大家好,又见面了,我是你们的朋友全栈君。
目录
DNS原理解析
DNS进化史
etc/hosts –> NIS –>DNS
起初域名和ip地址之间的解析都是完全存放在一个名为hosts的文件当中,在这个文件当中我们建立了ip和域名的一一对应的关系,在互联网初期,这样做完全是没有问题的,但是随着网络的发展,网络内的主机越来越多,这个文件会变得越来越大,而且为了保证每台主机都能有这样的解析功能,我们不得不让每台主机都有同样的文件,那么每次我们更新文件的时候,互联网每台主机都需要更新自己的hosts文件,这是一件工作量极其大的事情。
后期,人们采用了一种名为NIS的解决方式,实现的方法是把所有ip地址和网络域名之间的对应存放在一个服务器上,每次有主机需要进行域名解析的时候,我们就让该台主机去访问这台名为NIS的服务器,后来随着网络的扩展,互联网上的主机上百亿,这样对NIS服务器的负载极大,NIS不得不退出了历史舞台。
现在,我们使用DNS协议,来实现分布式、阶层式的系统来管理ip地址和域名之间的对应关系。
DNS结构

从上图中,我们可以知道,DNS利用类似树状目录的架构,将主机名的管理分配在不同层级的DNS服务器当中,经由分层管理,所以每一部DNS服务器记忆的信息就不会很多,而且若有IP 异动时也相当容易修改!因为你如果已经申请到主机名解析的授权,那么在你自己的DNS服务器中,就能够修改全世界都可以查询到的主机名了!
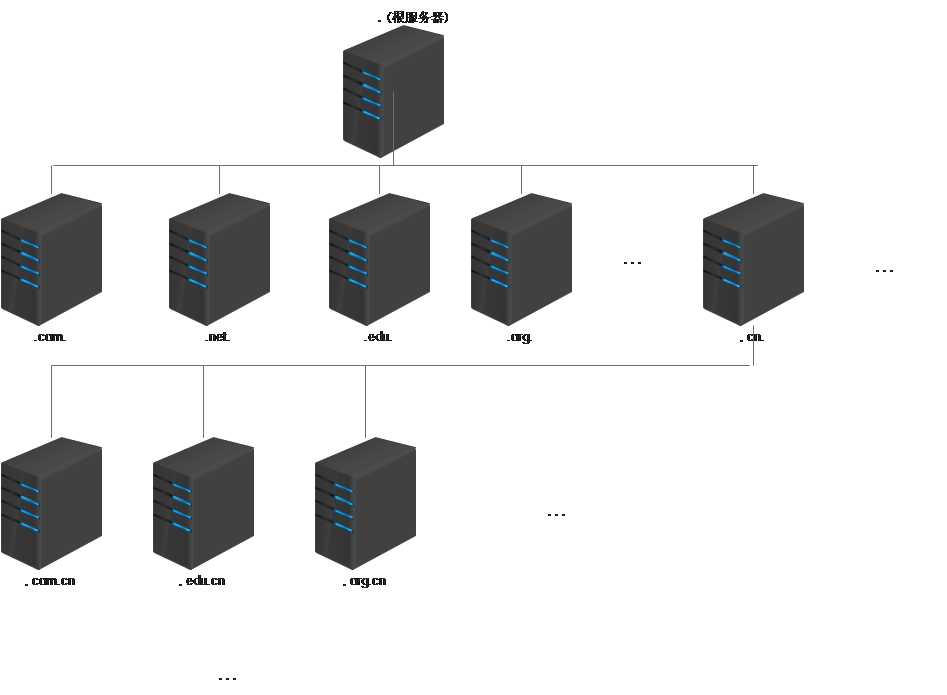
DNS是以树状目录分阶层的方式来处理主机名,我们知道树状结构的好处就是,父节点只关注他的子节点的内容,而不关注他的孙子节点的内容,这样就在很大程度上实现了分治,根节点只需要管理它的子节点.com .cn .edu等域名和ip地址之间的关系即可,再往下的baidu.com,qq.com域名就完全和他无关了。
DNS查询流程
我们以客户端第一次查询百度为例子解释DNS的查询流程
递归和迭代的区别?
