大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Neokylin-Server离线环境、跨主机、使用Docker部署PXC集群
Neokylin-Server离线环境、跨主机、使用Docker部署PXC集群
一、说明
背景:NeoKylin使用swarm、macvlan、calico组网docker环境中pxc高可用不成功后,使用flannel+etcd成功,记录过程如下。
系统:Neokylin-Server-5.0_U4-x86_64-Release-B14-20190320。
使用说明:pxc做集群;Haproxy做负载均衡;Keepalived浮动ip;etcd+Flannel保证容器跨主机互通;ntpdate时间同步、busybox做测试
环境:
| 虚拟机(节点)名称 | ip | 部署 |
|---|---|---|
| m1 | 192.168.136.21 | Haproxy、Keepalived、etcd、busybox |
| m2 | 192.168.136.22 | Haproxy、Keepalived、etcd、busybox |
| m3 | 192.168.136.23 | Haproxy、Keepalived、etcd、busybox |
| n1 | 192.168.136.26 | pxc、busybox |
| n2 | 192.168.136.27 | pxc、busybox |
| n3 | 192.168.136.28 | pxc、busybox |
部署相关文件:
- 链接:https://pan.baidu.com/s/1OAsF0Kq–umgBZIIHVSWpg
提取码:e39i
二、部署过程:
1. 切换root账号或所有语句加sudo;
2. 关闭6个节点防火墙(或打开端口);
systemctl stop firewalld
systemctl disable firewalld
3. 6个节点导入rpm包后安装基础环境:
rpm基础环境包放置于百度网盘中
rpm -ivh *.rpm --replacefiles --force –nodeps
说明:安装基础环境,docker,ntpdate,keepalived,flannel,etcd,其中etcd只有m1、m2、m3使用
4. 设置所有节点;
修改6个节点名称为m1、m2、m3、n1、n2、n3
hostnamectl set-hostname <newhostname>
修改6个节点hosts文件
vim /etc/hosts
结尾追加
192.168.136.21 m1
192.168.136.22 m2
192.168.136.23 m3
192.168.136.26 n1
192.168.136.27 n2
192.168.136.28 n3
5. 启动docker并导入images;
设置6个节点自启动docker
systemctl start docker
systemctl enable docker
导入docker images,为后续使用做准备,语句举例:
docker load < pxc56.tar
| 虚拟机(节点)名称 | 导入images |
|---|---|
| m1 | my-haproxy.tar、busybox.tar |
| m2 | my-haproxy.tar、busybox.tar |
| m3 | my-haproxy.tar、busybox.tar |
| n1 | pxc56.tar、busybox.tar |
| n2 | pxc56.tar、busybox.tar |
| n3 | pxc56.tar、busybox.tar |
6. 时间同步;
6个节点通过ntpdate时间同步,一般需要联网同步,这里使用时间服务器,192.168.136.1设置为提供ntp服务的win10电脑:
ntp 192.168.136.1
也可以通过联网时间同步:
ntpdate cn.pool.ntp.org
7. etcd集群配置;
备份etcd的配置文件:
cp /etc/etcd/etcd.conf /etc/etcd/etcd.conf.bak
编辑m1主机/etc/etcd/etcd.conf文件为:
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001"
ETCD_NAME="m1"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://m1:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://m1:2379,http://m1:4001"
ETCD_INITIAL_CLUSTER="m1=http://m1:2380,m2=http://m2:2380,m3=http://m3:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
编辑m2主机/etc/etcd/etcd.conf文件为:
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001"
ETCD_NAME="m2"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://m2:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://m2:2379,http://m2:4001"
ETCD_INITIAL_CLUSTER="m1=http://m1:2380,m2=http://m2:2380,m3=http://m3:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
编辑m3主机/etc/etcd/etcd.conf文件为:
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001"
ETCD_NAME="m3"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://m3:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://m3:2379,http://m3:4001"
ETCD_INITIAL_CLUSTER="m1=http://m1:2380,m2=http://m2:2380,m3=http://m3:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
修改m1~m3主机的/usr/lib/systemd/system/etcd.service文件为:
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
EnvironmentFile=/etc/etcd/etcd.conf
User=etcd
# set GOMAXPROCS to number of processors
ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/bin/etcd --name=\"${ETCD_NAME}\" --data-dir=\"${ETCD_DATA_DIR}\" --listen-client-urls=\"${ETCD_LISTEN_CLIENT_URLS}\""
