大家好,又见面了,我是你们的朋友全栈君。
FM
FM算法的提出旨在解决稀疏数据下的特征组合问题。
y = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n w i j x i x j , ( w 0 , w i , w i j ∈ R ) y=w_0+\sum\limits_{i=1}^n w_i x_i+\sum\limits_{i=1}^{n-1}\sum\limits_{j=i+1}^n w_{ij}x_i x_j,(w_0, w_i, w_{ij}\in R) y=w0+i=1∑nwixi+i=1∑n−1j=i+1∑nwijxixj,(w0,wi,wij∈R)
分解 w i j = < v i , v j > = ∑ k = 1 K v i k v j k \displaystyle w_{ij}=<v_i,v_j>=\sum\limits_{k=1}^{K}v_{ik}v_{jk} wij=<vi,vj>=k=1∑Kvikvjk
∑ i = 1 n − 1 ∑ j = i + 1 n w i j x i x j = 1 2 ( ∑ i = 1 n ∑ j = 1 n w i j x i x j − ∑ i = 1 n w i i x i 2 ) = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ k = 1 K v i k v j k x i x j − ∑ i = 1 n ∑ k = 1 K v i k 2 x i 2 ) \displaystyle\sum\limits_{i=1}^{n-1}\sum\limits_{j=i+1}^n w_{ij}x_i x_j=\frac{1}{2}\Big(\sum\limits_{i=1}^{n}\sum\limits_{j=1}^n w_{ij}x_i x_j-\sum\limits_{i=1}^n w_{ii}x^2_i\Big)=\frac{1}{2}\Big(\sum\limits_{i=1}^{n}\sum\limits_{j=1}^n \sum\limits_{k=1}^{K}v_{ik}v_{jk}x_i x_j-\sum\limits_{i=1}^n \sum\limits_{k=1}^{K}v^2_{ik}x^2_i\Big) i=1∑n−1j=i+1∑nwijxixj=21(i=1∑nj=1∑nwijxixj−i=1∑nwiixi2)=21(i=1∑nj=1∑nk=1∑Kvikvjkxixj−i=1∑nk=1∑Kvik2xi2)
= 1 2 ∑ k = 1 K ( ( ∑ i = 1 n v i k x i ) ( ∑ j = 1 n v j k x j ) − ∑ i = 1 n ( v i k x i ) 2 ) = 1 2 ∑ k = 1 K ( ( ∑ i = 1 n v i k x i ) 2 − ∑ i = 1 n ( v i k x i ) 2 ) \displaystyle=\frac{1}{2}\sum\limits_{k=1}^{K}\Big((\sum\limits_{i=1}^{n} v_{ik}x_i) (\sum\limits_{j=1}^n v_{jk}x_j)-\sum\limits_{i=1}^n (v_{ik}x_i)^2\Big)=\frac{1}{2}\sum\limits_{k=1}^{K}\Big((\sum\limits_{i=1}^{n} v_{ik}x_i)^2-\sum\limits_{i=1}^n (v_{ik}x_i)^2\Big) =21k=1∑K((i=1∑nvikxi)(j=1∑nvjkxj)−i=1∑n(vikxi)2)=21k=1∑K((i=1∑nvikxi)2−i=1∑n(vikxi)2)
其中 v i = ( v i 1 , v i 2 , ⋯   , v i K ) v_i=(v_{i1},v_{i2},\cdots,v_{iK}) vi=(vi1,vi2,⋯,viK)是第 i i i维特征的隐向量。【1】隐向量的长度为 k ( k < < n ) k(k<<n) k(k<<n),包含 k k k个描述特征的因子。由上可见,二次项的参数数量减少为 k n kn kn个,远少于多项式模型的参数数量。即通过矩阵分解,二次项可以化简,复杂度可以从 O ( k n 2 ) O(kn^2) O(kn2)优化到 O ( k n ) O(kn) O(kn)。