大家好,又见面了,我是你们的朋友全栈君。
Java IO 详解
初学java,一直搞不懂java里面的io关系,在网上找了很多大多都是给个结构图草草描述也看的不是很懂。而且没有结合到java7 的最新技术,所以自己来整理一下,有错的话请指正,也希望大家提出宝贵意见。
首先看个图:(如果你也是初学者,我相信你看了真个人都不好了,想想java设计者真是煞费苦心啊!)
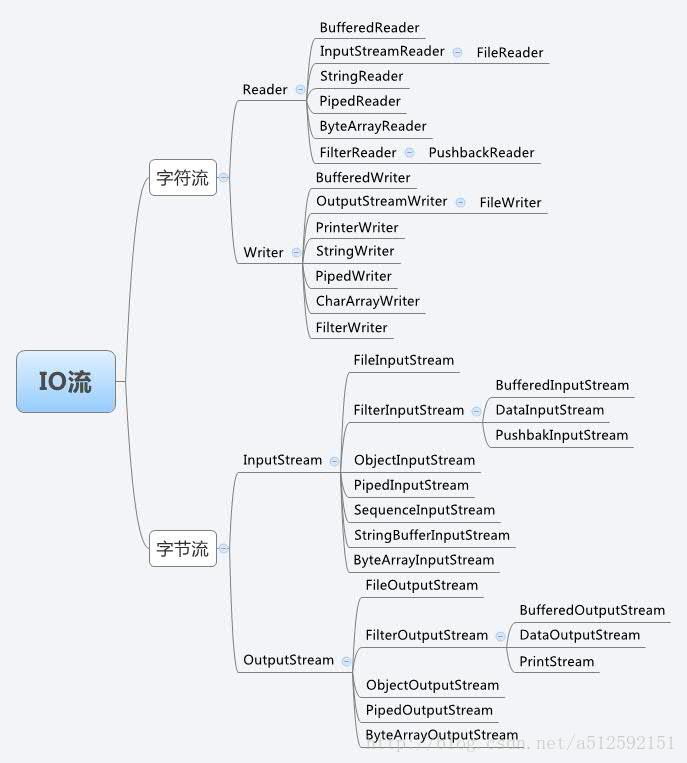

这是java io 比较基本的一些处理流,除此之外我们还会提到一些比较深入的基于io的处理类,比如console类,SteamTokenzier,Externalizable接口,Serializable接口等等一些高级用法极其原理。
一、java io的开始:文件
1. 我们主要讲的是流,流的本质也是对文件的处理,我们循序渐进一步一步从文件将到流去。
2. java 处理文件的类 File,java提供了十分详细的文件处理方法,举了其中几个例子,其余的可以去
Java代码 
package com.hxw.io;
import java.io.*;
public class FileExample{
public static void main(String[] args) {
createFile();
}
/**
* 文件处理示例
*/
public static void createFile() {
File f=new File(“E:/电脑桌面/jar/files/create.txt”);
try{
f.createNewFile(); //当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。
System.out.println(“该分区大小”+f.getTotalSpace()/(1024*1024*1024)+”G”); //返回由此抽象路径名表示的文件或目录的名称。
f.mkdirs(); //创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
// f.delete(); // 删除此抽象路径名表示的文件或目录
System.out.println(“文件名 “+f.getName()); // 返回由此抽象路径名表示的文件或目录的名称。
System.out.println(“文件父目录字符串 “+f.getParent());// 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
}catch (Exception e) {
e.printStackTrace();
}
}
}
二、字节流:
1.字节流有输入和输出流,我们首先看输入流InputStream,我们首先解析一个例子(FileInputStream)。
Java代码
package com.hxw.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class FileCount {
/**
* 我们写一个检测文件长度的小程序,别看这个程序挺长的,你忽略try catch块后发现也就那么几行而已。
*/
publicstatic void main(String[] args) {
//TODO 自动生成的方法存根
int count=0; //统计文件字节长度
InputStreamstreamReader = null; //文件输入流
try{
streamReader=newFileInputStream(new File(“D:/David/Java/java 高级进阶/files/tiger.jpg”));
/*1.new File()里面的文件地址也可以写成D:\\David\\Java\\java 高级进阶\\files\\tiger.jpg,前一个\是用来对后一个
* 进行转换的,FileInputStream是有缓冲区的,所以用完之后必须关闭,否则可能导致内存占满,数据丢失。
*/
while(streamReader.read()!=-1) { //读取文件字节,并递增指针到下一个字节
count++;
}
System.out.println(“—长度是: “+count+” 字节”);
}catch (final IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}finally{
try{
streamReader.close();
}catch (IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
}
我们一步一步来,首先,上面的程序存在问题是,每读取一个自己我都要去用到FileInputStream,我输出的结果是“—长度是: 64982 字节”,那么进行了64982次操作!可能想象如果文件十分庞大,这样的操作肯定会出大问题,所以引出了缓冲区的概念。可以将streamReader.read()改成streamReader.read(byte[]b)此方法读取的字节数目等于字节数组的长度,读取的数据被存储在字节数组中,返回读取的字节数,InputStream还有其他方法mark,reset,markSupported方法,例如:
markSupported 判断该输入流能支持mark 和 reset 方法。
mark用于标记当前位置;在读取一定数量的数据(小于readlimit的数据)后使用reset可以回到mark标记的位置。
FileInputStream不支持mark/reset操作;BufferedInputStream支持此操作;
mark(readlimit)的含义是在当前位置作一个标记,制定可以重新读取的最大字节数,也就是说你如果标记后读取的字节数大于readlimit,你就再也回不到回来的位置了。
通常InputStream的read()返回-1后,说明到达文件尾,不能再读取。除非使用了mark/reset。
2.FileOutputStream 循序渐进版, InputStream是所有字节输出流的父类,子类有ByteArrayOutputStream,FileOutputStream,ObjectOutputStreanm,这些我们在后面都会一一说到。先说FileOutputStream
