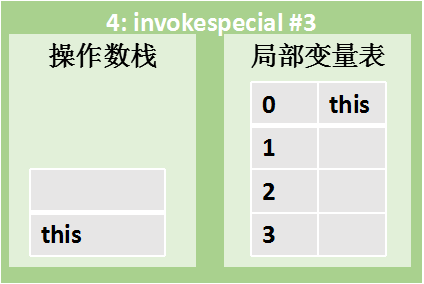 |  | 指令 4:invokespecial #3
弹出栈顶的一个元素this作为参数并调用HelloWorld.init方法,创建一层HelloWorld.init方法的栈帧 |
 | HelloWorld.init方法执行期间: HelloWorld.init方法中再调用Object.init方法,创建一层Object.init方法的栈帧 (见上一小节的构造方法图解) | |
| HelloWorld.init方法执行期间: Object.init方法执行完毕,其对应的栈帧销毁。 | |
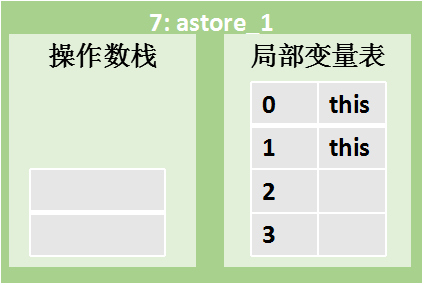 | | HelloWorld.init方法执行完毕,其对应栈帧销毁。
指令 7:astore_1 |
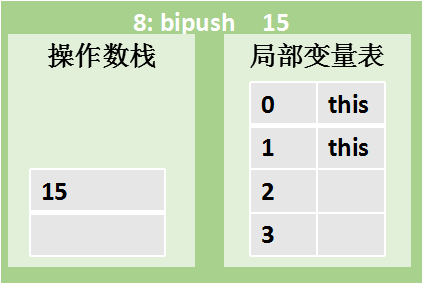 | | 指令 8:bipush 15 将byte类型常数15压入栈顶 |
 | | 指令 10:istore_2 将栈顶的int类型常数 15保存到局部变量表索引2位置 |
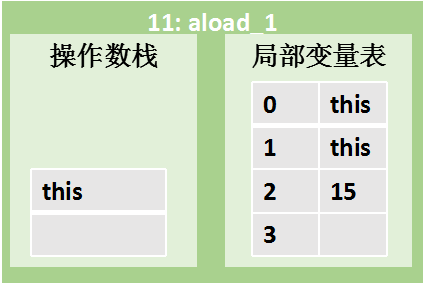 | | 指令 11:aload_1 将局部变量表的索引1位置的HelloWorld引用压入栈顶 |
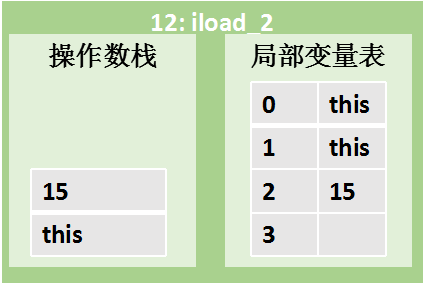 | | 指令 12: iload_2 将局部变量表的索引2位置的int类型的15压入栈顶 |
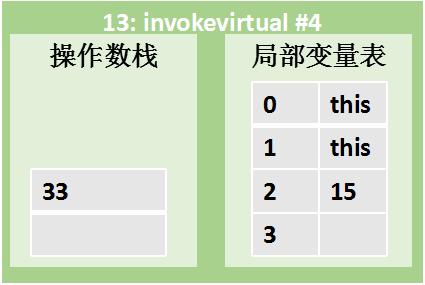 |  | 指令 13:invokevirtual #4 弹出栈顶的两个元素作为参数并调用add方法,,创建一层Object.init方法的栈帧 add方法执行完毕后返回值33压入栈顶 |
 | add方法执行期间: add方法调用change方法,创建一层change方法栈帧 | |
| add方法执行期间: change方法执行完毕,其对应的栈帧销毁 | |
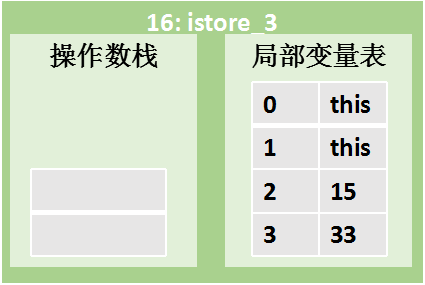 | | add方法执行完毕,其对应的栈帧销毁
指令 16:istore_3 |
| 指令 17:return main方法执行完毕,栈帧销毁,线程结束 |
四 数据类型占用空间分析
操作数栈:long和double需要占用2个栈深单位(unit of depth),其它类型占用1个栈深单位。
局部变量表:long和double需要占用2个局部变量空间(slot),其它类型占用1个局部变量空间。
运行时常量池:byte、short和int被存储为CONSTANT_Integer_info 结构;float被存储为CONSTANT_Float_info 结构;long被存储为CONSTANT_Long_info 结构;double被存储为 CONSTANT_Double_info 结构。其中,long 和 double占用8个字节,byte、short、int和float占用4个字节。
虽然运行时常量池中占用空间并没有进一步细分,但保存的数据结构中会标记数据类型,byte被标记为B,int 被标记为I……
Java堆:虽然《Java虚拟机规范》中并没有明确说明基本数据类型的空间占用,但根据我对JIT编译生成的汇编代码分析,byte占用一个字节,short占用2个字节,float和int占用4个字节,long 和 double占用8个字节。
