大家好,又见面了,我是你们的朋友全栈君。
2020-11-25-周报v1
论文一(对知识推理的认识)
中文引用格式: 官赛萍,靳小龙,贾岩涛,王元卓,程学旗.面向知识图谱的知识推理研究进展.软件学报,2018,29(10):29662994.
1.1 知识推理的简介
面向知识图谱的知识推理旨在基于已有的知识图谱事实,推理新的事实或识别错误知识。例如,在DBpedia 中已知三元组(X,birthPlace,Y),可以在很大程度上推理出缺失的三元组(X,nationality,Y)。
主要分为:知识图谱补全和知识图谱去噪
知识图谱补全:知识图谱补全实际上是给 定三元组中任意两个元素,试图推理出缺失的另外一个元素(包括实体预测和关系预测)
知识图谱去噪:知识图谱去噪专注于知识图谱内部已有三元组正确性的判断,但本质上是评估三元组的有效性。
1.2 基于传统方法的推理
具体可分为两类:基于传统规则 推理的方法和基于本体推理的方法,分别将传统的规则推理和本体推理方法用于面向知识图谱的知识推理.
-
基于传统规则推理的方法
基于传统规则推理的方法主要借鉴传统知识推理中的规则推理方法,在知识图谱上运用简单规则或统计特征进行推理。例如:NELL 知识图谱内部的推理组件采用一阶关系学习算法进行推理;YAGO知识图谱内部采用了一个推理机——Spass-YAGO以丰富知识图谱内容。还有学者提出了一阶概率语言模型ProPPR进行知识图谱的扩充等
-
基于本体推理的方法
基于本体推理的方法主要利用更为抽象化的本体层面的频繁模式、约束或路径进行推理。例如:基于模式的知识图谱的补全,关注于启发式规则推理知识图谱中不确定和冲突的知识等。
1.3 单步推理
单步推理是指用直接关系即知识图谱中的事实元组进行学习和推理,根据所用方法的不同,具体可分为基于规则的推理、基于分布式表示的推理、基于神经网络的推理以及混合推理。
-
基于分布式表示的推理
单步推理中,基于分布式表示的推理首先通过表示模型学习知识图谱中的事实元组,得到知识图谱的低维 向量表示;然后,将推理预测转化为基于表示模型的简单向量操作。基于分布式表示的单步推理包括基于转移、 基于张量/矩阵分解和基于空间分布等多类方法。
-
基于神经网络的推理
单步推理中,基于神经网络的推理利用神经网络直接建模知识图谱事实元组,得到事实元组元素的向量表示,用于进一步的推理。该类方法依然是一种基于得分函数的方法,区别于其他方法,整个网络构成一个得分函数,神经网络的输出即为得分值。
-
混合推理
单步推理中,混合推理通过混合多种单步推理方法,充分利用不同方法的优势,例如基于规则推理的高准确率、基于分布式表示推理的强计算能力、基于神经网络推理的强学习能力和泛化能力。混合单步推理包括混合规则与分布式表示以及混合神经网络与分布式表示的推理。
1.4 多步推理
多步推理是在单步推理建模直接关系的基础上进一步建模间接关系,即多步关系。多步关系是一种传递性约束,例如以下两步关系的例子:a 和 b 存在关系 r1,b 和 c 存在关系 r2,该两步路径对应的直接关系是 a 和 c 存在 关系 r3.多步关系的引入,建模了更多信息,往往比单步推理效果更好。多步推理按不同的推理方法划分,同样分为基于规则的推理、基于分布式表示的推理、基于神经网络的推理以及混合推理。
-
基于规则的推理
多步推理中,基于规则的推理不同于基于规则的单步推理,后者用到的是类似关系 r1 推出关系 r2 的简单经验规则或一些基于统计的频繁模式。而多步推理用到的规则更为复杂,如传递性规则。鉴于人工获取有效且覆盖率广的传递性规则代价比较高,这些规则一般通过挖掘的实体间路径来近似。根据是否引入局部结构,基于规则的多步推理可分为基于全局结构和引入局部结构的规则推理两种。
-
基于分布式表示的推理
多步推理中,基于分布式表示的推理与基于分布式表示的单步推理类似,都是通过向量化知识图谱进行推理。不同的是,多步推理在学习向量表示的过程中引入了多步关系约束,使得学到的向量表示更有助于实体和关系的推理预测。
-
基于神经网络的推理
多步推理中,基于神经网络的推理旨在用神经网络建模学习多步推理过程,包括建模多步路径以及模拟计算机或人脑的推理。
-
混合推理
多步推理中,混合推理通过混合不同多步方法进行推理,实现优势互补。分布式表示方法由于其计算的便捷性,通常被用于与其他方法混合.混合多步推理具体包括混合 PRA 与分布式表示、混合规则与分布式表示以及混合规则与神经网络的推理。
知识推理根据推理类型可分为单步推理和多步推理两大类。每类又包括基于规则的推理、基于分布式表示 的推理、基于神经网络的推理以及混合推理。各类方法的汇总见下表.