【2】参数因子化使得 x h x i x_h x_i xhxi的参数和 x i x j x_i x_j xixj的参数不再是相互独立的,因此可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说, x h x i x_h x_i xhxi和 x i x j x_i x_j xixj的系数分别为 < v h , v i > <v_h,v_i> <vh,vi>和 < v i , v j > <v_i,v_j> <vi,vj>,它们之间有共同项 v i v_i vi。也就是说,所有包含“ x i x_i xi的非零组合特征”(存在某个 j ≠ i j\neq i j̸=i,使得 x i x j ≠ 0 x_i x_j\neq 0 xixj̸=0)的样本都可以用来学习隐向量 v i v_i vi,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中, w h i w_{hi} whi和 w i j w_{ij} wij是相互独立的。【3】以上包含二阶项的拟合函数,可以采用不同的损失函数用于解决回归、二分类等问题,比如可以采用MSE(Mean Square Error)损失函数来求解回归问题,也可以采用Hinge/Cross-Entropy损失来求解分类问题。当然,在进行二元分类时,FM的输出需要经过sigmoid变换,这与Logistic回归是一样的。
回归问题(MSE)
记样本的真实的标签为 y ^ \hat{y} y^,FM模型预测的标签为 y y y,训练集大小为 N N N,则
l o s s ( y ^ , y ) = 1 2 ∑ l = 1 N ( y ^ ( l ) − y ( l ) ) 2 = 1 2 ∑ l = 1 N { y ^ ( l ) − [ w 0 ( l ) + ∑ i = 1 n w i ( l ) x i + 1 2 ∑ k = 1 K ( ( ∑ i = 1 n v i k ( l ) x i ) 2 − ∑ i = 1 n ( v i k ( l ) x i ) 2 ) ] } \displaystyle loss(\hat{y},y)=\frac{1}{2}\sum\limits_{l=1}^{N}(\hat{y}^{(l)} – y^{(l)})^2=\frac{1}{2}\sum\limits_{l=1}^{N}\Big\{\hat{y}^{(l)}-\Big[w^{(l)}_0+\sum\limits_{i=1}^n w^{(l)}_i x_i+\frac{1}{2}\sum\limits_{k=1}^{K}\Big((\sum\limits_{i=1}^{n} v^{(l)}_{ik}x_i)^2-\sum\limits_{i=1}^n (v^{(l)}_{ik}x_i)^2\Big)\Big]\Big\} loss(y^,y)=21l=1∑N(y^(l)−y(l))2=21l=1∑N{
y^(l)−[w0(l)+i=1∑nwi(l)xi+21k=1∑K((i=1∑nvik(l)xi)2−i=1∑n(vik(l)xi)2)]}
求 导 : ∂ l o s s ( y ^ , y ) ∂ θ = ∑ l = 1 N ( y ^ ( l ) − y ( l ) ) ∂ y ( l ) ∂ θ 求导:\displaystyle\frac{\partial loss(\hat{y},y)}{\partial\theta}=\sum\limits_{l=1}^{N}(\hat{y}^{(l)} – y^{(l)})\frac{\partial y^{(l)}}{\partial\theta} 求导:∂θ∂loss(y^,y)=l=1∑N(y^(l)−y(l))∂θ∂y(l)
利 用 S G D 训 练 模 型 , 各 参 数 梯 度 : ∂ y ( l ) ∂ θ = { 1 , θ = w 0 x i , θ = w i x i ∑ j = 1 n v j , k x j − v i , k x i 2 , θ = v i , k 利用SGD训练模型,各参数梯度:\displaystyle\frac{\partial y^{(l)}}{\partial\theta}=\begin{cases}1, &\theta=w_0 \cr x_i, & \theta=w_i \cr x_i\sum\limits_{j=1}^n v_{j,k}x_j-v_{i,k}x^2_i,& \theta=v_{i,k}\end{cases} 利用SGD训练模型,各参数梯度:∂θ∂y(l)=⎩⎪⎪⎪⎨⎪⎪⎪⎧1,xi,xij=1∑nvj,kxj−vi,kxi2,θ=w0θ=wiθ=vi,k
分类问题(logloss)
记样本的真实的标签为 y ^ \hat{y} y^,FM模型预测的标签为 y y y,训练集大小为 N N N;当正负样本的标签分别为 + 1 +1 +1和 − 1 -1 −1时,交叉熵损失可以表示为
