大家好,又见面了,我是你们的朋友全栈君。
摘要
本文在写完GBDT的三篇文章后本来就想写的,但一直没有时间,终于刚好碰上需要,有空来写这篇关于xgboost原理以及一些实践的东西(这里实践不是指给出代码然后跑结果,而是我们来手动算一算整个xgboost流程)
由于网上已经许多优秀的文章对xgboost原理进行了详细的介绍,特别是xgboost作者陈天奇的论文以及slide已经非常完整阐述了整个xgboost的来龙去脉,现有的文章基本也是参考了这两个资料。
但是却少涉及把原理对应到实际实现过程的文章,许多人看完原理之后可能对整个过程还是抱有好奇心,所以本文从另一个角度,原理到实际运行的角度来分析xgboost,相当于结合原理,仔细看看xgboost每一步到底计算了什么。
原理
当然,我们还是需要简要的回顾一下xgboost的整个推导过程,以及做一些铺垫,方便后面叙述。
我们知道,任何机器学习的问题都可以从目标函数(objective function)出发,目标函数的主要由两部分组成 损失函数+正则项。
Obj(Θ)=L(Θ)+Ω(Θ) O b j ( Θ ) = L ( Θ ) + Ω ( Θ )
损失函数用于描述模型拟合数据的程度。
正则项用于控制模型的复杂度。
对于正则项,我们常用的L2正则和L1正则。
L1正则:
Ω(w)=λ||w||1 Ω ( w ) = λ | | w | | 1
L2正则:
Ω(w)=λ||w||2 Ω ( w ) = λ | | w | | 2
在这里,当我选择树模型为基学习器时,我们需要正则的对象,或者说需要控制复杂度的对象就是这 K K 颗树,通常树的参数有树的深度,叶子节点的个数,叶子节点值的取值(xgboost里称为权重weight)。
所以,我们的目标函数形式如下:
L(yi,ŷ i)+∑Kk=1Ω(fk(xi))
对一个目标函数,我们最理想的方法就选择一个优化方法算法去一步步的迭代的学习出参数。但是这里的参数是一颗颗的树,没有办法通过这种方式来学习。
既然如此,我们可以利用Boosting的思想来解决这个问题,我们把学习的过程分解成先学第一颗树,然后基于第一棵树学习第二颗树。也就是说:
ŷ 0i=常数 y ^ i 0 = 常 数
ŷ 1i=ŷ 0i+f1(xi) y ^ i 1 = y ^ i 0 + f 1 ( x i )
ŷ 2i=ŷ 1i+f2(xi) y ^ i 2 = y ^ i 1 + f 2 ( x i )
ŷ Ki=ŷ K−1i+fK(xi)(0) (0) y ^ i K = y ^ i K − 1 + f K ( x i )
所以,对于第K次的目标函数为:
ObjK=∑iL(yi,ŷ Ki)+Ω(fK)+constant O b j K = ∑ i L ( y i , y ^ i K ) + Ω ( f K ) + c o n s t a n t
==>
ObjK=∑iL(yi,ŷ K−1i+fK(xi))+Ω(fK)+constant O b j K = ∑ i L ( y i , y ^ i K − 1 + f K ( x i ) ) + Ω ( f K ) + c o n s t a n t
上面的式子意义很明显,只需要寻找一颗合适的树 fK f K 使得目标函数最小。然后不断的迭代K次就可以完成K个学习器的训练。
那么我们这颗树到底怎么找呢?
在GBDT里面(当然GBDT没有正则),我们的树是通过拟合上一颗树的负梯度值,建树的时候采用的启发式准则。具体参考文章。
然而,在xgboost里面,它是通过对损失函数进行泰勒展开。
(其思想主要来自于文章:Additive logistic regression a statistical view of boosting也是Friedman大牛的作品)
二阶泰勒展开:
f(x+Δx)=f(x)+f′(x)Δx+12f″(x)Δx2 f ( x + Δ x ) = f ( x ) + f ′ ( x ) Δ x + 1 2 f ″ ( x ) Δ x 2
对损失函数二阶泰勒展开:
∑iL(yi,ŷ K−1i+fK(xi))=∑i[L(yi,ŷ K−1i)+L′(yi,ŷ K−1i)fK(xi)+12L″(yi,ŷ K−1i)f2K(xi)] ∑ i L ( y i , y ^ i K − 1 + f K ( x i ) ) = ∑ i [ L ( y i , y ^ i K − 1 ) + L ′ ( y i , y ^ i K − 1 ) f K ( x i ) + 1 2 L ″ ( y i , y ^ i K − 1 ) f K 2 ( x i ) ]
注意的是,这里的 yi y i 是标签值是个常数,而 ŷ K−1i y ^ i K − 1 是前一次学习到的结果,也是个常数。所以只要把变化量 Δx Δ x 看成我们需要学习的模型 fK(x) f K ( x ) 就可以展成上面的这个样子了。
