大家好,又见面了,我是你们的朋友全栈君。
【对于一个给定的算法,通常要评估其正确性和运行效率的高低。算法的正确性评估不在本文范围之内,本文主要讨论从算法的时间复杂度特性去评估算法的优劣。】
如何衡量一个算法的好坏呢?
显然,选用的算法应该是正确的(算法的正确性不在此论述)。除此之外,通常有三个方面的考虑:
(1)算法在执行过程中所消耗的时间;
(2)算法在执行过程中所占资源的大小,例如,占用内存空间的大小;
(3)算法的易理解性、易实现性和易验证性等等。
本文主要讨论算法的时间特性,并给出算法在时间复杂度上的度量指标。
在各种不同的算法中,若算法语句的执行次数为常数,则算法的时间复杂度为O(1),按数量级递增排列,常见的时间复杂度量有:
(1)O(1):常量阶,运行时间为常量
(2)O(logn):对数阶,如二分搜索算法
(3)O(n):线性阶,如n个数内找最大值
(4)O(nlogn):对数阶,如快速排序算法
(5)O(n^2):平方阶,如选择排序,冒泡排序
(6)O(n^3):立方阶,如两个n阶矩阵的乘法运算
(7)O(2^n):指数阶,如n个元素集合的所有子集的算法
(8)O(n!):阶乘阶,如n个元素全部排列的算法
下图给出了随着n的变化,不同量级的时间复杂度变化曲线。
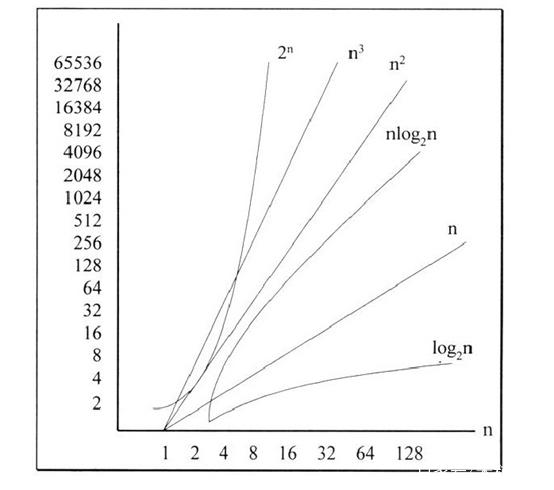

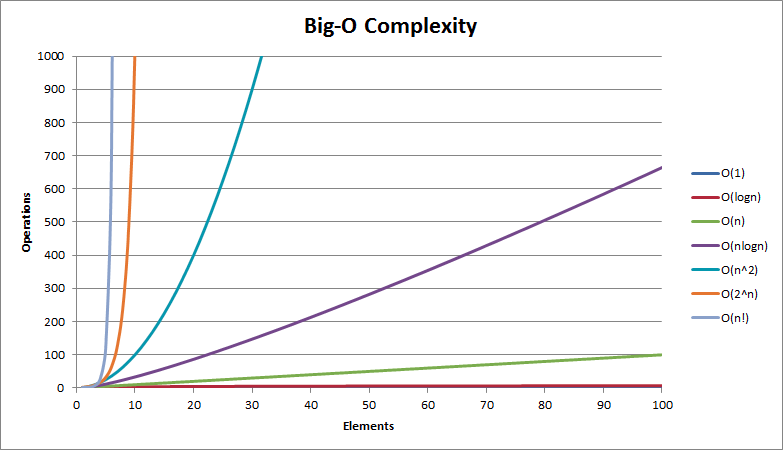
| 复杂度 | 10 | 20 | 50 | 100 | 1000 | 10000 | 100000 |
| O(1) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(log2(n)) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n*log2(n)) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n2) |
<1s |
<1s |
<1s |
<1s |
<1s |
2s |
3-4 min |
| O(n3) |
<1s |
<1s |
<1s |
<1s |
20s |
5 hours |
231 days |
| O(2n) |
<1s |
<1s |
260 days |
hangs |
hangs |
hangs |
hangs |
| O(n!) |
<1s |
hangs |
hangs |
hangs |
hangs |
hangs |
hangs |
| O(nn) |
3-4 min |
hangs |
hangs |
hangs |
hangs |
hangs |
hangs |
评估算法时间复杂度的具体步骤是:
(1)找出算法中重复执行次数最多的语句的频度来估算算法的时间复杂度;
(2)保留算法的最高次幂,忽略所有低次幂和高次幂的系数;
(3)将算法执行次数的数量级放入大Ο记号中。
以下对常见的算法时间复杂度度量进行举例说明:
(1)O(1):常量阶,操作的数量为常数,与输入的数据的规模无关。n = 1,000,000 -> 1-2 operations
temp=a;
a=b;
b=temp;用常数1来取代运行时间中所有加法常数;
上面语句共三条操作,单条操作的频度为1,即使他有成千上万条操作,也只是个较大常数,这一类的时间复杂度为O(1);