l o s s ( y ^ , y ) = ∑ l = 1 N − l n σ ( y ^ ( l ) y ( l ) ) = ∑ l = 1 N − l n 1 1 + e − y ^ ( l ) y ( l ) = ∑ l = 1 N − l n 1 1 + e − y ^ ( l ) [ w 0 ( l ) + ∑ i = 1 n w i ( l ) x i + 1 2 ∑ k = 1 K ( ( ∑ i = 1 n v i k ( l ) x i ) 2 − ∑ i = 1 n ( v i k ( l ) x i ) 2 ) ] \displaystyle loss(\hat{y},y)=\sum\limits_{l=1}^{N}-ln\sigma(\hat{y}^{(l)}y^{(l)})=\sum\limits_{l=1}^{N}-ln\frac{1}{1+e^{-\hat{y}^{(l)}y^{(l)}}}=\sum\limits_{l=1}^{N}-ln\frac{1}{1+e^{-\hat{y}^{(l)}\Big[w^{(l)}_0+\sum\limits_{i=1}^n w^{(l)}_i x_i+\frac{1}{2}\sum\limits_{k=1}^{K}\Big((\sum\limits_{i=1}^{n} v^{(l)}_{ik}x_i)^2-\sum\limits_{i=1}^n (v^{(l)}_{ik}x_i)^2\Big)\Big]}} loss(y^,y)=l=1∑N−lnσ(y^(l)y(l))=l=1∑N−ln1+e−y^(l)y(l)1=l=1∑N−ln1+e−y^(l)[w0(l)+i=1∑nwi(l)xi+21k=1∑K((i=1∑nvik(l)xi)2−i=1∑n(vik(l)xi)2)]1
求 导 : ∂ l o s s ( y ^ , y ) ∂ θ = ∑ l = 1 N − 1 σ ( y ^ ( l ) y ( l ) ) ⋅ ∂ σ ( y ^ ( l ) y ( l ) ) ∂ y ( l ) ⋅ ∂ y ( l ) ∂ θ 求导:\displaystyle\frac{\partial loss(\hat{y},y)}{\partial\theta}=\sum\limits_{l=1}^{N}-\frac{1}{\sigma(\hat{y}^{(l)}y^{(l)})}\cdot\frac{\partial\sigma(\hat{y}^{(l)}y^{(l)})}{\partial y^{(l)}}\cdot\frac{\partial y^{(l)}}{\partial \theta} 求导:∂θ∂loss(y^,y)=l=1∑N−σ(y^(l)y(l))1⋅∂y(l)∂σ(y^(l)y(l))⋅∂θ∂y(l)
同样, 利 用 S G D 训 练 模 型 , 各 参 数 梯 度 : ∂ y ( l ) ∂ θ = { 1 , θ = w 0 x i , θ = w i x i ∑ j = 1 n v j , k x j − v i , k x i 2 , θ = v i , k 利用SGD训练模型,各参数梯度:\displaystyle\frac{\partial y^{(l)}}{\partial\theta}=\begin{cases}1, &\theta=w_0 \cr x_i, & \theta=w_i \cr x_i\sum\limits_{j=1}^n v_{j,k}x_j-v_{i,k}x^2_i,& \theta=v_{i,k}\end{cases} 利用SGD训练模型,各参数梯度:∂θ∂y(l)=⎩⎪⎪⎪⎨⎪⎪⎪⎧1,xi,xij=1∑nvj,kxj−vi,kxi2,θ=w0θ=wiθ=vi,k
FFM
通过引入field的概念,FFM把相同性质的特征/归于同一个field。FM可以看作FFM的特例,是把所有特征/都归属到一个field时的FFM模型。

y = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n < v i , f j , v j , f i > x i x j y=w_0+\sum\limits_{i=1}^n w_i x_i+\sum\limits_{i=1}^{n-1}\sum\limits_{j=i+1}^n <v_{i,f_j},v_{j,f_i}>x_i x_j y=w0+i=1∑nwixi+i=1∑n−1j=i+1∑n<vi,fj,vj,fi>xixj
注意,这里 i i i是特征,属于field f i f_i fi; v i , f j v_{i,f_j} vi,fj表示特征 f i f_i fi对field f j f_j fj的隐向量。