所谓 递归查询过程 就是 “查询的递交者” 更替, 而 迭代查询过程 则是 “查询的递交者”不变。
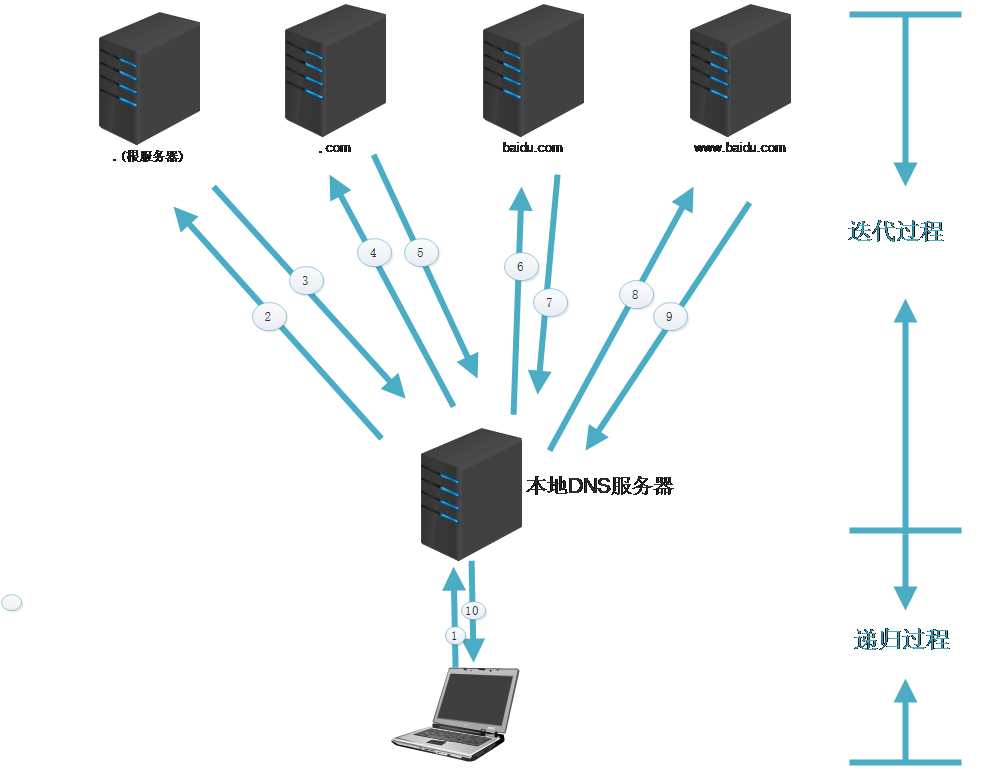
在需要DNS解析的客户端,比如说笔记本,当我们解析www.baidu.con时我们会先进行下面的操作:
操作系统会先检查自己本地的hosts文件—>查找本地DNS解析器缓存(笔记本的缓存)
如果以上两步都没有找到会执行上图所示的步骤:
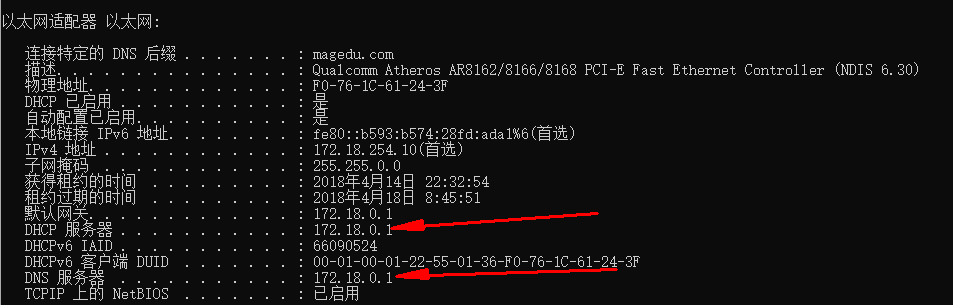
1.如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,进入windows下的命令行窗口输入ipconfig/all,即可查到你当前的DNSsever.如图
箭头一是DHCP服务器,箭头二是DNS服务器。
此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
2.如果本地DNS没有该条记录,那么本地DNS就把请求发至 “根DNS服务器”,“根DNS服务器”收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。基于本例子,根服务器会发送.com服务器ip地址。(对应图中的2、3条信息记录)。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(baidu.com)给本地DNS服务器。(对应途中4、5条信息记录),以此类推下去,直至最后本地DNS得到了www.baidu.com服务器的IP地址
3.最后一步,本地DNS把查询到的记录进行缓存并且将该条记录返回给客户端。对应图中的第10步。
我们把该过程画成流程图则如下所示:

DNS服务搭建
DNS相关软件的安装
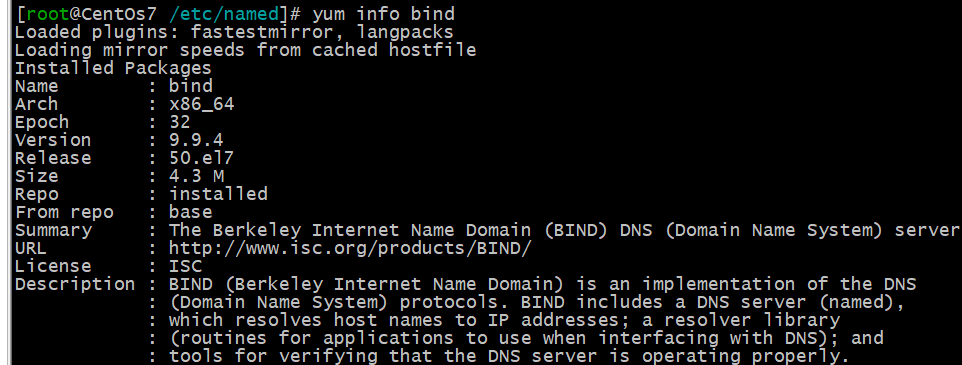
我们使用主流的提供DNS服务的软件,bind.下面我们先查询一下该软件的相关信息
