大家好,又见面了,我是你们的朋友全栈君。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
kafka集群搭建
文章目录
前言
不使用 集群请参考这个文章:https://www.cnblogs.com/luzhanshi/p/13369834.html
kafka 是个高吞吐的消息中间件,为啥快啊?
1顺序读写
2 0拷贝
3 批量提交和批量ACK
4 分片和副本
消息队列高可用 就得用集群 。
提示:以下是本篇文章正文内容,下面案例可供参考
一、kafka是什么?
kafka理论参考:
从入门到入土 04-2 kafka理论(面试)篇 :
https://blog.csdn.net/qq_14919677/article/details/119867555
二、集群
1.集群
集群:多台服务器组成的整体叫做集群,这个整体对生产者和消费者来说,是透明的。其实对消费系统组成的集群添加一台服务器减少一台服务器对生产者和消费者都是无感之的。如果增加消费者(group)
kafka会重新分配你要去消费的分片; 比如你1个消费端消费两个服务器组成的集群s1,s2 当你再增加一个消费者(group不一样的时候)会重新分配类似于c1 消费s1 , c2 消费s2 , 意思就是重新负载
2.负载均衡
负载均衡:对消息系统来说负载均衡是大量的生产者和消费者向消息系统发出请求消息,系统必须均衡这些请求使得每一台服务器的请求达到平衡,而不是大量的请求,落到某一台或几台,使得这几台服务器高负荷或超负荷工作,严重情况下会停止服务或宕机。
3.扩容
扩容:动态扩容是很多公司要求的技术之一,不支持动态扩容就意味着停止服务,这对很多公司来说是不可以接受的。
4.Zookeeper Leader选举
选举: 是通过ISR维护的节点列表集合(In-Sync Replicas)。
但是,为了保证较高的处理效率,消息的读写都是在固定的一个副本上完成。这个副本就是所谓的Leader,而其他副本则是Follower。而Follower则会定期地到Leader上同步数据。
同步数据分定期同步和定数量同步
Leader选举
如果某个分区所在的服务器出了问题,zk会从该分区的其他的副本中选择一个作为新的Leader。之后所有的读写就会转移到这个新的Leader上。现在的问题是应当选择哪个作为新的Leader。显然,只有那些跟Leader保持同步的Follower才应该被选作新的Leader。
Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录。
如果某个分区的Leader不可用,Kafka就会从ISR集合中选择一个副本作为新的Leader。
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有f+1个副本,kafka可以容忍f个服务器不可用。
为什么不用少数服从多数的方法
少数服从多数是一种比较常见的一致性算法和Leader选举法。它的含义是只有超过半数的副本同步了,系统才会认为数据已同步;选择Leader时也是从超过半数的同步的副本中选择。这种算法需要较高的冗余度。譬如只允许一台机器失败,需要有三个副本;而如果只容忍两台机器失败,则需要五个副本。而kafka的ISR集合方法,分别只需要两个和三个副本。
如果所有的ISR副本都失败了怎么办
此时有两种方法可选,一种是等待ISR集合中的副本复活,一种是选择任何一个立即可用的副本,而这个副本不一定是在ISR集合中。这两种方法各有利弊,实际生产中按需选择。
如果要等待ISR副本复活,虽然可以保证一致性,但可能需要很长时间。而如果选择立即可用的副本,则很可能该副本并不一致。
kafka架构
生产者生产消息、kafka集群、消费者获取消息这样一种架构
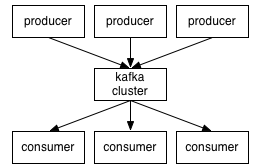

kafka集群中的消息,是通过Topic(主题)来进行组织的,如下图:
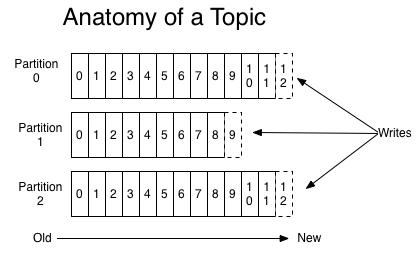
这个有一个HW水平位的概念 就是当你消费的时候是消费到副本同步的最小值 如上图如果换成是Replication副本的化你最多消费到8 hw是8
1、主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
2、分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
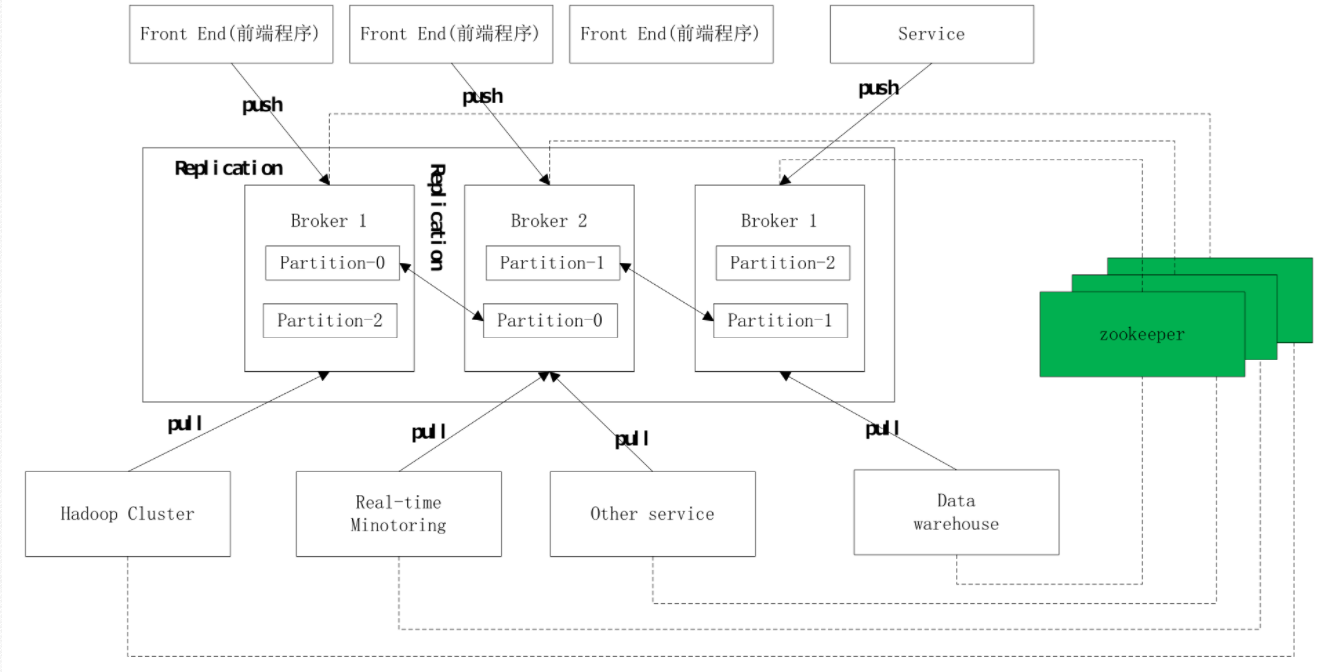
集群搭建
下载 安装zookeeper
version: '3.4'
services:
zoo1:
image: zookeeper:3.4
restart: always
hostname: zoo1
container_name: zoo1
ports:
- 2184:2181
