大家好,又见面了,我是全栈君。
原文: https://blog.csdn.net/hel12he/article/details/51138507
redis的安装
哎,写到这儿,说一句,诅咒联通这网络,联通网络一上,打开vpn,照样不能访问外网,联baidu都一卡一卡的。
redis就不用yum来进行安装了。直接从官方下载来安装吧。(老实说,我也不知道yum里边有没有redis的最新版)
下载redis
$ wget -c http://download.redis.io/releases/redis-3.0.7.tar.gz
当然你也可以到redis官网 下载最新的版本。当然个人建议,开发中还是使用稳定版本吧! 
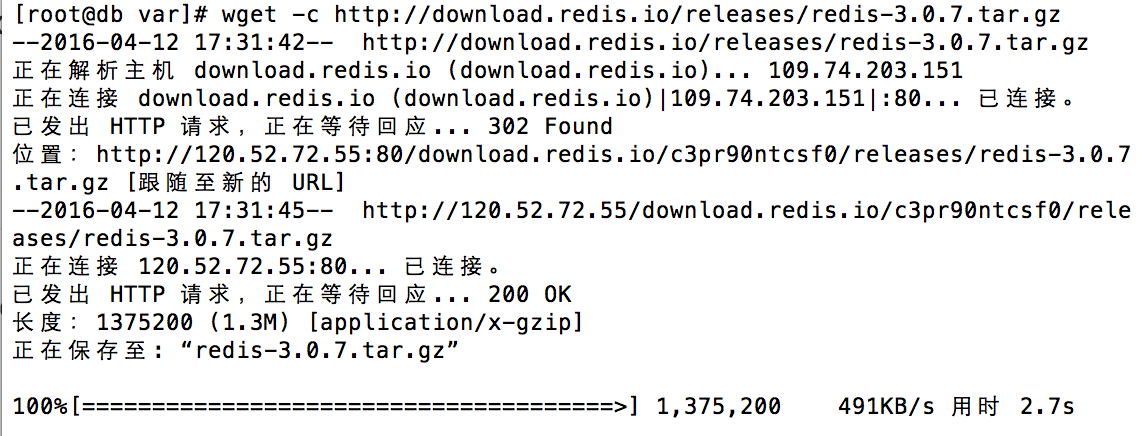
解压redis
$ tar -zxvf redis-3.0.7.tar.gz
这个命令什么意思,我就不多说了,如果不清楚的同学,建议平时还是多积累点linux的命令知识额。加薪升职的利器额。
编译安装redis
$ cd redis-3.0.7
$ make && make install
进入到解压后的目录,然后执行编译,然后安装。
OK,至此,我们的redis安装还没有完额,其实好玩儿的才刚刚开始呢。
配置redis
创建redis 配置文件夹。
$ mkdir /etc/redis
在/var/lib/redis 下创建有效的保存数据的目录
$ mkdir -p /var/lib/redis/6379
redis.conf 是 redis 的配置文件,然而你会看到我们会把这个文件的名字改为 6379.conf ,而这个数字就是 redis 监听的网络端口。如果你想要运行超过一个的 redis 实例,推荐用这样的名字。
复制示例的 redis.conf 到 /etc/redis/6379.conf。
$ cp redis.conf /etc/redis/6379.conf
修改的内容如下:
设置 daemonize 为 no,systemd 需要它运行在前台,否则 redis 会突然挂掉。
daemonize yes设置 pidfile 为 /var/run/redis_6379.pid。
pidfile /var/run/redis_6379.pid如果不准备用默认端口,可以修改。
port 6379设置日志级别。
loglevel debug修改日志文件路径。
logfile /var/log/redis_6379.log设置目录为 /var/lib/redis/6379
dir /var/lib/redis/6379
redis配置文件,各项的详解
######################### 通用 ######################### # 启动后台进程 daemonize yes # 后台进程的pid文件存储位置 pidfile /var/run/redis.pid # 默认监听端口 port 6379 # 在高并发的环境中,为避免慢客户端的连接问题,需要设置一个高速后台日志 tcp-backlog 511 # 只接受以下绑定的IP请求 # Examples: # bind 192.168.1.100 10.0.0.1 bind 127.0.0.1 # 设置unix监听,默认为空 # unixsocket /tmp/redis.sock # unixsocketperm 700 #客户端空闲多长时间,关闭链接,0表示不关闭 timeout 0 # TCP keepalive. # 如果是非零值,当失去链接时,会使用SO_KEEPALIVE发送TCP ACKs 到客户端。 # 这个参数有两个作用: # 1.检测断点。 # 2.从网络中间设备来看,就是保持链接 # 在Linux上,设定的时间就是发送ACKs的周期。 # 注意:达到双倍的设定时间才会关闭链接。在其他内核上,周期依赖于内核设置。 # 一个比较合理的值为60s tcp-keepalive 0 # 指定日志级别,以下记录信息依次递减 # debug用于开发/测试 # verbose没debug那么详细 # notice适用于生产线 # warning只记录非常重要的信息 loglevel notice #日志文件名称,如果为stdout则输出到标准输出端,如果是以后台进程运行则不产生日志 logfile "" # 要想启用系统日志记录器,设置一下选项为yes # syslog-enabled no # 指明syslog身份 # syslog-ident redis # 指明syslog设备。