大家好,又见面了,我是你们的朋友全栈君。
在分布式存储技术体系当中,分布式文件存储是其中的分类之一,也是大数据架构当中常常用到的。得益于Hadoop的高人气,Hadoop原生的HDFS分布式文件系统,也广泛为人所知。但是分布式文件存储系统,并非只有HDFS。今天的大数据开发分享,我们就主要来讲讲常见的分布式文件存储系统。


分布式文件系统,可以说是分布式系统下的一个子集,这里我们选取市场应用比较广泛的几款产品,HDFS、Ceph、FastDFS以及MooseFS来做简单的分析——
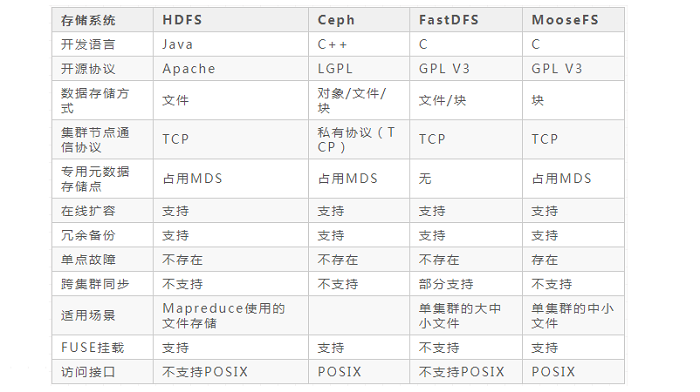
HDFS
如上所说,HDFS是分布式文件系统当中人气非常高的一个。基于Hadoop基础架构,HDFS天然就有很好的优势,尤其是面对大规模离线批处理任务,地位难以撼动。
HDFS,可以为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务,同时HBase、Hive底层存储也依赖于HDFS。与Hadoop生态的紧密联系,也使其稳稳占据市场主流地位。
优点:
高容错性:数据自动保存多个副本,副本丢失后,自动恢复
适合批处理:移动计算而非数据。数据位置暴露给计算框架
适合大数据处理:GB,TB,甚至PB级数据。百万规模以上文件数量。10K+节点规模。
流式文件访问:一次性写入,多次读取。保证数据一致性。
可构建在廉价机器上:通过多副本提高可靠性。提供容错和恢复机制。
缺点:
不适合低延迟数据访问场景:比如毫秒级,低延迟与高吞吐率
不适合小文件存取场景:占用NameNode大量内存。寻道时间超过读取时间。
不适合并发写入,文件随机修改场景:一个文件只能有一个写者。仅支持append
不符合posix语义,需要通过SDK来读写操作。对java支持良好,其他语言一般
Ceph
企业级的存储需求,通常分为块存储、文件存储和对象存储,而Ceph能够同时满足这三种需求。Ceph提供三大存储接口,能够将企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储,具备高可用性、高性能及可扩展等特点。
优点:
支持对象存储(OSD)集群,通过CRUSH算法,完成文件动态定位,处理效率更高
符合posix语义,支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
支持分布式的MDS/MON,无单点故障
强大的容错处理和自愈能力
支持在线扩容和冗余备份,增强系统的可靠性
缺点:
目前处于试验阶段,系统稳定性有待考究
部署和运维较复杂,集群管理工具较少
FastDFS
FastDFS是以C语言开发的一项开源轻量级分布式文件系统,提供文件存储、文件同步、文件访问(文件上传/下载)等通用文件管理操作,尤其适合以文件为载体的在线服务,如图片网站,视频网站等。追求高性能和高扩展性FastDFS,可以看做是基于文件的key value pair存储系统,称作分布式文件存储服务更为合适。
优点:
支持在线扩容机制,增强系统的可扩展性
实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
支持主从文件,支持自定义扩展名
主备Tracker服务,增强系统的可用性
缺点:
不支持POSIX通用接口访问,通用性较低
对跨公网的文件同步,存在较大延迟,需要应用做相应的容错策略
同步机制不支持文件正确性校验,降低了系统的可用性
通过API下载,存在单点的性能瓶颈
MooseFS
MooseFS是在HDFS之后出现的,它也是类似的MDS+OSS架构,区别于HDFS的是,MooseFS没有对运行其上的业务做假设,它没有假设业务是大文件或海量小文件,也就是说,MooseFS的定位是像ext4、xfs、NTFS等单机文件系统一样的通用型文件存储。
优点:
扩容成本低、支持在线扩容,不影响业务,体系架构可伸缩性极强
支持POSIX通用接口访问,支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
文件对象高可用,可设置任意的文件冗余程度(提供比Raid 10更高的冗余级别)
提供系统负载,将数据读写分配到所有的服务器上,加速读写性能
实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
数据恢复比较容易,增强系统的可用性。有回收站功能,方便业务定制
缺点:
Master Server的单点解决方案的健壮性。Master Server一旦出问题Metalogger Server可以恢复升级为Master Server,但是需要恢复时间
Master Server本身的性能瓶颈。MFS的主备架构情况类似于MySQL的主从复制,从可以扩展,主却不容易扩展
随着MFS体系架构中存储文件的总数上升,Master Server对内存的需求量会不断增大
关于大数据开发,分布式文件存储系统,以上就为大家做了简单的介绍了。分布式文件系统,是解决大数据存储问题的重要底层支持,对于市场主流分布式存储产品,需要有相应的了解才行。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135582.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