volumes:
- "/test/volume/zkcluster/zoo1/data:/data"
- "/test/volume/zkcluster/zoo1/datalog:/datalog"
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
networks:
kafka:
ipv4_address: 172.19.0.11
zoo2:
image: zookeeper:3.4
restart: always
hostname: zoo2
container_name: zoo2
ports:
- 2185:2181
volumes:
- "/test/volume/zkcluster/zoo2/data:/data"
- "/test/volume/zkcluster/zoo2/datalog:/datalog"
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=0.0.0.0:2888:3888 server.3=zoo3:2888:3888
networks:
kafka:
ipv4_address: 172.19.0.12
zoo3:
image: zookeeper:3.4
restart: always
hostname: zoo3
container_name: zoo3
ports:
- 2186:2181
volumes:
- "/test/volume/zkcluster/zoo3/data:/data"
- "/test/volume/zkcluster/zoo3/datalog:/datalog"
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=0.0.0.0:2888:3888
networks:
kafka:
ipv4_address: 172.19.0.13
networks:
kafka:
external:
name: kafka
上面这个命令如果是单机版本可以一起执行,如果是多个机器执行则需要把其他两个去掉但是切记要留着后面的networks否则启动会报错,ip地址和端口号自行修改. 对于初次使用的记得安装docker-compose 插件
接下来安装docker-compose,运行命令:
sudo curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
docker-compose -v
,然后上面的yml文件需要命名成docker-compose.yml 这个我不知道怎么解释 我也是第一次使用,如果不这么命名则会报错。
执行命令:
docker-compose up
或者docker-compose -f zk.yml up -d
networks:
kafka: 这个东西是docker用的网关 一般可以自动创建的 如果没有创建的话,那就手动创建一下
查询/创建 的命令是:
docker network ls
docker network create --driver bridge --subnet 172.19.0.0/16 --gateway 172.19.0.1 kafka
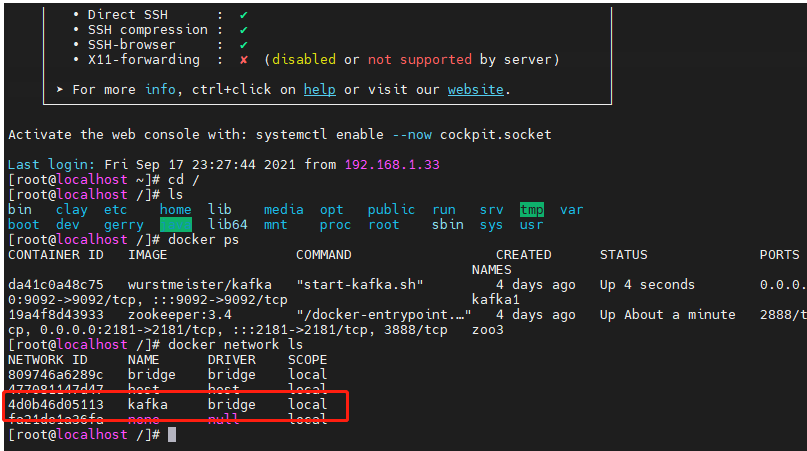
然后再执行上面的up命令,都执行成功了通过docker ps 查看,如果都活着 通过docker logs 查看如果没有错误信息基本就搞定了。 可以通过客户端去连接。 我用的是kafkatools 连接的。 先创建topics 然后再生产数据, 在工具里都可以看到数据, 在通过消费者消费数据即可;
测试kafka
输入docker exec -it kafka0 bash 进入kafka0容器,并执行如下命令创建topic
cd /opt/kafka_2.13-2.6.0/bin/
./kafka-topics.sh –create –topic chat –partitions 5 –zookeeper 8.210.138.111:2181 –replication-factor
输入如下命令开启生产者
./kafka-console-producer.sh –broker-list kafka0:9092 –topic chat
开启另一个shell界面进入kafka2容器并执行下列命令开启消费者
./kafka-console-consumer.sh –bootstrap-server kafka2:9094 –topic chat –from-beginning
<font
color=#999AAA >提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134462.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