基于field的FFM和FM的区别:(1)FM特征 x i 、 x j 、 x k x_i、x_j、x_k xi、xj、xk交叉时,对应的隐向量 v i 、 v j 、 v k v_i、v_j、v_k vi、vj、vk是可以无区别得互相交叉的,即“ x i x j x_i x_j xixj的系数为 v i v j v_i v_j vivj”,“ x i x k x_i x_k xixk的系数为 v i v k v_i v_k vivk”,很显然: x i x_i xi无论与特征 x j x_j xj、还是特征 x k x_k xk做交叉时,组合系数都是同一个 v i v_i vi,并没有区别开。(2)FFM也是对特征进行交叉(5个feature两两交叉 C 5 2 C^2_5 C52),但是FFM的特征 x i 、 x j 、 x k x_i、x_j、x_k xi、xj、xk交叉时,对应的隐向量 v i 、 v j 、 v k v_i、v_j、v_k vi、vj、vk不能不考虑field互相交叉;即 x i x_i xi与特征 x j x_j xj、 x i x_i xi与特征 x k x_k xk做交叉时,组合系数不能使用同一个 v i v_i vi,应该根据field信息区别为 v i , f j v_{i,f_j} vi,fj和 v i , f k v_{i,f_k} vi,fk。只有feature x j x_j xj和 x k x_k xk属于同一field时,有 v i , f j = v i , f k v_{i,f_j}=v_{i,f_k} vi,fj=vi,fk。
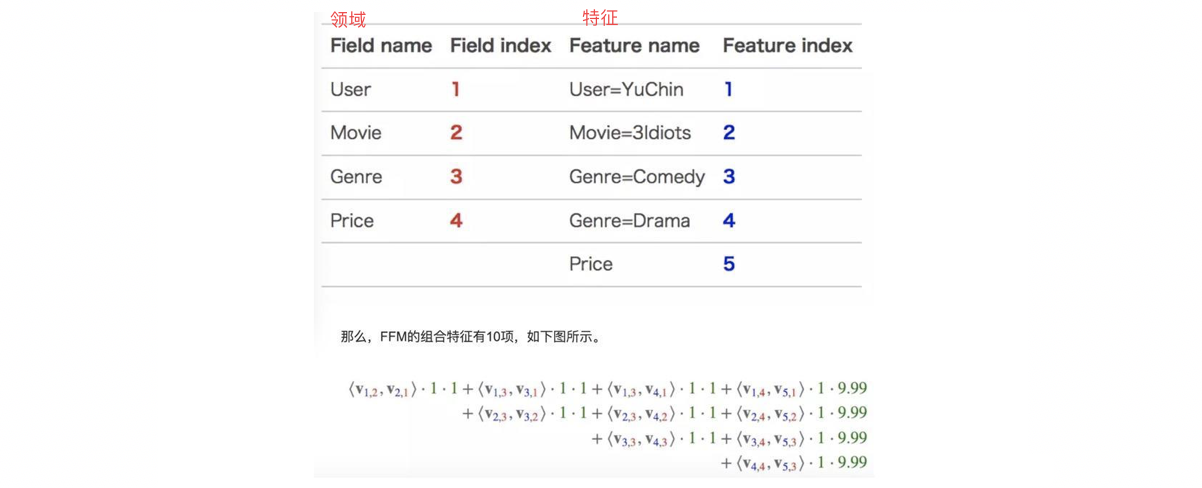
结合上图表格:(1)feature1-User分别与feature2-Movie和feature5-Price做交叉时,由于feature2-Movies属于field2、feature5-Price属于field4,所以feature1-User和feature2-Movie组合的系数为 < v 1 , 2 , v 2 , 1 > <v_{1,2}, v_{2,1}> <v1,2,v2,1>,feature1-User和feature5-Price组合的系数为 < v 1 , 4 , v 5 , 1 > <v_{1,4},v_{5,1}> <v1,4,v5,1>,即 v 1 , 2 v_{1,2} v1,2和 v 1 , 4 v_{1,4} v1,4是不同的两项。(2)feature1-User分别与feature3-Genre和feature4-Genre做交叉时,由于feature3-Genre和feature4-Genre都属于field3,所以feature1-User和feature3-Genre组合的系数为 < v 1 , 3 , v 3 , 1 > <v_{1,3}, v_{3,1}> <v1,3,v3,1>,feature1-User和feature4-Genre组合的系数为 < v 1 , 3 , v 4 , 1 > <v_{1,3},v_{4,1}> <v1,3,v4,1>,即 v 1 , 3 v_{1,3} v1,3和 v 1 , 3 v_{1,3} v1,3是相同的项。
FM背景及相关算法对比
(1)FM(factorization machine)是在LR(logistic regression)基础上,加入了特征的二阶组合项;
(2)SVM和FM的主要区别在于,SVM的二元特征交叉参数是独立的,如 w i j w_{ij} wij,而FM的二元特征交叉参数是两个k维的向量 v i 、 v j v_i、v_j vi、vj,即 < v i , v j > <v_i,v_j> <vi,vj>和 < v j , v m > <v_j,v_m> <vj,vm>是相互影响的。
Q:为什么线性SVM在和多项式SVM在稀疏条件下效果会比较差呢?A:线性SVM只有一维特征,不能挖掘深层次的组合特征在实际预测中并没有很好的表现;而多项式SVM正如前面提到的,交叉的多个特征需要在训练集上共现才能被学习到,否则该对应的参数就为0,对测试集上的case而言这样的特征就失去了意义,因此在稀疏条件下,SVM表现并不能让人满意。而FM不一样,通过向量化的交叉,可以学习到不同特征之间的交互,进行提取到更深层次的抽象意义。
参考文献
https://tech.meituan.com/2016/03/03/deep-understanding-of-ffm-principles-and-practices.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134576.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