这里,我们用 gi g i 记为第i个样本损失函数的一阶导, hi h i 记为第i个样本损失函数的二阶导。
gi=L′(yi,ŷ K−1i)(1) (1) g i = L ′ ( y i , y ^ i K − 1 )
hi=L″(yi,ŷ K−1i)(2) (2) h i = L ″ ( y i , y ^ i K − 1 )
(1)式和(2)非常的重要,贯穿了整个树的构建(分裂,叶子节点值的计算)。以及(2)式是我们利用xgboost做特征选择时的其中一个评价指标。
所以我们可以得到我们进化后的目标函数:
∑i[L(yi,ŷ K−1i)+gifK(xi)+12hif2K(xi)]+Ω(fK)+constant ∑ i [ L ( y i , y ^ i K − 1 ) + g i f K ( x i ) + 1 2 h i f K 2 ( x i ) ] + Ω ( f K ) + c o n s t a n t
这里,我们先回忆一下,一颗树用数学模型来描述是什么样,很简单其实就是一个分段函数。比如有下面一颗树。

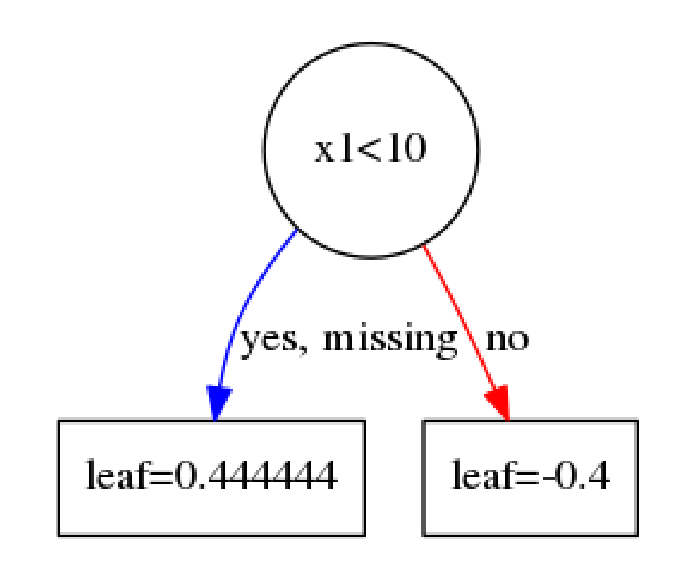
0.444444−0.4x1<10x1>=10 f ( x ) = { 0.444444 x 1 < 10 − 0.4 x 1 >= 10
也就是说,一棵树其实可以由一片区域以及若干个叶子节点来表达。
而同时,构建一颗树也是为了找到每个节点的区域以及叶子节点的值。
也就说可以有如下映射的关系 fK(x)=wq(x) f K ( x ) = w q ( x ) 。其中 q(x) q ( x ) 叶子节点的编号(从左往右编)。 w w 是叶子节点的取值。
也就说对于任意一个样本
x
,其最后会落在树的某个叶子节点上,其值为 wq(x) w q ( x ) 。
既然一棵树可以用叶子节点来表达,那么,我们上面的正则项就了其中一个思路。我们可以对叶子节点值进行惩罚(正则),比如取L2正则,以及我们控制一下叶子节点的个数T,那么正则项有:
Ω(fK)=12λ∑Tj||wj||2+γT Ω ( f K ) = 1 2 λ ∑ j T | | w j | | 2 + γ T
其实正则为什么可以控制模型复杂度呢?有很多角度可以看这个问题,最直观就是,我们为了使得目标函数最小,自然正则项也要小,正则项要小,叶子节点个数T要小(叶子节点个数少,树就简单)。
而为什么要对叶子节点的值进行L2正则,这个可以参考一下LR里面进行正则的原因,简单的说就是LR没有加正则,整个 w w 的参数空间是无限大的,只有加了正则之后,才会把
w
的解规范在一个范围内。(对此困惑的话可以跑一个不带正则的LR,每次出来的权重 w w 都不一样,但是loss都是一样的,加了L2正则后,每次得到的w都是一样的)
这个时候,我们的目标函数(移除常数项后)就可以改写成这样(用叶子节点表达):
∑i[giwq(xi)+12hiw2q(xi)]+12λ∑Tj||wj||2+γT(3)
其实我们可以进一步化简,那么最后可以化简成:
∑Tj=1[(∑(i∈Ij)gi)wj+12(∑(i∈Ij)hi+λ)w2j]+γT(4) (4) ∑ j = 1 T [ ( ∑ ( i ∈ I j ) g i ) w j + 1 2 ( ∑ ( i ∈ I j ) h i + λ ) w j 2 ] + γ T
(3)式子展开之后按照叶子节点编号进行合并后可以得到(4)。可以自己举T=2的例子推导一下。
下面,我们把 ∑(i∈Ij)gi ∑ ( i ∈ I j ) g i 记为 Gj G j ,把 ∑(i∈Ij)hi ∑ ( i ∈ I j ) h i 记为 Hj H j 。
Gj=∑(i∈Ij)gi(5) (5) G j = ∑ ( i ∈ I j ) g i
Hj=∑(i∈Ij)hi(6) (6) H j = ∑ ( i ∈ I j ) h i
那么目标函数可以进一步简化为:
∑Tj=1[Gjwj+12(Hj+λ)w2j]+γT(7) (7) ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T
我们做了这么多,其实一直都是在对二阶泰勒展开后的式子化简,其实刚展开的时候就已经是一个二次函数了,只不过化简到这里能够把问题看的更加清楚。所以对于这个目标函数,我们对 wj w j 求导,然后带入极值点,可以得到一个极值:
w∗=−GjHj+λ(8) (8) w ∗ = − G j H j + λ
Obj=−12∑Tj=1G2jHj+λ+γT(9) (9) O b j = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T
我们花了这么大的功夫,得到了叶子结点取值的表达式。
如果有看过我们前面GBDT文章的朋友应该没有忘记当时我们也给出了一系列的损失函数下的叶子节点的取值,在xgboost里,叶子节点取值的表达式很简洁,推导起来也比GBDT的要简便许多