必须是一个用户或者是local0 ~ local7之一 # syslog-facility local0 #设置数据库数目,第一个数据库编号为:0 databases 16 ######################### 快照 ######################### # 在什么条件下保存数据库到磁盘,条件可以有很多个,满足任何一个条件都会进行快照存储 # 在900秒之内有一次key的变化 save 900 1 # 在300秒之内,有10个key的变化 save 300 10 # 在60秒之内有10000个key变化 save 60 10000 # 当持久化失败的时候,是否继续提供服务 stop-writes-on-bgsave-error yes # 当写入磁盘时,是否使用LZF算法压缩数据,默认为yes rdbcompression yes # 是否添加CRC64校验到每个文件末尾--花费时间保证安全 rdbchecksum yes # 磁盘上数据库的保存名称 dbfilename dump.rdb # Redis工作目录,以上数据库保存文件和AOF日志都会写入此目录 dir ./ ######################### 主从同步 ######################### # 主从复制,当本机是slave时配置 # slaveof <masterip> <masterport> # 当主机需要密码验证时候配置 # masterauth <master-password> # 当slave和master丢失链接,或正处于同步过程中。是否响应客户端请求 # 设置为yes表示响应 # 设置为no,直接返回"SYNC with master in progress"(正在和主服务器同步中) slave-serve-stale-data yes # 设置slave是否为只读。 # 注意:即使slave设置为只读,也不能令其暴露在不受信任的网络环境中 slave-read-only yes # 无硬盘复制功能 repl-diskless-sync no # 等待多个slave一起来请求之间的间隔时间 repl-diskless-sync-delay 5 # 设置slave给master发送ping的时间间隔 # repl-ping-slave-period 10 # 设置数据传输I/O,主机数据、ping响应超时时间,默认60s # 这个时间一定要比repl-ping-slave-period大,否则会不断检测到超时 # repl-timeout 60 # 是否在SYNC后slave socket上禁用TCP_NODELAY? # 如果你设置为yes,Redis会使用少量TCP报文和少量带宽发送数据给slave。 # 但是这样会在slave端出现延迟。如果使用Linux内核的默认设置,大概40毫秒。 # 如果你设置为no,那么在slave端研究就会减少但是同步带宽要增加。 # 默认我们是为低延迟优化的。 # 但是如果流量特别大或者主从服务器相距比较远,设置为yes比较合理。 repl-disable-tcp-nodelay no # 设置复制的后台日志大小。 # 复制的后台日志越大, slave 断开连接及后来可能执行部分复制花的时间就越长。 # 后台日志在至少有一个 slave 连接时,仅仅分配一次。 # repl-backlog-size 1mb # 在 master 不再连接 slave 后,后台日志将被释放。下面的配置定义从最后一个 slave 断开连接后需要释放的时间(秒)。 # 0 意味着从不释放后台日志 # repl-backlog-ttl 3600 # 设置slave优先级,默认为100 # 当主服务器不能正确工作的时候,数字低的首先被提升为主服务器,但是0是禁用选择 slave-priority 100 # 如果少于 N 个 slave 连接,且延迟时间 <=M 秒,则 master 可配置停止接受写操作。 # 例如需要至少 3 个 slave 连接,且延迟 <=10 秒的配置: # min-slaves-to-write 3 # min-slaves-max-lag 10 # 设置 0 为禁用 # 默认 min-slaves-to-write 为 0 (禁用), min-slaves-max-lag 为 10 ######################### 安全 ######################### # 设置客户端连接密码,因为Redis响应速度可以达到每秒100w次,所以密码要特别复杂 # requirepass 1413 # 命令重新命名,或者禁用。 # 重命名命令为空字符串可以禁用一些危险命令比如:FLUSHALL删除所有数据 # 需要注意的是,写入AOF文件或传送给slave的命令别名也许会引起一些问题 # rename-command CONFIG "" # 设置客户端连接密码,因为Redis响应速度可以达到每秒100w次,所以密码要特别复杂 requirepass 1413 # 命令重新命名,或者禁用。 # 重命名命令为空字符串可以禁用一些危险命令比如:FLUSHALL删除所有数据 # 需要注意的是,写入AOF文件或传送给slave的命令别名也许会引起一些问题 # rename-command CONFIG "" ######################### 限制 ######################### # 设置最多链接客户端数量,默认为10000。 # 实际可以接受的请求数目为设置值减去32,这32是Redis为内部文件描述符保留的 # maxclients 10000 # 设置最多链接客户端数量,默认为10000。 # 实际可以接受的请求数目为设置值减去32,这32是Redis为内部文件描述符保留的 # maxclients 10000 # 设置最大使用内存数量,在把Redis当作LRU缓存时特别有用。 # 设置的值要比系统能使用的值要小 # 因为当启用删除算法时,slave输出缓存也要占用内存 # maxmemory <bytes> #达到最大内存限制时,使用何种删除算法 # volatile-lru 使用LRU算法移除带有过期标致的key # allkeys-lru -> 使用LRU算法移除任何key # volatile-random -> 随机移除一个带有过期标致的key # allkeys-random -> 随机移除一个key # volatile-ttl -> 移除最近要过期的key # noeviction -> 不删除key,当有写请求时,返回错误 #默认设置为volatile-lru # maxmemory-policy noeviction # LRU和最小TTL算法没有精确的实现 # 为了节省内存只在一个样本范围内选择一个最近最少使用的key,可以设置这个样本大小 # maxmemory-samples 5 ######################### AO模式 ######################### # AOF和RDB持久化可以同时启用 # Redis启动时候会读取AOF文件,AOF文件有更好的持久化保证 appendonly no # AOF的保存名称,默认为appendonly.aof appendfilename "appendonly.aof" # 设置何时写入追加日志,又三种模式 # no:表示由操作系统决定何时写入。性能最好,但可靠性最低 # everysec:表示每秒执行一次写入。折中方案,推荐 # always:表示每次都写入磁盘。性能最差,比上面的安全一些 # appendfsync always appendfsync everysec # appendfsync no # 当AOF同步策略设定为alway或everysec # 当后台存储进程(后台存储或者AOF日志后台写入)会产生很多磁盘开销 # 某些Linux配置会使Redis因为fsync()调用产生阻塞很久 # 现在还没有修复补丁,甚至使用不同线程进行fsync都会阻塞我们的同步write(2)调用。 # 为了缓解这个问题,使用以下选项在一个BGSAVE或BGREWRITEAOF运行的时候 # 可以阻止fsync()在主程序中被调用, no-appendfsync-on-rewrite no # AOF自动重写(合并命令,减少日志大小) # 当AOF日志大小增加到一个特定比率,Redis调用BGREWRITEAOF自动重写日志文件 # 原理:Redis 会记录上次重写后AOF文件的文件大小。 # 如果刚启动,则记录启动时AOF大小 # 这个基本大小会用来和当前大小比较。如果当前大小比特定比率大,就会触发重写。 # 你也需要指定一个AOF需要被重写的最小值,这样会避免达到了比率。 # 但是AOF文件还很小的情况下重写AOF文件。 # 设置为0禁用自动重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb #redis在启动时可以加载被截断的AOF文件,而不需要先执行 redis-check-aof 工具 aof-load-truncated yes ######################### LUA脚本 ######################### # Lua脚本的最大执行时间,单位毫秒 # 超时后会报错,并且计入日志 # 当一个脚本运行时间超过了最大执行时间 # 只有SCRIPT KILL和 SHUTDOWN NOSAVE两个命令可以使用。 # SCRIPT KILL用于停止没有调用写命令的脚本。 # SHUTDOWN NOSAVE是唯一的一个,在脚本的写命令正在执行 # 用户又不想等待脚本的正常结束的情况下,关闭服务器的方法。 # 以下选项设置为0或负数就会取消脚本执行时间限制 lua-time-limit 5000 ####################### redis集群 ######################## # 是否启用集群 # cluster-enabled yes # 集群配置文件 # 集群配置变更后会自动写入改文件 # cluster-config-file nodes-6379.conf # 节点互连超时的阀值 # 节点超时时间,超过该时间无法连接主要Master节点后,会停止接受查询服务 # cluster-node-timeout 15000 # 控制从节点FailOver相关的设置,设为0,从节点会一直尝试启动FailOver. # 设为正数,失联大于一定时间(factor*节点TimeOut),不再进行FailOver # cluster-slave-validity-factor 10 # 最小从节点连接数 # cluster-migration-barrier 1 # 默认为Yes,丢失一定比例Key后(可能Node无法连接或者挂掉),集群停止接受写操作 # 设置为No,集群丢失Key的情况下仍提供查询服务 # cluster-require-full-coverage yes ######################### 慢查询 ######################### # Redis慢查询日志记录超过设定时间的查询,且只记录执行命令的时间 # 不记录I/O操作,比如:和客户端交互,发送回复等。 # 时间单位为微妙,1000000微妙 = 1 秒 # 设置为负数会禁用慢查询日志,设置为0会记录所有查询命令 slowlog-log-slower-than 10000 # 日志长度没有限制,但是会消耗内存。超过日志长度后,最旧的记录会被移除 # 使用SLOWLOG RESET命令可以回收内存 slowlog-max-len 128 ######################### 延迟监测 ######################### # 系统只记录超过设定值的操作,单位是毫秒,0表示禁用该功能 # 可以通过命令“CONFIG SET latency-monitor-threshold <milliseconds>” 直接设置而不需要重启redis latency-monitor-threshold 0 ######################### 事件通知 ######################### # 当事件发生时, Redis 可以通知 Pub/Sub 客户端。 # 可以在下表中选择 Redis 要通知的事件类型。事件类型由单个字符来标识: # K Keyspace 事件,以 _keyspace@<db>_ 的前缀方式发布 # E Keyevent 事件,以 _keysevent@<db>_ 的前缀方式发布 # g 通用事件(不指定类型),像 DEL, EXPIRE, RENAME, … # $ String 命令 # s Set 命令 # h Hash 命令 # z 有序集合命令 # x 过期事件(每次 key 过期时生成) # e 清除事件(当 key 在内存被清除时生成) # A g$lshzxe 的别称,因此 ”AKE” 意味着所有的事件 # notify-keyspace-events 带一个由 0 到多个字符组成的字符串参数。空字符串意思是通知被禁用。 # 例子:启用 list 和通用事件: # notify-keyspace-events Elg # 默认所用的通知被禁用,因为用户通常不需要改特性,并且该特性会有性能损耗。 # 注意如果你不指定至少 K 或 E 之一,不会发送任何事件。 notify-keyspace-events "" #notify-keyspace-events AKE ######################### 高级设置 ######################### # 当有少量条目的时候,哈希使用高效内存数据结构。最大的条目也不能超过设定的阈值。# “少量”定义如下: hash-max-ziplist-entries 512 hash-max-ziplist-value 64 # 和哈希编码一样,少量列表也以特殊方式编码节省内存。“少量”设定如下: list-max-ziplist-entries 512 list-max-ziplist-value 64 # 集合只在以下情况下使用特殊编码来节省内存 # -->集合全部由64位带符号10进制整数构成的字符串组成 # 下面的选项设置这个特殊集合的大小。 set-max-intset-entries 512 # 当有序集合的长度和元素设定为以下数字时,又特殊编码节省内存 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 # HyperLogLog 稀疏表示字节限制 # 这个限制包含了16个字节的头部,当一个HyperLogLog使用sparse representation # 超过了这个显示,它就会转换到dense representation上 hll-sparse-max-bytes 3000 # 哈希刷新使用每100个CPU毫秒中的1毫秒来帮助刷新主哈希表(顶级键值映射表)。 # Redis哈希表使用延迟刷新机制,越多操作,越多刷新。 发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/112229.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
