大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、准备工作
参照官网上资料 ,进行准备工作
1. 验证自己的电脑是否有一个可以支持CUDA的GPU
$ lspci | grep -i nvidia 我的显示为Tesla P800
if it is listed in http://developer.nvidia.com/cuda-gpus, your GPU is CUDA-capable
2.验证自己的Linux版本是否支持 CUDA:The CUDA Development Tools are only supported on some specific distributions of Linux. These are listed in the CUDA Toolkit release notes
uname -m && cat /etc/*release
3. 验证系统是否安装了gcc 在终端中输入: $ gcc –v
4. 验证系统是否安装了kernel header和 package development
sudo apt-get install linux-headers-$(uname -r)
结果显示:升级了 0 个软件包,新安装了 0 个软件包,要卸载 0 个软件包,有 x个软件包未被升级. 表示系统里已经有了,不用重复安装。
二、下载cuda并安装(官网步骤)
1.首先注意版本!
查看版本之间要求 https://www.tensorflow.org/install/source#linux
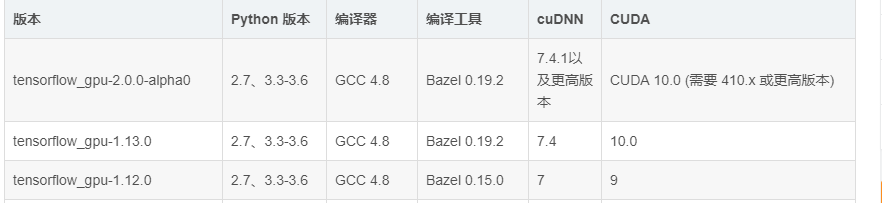

gcc需要降级、cudnn需要7,TensorFlow需要1.12.0
2.下载
官网下载页面上是最新的10.1版本,在后面的过程中才发现TensorFlow可能还不支持,所以想下载低版本的cuda
下载旧版本的cuda地址,本来想选择cuda 9.* ,但里面Ubuntu最高只支持17.10,我的是18.04,所以只能选择cuda 10.0

2.安装:runfile形式安装据说错误率更少
1) 禁用 nouveau驱动
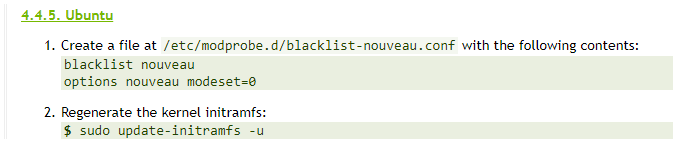
lsmod | grep nouveau 若无内容输出,则禁用成功
我执行以上操作后,还是有输出,reboot重启后,无输出了。
2)执行安装脚本
sudo sh cuda_***_linux.run (你下载的runfile安装包名字)
注意:先accept,安装项里不要选择安装驱动,避免有坑,其他都yes
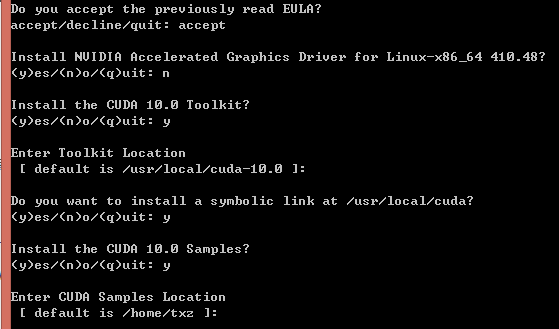
会提示:
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 10.0 functionality to work.忽略就行
可以看到软连接已经指向10.0版本了
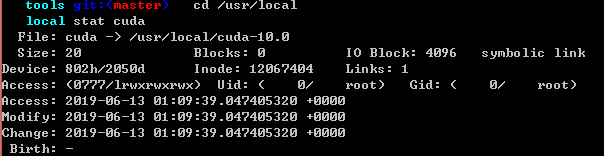
3)设置环境变量
在主目录下的~/.bashrc文件添加如下路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.0/lib64
export PATH=$PATH:/usr/local/cuda-10.0/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-10.0
用su直接切换到root,再执行 source ~/.bashrc
4)检测是否安装成功