到这里,我们一直都是在围绕目标函数进行分析,这个到底是为什么呢?这个主要是为了后面我们寻找 fk(x) f k ( x ) ,也就是建树的过程。
具体来说,我们回忆一下建树的时候需要做什么,建树的时候最关键的一步就是选择一个分裂的准则,也就如何评价分裂的质量。比如在前面文章GBDT的介绍里,我们可以选择MSE,MAE来评价我们的分裂的质量,但是,我们所选择的分裂准则似乎不总是和我们的损失函数有关,因为这种选择是启发式的。
比如,在分类任务里面,损失函数可以选择logloss,分裂准确选择MSE,这样看来,似乎分裂的好坏和我们的损失并没有直接挂钩。
但是,在xgboost里面,我们的分裂准则是直接与损失函数挂钩的准则,这个也是xgboost和GBDT一个很不一样的地方。
具体来说,xgboost选择这个准则,计算增益 Gain G a i n
Gain=12[G2LH2L+λ+G2RH2R+λ−(GL+GR)2(HL+HR)2+λ]−γ(10) (10) G a i n = 1 2 [ G L 2 H L 2 + λ + G R 2 H R 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] − γ
其实选择这个作为准则的原因很简单也很直观。
我们这样考虑。由(9)式知道,对于一个结点,假设我们不分裂的话。
此时损失为: (GL+GR)2(HL+HR)2+λ ( G L + G R ) 2 ( H L + H R ) 2 + λ
假设在这个节点分裂的话,分裂之后左右叶子节点的损失分别为: G2LH2L+λ G L 2 H L 2 + λ 、 G2RH2R+λ G R 2 H R 2 + λ 。
既然要分裂的时候,我们当然是选择分裂成左右子节点后,损失减少的最多(或者看回(9)式,由于前面的负号,所以欲求(9)的最小值,其实就是求(10)的最大值)
也就是找到一种分裂有: Max([G2LH2L+λ+G2RH2R+λ−(GL+GR)2(HL+HR)2+λ]) M a x ( [ G L 2 H L 2 + λ + G R 2 H R 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] ) 。
那么 γ γ 的作用是什么呢?利用 γ γ 可以控制树的复杂度,进一步来说,利用 γ γ 来作为阈值,只有大于 γ γ 时候才选择分裂。这个其实起到预剪枝的作用。
最后就是如何得到左右子节点的样本集合?这个和普通的树一样,都是通过遍历特征所有取值,逐个尝试。
至此,我们把xgboost的基本原理阐述了一遍。我们总结一下,其实就是做了以下几件事情。
1.在损失函数的基础上加入了正则项。
2.对目标函数进行二阶泰勒展开。
3.利用推导得到的表达式作为分裂准确,来构建每一颗树。
xgboost算法流程总结
xgboost核心部分的算法流程图如下。
(这里的m貌似是d)

手动计算还原xgboost的过程
上面,我只是简单的阐述整个流程,有一些细节的地方可能都说的不太清楚,我以一个简单的UCI数据集,一步一步的和大家演算整个xgboost的过程。
数据集的样本条数只有15条,2个特征。具体如下:
| ID | x1 | x2 | y |
|---|---|---|---|
| 1 | 1 | -5 | 0 |
| 2 | 2 | 5 | 0 |
| 3 | 3 | -2 | 1 |
| 4 | 1 | 2 | 1 |
| 5 | 2 | 0 | 1 |
| 6 | 6 | -5 | 1 |
| 7 | 7 | 5 | 1 |
| 8 | 6 | -2 | 0 |
| 9 | 7 | 2 | 0 |
| 10 | 6 | 0 | 1 |
| 11 | 8 | -5 | 1 |
| 12 | 9 | 5 | 1 |
| 13 | 10 | -2 | 0 |
| 14 | 8 | 2 | 0 |
| 15 | 9 | 0 | 1 |
这里为了简单起见,树的深度设置为3(max_depth=3),树的颗数设置为2(num_boost_round=2),学习率为0.1(eta=0.1)。
另外再设置两个正则的参数, λ=1 λ = 1 , γ=0 γ = 0 。
损失函数选择logloss。
由于后面需要用到logloss的一阶导数以及二阶导数,这里先简单推导一下。
L(yi,ŷ i)=yiln(1+e−ŷ i)+(1−yi)ln(1+eŷ i) L ( y i , y ^ i ) = y i l n ( 1 + e − y ^ i ) + ( 1 − y i ) l n ( 1 + e y ^ i )
两边对 ŷ i y ^ i 求一阶导数。
L′(yi,ŷ i)=yi−e−ŷ i1+e−ŷ i+(1−yi)eŷ i1+eŷ i L ′ ( y i , y ^ i ) = y i − e − y ^ i 1 + e − y ^ i + ( 1 − y i ) e y ^ i 1 + e y ^ i