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
配置完后,在m1~m3上设置自启并启动etcd服务,
systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
在m1~m3主机上,可通过etcdctl member list命令查看etcd集群节点信息
8. 部署flannel网络;
将所有docker容器部署于flannel网络中,可使得容器间可以跨主机通信,也可以使宿主与容器通信。
在所有主机上,备份flanneld文件
cp /etc/sysconfig/flanneld /etc/sysconfig/flanneld.bak
修改所有主机上的/etc/sysconfig/flanneld 为如下内容:
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://m1:2379,http://m2:2379,http://m3:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
#FLANNEL_ETCD_PREFIX="/atomic.io/network"
FLANNEL_ETCD_PREFIX="/coreos.com/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
然后只需在m1主机上执行
etcdctl mk /coreos.com/network/config '{ "Network": "192.168.0.0/16" }'
将所有主机的/usr/lib/systemd/system/docker.service文件中ExecStart=/usr/bin/dockerd修改为下面两行:
EnvironmentFile=-/run/flannel/docker
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS
以上配置完成后,执行以下命令
systemctl enable flanneld.service && systemctl start flanneld.service && systemctl restart docker
测试flannel网络
例如使用busybox测试,在所有主机运行busybox容器,用来测试flannel网络
docker run -it -d --name=bbox busybox /bin/sh && docker exec -it bbox /bin/sh
在容器中运行ip a命令,如下图所示
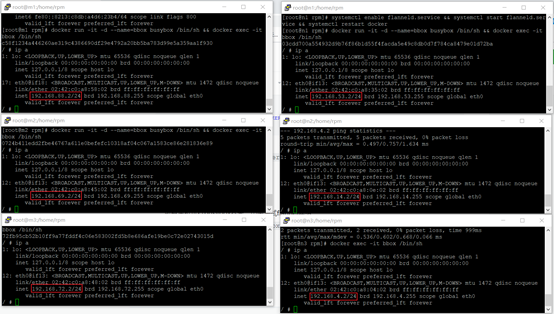

各主机上busybox容器的IP如下:
| busybox IP | 所属主机 |
|---|---|
| 192.168.88.2 | m1 |
| 192.168.69.2 | m2 |
| 192.168.72.2 | m3 |
| 192.168.53.2 | n1 |
| 192.168.14.2 | n2 |
| 192.168.4.2 | n3 |
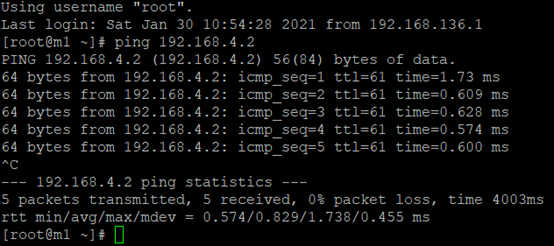
m1主机 ping n3主机的busybox容器IP 192.168.4.2,如下图:
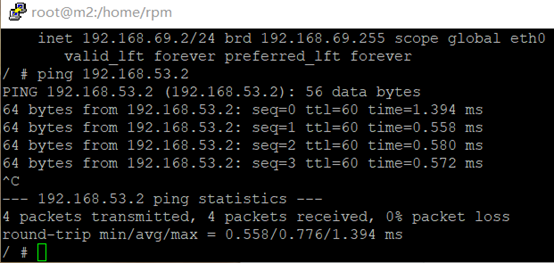
m2主机的busybox容器 ping n1主机的busybox容器IP 192.168.53.2,如下图:
以上测试通过,说明各主机、主机上的容器现在可通过flannel跨主机网络相互通信,为后续在麒麟系统上使用docker容器搭建应用打下基础。
9. n1-n3部署pxc;
通过docker本地安装pxc5.6。使用5.6是因为该环境高版本多节点部署有问题,pxc5.7版本不支持不使用k8s或者etcd模式的docker集群。
删除数据卷,每次重装pxc前最好做一次
docker volume rm v1
创建名称为v1的数据卷,–name可以省略
docker volume create --name v1
查看数据卷
docker inspect v1
创建3个PXC容器构成集群
n1节点执行
docker run -d -p 3306:3306 -p 3307:3307 -p 4567:4567 -p 4568:4568 -p 4444:4444 -p 8888:8888 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql --name=n1 pxc
在第一个节点启动后要等待一段时间,等候mysql启动完成。
n2节点执行
docker run -d -p 3306:3306 -p 3307:3307 -p 4567:4567 -p 4568:4568 -p 4444:4444 -p 8888:8888 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=192.168.136.26 -v v1:/var/lib/mysql --name=n2 pxc
n3节点执行
docker run -d -p 3306:3306 -p 3307:3307 -p 4567:4567 -p 4568:4568 -p 4444:4444 -p 8888:8888 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=192.168.136.26 -v v1:/var/lib/mysql --name=n3 pxc
在n1节点添加账号,三台可自动同步,为Haproxy做准备
docker exec -it n1 /usr/bin/mysql -uroot -pabc123456
create user 'haproxy'@'%' identified by '';
10. m1-m3部署Haproxy+Keepalived容器;
使用Haproxy做负载均衡与监听pxc,keepalive做热备份与虚拟IP;
m1-m3安装Haproxy+keepalived
3个节点在/home/soft/haproxy/下放置haproxy.cfg,内容如下
# haproxy.cfg
global
#工作目录
chroot /usr/local/etc/haproxy
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon
defaults
log global
mode http
#日志格式
option httplog
#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000
#监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:8888
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登陆帐户信息
stats auth admin:abc123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#负载均衡算法(轮询算法)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测
option mysql-check user haproxy
server MySQL_1 192.168.136.26:3306 check weight 1 maxconn 2000