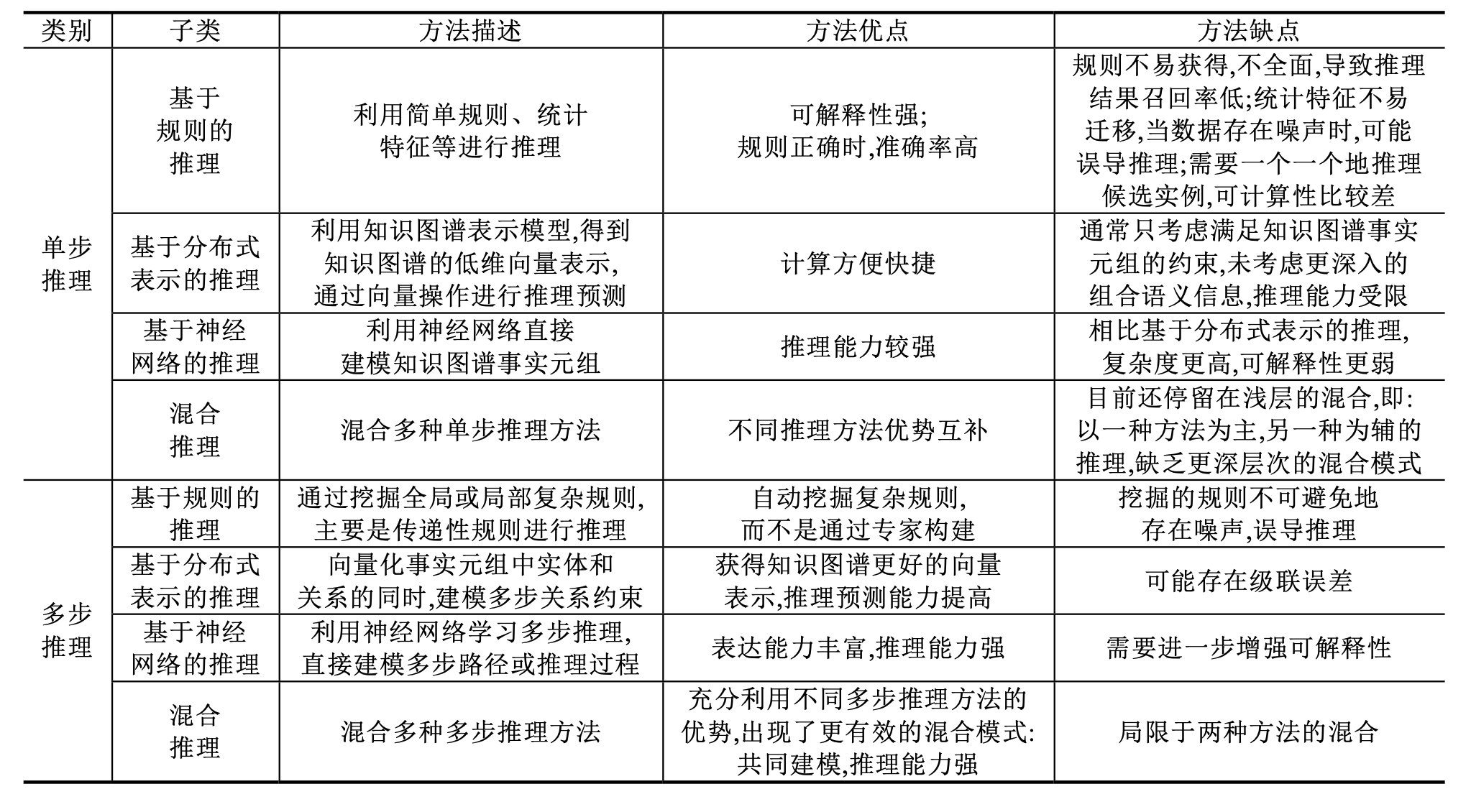

总的来说,单步推理基于知识图谱中的事实元组建模,而多步推理在单步推理的基础上建模了多步路径的约束,表达能力往往比单步推理更强,推理预测效果更好。
1.5 知识图谱的典型应用
前述的知识图谱补全和去噪是知识推理的两大基础应用。现有的知识图谱由于数据来源的不全面以及知识获取的遗漏,不可能构建完备的知识图谱。通常,代表性的知识图谱中有69%~99%的实体缺少至少一个属性信息三元组。例如,在Freebase 中,93.8%的人没有出生地信息,78.5%的人没有国籍信息解决办法之一就是通过知识推理方法,利用知识图谱中已有的知识去推理出新的事实(即隐含的知识),从而尽可能地对知识图谱进行补全。另一方面,就知识图谱自身而言,由于数据来源的噪声以及抽取过程的不准确,内部也存在噪声知识和知识矛盾现象。
除了知识图谱补全与去噪,知识推理在垂直搜索、智能问答、机器翻译等领域也发挥了重要作用,在疾病 诊断、金融反欺诈、数据异常分析等诸多不同的领域已展示出良好的应用前景。
例如Google的搜索,在Google搜索引擎输入查询,搜索引擎在利用知识图谱直接给出推理得到的精确回答的同时,在搜索结果的右侧显示该词条的深层信息。
在智能问答领域,IBM的Watson、Google的Google Now、苹果公司的Siri、亚马逊的Alexa、微软的小娜和小冰以及百度的度秘等是近期代表性的智能问答系统。这些系统基于知识图谱的知识推理,提供精确、简洁的答案。
论文二
X. Xiang, Z. Wang, Y. Jia and B. Fang, “Knowledge Graph-Based Clinical Decision Support System Reasoning: A Survey,” 2019 IEEE Fourth International Conference on Data Science in Cyberspace (DSC), Hangzhou, China, 2019, pp. 373-380, doi: 10.1109/DSC.2019.00063.