==> L′(yi,ŷ i)=yi−11+eŷ i+(1−yi)11+e−ŷ i L ′ ( y i , y ^ i ) = y i − 1 1 + e y ^ i + ( 1 − y i ) 1 1 + e − y ^ i
==> L′(yi,ŷ i)=yi∗(yi,pred−1)+(1−yi)∗yi,pred L ′ ( y i , y ^ i ) = y i ∗ ( y i , p r e d − 1 ) + ( 1 − y i ) ∗ y i , p r e d
==> L′(yi,ŷ i)=yi,pred−yi L ′ ( y i , y ^ i ) = y i , p r e d − y i ,其中 yi,pred=11+e−ŷ i y i , p r e d = 1 1 + e − y ^ i
在一阶导的基础上再求一次有(其实就是sigmod函数求导)
L″(yi,ŷ i)=yi,pred∗(1−yi,pred) L ″ ( y i , y ^ i ) = y i , p r e d ∗ ( 1 − y i , p r e d )
所以样本的一阶导数值 gi=yi,pred−yi(11) (11) g i = y i , p r e d − y i
样本的二阶导数值 hi=yi,pred∗(1−yi,pred)(12) (12) h i = y i , p r e d ∗ ( 1 − y i , p r e d )
下面就是xgboost利用上面的参数拟合这个数据集的过程:
建立第一颗树(k=1)
建树的时候从根节点开始(Top-down greedy),在根节点上的样本有ID1~ID15。那么回顾xgboost的算法流程,我们需要在根节点处进行分裂,分裂的时候需要计算式子(10)。
Gain=12[G2LH2L+λ+G2RH2R+λ−(GL+GR)2(HL+HR)2+λ]−γ(10) (10) G a i n = 1 2 [ G L 2 H L 2 + λ + G R 2 H R 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] − γ
那么式子(10)表达是:在结点处把样本分成左子结点和右子结点两个集合。分别求两个集合的 GL G L 、 HL H L 、 GR G R 、 HR H R ,然后计算增益 Gain G a i n 。
而这里,我其实可以先计算每个样本的一阶导数值和二阶导数值,即按照式子(11)和(12)计算,但是这里你可能碰到了一个问题,那就是第一颗树的时候每个样本的预测的概率 yi,pred y i , p r e d 是多少?这里和GBDT一样,应该说和所有的Boosting算法一样,都需要一个初始值。而在xgboost里面,对于分类任务只需要初始化为(0,1)中的任意一个数都可以。具体来说就是参数base_score。(其默认值是0.5)
(值得注意的是base_score是一个经过sigmod映射的值,可以理解为一个概率值,提这个原因是后面建第二颗树会用到,需要注意这个细节)
这里我们也设base_score=0.5。然后我们就可以计算每个样本的一阶导数值和二阶导数值了。具体如下表:

比如说对于ID=1样本, g1=y1,pred−y1=0.5−0=0.5 g 1 = y 1 , p r e d − y 1 = 0.5 − 0 = 0.5 。
h1=y1,pred∗(1−y1,pred)=0.5∗(1−0.5)=0.25 h 1 = y 1 , p r e d ∗ ( 1 − y 1 , p r e d ) = 0.5 ∗ ( 1 − 0.5 ) = 0.25
那么把样本如何分成两个集合呢?这里就是上面说到的选取一个最佳的特征以及分裂点使得 Gain G a i n 最大。
比如说对于特征x1,一共有[1,2,3,6,7,8,9,10]8种取值。可以得到以下这么多划分方式。
以1为划分时(x1<1):
左子节点包含的样本 IL I L =[]
右子节点包含的样本 IR I R =[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]
那么左子节点为空, GL=0 G L = 0 和 HL=0 H L = 0
右子节点的一阶导数和:
GR=∑(i∈IR)gi=(0.5+0.5+....−0.5)=−1.5 G R = ∑ ( i ∈ I R ) g i = ( 0.5 + 0.5 + . . . . − 0.5 ) = − 1.5
右子节点的二阶导数和:
HR=∑(i∈IR)hi=(0.25+0.25…0.25)=3.75 H R = ∑ ( i ∈ I R ) h i = ( 0.25 + 0.25…0.25 ) = 3.75