(2)O(logn):对数阶,如二分搜索算法。操作的数量与输入数据的规模 n 的比例是 log2 (n)。n = 1,000,000 -> 30 operations
比如: 1,3,5,6,7,9;找出7
如果全部遍历时间频度为n;
二分查找每次砍断一半,即为n/2;
随着查询次数的提升,频度变化作表:
查询次数 时间频度
1 n/2
2 n/2^2
3 n/2^3
k n/2^k
当最后找到7的时候时间频度则是1;
也就是:
n/2^k = 1;
n = 2^k;
k则是以2为底,n的对数,就是Log2N;
那么二分查找的时间复杂度就是O(Log2N);
(3)O(n):线性阶,如n个数内找最大值。操作的数量与输入数据的规模 n 成正比。n = 10,000 -> 5000 operations

这一类算法中操作次数和n正比线性增长。
(4)O(nlogn):对数阶,如快速排序算法
上面看了二分查找,是LogN的(LogN没写底数默认就是Log2N);
线性对数阶就是在LogN的基础上多了一个线性阶;
比如这么一个算法流程:
数组a和b,a的规模为n,遍历的同时对b进行二分查找,如下代码:
for(int i =0;i<n;i++)
{
binary_search(b);
}(5)O(n^2):平方阶,如选择排序,冒泡排序。操作的数量与输入数据的规模 n 的比例为二次平方。n = 500 -> 250,000 operations
long SumMN(int n, int m)
{
long sum = 0;
for (int x = 0; x < n; x++)
for (int y = 0; y < m; y++)
sum += x * y;
return sum;
}
(6)O(n^3):立方阶,如两个n阶矩阵的乘法运算。操作的数量与输入数据的规模 n 的比例为三次方。n = 200 -> 8,000,000 operations
long SumMNK(int n, int m,int k)
{
long sum = 0;
for (int x = 0; x < n; x++)
for (int y = 0; y < m; y++)
for(int z=0;z<k;z++)
sum += x * y*z;
return sum;
}
(7)O(2^n):指数阶,如n个元素集合的所有子集的算法。指数级的操作,快速的增长。n = 20 -> 1048576 operations
-
long long Fib(long long N) -
{
-
return (N < 3) ? 1 : Fib(N - 1) + Fib(N - 2); -
}
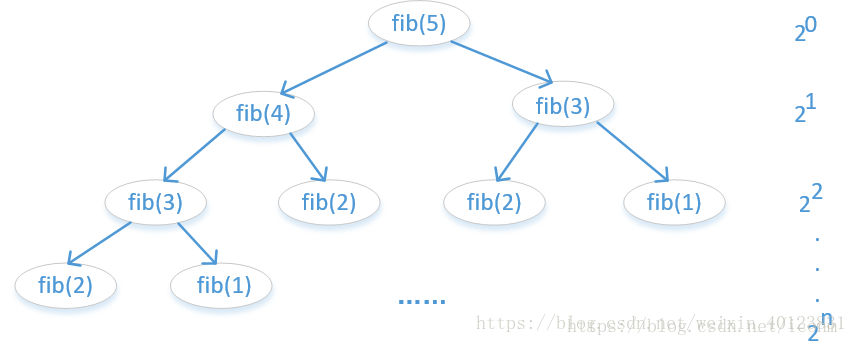
(8)O(n!):阶乘阶,如n个元素全部排列的算法
参考文献:
https://blog.csdn.net/user11223344abc/article/details/81485842
https://www.cnblogs.com/gaochundong/p/complexity_of_algorithms.html
https://baijiahao.baidu.com/s?id=1609024533531824968&wfr=spider&for=pc
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146396.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