我以一个文件复制程序来说,顺便演示一下缓存区的使用。(Java I/O默认是不缓冲流的,所谓“缓冲”就是先把从流中得到的一块字节序列暂存在一个被称为buffer的内部字节数组里,然后你可以一下子取到这一整块的字节数据,没有缓冲的流只能一个字节一个字节读,效率孰高孰低一目了然。有两个特殊的输入流实现了缓冲功能,一个是我们常用的BufferedInputStream.)
Java代码
package com.hxw.io;
import java.io.*;
public class FileCopy {
public static void main(String[] args) {
// TODO自动生成的方法存根
byte[] buffer=new byte[512]; //一次取出的字节数大小,缓冲区大小
int numberRead=0;
FileInputStream input=null;
FileOutputStream out =null;
try {
input=new FileInputStream(“D:/David/Java/java 高级进阶/files/tiger.jpg”);
out=new FileOutputStream(“D:/David/Java/java 高级进阶/files/tiger2.jpg”); //如果文件不存在会自动创建
while ((numberRead=input.read(buffer))!=-1) { //numberRead的目的在于防止最后一次读取的字节小于buffer长度,
out.write(buffer, 0, numberRead); //否则会自动被填充0
}
} catch (final IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}finally{
try {
input.close();
out.close();
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}
}
}
}
3.读写对象:ObjectInputStream 和ObjectOutputStream ,该流允许读取或写入用户自定义的类,但是要实现这种功能,被读取和写入的类必须实现Serializable接口,其实该接口并没有什么方法,可能相当于一个标记而已,但是确实不合缺少的。实例代码如下:
Java代码
package com.hxw.io;
import java.io.*;
public class ObjetStream {
/**
* @param args
*/
public static void main(String[] args) {
// TODO自动生成的方法存根
ObjectOutputStream objectwriter=null;
ObjectInputStream objectreader=null;
try {
objectwriter=new ObjectOutputStream(new FileOutputStream(“D:/David/Java/java 高级进阶/files/student.txt”));
objectwriter.writeObject(new Student(“gg”, 22));
objectwriter.writeObject(new Student(“tt”, 18));
objectwriter.writeObject(new Student(“rr”, 17));
objectreader=new ObjectInputStream(new FileInputStream(“D:/David/Java/java 高级进阶/files/student.txt”));
for (int i = 0; i
System.out.println(objectreader.readObject());
}
} catch (IOException | ClassNotFoundException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}finally{
try {
objectreader.close();
objectwriter.close();
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}
}
}
}
class Student implements Serializable{
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return “Student [name=” + name + “, age=” + age + “]”;
}
}
运行后系统输出:
Student [name=gg, age=22]
Student [name=tt, age=18]
Student [name=rr, age=17]
4.有时没有必要存储整个对象的信息,而只是要存储一个对象的成员数据,成员数据的类型假设都是Java的基本数据类型,这样的需求不必使用到与Object输入、输出相关的流对象,可以使用DataInputStream、DataOutputStream来写入或读出数据。下面是一个例子:(DataInputStream的好处在于在从文件读出数据时,不用费心地自行判断读入字符串时或读入int类型时何时将停止,使用对应的readUTF()和readInt()方法就可以正确地读入完整的类型数据。)
Java代码
package com.hxw;
public class Member {
private String name;
private int age;
public Member() {
}
public Member(String name, int age) {
this.name = name;
this.age = age;
}
public void setName(String name){
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
打算将Member类实例的成员数据写入文件中,并打算在读入文件数据后,将这些数据还原为Member对象。下面的代码简单示范了如何实现这个需求。
Java代码
package com.hxw;
import java.io.*;
public class DataStreamDemo
{
public static void main(String[]args)
{
Member[] members = {newMember(“Justin”,90),