测试方法:声明byte[],顺序写入索引0、索引1、索引2、索引3的元素。运行时开启JIT编译,查看得到的汇编代码中你会发现内存地址变化正如上面所说。
示例Java代码:
byte[] array = new byte[4];
array[0] = 0;
array[1] = 1;
array[2] = 2;
array[3] = 3;</span>
关键汇编代码:
0xa726a086: jne 0xa726a07d ;*newarray检测zf标志位:1顺序执行下一条指令;0跳转到0xa726a07d处指令
;eax寄存器中保存的是数组的起始内存地址。0xc(%eax):基址eax + 偏移12。
;32位JVM中,数组对象使用12个字节记录两项信息:数组长度4字节 + 数组对象头8字节 = 12字节(0x0 至 0xb),所以保存数据的起始地址是0xc。
0xa726a088: movb $0x0,0xc(%eax) ;*bastore将0写入0xc偏移位置
0xa726a08c: movb $0x1,0xd(%eax) ;*bastore将1写入0xd偏移位置
0xa726a090: movb $0x2,0xe(%eax) ;*bastore将2写入0xd偏移位置
0xa726a094: movb $0x3,0xf(%eax) ;*bastore将3写入0xd偏移位置
五 递归优化
㈠ 栈溢出
根据第三节图例,JVM每执行每一个方法都会创建一层新的栈帧,当方法结束,那么栈帧就会销毁。
方法1调用方法2,方法2调用方法3……方法i-1调用方法i,因为每一个方法都没结束,那么最后会创建i层栈帧。
JVM中的虚拟机栈的空间大小可以通过参数配置,但如果方法嵌套调用链过长导致栈空间耗尽,那么就会发生栈溢出(StackOverflowError)。
㈡ 递归注意事项
正常程序一般不会导致栈溢出,但递归方法需要特别注意。
因为递归方法本身既是调用者又是被调用者,每一次方法执行时被调用者又会成为调用者而没有结束,所以栈帧不会被销毁,而是会一层一层累加。
虽然如此,很多时候依然会倾向于使用递归,但使用递归方法应注意以下几点:
1、一定要设定退出条件(无需递归即可直接求解的基准情况)。
2、避免在递归中反复求解。
3、避免在递归方法中嵌套递归方法。
4、避免在递归中创建大对象。
㈢ 错误示例及优化
错误示例1(无退出条件):
public static void getAndSet(){
Object obj = get();
set(obj);
getAndSet();
}
正确方式:
public static void getAndSet(){
Object obj = get();
if(null != obj){
set(obj);
getAndSet();
}
}
如果实在没办法判断退出条件,可以这样:
public static void getAndSet(){
for( ; ; ){
Object obj = get();
set(obj);
}
}
错误示例2(反复求解):
/**计算斐波那契数列
* 0,1,1,2,3,5,8,13
* 为了计算第7个数,必须先计算第6个;为了计算第6个,先得计算第5个……因为每一步计算的结果都没有存储,所以相同的计算结果反复计算。
* 每一次方法调用都是两个f(n)的计算,所以第3个数开始,每次的计算都是前面两个数的计算次数之和。这是一个非常非常非常缓慢的算法!!!