出现以下结果

博客里说这个result为pass则为成功
时隔几个月之后,cuda又不能正常使用了
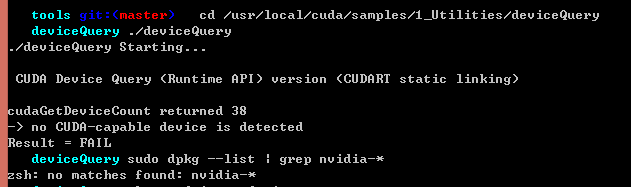
显示是缺失driver(安装的时候选了安,不知为何又bug了)
参照网上的安装步骤
(1)方式1
ubuntu-drivers devices
sudo ubuntu-drivers autoinstall #自动安装报错
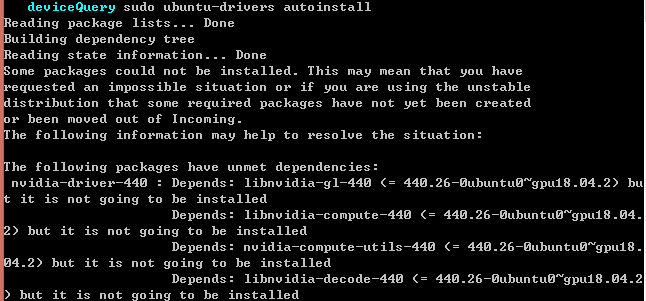
(2)方式2
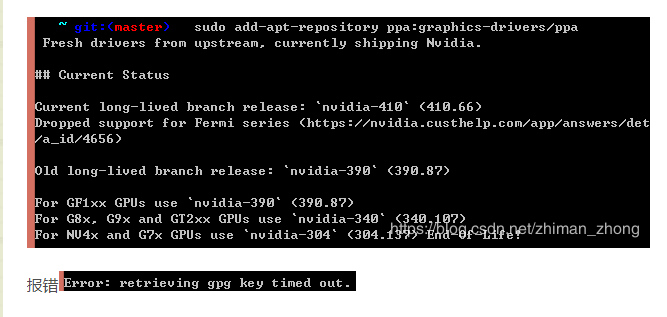
(3)方式3
只能尝试手动下载,在https://www.nvidia.com/Download/index.aspx官网选择
下载之后  ,会进入交互界面
,会进入交互界面
提示说一句有410.48版本
但是再用sudo dpkg –list | grep nvi,查不到410.48,用cat /proc/driver/nvidia/version,也是无此文件
交互过程中提示内核版本之类的问题,也是无疾而终
(4)方式4:重装,并选择install driver
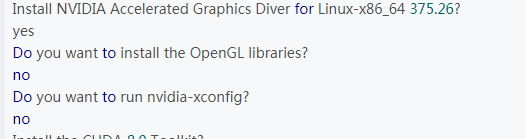
发现这次报错了,显示missing recommended library,可由此篇博客解决,但解决之后对驱动没有太大影响
在nvidia安装日志(/tmp/cuda_install_2971.log)里发现是dkms的问题
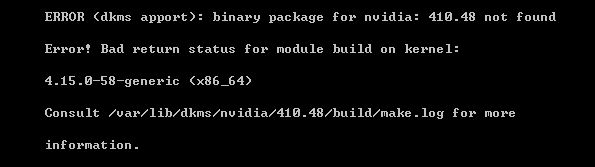
又寻根到/var/lib/dkms/nvidia/…
找到error:unrecognized command line option ‘fstack-protector-strong’
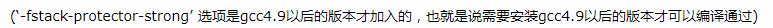
gcc之前是4.8.5问题,我升级到5.5.0,再重新安装
刚刚dkms的问题没有了,甚至执行王同学的代码都能OK