newMember(“momor”,95),
newMember(“Bush”,88)};
try
{
DataOutputStreamdataOutputStream = new DataOutputStream(new FileOutputStream(args[0]));
for(Member member:members)
{
//写入UTF字符串
dataOutputStream.writeUTF(member.getName());
//写入int数据
dataOutputStream.writeInt(member.getAge());
}
//所有数据至目的地
dataOutputStream.flush();
//关闭流
dataOutputStream.close();
DataInputStreamdataInputStream = new DataInputStream(new FileInputStream(args[0]));
//读出数据并还原为对象
for(inti=0;i
{
//读出UTF字符串
String name =dataInputStream.readUTF();
//读出int数据
int score =dataInputStream.readInt();
members[i] = newMember(name,score);
}
//关闭流
dataInputStream.close();
//显示还原后的数据
for(Member member : members)
{
System.out.printf(“%s\t%d%n”,member.getName(),member.getAge());
}
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
5.PushbackInputStream类继承了FilterInputStream类是iputStream类的修饰者。提供可以将数据插入到输入流前端的能力(当然也可以做其他操作)。简而言之PushbackInputStream类的作用就是能够在读取缓冲区的时候提前知道下一个字节是什么,其实质是读取到下一个字符后回退的做法,这之间可以进行很多操作,这有点向你把读取缓冲区的过程当成一个数组的遍历,遍历到某个字符的时候可以进行的操作,当然,如果要插入,能够插入的最大字节数是与推回缓冲区的大小相关的,插入字符肯定不能大于缓冲区吧!下面是一个示例。
Java代码
package com.hxw.io;
import java.io.ByteArrayInputStream; //导入ByteArrayInputStream的包
import java.io.IOException;
import java.io.PushbackInputStream;
/**
* 回退流操作
* */
public class PushBackInputStreamDemo {
public static void main(String[] args) throws IOException {
String str = “hello,rollenholt”;
PushbackInputStream push = null; // 声明回退流对象
ByteArrayInputStream bat = null; // 声明字节数组流对象
bat = new ByteArrayInputStream(str.getBytes());
push = new PushbackInputStream(bat); // 创建回退流对象,将拆解的字节数组流传入
int temp = 0;
while ((temp = push.read()) != -1) { // push.read()逐字节读取存放在temp中,如果读取完成返回-1
if (temp == ‘,’) { // 判断读取的是否是逗号
push.unread(temp); //回到temp的位置
temp = push.read(); //接着读取字节
System.out.print(“(回退” + (char) temp + “) “); // 输出回退的字符
} else {
System.out.print((char) temp); // 否则输出字符
}
}
}
}
6.SequenceInputStream:有些情况下,当我们需要从多个输入流中向程序读入数据。此时,可以使用合并流,将多个输入流合并成一个SequenceInputStream流对象。SequenceInputStream会将与之相连接的流集组合成一个输入流并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。 合并流的作用是将多个源合并合一个源。其可接收枚举类所封闭的多个字节流对象。
Java代码
package com.hxw.io;
import java.io.*;
import java.util.Enumeration;
import java.util.Vector;
public class SequenceInputStreamTest {
/**
* @param args
* SequenceInputStream合并流,将与之相连接的流集组合成一个输入流并从第一个输入流开始读取,
* 直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
* 合并流的作用是将多个源合并合一个源。可接收枚举类所封闭的多个字节流对象。
*/
public static void main(String[] args) {
doSequence();
}
private static void doSequence() {
// 创建一个合并流的对象
SequenceInputStream sis = null;
// 创建输出流。
BufferedOutputStream bos = null;
try {
// 构建流集合。
Vector vector = new Vector();
vector.addElement(new FileInputStream(“D:\text1.txt”));
vector.addElement(new FileInputStream(“D:\text2.txt”));
vector.addElement(new FileInputStream(“D:\text3.txt”));
Enumeration e = vector.elements();