* 相当于每增加1,计算次数就要乘以1.618。
* 当计算第30个数字的值时,方法调用达到1664079次,栈帧数量等同。
*/
public static int f(int n){
if(n == 0){
return 0;
}
if(n <= 2){
return 1;
}
return f(n-1) + f(n-2);
}
正确方式:
public static int f(int n){
int lastlast = 0;
int last = 1;
int sum = 1;
for(int i=2; i<=n; i++){
sum = last + lastlast;
lastlast = last;
last = sum;
}
return sum;
}
错误示例3(递归中嵌套递归):
public static void getAndSet(){
Object obj = get();
if(null != obj){
set(obj);
getAndSet();
}
}
public static void set(Object obj){
obj.value = 10;
obj = obj.next;
if(null != obj){
set(obj);
}
}
正确方式:
public static void getAndSet(){
Object obj = get();
while(null != obj){
set(obj);
obj = get();
}
}
public static void set(Object obj){
while(null != obj){
obj.value = 10;
obj = obj.next;
}
}
错误方式4(递归方法中创建大数据对象):
public static void build(){
int[] array = new int[1024 * 1024 * 1024];
build();
}
㈣ 总结
从以上示例可知,简单的尾递归都可以转化成循环。
从汇编语言的角度来看,比较、赋值和跳转构成了所有的语法结构,并没有递归,也没有循环。因此其实所有的递归,无论多复杂都可以转化成循环语句。
大部分情况下,递归并不需要转化成循环。譬如树搜索等使用递归会使得程序结构简单明了,且因其特殊的数据结构也使得递归层次并不会太深。
现代JVM会对大部分的尾递归方法进行优化,也就是转化成循环结构。但JVM并不保证对所有的尾递归都会进行转换。因此当存在递归深度过深的风险、递归方法中包含大对象等可能导致栈溢出的情况,手动转化成循环结构应该是更好的选择。
六 后记
JVM的知识结构体系庞大而复杂,牵涉到很多其它学科的知识,譬如计算机体系结构、操作系统、编译原理、离散数学、汇编语言、C、C++……
而且JVM中的每一个知识点几乎都可以写几本厚厚的书,譬如垃圾回收算法、性能调优……
本文目的只是让java coder对JVM有一个直观的认识,因此尽量用简单明了的语言和图例来描述比较抽象的概念,如果能帮助大伙在进一步学习时建立一点基本常识则非常欢喜了。
另,如有错误之处欢迎指正。谢谢!
七 参考资料
这也是我的推荐书单。
⑴是我买的关于JVM的第一本书,也是我后来最常翻阅的一本书,强烈推荐。周志明大大既是⑴的作者,也是⑵的译者之一。⑵的翻译非常流畅准确,是我阅读过的翻译得最好的资料之一。
⑷是计算机体系结构、操作系统和编译原理的综合书籍,对于希望进一步理解计算机科学底层原理的读者来说是一本非常好的教材。
⑸是操作系统方面的书,对进程、线程、cpu、内存、文件系统……等等都有很好的介绍。
递归优化主要参考⑻,这也是学习数据结构和算法的很好的书籍,某些部分比《算法导论》讲得更深入,学完这个再看《算法导论》几乎无压力。
⑺介绍了JVM性能调优的大量方法、系统监控和JVM监控的大量工具,并且有很多测试和优化场景案例,推荐阅读。
⑴ 《深入理解Java虚拟机:JVM高级特性与最佳实践 第2版》 作者:周志明
⑵ 《Java虚拟机规范:Java SE 7 Edition》 作者:Tim Lindholm、Frank Yellin、Gilad Bracha、Alex Buckley 译者:周志明、吴璞渊、冶秀刚
⑶ 《The Java® Virtual Machine Specification :Java SE 8 Edition》 作者:Tim Lindholm、Frank Yellin、Gilad Bracha、Alex Buckley
⑷ 《深入理解计算机系统 第2版》 作者:Randal E.Bryant、David R.O’Hallaron
⑸ 《操作系统概念 第7版》 作者:Abraham Silberschatz、Peter Baer Galvin、Greg Gagne
⑹ 《Garbage Collection in the Java HotSpot Virtual Machine》 作者:Tony Printezis
⑺ 《Java 性能优化权威指南》 作者:charlie Hunt、Binu John
⑻ 《数据结构与算法分析.Java语言描述》 作者:Mark Allen Weiss
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136161.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