2.1 主要研究
2.1.1 涉及知识图谱的计算和应用:KG推理。
目的是通过已知事实推断隐藏信息诱导新知识,而无需人工干预。基于其推理能力,可以实现各种下游应用程序,例如问答工具,推荐系统和文本分类设备。
2.1.2 知识图谱推理
-
目的
知识图谱推理,也称知识图谱补全,链接预测或知识图谱更新,无需学习特定推理公式,即可完成任务。例如,如果KG包含这样的陈述,即鲍勃患有癫痫发作,并且癫痫发作可能导致自闭症,那么推理者应该能够学习以下公式:(鲍勃,患有,癫痫发作)∧(癫痫发作,可能引起自闭症)⇒ (鲍勃,也许有,自闭症)。当在临床决策支持系统中应用这种推理方法时,即使没有卫生专业人员,机器本身也可以自动识别缺失的链接或错误的事实并产生新的知识。 为简单起见,知识图推理通常分为两个子类别,一个称为嵌入方法,另一个称为基于路径的方法。
-
基于知识图谱嵌入的方法
知识图嵌入旨在将KG中的实体和关系投影到一个低维的连续语义空间中,以简化操作,同时保留知识图的固有结构完整。这种机制通常将实体和关系从符号空间嵌入到连续向量空间;并根据评分功能对每个唯一观察到的事实进行评估,以确定其可信度。计分功能是矢量或矩阵运算。与不存在的事实相比,KG中出现的事实倾向于构成更高的权重。最后,可以通过最大化观察到的事实的总似真性来实现嵌入表示(当今最流行的嵌入技术是RESCAL,TransE,TransH,TransR和TransD)。
-
基于知识图谱路径的方法
路径排序算法可以获取推理规则并处理巨大的知识图上的推理。由Lao和Cohen在2010年提出的PRA [70]成为学习知识图中推理任务的有前途的方法。 PRA将知识库视为图形,然后使用随机游动将KG上的相关特征(或路径)序列生成为节点对上的特征矩阵。然后将它们与逻辑回归模型结合以进行推理。建立在PRA之上的假设是,在图节点对之间存在通过相同边线类型连接的一些公共子结构[71],并且它尝试使用关系路径的集合对该结构进行建模。

下图中所示的示例。假定该算法尝试学习模型并推断与图中绿线相对应的医学关系SymptomMightCause的新实例。
在最初的FindEdgeSequence轮次中,PRA将查找从源节点到目标节点的路径,例如,((Seizures or epilepsy, Autism), (No response to name, Autism), (Genetic Cause, Rett Syndrome)【(癫痫发作或癫痫,自闭症),(对姓名的无反应,自闭症),(遗传原因,瑞特综合症)】等。确定所有路径类型后,FindEdgeSequence会选择这些路径的一部分,以将其用作模型中的特征(在现实世界中,边缘序列太多而无法全部包含在特征矩阵中)。
ComputeFeatureMatrix步骤计算每个训练实例和相关路径序列的概率。该概率表明随机游走从遵循预定边缘类型的源节点开始并在目标节点处结束的可能性。对于此示例性知识图中给出的大多数路径,(癫痫发作或癫痫,自闭症),(对姓名无反应,交流障碍,自闭症)和(16个月内没有一个单词,交流障碍,自闭症)等于1。但是,对于某些路径(遗传原因,自闭症),概率肯定小于1,可能为0.5;由于随机步行者会间歇性地到达瑞特综合症,因此疾病不再属于ASD谱图。
最终操作TrainLogisticRegression(或在没有PRA方案的情况下,可以使用任何其他分类模型)可以使用前一会话提供的功能矩阵来执行即将来临的操作。

总结
1.知识推理主要应用于知识补全(帮助进一步完善和补全知识图谱)和应用于领域知识方面推理等功能
2.知识推理在实际的中药检索方面应用并不广泛(有待更进一步考察)
3.列举部分已有医学领域方面基于知识推理的具体应用,例如,Kumar,Singh和Sanyal(2009)提出了一种基于案例推理和基于规则推理的混合方法,以构建重症监护病房(ICU)的临床决策支持系统。 García-Crespo,Rodríguez,Mencke,Gómez-Berbís和Colomo-Palacios(2010)设计了一种基于本体的差异诊断系统(ODDIN),该系统基于逻辑推理和概率改进。 Martínez-Romero等。 (2013年)建立了一个基于本体的系统,用于对急性心脏疾病的重症患者进行智能监督和治疗,其中专家的知识由OWL本体和一套SWRL规则代表。在此知识的基础上,推理引擎将执行推理过程,并为医生提供有关患者治疗的建议。 Ruan,Sun,Wang,Fang和Yin(2016)将存储在中医知识图中的数据转换为推理规则,然后将其与患者数据结合起来,以根据知识图得出辅助处方。参考来自以下论文:

4.知识推理具有多种实现方法,具体实现可择优选择
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135151.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
