大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
LSTM的参数解释
LSTM总共有7个参数:前面3个是必须输入的
1:input_size: 输入特征维数,即每一行输入元素的个数。输入是一维向量。如:[1,2,3,4,5,6,7,8,9],input_size 就是9
2:hidden_size: 隐藏层状态的维数,即隐藏层节点的个数,这个和单层感知器的结构是类似的。这个维数值是自定义的,根据具体业务需要决定,如下图:
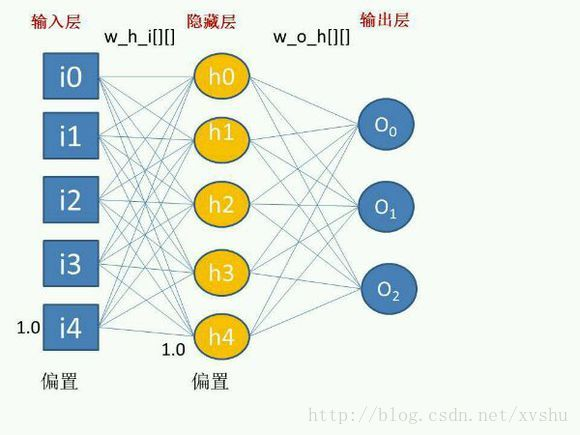

input_size:就是输入层,左边蓝色方格 [i0,i1,i2,i3,i4],hidden_size:就是隐藏层,中间黄色圆圈 [h0,h1,h2,h3,h4]。最右边蓝色圆圈 [o0,o1,o2] 的是输出层,节点个数也是按具体业务需求决定的。
3:num_layers: LSTM 堆叠的层数,默认值是1层,如果设置为2,第二个LSTM接收第一个LSTM的计算结果。也就是第一层输入 [ X0 X1 X2 … Xt],计算出 [ h0 h1 h2 … ht ],第二层将 [ h0 h1 h2 … ht ] 作为 [ X0 X1 X2 … Xt] 输入再次计算,输出最后的 [ h0 h1 h2 … ht ]。(下面是一开始对这个参数的理解,现在看来是错误的,但依然保留,防止哪天再次理解错误)
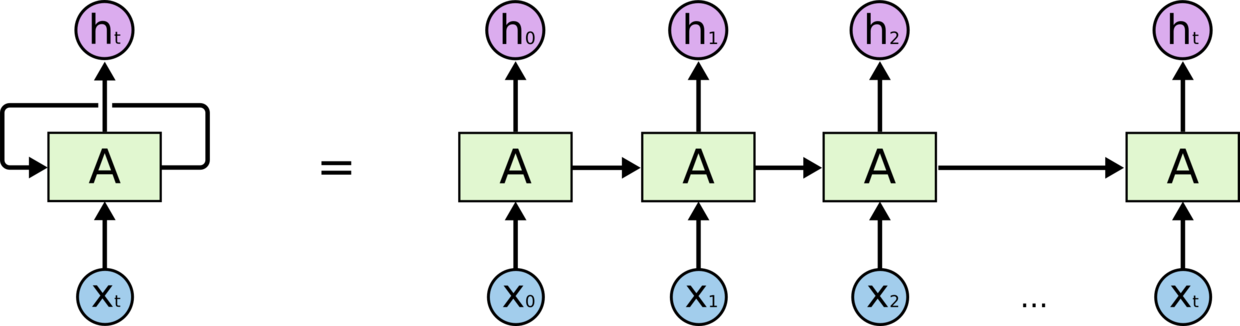
(RNN 单元的个数。我们可以简单理解,LSTM 实际上就是由多个上面图例的结构组成(准确说是一个 RNN 结构),一个结构体为一个单元,也可以叫做一个神经元。这里的 num_layers 就是表示有多少个这样的结构体。如下图:就是 A 单元的个数,换言之,就是你有多少个连续相关的数据需要输入,就有多少个这样的结构体来组成 LSTM。 因为 LSTM 要实现的功能就是根据前后相关联的数据来推断结果,前后数据之间必须建立某种联系,而这种联系一般都是有顺序性或有时序的数据。)
4:bias: 隐层状态是否带bias,默认为true。bias是偏置值,或者偏移值。没有偏置值就是以0为中轴,或以0为起点。偏置值的作用请参考单层感知器相关结构。
5:batch_first: 输入输出的第一维是否为 batch_size,默认值 False。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。 在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。 如果是相同意义的,就设置为True,如果不同意义的,设置为False。 torch.LSTM 中 batch_size 维度默认是放在第二维度,故此参数设置可以将 batch_size 放在第一维度。如:input 默认是(4,1,5),中间的 1 是 batch_size,指定batch_first=True后就是(1,4,5)。所以,如果你的输入数据是二维数据的话,就应该将 batch_first 设置为True;
6:dropout: 默认值0。是否在除最后一个 RNN 层外的其他 RNN 层后面加 dropout 层。输入值是 0-1 之间的小数,表示概率。0表示0概率dripout,即不dropout
7:bidirectional: 是否是双向 RNN,默认为:false,若为 true,则:num_directions=2,否则为1。 我的理解是,LSTM 可以根据数据输入从左向右推导结果。然后再用结果从右到左反推导,看原因和结果之间是否可逆。也就是原因和结果是一对一关系,还是多对一的关系。这仅仅是我肤浅的假设,有待证明。
首先,看看官方给出的例子
# 首先导入LSTM需要的相关模块
import torch
import torch.nn as nn # 神经网络模块
# 数据向量维数10, 隐藏元维度20, 2个LSTM层串联(如果是1,可以省略,默认为1)
rnn = nn.LSTM(10, 20, 2)
# 序列长度seq_len=5, batch_size=3, 数据向量维数=10
input = torch.randn(5, 3, 10)