最后我们在计算一下增益Gain,可以有得到 Gain=0 G a i n = 0 。
计算出来发现Gain=0,不用惊讶,因为左子结点为空,也就是这次分裂把全部样本都归到右子结点,这个和没分裂有啥区别?所以,分裂的时候每个结点至少有一个样本。
下面,我再计算当以2划分时的增益Gain。
以2为划分时(x1<2):
左子结点包含的样本 IL I L =[1,4]
右子节点包含的样本 IR I R =[2,3,5,6,7,8,9,10,11,12,13,14,15]
左子结点的一阶导数:
GL=∑(i∈IL)gi=(0.5−0.5)=0 G L = ∑ ( i ∈ I L ) g i = ( 0.5 − 0.5 ) = 0
右子结点的二阶导数和:
HL=∑(i∈IL)hi=(0.25+0.25)=0.5 H L = ∑ ( i ∈ I L ) h i = ( 0.25 + 0.25 ) = 0.5
右子结点的一阶导数和:
GR=∑(i∈IR)gi=−1.5 G R = ∑ ( i ∈ I R ) g i = − 1.5
右子结点的二阶导数和:
HR=∑(i∈IR)hi=3.25 H R = ∑ ( i ∈ I R ) h i = 3.25
最后计算一下增益Gain:
Gain=[G2LH2L+λ+G2LH2L+λ−(GL+GR)2(HL+HR)2+λ]=0.0557275541796 G a i n = [ G L 2 H L 2 + λ + G L 2 H L 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] = 0.0557275541796
以3为划分时(x1<3):
左子节点包含的样本ID=[1,2,4,5]
右子节点包含的样本ID=[3,6,7,8,9,10,11,12,13,14,15]
左子结点的一阶导数:
GL=∑(i∈IL)gi=0 G L = ∑ ( i ∈ I L ) g i = 0
右子结点的二阶导数和:
HL=∑(i∈IL)hi=1 H L = ∑ ( i ∈ I L ) h i = 1
右子结点的一阶导数和:
GR=∑(i∈IR)gi=−1.5 G R = ∑ ( i ∈ I R ) g i = − 1.5
右子结点的二阶导数和:
HR=∑(i∈IR)hi=2.75 H R = ∑ ( i ∈ I R ) h i = 2.75
最后计算一下增益Gain:
Gain=[G2LH2L+λ+G2LH2L+λ−(GL+GR)2(HL+HR)2+λ]=0.126315789474 G a i n = [ G L 2 H L 2 + λ + G L 2 H L 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] = 0.126315789474
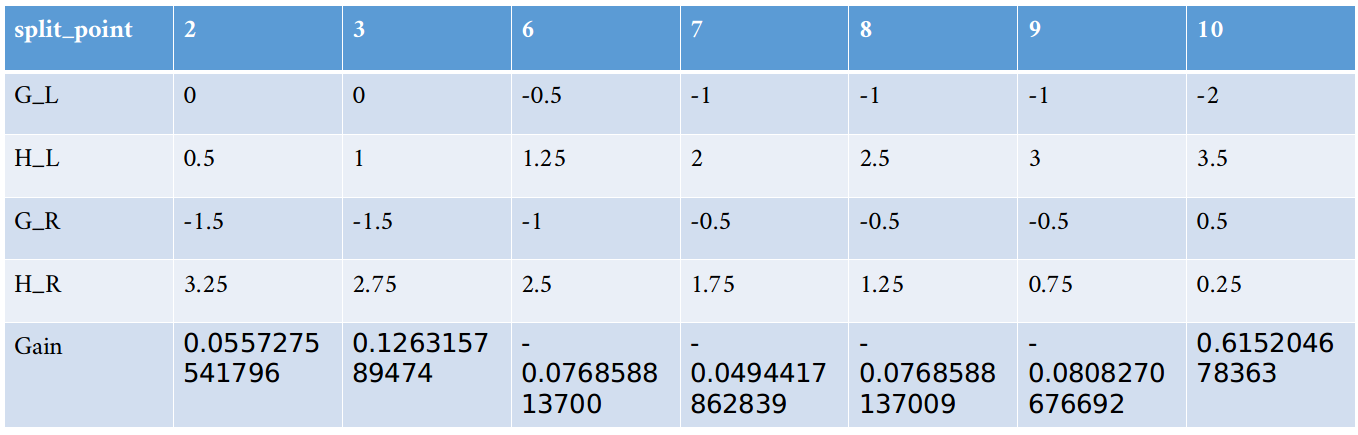
其他的值[6,7,8,9,10]类似,计算归总到下面表,供大家参考(如果错漏请和我说一下)
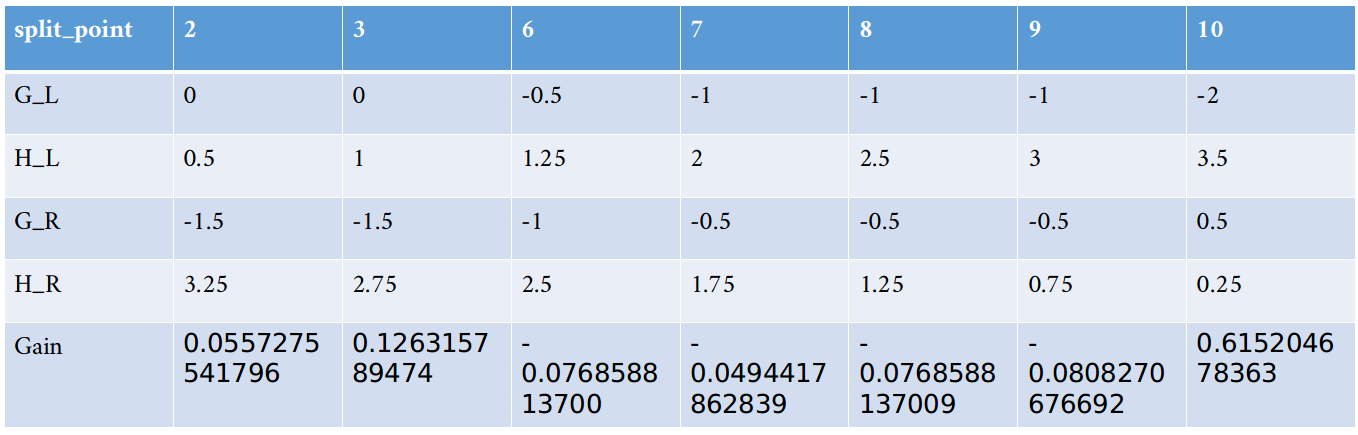
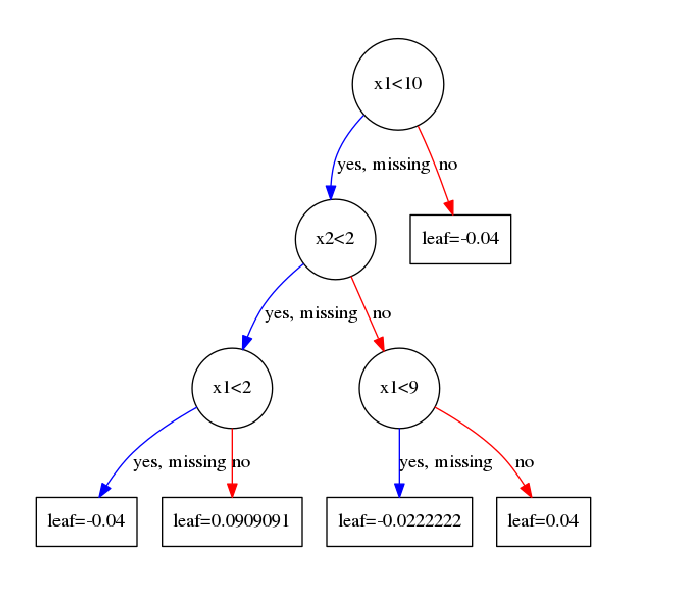
从上表我们可以到,如果特征x1以x1<10分裂时可以得到最大的增益0.615205。
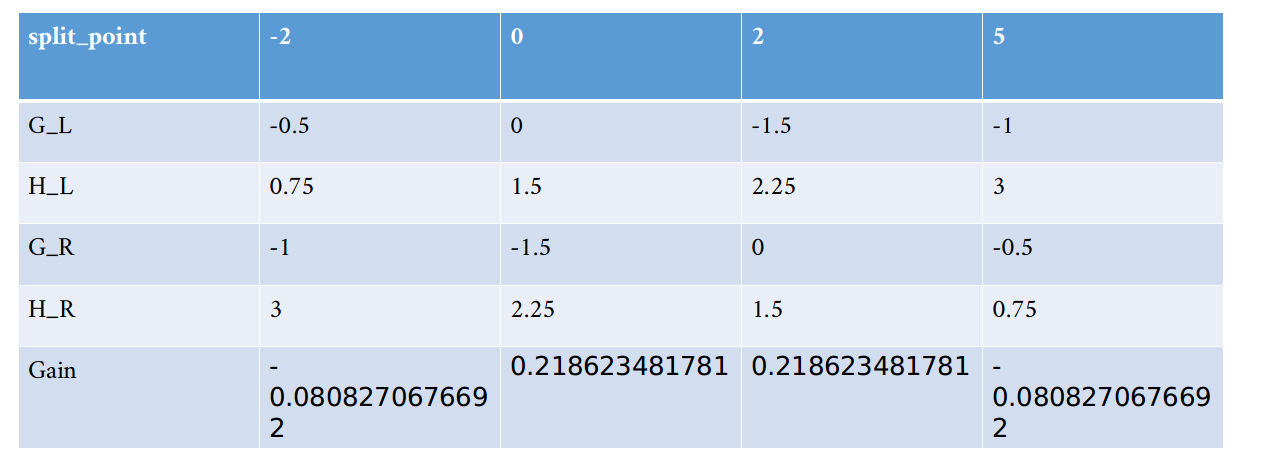
按照算法的流程,这个时候需要遍历下一个特征x2,对于特征x2也是重复上面这些步骤,可以得到类似的表如下,供大家参考。
可以看到,以x2特征来分裂时,最大的增益是0.2186<0.615205。所以在根节点处,我们以x1<10来进行分裂。
由于我设置的最大深度是3,此时只有1层,所以还需要继续往下分裂。
左子节点的样本集合 IL=[1,2,3,4,5,6,7,8,9,10,11,12,14,15] I L = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 14 , 15 ]
右子节点的样本集合 IR=[13] I R = [ 13 ]
右子节点此时只剩一个样本,不需要分裂了,也就是已经是叶子结点。可以计算其对应的叶子结点值了,按照公式(8):
w∗=−GjHj+λ(8) (8) w ∗ = − G j H j + λ
w1=−GRHR+λ=−g13h13+1=−0.51+0.25=−0.4 w 1 = − G R H R + λ = − g 13 h 13 + 1 = − 0.5 1 + 0.25 = − 0.4
那么下面就是对左子结点 IL I L 进行分裂。分裂的时候把此时的结点看成根节点,其实就是循环上面的过程,同样也是需要遍历所有特征(x1,x2)的所有取值作为分裂点,选取增益最大的点。
这里为了说的比较清晰,也重复一下上面的过程:
此时样本有 I=[1,2,3,4,5,6,7,8,9,10,11,12,14,15] I = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 14 , 15 ]
先考虑特征x1,此时x1的取值有[1, 2, 3, 6, 7, 8, 9]
以1为分裂Gain=0。
以2为划分时(x1<2):
左子结点包含的样本 IL I L =[1,4]
右子结点包含的样本 IR I R =[2,3,5,6,7,8,9,10,11,12,14,15]
左子结点的一阶导数:
GL=∑(i∈IL)gi=(0.5−0.5)=0 G L = ∑ ( i ∈ I L ) g i = ( 0.5 − 0.5 ) = 0
右子结点的二阶导数和:
HL=∑(i∈IL)hi=(0.25+0.25)=0.5 H L = ∑ ( i ∈ I L ) h i = ( 0.25 + 0.25 ) = 0.5
右子结点的一阶导数和:
GR=∑(i∈IR)gi=−2 G R = ∑ ( i ∈ I R ) g i = − 2
右子结点的二阶导数和:
HR=∑(i∈IR)hi=3 H R = ∑ ( i ∈ I R ) h i = 3
最后计算一下增益Gain:
Gain=[G2LH2L+λ+G2LH2L+λ−(GL+GR)2(HL+HR)2+λ]=0.111111111111 G a i n = [ G L 2 H L 2 + λ + G L 2 H L 2 + λ − ( G L + G R ) 2 ( H L + H R ) 2 + λ ] = 0.111111111111
其他的同理,最后所有值都遍历完后可以得到下表:
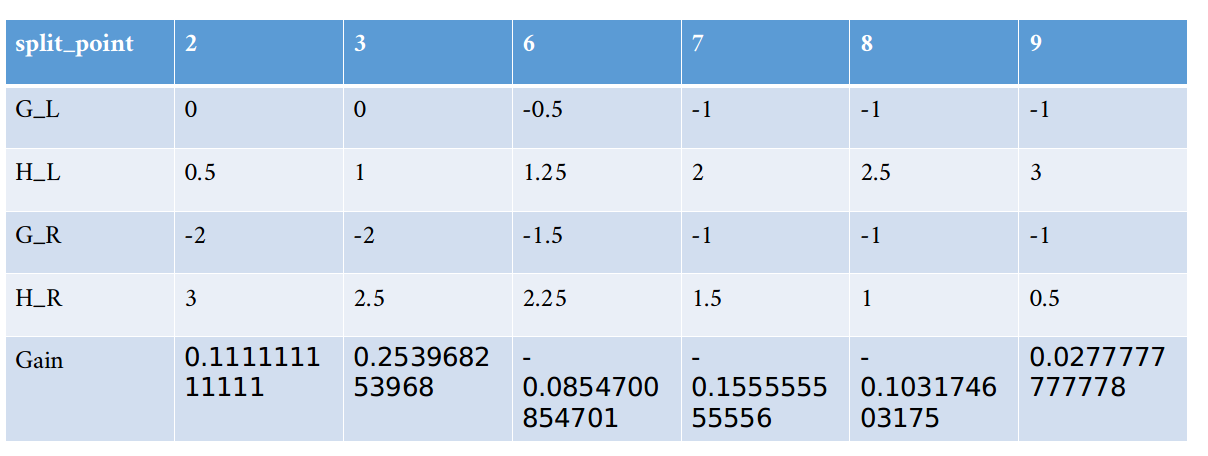
可以看到,x1选择x<3时能够获得最大的增益0.2539。
同理,我们对x2再次遍历可以得到下表:
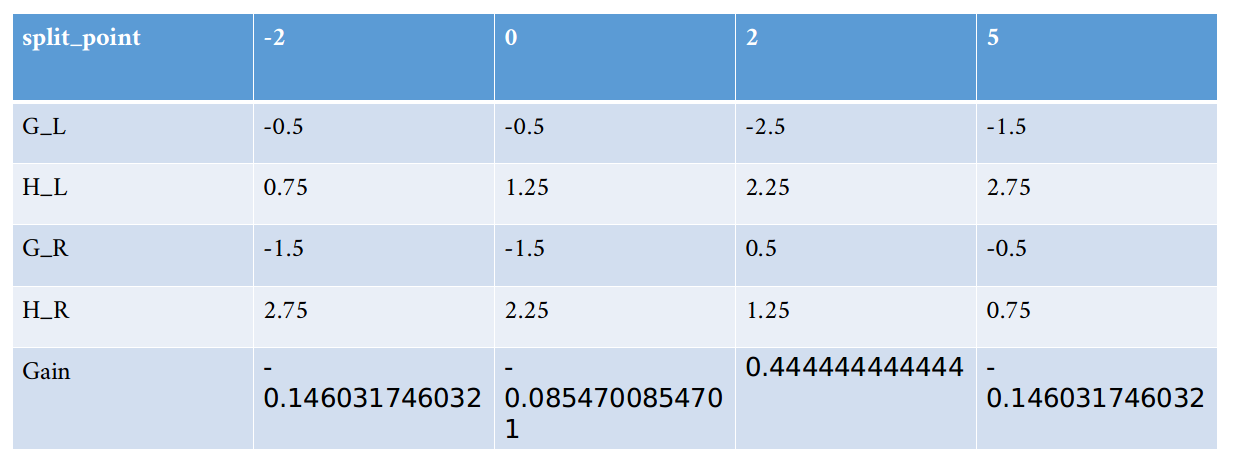
可以看到x2在x2<2时分裂可以获得最大的增益0.4444。
比较知道,应该选择x2<2作为分裂点。
分裂后左右叶子结点的集合如下:
左子节点的样本集合 IL=[1,3,5,6,8,10,11,15] I L = [ 1 , 3 , 5 , 6 , 8 , 10 , 11 , 15 ]
右子节点的样本集合 IR=[2,4,7,9,12,14] I R = [ 2 , 4 , 7 , 9 , 12 , 14 ]
然后继续对 IL I L 和 IR I R 进行分裂。这里就不在啰嗦了。这里直接给出第一个树的结构。
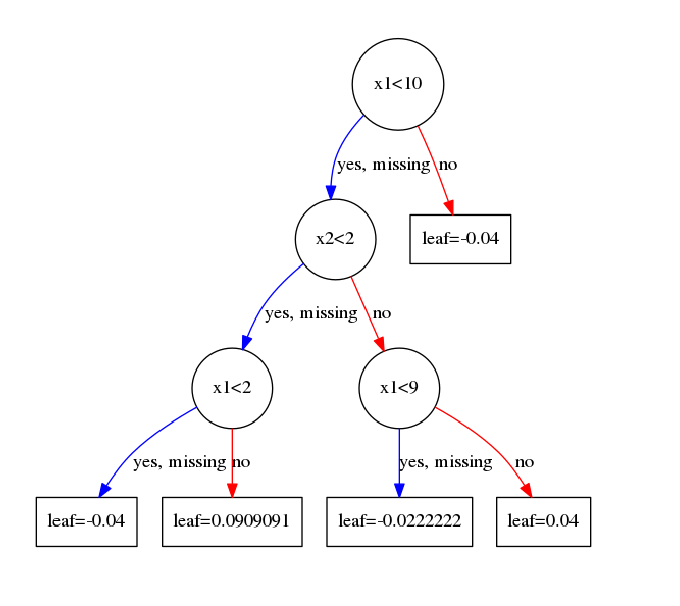
注意:
这里有的人可能对叶子结点取值感到困惑。为何我算出来的是-0.4,可图上却是-0.04?
这里以最左边的一个叶子结点为例,展示一下计算的过程。
落在最左边这个叶子结点上的样本有 I=[1] I = [ 1 ]
所以由公式: w∗=−GjHj+λ(8) (8) w ∗ = − G j H j + λ
w2=−GRHR+λ=−g1h1+1=−0.51+0.25=−0.4 w 2 = − G R H R + λ = − g 1 h 1 + 1 = − 0.5 1 + 0.25 = − 0.4
落在从左边数起第二个叶子结点上的样本有 I=[3,5,6,8,10,11,15] I = [ 3 , 5 , 6 , 8 , 10 , 11 , 15 ]
w3=−GRHR+λ=−g3+g5+g6+g8+g10+g11+g15h3+h5+h6+h8+h10+h11+h15+1=−−2.51+1.75=0.909 w 3 = − G R H R + λ = − g 3 + g 5 + g 6 + g 8 + g 10 + g 11 + g 15 h 3 + h 5 + h 6 + h 8 + h 10 + h 11 + h 15 + 1 = − − 2.5 1 + 1.75 = 0.909
到这里完全没有问题,但是为什么和图上的不一样呢?这里其实和我们在GBDT中的处理一样,我们会以一个学习率来乘这个值,当完全取-0.4时说明学习率取1,这个时候很容易过拟合。所以每次得到叶子结点的值后需要乘上学习率eta,在前面我们已经设置了学习率是0.1。这里也是GBDT和xgboost一个共同点,大家都是通过学习率来进行Shrinkage,以减少过拟合的风险。
至此,我们学习完了第一颗树。
建立第2颗树(k=2)
这里,我们开始拟合我们第二颗树。其实过程和第一颗树完全一样。只不过对于 yi,pred y i , p r e d 需要进行更新,也就是拟合第二颗树是在第一颗树预测的结果基础上。这和GBDT一样,因为大家都是Boosting思想的算法。
在第一颗树里面由于前面没有树,所以初始 yi,pred=0.5 y i , p r e d = 0.5 (玩家自己设置的)
假设此时,模型只有这一颗树(K=1),那么模型对样例 xi x i 进行预测时,预测的结果表达是什么呢?