sis = new SequenceInputStream(e);
bos = new BufferedOutputStream(new FileOutputStream(“D:\text4.txt”));
// 读写数据
byte[] buf = new byte[1024];
int len = 0;
while ((len = sis.read(buf)) != -1) {
bos.write(buf, 0, len);
bos.flush();
}
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
} finally {
try {
if (sis != null)
sis.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (bos != null)
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
7.PrintStream 说这个名字可能初学者不熟悉,如果说System.out.print()你肯定熟悉,System.out这个对象就是PrintStream,这个我们不做过多示例
三、字符流(顾名思义,就是操作字符文件的流)
1.java 使用Unicode存储字符串,在写入字符流时我们都可以指定写入的字符串的编码。前面介绍了不用抛异常的处理字节型数据的流ByteArrayOutputStream,与之对应的操作字符类的类就是CharArrayReader,CharArrayWriter类,这里也会用到缓冲区,不过是字符缓冲区,一般讲字符串放入到操作字符的io流一般方法是
CharArrayReaderreader=mew CharArrayReader(str.toCharArray()); 一旦会去到CharArrayReader实例就可以使用CharArrayReader访问字符串的各个元素以执行进一步读取操作。不做例子
2.我们用FileReader,PrintWriter来做示范
Java代码
package com.hxw.io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.CharBuffer;
public class Print {
/**
* @param args
*/
public static void main(String[] args) {
// TODO自动生成的方法存根
char[] buffer=new char[512]; //一次取出的字节数大小,缓冲区大小
int numberRead=0;
FileReader reader=null; //读取字符文件的流
PrintWriter writer=null; //写字符到控制台的流
try {
reader=new FileReader(“D:/David/Java/java 高级进阶/files/copy1.txt”);
writer=new PrintWriter(System.out); //PrintWriter可以输出字符到文件,也可以输出到控制台
while ((numberRead=reader.read(buffer))!=-1) {
writer.write(buffer, 0, numberRead);
}
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}finally{
try {
reader.close();
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}
writer.close(); //这个不用抛异常
}
}
}
3.相对我们前面的例子是直接用FileReader打开的文件,我们这次使用链接流,一般比较常用的都用链接流,所谓链接流就是就多次对流的封装,这样能更好的操作个管理数据,(比如我们利用DataInputStream(BufferedInputStream(FileInputStream))将字节流层层包装后,我们可以读取readByte(),readChar()这样更加具体的操作,注意,该流属于字节流对字符进行操作,)字符流用CharArrayReader就可以了。下面的示例我们将用到j2se 5中的一个可变参数进行一个小度扩展。使用BufferedWriter 和BufferedReader用文件级联的方式进行写入,即将多个文件写入到同一文件中(自带缓冲区的输出输出流BufferedReader和BufferedWriter,该流最常用的属readLine()方法了,读取一行数据,并返回String)。
Java代码
package com.hxw.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Iterator;
public class FileConcatenate {
/**
* 包装类进行文件级联操作
*/
public static void main(String[] args) {
// TODO自动生成的方法存根
try {
concennateFile(args);
} catch (IOException e) {
// TODO自动生成的 catch 块
e.printStackTrace();
}
}
public static voidconcennateFile(String…fileName) throws IOException{
String str;
//构建对该文件您的输入流
BufferedWriter writer=new BufferedWriter(new FileWriter(“D:/David/Java/java 高级进阶/files/copy2.txt”));
for(String name: fileName){
BufferedReader reader=new BufferedReader(new FileReader(name));
while ((str=reader.readLine())!=null) {
writer.write(str);
writer.newLine();
}
}
}
}
4.Console类,该类提供了用于读取密码的方法,可以禁止控制台回显并返回char数组,对两个特性对保证安全有作用,平时用的不多,了解就行。