# 初始化的隐藏元和记忆元,通常它们的维度是一样的
# 2个LSTM层,batch_size=3,隐藏元维度20
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
# 这里有2层lstm,output是最后一层lstm的每个词向量对应隐藏层的输出,其与层数无关,只与序列长度相关
# hn,cn是所有层最后一个隐藏元和记忆元的输出
output, (hn, cn) = rnn(input, (h0, c0))
print(output.size(),hn.size(),cn.size())
torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
注意:
1、对 nn.LSTM(10, 20, 2) 最后一个参数的理解。这是 2 个完整的 LSTM 串连,是 LSTM参数中 num_layers 的个数。
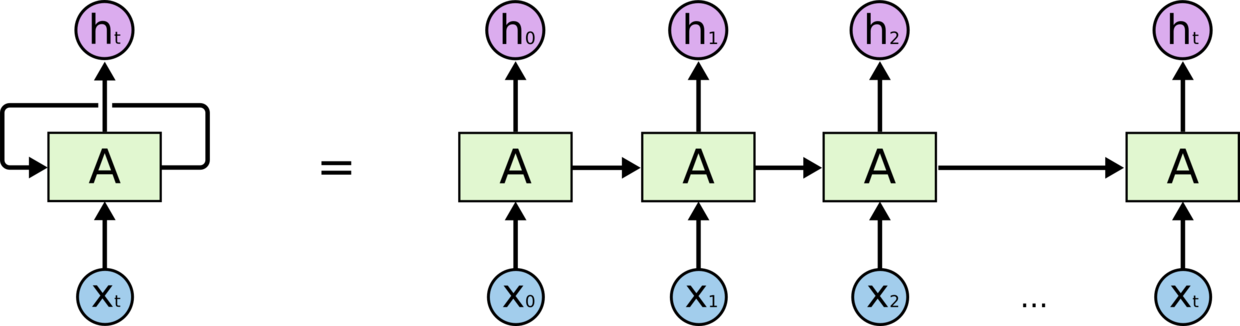
上图,是一个完整的 LSTM。2 个LSTM的运作是,第一层的输出 h0 h1 h2 … ht,变成 第二层 LSTM 的 x0 x1 x2 … xt 输入。
2、torch.randn(5, 3, 10) 数据中第一维度5(有5组数据,每组3行,每行10列),在整个模型中似乎没有看到在哪里处理了5次。整个模型也没有循环5次,它到哪了呢?
其实,它被自动分配到上图中的 A 的个数,也就是每一个LSTM层中,有5个A(神经元)。也就是每次输入模型的数据长度是可变的。也许,这就是为什么被称为长短记忆了。
举一个栗子,假如我们输入有3个句子,每个句子都由5个单词组成,而每个单词用10维的词向量表示,则seq_len=5, batch=3, input_size=10。而事实上每一个句子不可能是固定5个单词组成。所以,使用LSTM网络,就不要担心单词数量不相等。
总结一下对参数的理解
1、在实例模型的时候有2个参数是必须的,1个参数是可选的。
第一个参数是数据的长度:是有数据结构中最小维度的列数决定的。大白话就是:“每行有多少个数据。”这是一个固定值,不可变。
第二个参数是隐藏层的单元个数:这是自定义的,取决于你业务需要,也就是你想对每行数据使用多少个权重来计算,可以增加(升维),也可以压缩(降维)。
第三个参数是 LSTM 的层数:默认是1个,至少要有一个完整的LSTM吧,不然算什么呢?但也可以增加,使用2层或更多。这个意义在哪里,恐怕要在实践中才能体会了。
当然,还有其他的参数,根据实际情况选择,值得注意的是 bacth_size,根据你输入的数据结构,可能存在两种不同情况。
2、运行模型时3个参数是必须的。
运行模型的格式是这样写的。output, (hn, cn) = model(input, (h0, c0))
从形式上看,输入结构和输出结构是一样的。都是3个输入,3个输出。
参数1:你输入的数据团。好像必须是 3 维数据。但必须注意 batch_size 的位置。是第一维,还是第二维。默认是在第二维度。是不可变的维度。最后一个维度是行数据的个数。剩下的1维数据是可变的,这就是长短数据。默认放在第一维。
参数2:隐藏层数据,也必须是3维的,第一维:是LSTM的层数,第二维:是隐藏层的batch_size数,必须和输入数据的batch_size一致。第三维:是隐藏层节点数,必须和模型实例时的参数一致。
参数3:传递层数据,也必须是3维的,通常和参数2的设置一样。它的作用是LSTM内部循环中的记忆体,用来结合新的输入一起计算。
思考:如果参数2和参数3不同设置会是什么结果,这里就不知道了,以后深入研究在探讨。但据我测试,维度的任何改变都会出错的,感觉上维度必须一样。之所以分成两个参数,是因为可以不同初始值的缘故吧。
了解这些,基本上可以设计LSTM模型了,至于那几个生死门如何开关,据说是可以控制的,以后再说吧。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195221.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