由加法模型
yKi=∑Kk=0fk(xi)(13) (13) y i K = ∑ k = 0 K f k ( x i )
y1i=f0(xi)+f1(xi)(14) (14) y i 1 = f 0 ( x i ) + f 1 ( x i )
f1(xi) f 1 ( x i ) 的值是样例 xi x i 落在第一棵树上的叶子结点值。那 f0(xi) f 0 ( x i ) 是什么呢?这里就涉及前面提到一个问题base_score是一个经过sigmod映射后的值(因为选择使用Logloss做损失函数,概率 p=11+e−x p = 1 1 + e − x )
所以需要将0.5逆运算 x=lny1−y x = l n y 1 − y 后可以得到 f0(xi)=0 f 0 ( x i ) = 0 。
所以第一颗树预测的结果就是 y1i=f0(xi)+f1(xi)=0+wq(xi) y i 1 = f 0 ( x i ) + f 1 ( x i ) = 0 + w q ( x i )
(其实当训练次数K足够多的时候,初始化这个值几乎不起作用的,这个在官网文档上有说明)
所以,我们可以得到第一棵树预测的结果为下表(预测后将其映射成概率)
| ID | yi,pred y i , p r e d |
|---|---|
| 1 | 0.490001 |
| 2 | 0.494445 |
| 3 | 0.522712 |
| 4 | 0.494445 |
| 5 | 0.522712 |
| 6 | 0.522712 |
| 7 | 0.494445 |
| 8 | 0.522712 |
| 9 | 0.494445 |
| 10 | 0.522712 |
| 11 | 0.522712 |
| 12 | 0.509999 |
| 13 | 0.490001 |
| 14 | 0.494445 |
| 15 | 0.522712 |
比如对于ID=1的样本,其落在-0.04这个节点。那么经过sigmod映射后的值为
p1,pred=11+e(0+0.04)=0.490001 p 1 , p r e d = 1 1 + e ( 0 + 0.04 ) = 0.490001
有了这个之后,我们就可以计算所有样本新的一阶导数和二阶导数的值了。具体如下表:
| ID | gi g i | hi h i |
|---|---|---|
| 1 | 0.490001320839 | 0.249900026415 |
| 2 | 0.494444668293 | 0.24996913829 |
| 3 | -0.477288365364 | 0.249484181652 |
| 4 | -0.505555331707 | 0.24996913829 |
| 5 | -0.477288365364 | 0.249484181652 |
| 6 | -0.477288365364 | 0.249484181652 |
| 7 | -0.505555331707 | 0.24996913829 |
| 8 | 0.522711634636 | 0.249484181652 |
| 9 | 0.494444668293 | 0.24996913829 |
| 10 | -0.477288365364 | 0.249484181652 |
| 11 | -0.477288365364 | 0.249484181652 |
| 12 | -0.490001320839 | 0.249900026415 |
| 13 | 0.490001320839 | 0.249900026415 |
| 14 | 0.494444668293 | 0.24996913829 |
| 15 | -0.477288365364 | 0.249484181652 |
之后,我们和第一颗树建立的时候一样以公式(10)去建树。
拟合完后第二颗树如下图:
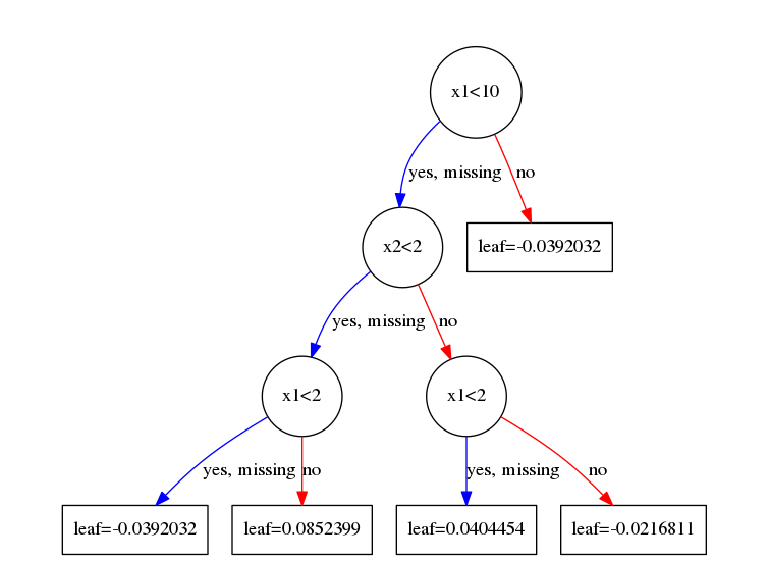
后面的所有过程都是重复这个过程,这里就不再啰嗦了。
至此,整个xgboost的训练过程已经完了,但是其实里面还有一些细节的东西,下面已单独一个部分来说明这个部分。
训练过程的细节-参数min_child_weight
在选择分裂的时候,我们是选取分裂点为一个最大的增益Gain。但是其实在xgboost里面有一个参数叫min_child_weight。
我先来看看官网对这个参数的解释:

可能看完大概知道这个权重指的应该是二阶导数,但是具体是怎么一回事呢。
其实是这样的:
在前面建立第一颗的根结点的时候,我们得到特征x1每个分裂点的这个表:
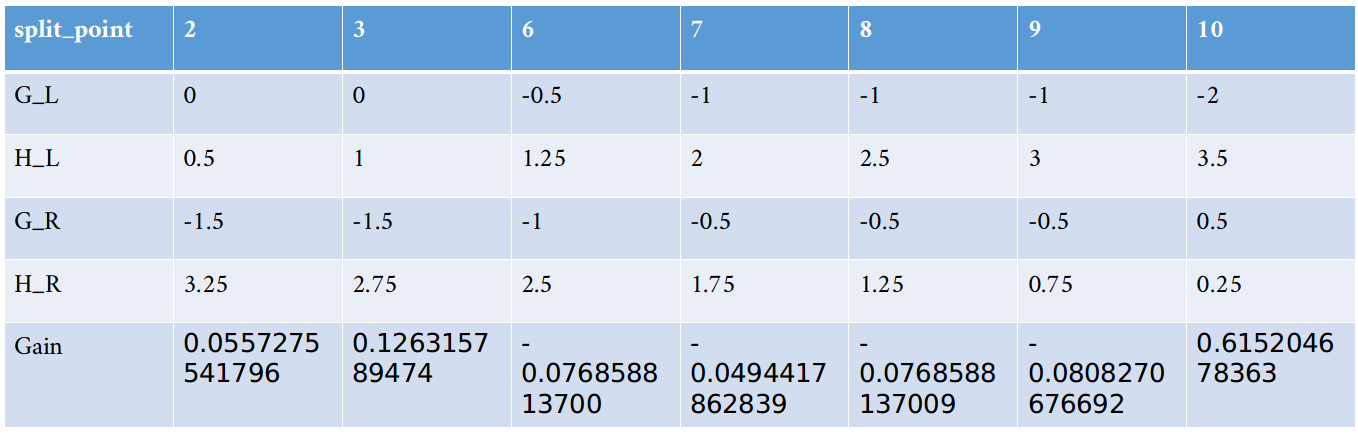
我们当时选取了x1<10作为分裂特征,但是!这个是有一个前提的,那就是参数min_child_weight <min(HL,HR) < m i n ( H L , H R ) <script type=”math/tex” id=”MathJax-Element-152″> 如果我们设置min_child_weight=0.26的时候,分裂点就不是选择10,而是放弃这个最大增益,考虑次最大增益。如果次最大增益也不满足min_child_weight <min(HL,HR) < m i n ( H L , H R ) <script type=”math/tex” id=”MathJax-Element-153″>
训练过程细节-参数 γ γ
在前面例子里,我们把 γ γ 设成了0,如果我们设置成其他值比如1的话,在考虑最大增益的同时,也要考虑这个最大的增益是否比 γ γ 大,如果小于 γ γ 则不进行分裂(预剪枝)。
训练过程细节-缺失值的处理
我前面放了许多树的结构图,上面有一个方向是missing,其实这个是xgboost自动学习的一个对缺失值处理的方向。可以看到,所有的missing方向都是指向右子结点,这是因为我们数据集中没有缺失值。
xgboost对缺失值的处理思想很简单,具体看下面的算法流程:

首先需要注意到两个集合一个是 I I ,其包含所有的样本(包括含空缺值的样本)。
Ik
是不包含空缺值样本的集合。
在计算总的 G和H G 和 H 时用的是 I I !!也就说空缺值的一阶导数和二阶导数已经包含进去了。
可以看到内层循环里面有两个for,第一个for是从把特征取值从小到大排序,然后从小到大进行扫描,这个时候在计算
GR的时候是用总的G减去GL
, HR H R 也是同样用总的H减去 HL H L ,这意味着把空缺样本归到了右子结点。
第二个for相反过来,把空缺样本归到了左子结点。
只要比较这两次最大增益出现在第一个for中还是第二个for中就可以知道对于空缺值的分裂方向,这就是xgboost如何学习空缺值的思想。
训练过程细节-近似贪婪算法
在前面,我们可以看到选取特征的时候是遍历了每个特征所有可能的取值,但是实际上,我们可以使用近似的方法来进行特征分裂的选择,具体算法流程:

xgboost如何用于特征选择?
