大家好,又见面了,我是你们的朋友全栈君。
1.简单爬取百度网页内容:
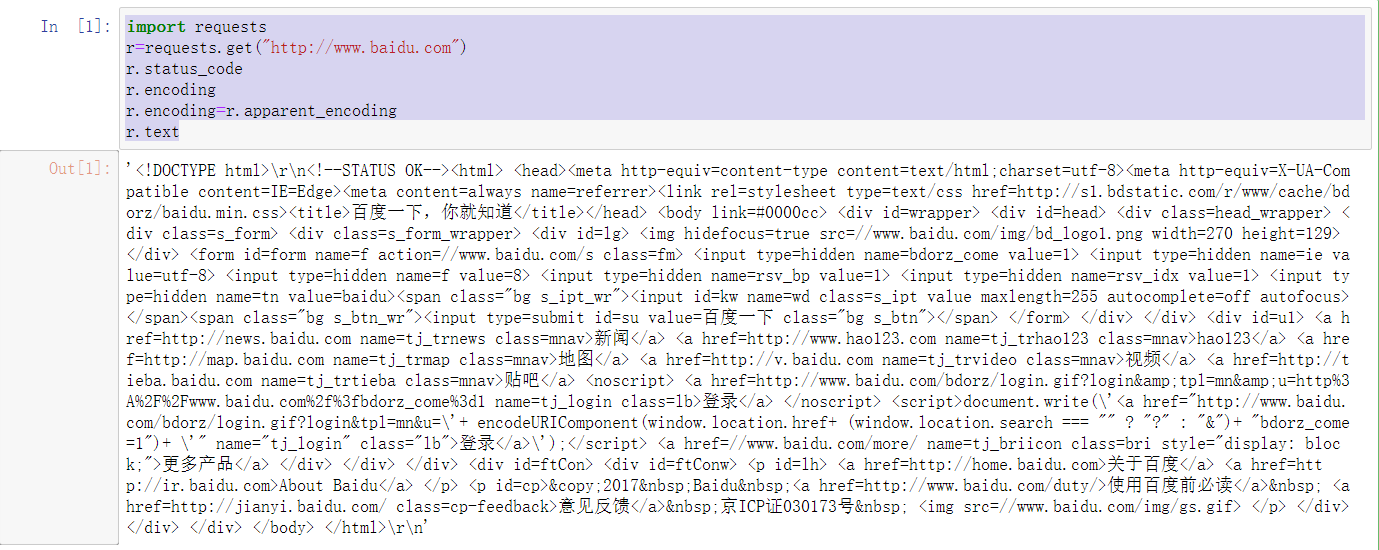
爬取百度网页源代码:
import requests
r=requests.get("http://www.baidu.com")
r.status_code
r.encoding
r.encoding=r.apparent_encoding
r.text
结果展示:

2.爬取网页的通用代码框架:(这里继续选用百度网页)
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ =="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
爬取结果展示

3.京东商品页面爬取
京东商品页面爬取
import requests
url="http://item.jd.com/2967929.html"
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
爬取结果展示:

4.亚马逊商品页面的爬取
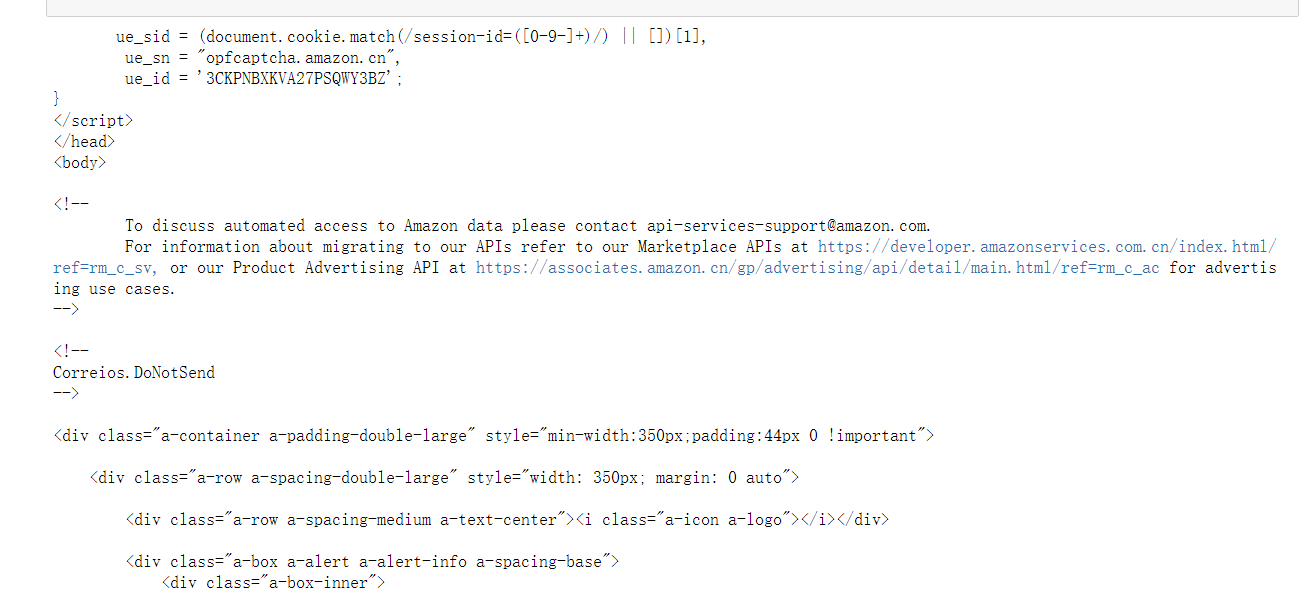
亚马逊商品爬取源代码
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={
'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
结果展示:
5.百度搜索全代码
百度搜索全代码
import requests
keyword="Python"
try:
kv={
'wd':'keyword'}
r=requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败!")
结果展示:

6.360搜索全代码
360搜素全代码
import requests
keyword="Python"
try:
kv={
'q':keyword}
r=requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
结果展示:

7. 图片爬取全代码:
爬取高清图片源代码
import requests
import os
url="http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
root="D://pics//"
path=root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件爬取失败")
except:
print("爬取失败")
8.用requests库获取源代码:
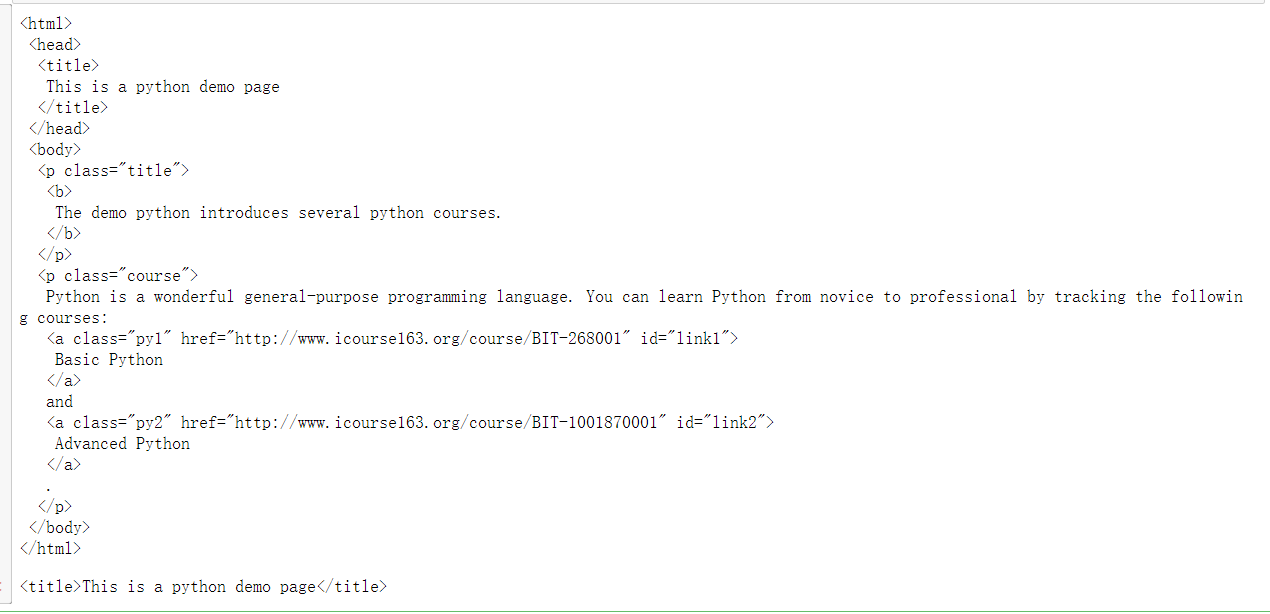
获取源代码
import requests
r=requests.get("http://python123.io/ws/demo.html")
r.text
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify())
soup.title
爬取结果显示:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135839.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