但存在另一个问题
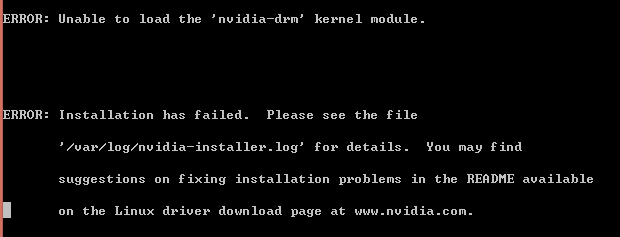
(有人说这个问题不重要)
那难道是没有卸载之前版本的问题吗? sudo apt-get purge nvidia*
一狠心就执行,全部删掉,然后重新sh .run文件
还是不行。。。。重装机器吧。。。
三、安装cudnn
下载地址,需要自行注册,然后选择cuda10.0的对应版本,cudnn 7.4.1

解压缩:tar -xzvf cudnn-9.0-linux-x64-v7.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
查看cudnn版本 cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
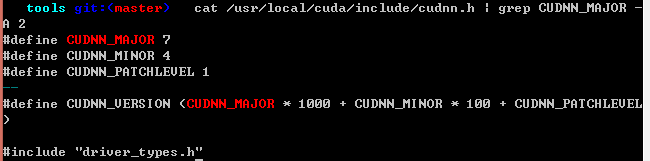
如果出现所示版本信息,说明安装成功。
四、安装TensorFlow-GPU版本
查看python3对应的TensorFlow安装版本,发现cpu与gpu并存
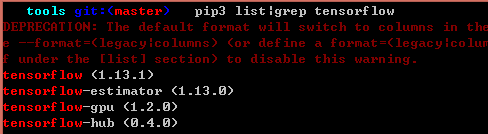
1.尝试安装对应gpu版本
pip3 install tensorflow-gpu==1.13.1
结果import的时候报错

查了下原因,应该是前面设置的环境变量没有生效,参考博客
(1)临时解决方法1(下次登录失效)
在终端执行前面的的export操作,发现终于能正常运行
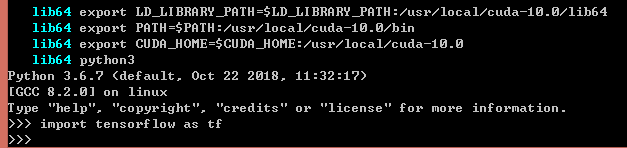
(2)临时解决方法2
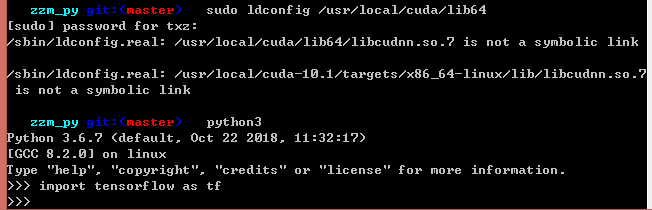
2.判断运行的TensorFlow是cpu还是gpu
# 转自知乎.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
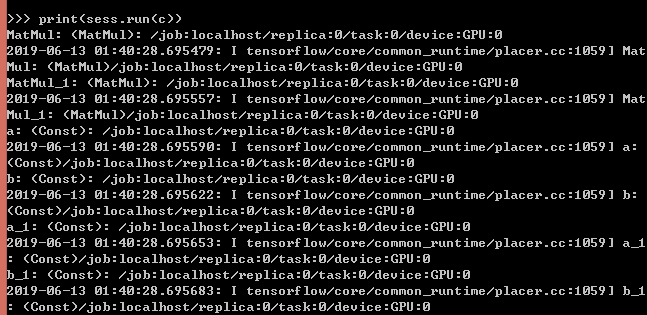
可以看到输出信息都是关于GPU的,说明TensorFlow-GPU版本正常工作了
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193785.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