相信很多做过数据挖掘比赛的人都利用xgboost来做特征选择。
一般我们调用xgb库的get_fscore()。但其实xgboost里面有三个指标用于对特征进行评价,而get_fscore()只是其中一个指标weight。
这个指标大部分玩家都很熟悉,其代表着某个特征被选作分裂的次数。
比如在前面举的例子里,我们得到这两颗树:

可以看到特征x1被选作分裂点的次数为6,x2被选做分裂点的次数为2。
get_fscore()就是返回这个指标。
而xgboost还提供了另外两个指标,一个叫gain,一个叫cover。可以利用get_score()来选择。
那么gain是指什么呢?其代表着某个特征的平均增益。
比如,特征x1被选了6次作为分裂的特征,每次的增益假如为Gain1,Gain2,…Gain6,那么其平均增益为 (Gain1+Gain2+...Gain3)/6 ( G a i n 1 + G a i n 2 + . . . G a i n 3 ) / 6
最后一个cover指的是什么呢?其代表着每个特征在分裂时结点处的平均二阶导数。
这个为了加深理解,我举个例子,这个例子用的还是UCI数据集,不过此时只有max_depth=2,num_boost_round=1(不想再画表了。。太累了。。)
建树完之后,其结构如上。
在第一个结点分裂时,x1的特征增益表如下:
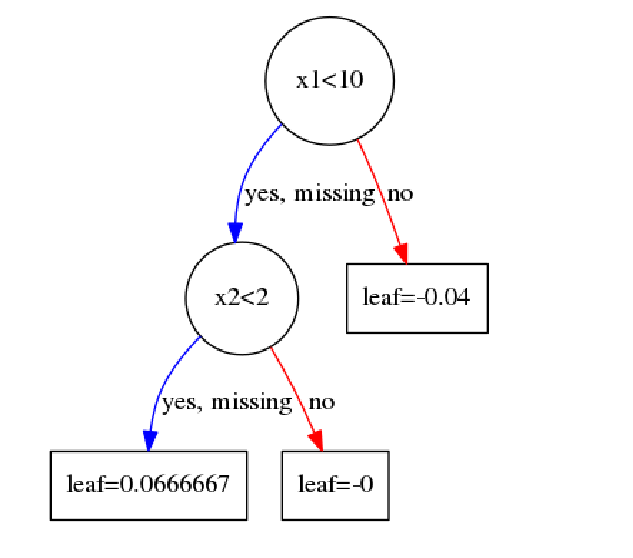
第二个结点分裂时,x2的特征增益表如下:
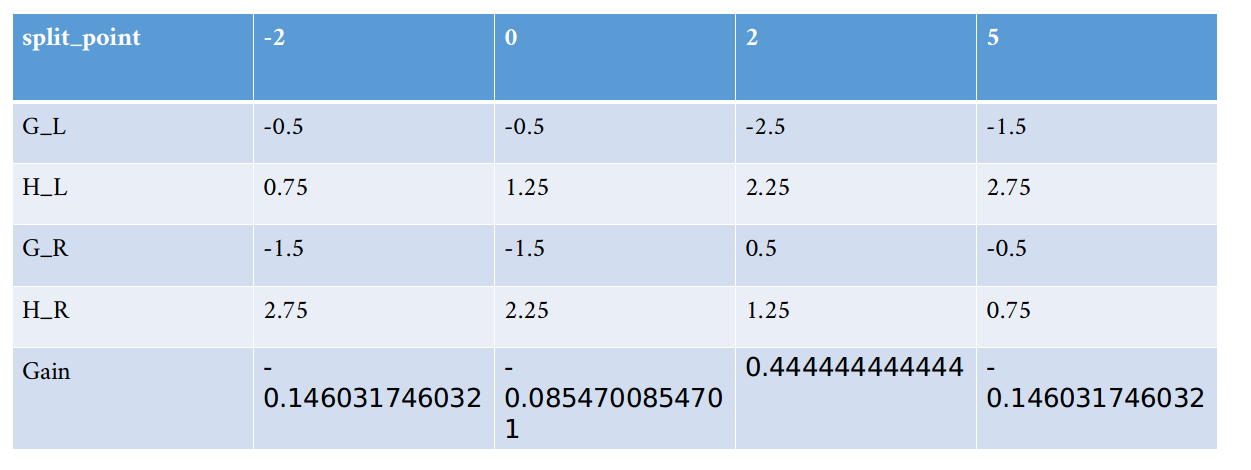
那么特征x1的cover是如下计算的:
在x1在第一个结点处被选择分裂特征,此时结点处的总二阶导数 G=3.75 G = 3.75
故x1的cover值为3.75。
这里x1只是被分裂了一次,如果后续还有就是求平均。
同样地,x2的cover值为3.5。
举这个例子就是先给大家说一下何为平均二阶导数。
其实为什么需要选择二阶导数?这个二阶导数背后有什么意义吗?我们先看看官网对cover的定义:
‘cover’ – the average coverage of the feature when it is used in trees。大概的意义就是特征覆盖了多少个样本。
这里,我们不妨假设损失函数是mse,也就是 0.5∗(yi−ypred)2 0.5 ∗ ( y i − y p r e d ) 2 ,我们求其二阶导数,很容易得到为常数1。也就是每个样本对应的二阶导数都是1,那么这个cover指标不就是意味着,在某个特征在某个结点进行分裂时所覆盖的样本个数吗?
xgboost与传统GBDT的区别与联系?
至此,我们来简单的总结一下xgboost和GBDT的区别以及联系。
区别:
1.xgboost和GBDT的一个区别在于目标函数上。
在xgboost中,损失函数+正则项。
GBDT中,只有损失函数。
2.xgboost中利用二阶导数的信息,而GBDT只利用了一阶导数。
3.xgboost在建树的时候利用的准则来源于目标函数推导,而GBDT建树利用的是启发式准则。(这一点,我个人认为是xgboost牛B的所在,也是为啥要费劲二阶泰勒展开)
4.xgboost中可以自动处理空缺值,自动学习空缺值的分裂方向,GBDT(sklearn版本)不允许包含空缺值。
5.其他若干工程实现上的不同(这个由于本文没有涉及就不说了)
联系:
1.xgboost和GBDT的学习过程都是一样的,都是基于Boosting的思想,先学习前n-1个学习器,然后基于前n-1个学习器学习第n个学习器。(Boosting)
2.建树过程都利用了损失函数的导数信息(Gradient),只是大家利用的方式不一样而已。
3.都使用了学习率来进行Shrinkage,从前面我们能看到不管是GBDT还是xgboost,我们都会利用学习率对拟合结果做缩减以减少过拟合的风险。
4.其他本文没涉及到的共同点。。
至此,关于xgboost的一些简单知识就算说完了,希望对大家的学习有帮助。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134653.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