server MySQL_2 192.168.136.27:3306 check weight 1 maxconn 2000
server MySQL_3 192.168.136.28:3306 check weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka
/home/soft/keepalived/下放置keepalived.conf,内容如下
vrrp_instance VI_1 {
state MASTER # Keepalived的身份(MASTER主服务要抢占IP,BACKUP备服务器不会抢占IP)。
interface eth0 # docker网卡设备,虚拟IP所在
virtual_router_id 51 # 虚拟路由标识,MASTER和BACKUP的虚拟路由标识必须一致。从0~255
priority 100 # MASTER权重要高于BACKUP数字越大优先级越高
advert_int 1 # MASTER和BACKUP节点同步检查的时间间隔,单位为秒,主备之间必须一致
authentication {
# 主从服务器验证方式。主备必须使用相同的密码才能正常通信
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
# 虚拟IP。可以设置多个虚拟IP地址,每行一个
192.168.65.201
}
}
keepalived的配置文件的权限设定是644
chmod 644 keepalived.conf
这里已经将Haproxy和Keepalived合成一个容器,同时启动,
m1执行:
docker run -it -d -p 4003:8888 -p 3306:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy -v /home/soft/keepalived:/etc/keepalived --name hlyc1 --privileged my-haproxy
m2执行:
docker run -it -d -p 4003:8888 -p 3306:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy -v /home/soft/keepalived:/etc/keepalived --name hlyc2 --privileged my-haproxy
m3执行:
docker run -it -d -p 4003:8888 -p 3306:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy -v /home/soft/keepalived:/etc/keepalived --name hlyc3 --privileged my-haproxy
Haproxy完成负载均衡,keepalived容器对flannel网外暴露192.168.65.201,可供宿主机使用
Haproxy登录界面
http://192.168.136.21:4003/dbs
http://192.168.136.22:4003/dbs
http://192.168.136.23:4003/dbs
用户名admin,密码abc123456。
11. m1-m3宿主机部署keepalived:
Docker内的ip在flannel组网中,不能被外网访问,所有需要借助宿主机Keepalived映射成外网可以访问的虚拟ip,这里设定为 192.168.65.201
在3个节点/etc/keepalived/目录放置keepalived.conf,内容如下:
vrrp_instance VI_1 {
state MASTER
#这里是宿主机的网卡,可以通过ip a查看当前自己电脑上用的网卡名是哪个
interface enp0s3
virtual_router_id 100
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
#这里是指定的一个宿主机上的虚拟ip,一定要和宿主机网卡在同一个网段,
#我的宿主机网卡ip是192.168.136.1,所以指定虚拟ip是160
192.168.136.160
}
}
#接受监听数据来源的端口,网页入口使用
virtual_server 192.168.136.160 8888 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#把接受到的数据转发给docker服务的网段及端口,由于是发给docker服务,所以和docker服务数据要一致,这里使用flannel分配地址
real_server 192.168.65.201 8888 {
weight 1
}
real_server 192.168.34.201 8888 {
weight 1
}
real_server 192.168.78.201 8888 {
weight 1
}
}
#接受数据库数据端口,宿主机数据库端口是3306,所以这里也要和宿主机数据接受端口一致
virtual_server 192.168.136.160 3306 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#同理转发数据库给服务的端口和ip要求和docker服务中的数据一致,这里使用flannel分配地址
real_server 192.168.65.201 3306 {
weight 1
}
real_server 192.168.34.201 3306 {
weight 1
}
real_server 192.168.78.201 3306 {
weight 1
}
}
m1、m2、m3执行:
systemctl start keepalived
systemctl enable keepalived
flannel网外可访问数据库地址192.168.136.160:3306,是pxc对外统一接口,具有负载均衡、浮动ip。至此,pxc集群安装结束。
12. 宕机
当有一个pxc节点宕机后,将该节点数据卷中的grastate.dat文件删除
rm -rf /var/lib/docker/volumes/v1/_data/grastate.dat
再以从节点的方式加入pxc集群中,这里举例初始主节点n1节点宕机后,n1以从节点方式加入组网
docker run -d -p 3306:3306 -p 3307:3307 -p 4567:4567 -p 4568:4568 -p 4444:4444 -p 8888:8888 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=192.168.136.28 -v v1:/var/lib/mysql --name=n1 pxc
当有两个节点宕机后,将两个节点grastate.dat文件删除,再以从节点形式加入没宕机节点。
当三个节点全部宕机,将所有节点数据卷中的grastate.dat文件删除,不要删除v1中其它文件,检查Haproxy,按最后宕机的为主节点依次启动三个节点,即可恢复数据。
参考文档:
Docker部署Mysql集群.
NeoKylin-Server-5.0 离线部署 etcd+flannel 集群,实现 docker 容器跨主机网络通信.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169447.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