安装方法:[root@CentOs7 /etc/named]# yum -y install bind
服务器搭建规划
规划自己搭建的局域网的域名为xiaomi.com。由于我们搭建的DNS是不接上互联网的,所以此处域名是可以随意取得,我就使用xiaomi的域名了。
- 两台安装了CentOs7.4的虚拟机,利用这两台主机搭建Master/Slave结构的DNS服务
- 涉及到的配置文件:
- named.conf(主要配置文件)
- named.xiaomi.com(涉及到xiaomi.com这个域的正解配置文件)
- named.ca (bind软件提供的能够解析根服务器的正解配置文件)
手把手教你搭建基本DNS服务器
搭建主DNS服务器
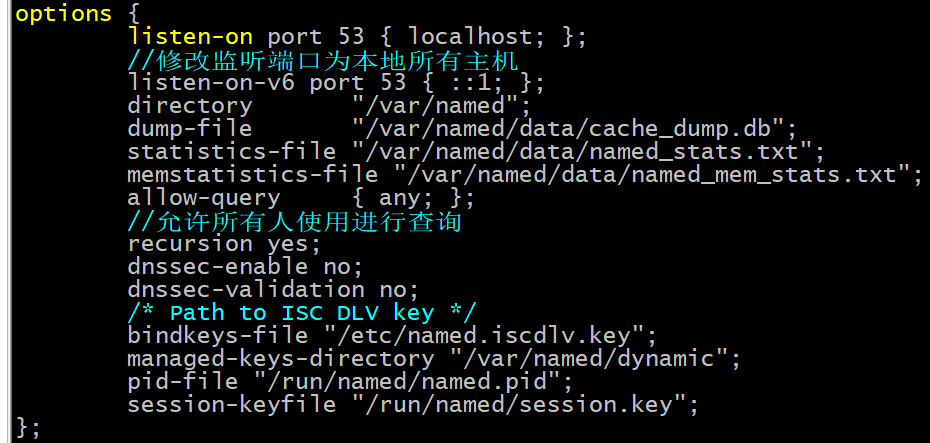
第一步:安装bind软件包,修改/etc/named.conf文件,对全局配置options修改如下:
第二步:在/etc/named.conf配置文件中加入一段有关xiaomi.com的zone文件。具体配置如下:
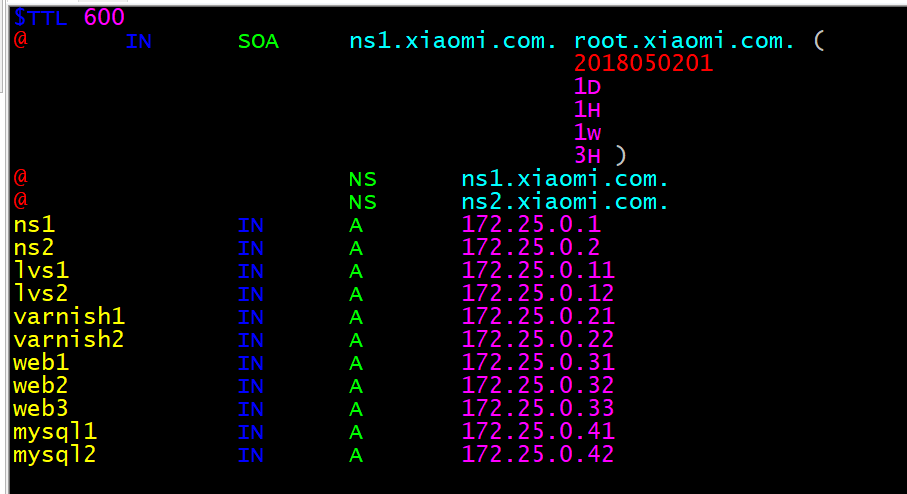
第三步:新建文件/var/named/xiaomi.com.zone,编辑正向解析区域文件,配置内容如下:
第四步:重启服务,并设置为开机自启动服务。

搭建从DNS服务器
步骤较为简单,连正解zone文件都不需要写,你只需要写个zone文件的类似于声明一样的东西,写在主配置文件/etc/named.conf尾部。如下所示
当你主配置文件的SOA记录的serial变大时,从配置文件会自动更新收到主配置文件的变化并努力保持一致。

参考文献
- 《鸟哥的linux私房菜服务篇》
- DNS解析的工作原理及递归与迭代的区别
- 《TCP/IP详解卷一:协议》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134835.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