5.StreamTokenizer 类,这个类非常有用,它可以把输入流解析为标记(token), StreamTokenizer 并非派生自InputStream或者OutputStream,而是归类于io库中,因为StreamTokenizer只处理InputStream对象。
首先给出我的文本文件内容:
‘水上漂’
青青草
“i love wyhss”
{3211}
23223 3523
i love wyh ,。
. ,
下面是代码:
Java代码
package com.hxw.io;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.StreamTokenizer;
/**
* 使用StreamTokenizer来统计文件中的字符数
* StreamTokenizer 类获取输入流并将其分析为“标记”,允许一次读取一个标记。
* 分析过程由一个表和许多可以设置为各种状态的标志控制。
* 该流的标记生成器可以识别标识符、数字、引用的字符串和各种注释样式。
*
* 默认情况下,StreamTokenizer认为下列内容是Token: 字母、数字、除C和C++注释符号以外的其他符号。
* 如符号”/”不是Token,注释后的内容也不是,而”\”是Token。单引号和双引号以及其中的内容,只能算是一个Token。
* 统计文章字符数的程序,不是简单的统计Token数就万事大吉,因为字符数不等于Token。按照Token的规定,
* 引号中的内容就算是10页也算一个Token。如果希望引号和引号中的内容都算作Token,应该调用下面的代码:
* st.ordinaryChar(‘\”);
* st.ordinaryChar(‘\”‘);
*/
public class StreamTokenizerExample {
/**
* 统计字符数
* @param fileName 文件名
* @return 字符数
*/
public static void main(String[] args) {
String fileName = “D:/David/Java/java 高级进阶/files/copy1.txt”;
StreamTokenizerExample.statis(fileName);
}
public static long statis(String fileName) {
FileReader fileReader = null;
try {
fileReader = new FileReader(fileName);
//创建分析给定字符流的标记生成器
StreamTokenizer st = new StreamTokenizer(new BufferedReader(
fileReader));
//ordinaryChar方法指定字符参数在此标记生成器中是“普通”字符。
//下面指定单引号、双引号和注释符号是普通字符
st.ordinaryChar(‘\”);
st.ordinaryChar(‘\”‘);
st.ordinaryChar(‘/’);
String s;
int numberSum = 0;
int wordSum = 0;
int symbolSum = 0;
int total = 0;
//nextToken方法读取下一个Token.
//TT_EOF指示已读到流末尾的常量。
while (st.nextToken() !=StreamTokenizer.TT_EOF) {
//在调用 nextToken 方法之后,ttype字段将包含刚读取的标记的类型
switch (st.ttype) {
//TT_EOL指示已读到行末尾的常量。
case StreamTokenizer.TT_EOL:
break;
//TT_NUMBER指示已读到一个数字标记的常量
case StreamTokenizer.TT_NUMBER:
//如果当前标记是一个数字,nval字段将包含该数字的值
s = String.valueOf((st.nval));
System.out.println(“数字有:”+s);
numberSum ++;
break;
//TT_WORD指示已读到一个文字标记的常量
case StreamTokenizer.TT_WORD:
//如果当前标记是一个文字标记,sval字段包含一个给出该文字标记的字符的字符串
s = st.sval;
System.out.println(“单词有: “+s);
wordSum ++;
break;
default:
//如果以上3中类型都不是,则为英文的标点符号
s = String.valueOf((char) st.ttype);
System.out.println(“标点有: “+s);
symbolSum ++;
}
}
System.out.println(“数字有 ” + numberSum+”个”);
System.out.println(“单词有 ” + wordSum+”个”);
System.out.println(“标点符号有: ” + symbolSum+”个”);
total = symbolSum + numberSum +wordSum;
System.out.println(“Total = ” + total);
return total;
} catch (Exception e) {
e.printStackTrace();
return -1;
} finally {
if (fileReader != null) {
try {
fileReader.close();
} catch (IOException e1) {
}
}
}
}
}
运行结果为:
标点有: ‘
单词有: 水上漂
标点有: ‘
单词有: 青青草
标点有: “
单词有: i
单词有: love
单词有: wyh
单词有: ss
标点有: “
标点有: {
数字有:3211.0
标点有: }
数字有:23223.0
数字有:35.23
单词有: i
单词有: love
单词有: wyh
单词有: ,。
数字有:0.0
标点有: ,
数字有 4个
单词有 10个
标点符号有: 7个
Total= 21
我们从其中可以看到很多东西:
1.一个单独的小数点“.”是被当做一个数字来对待的,数字的值为0.0;
2.一串汉字只要中间没有符号(空格回车 分号等等)都是被当做一个单词的。中文的标点跟中文的汉字一样处理
3.如果不对引号化成普通字符,一个引号内的内容不论多少都被当做是一个标记。
4.该类能够识别英文标点
6. java io里面还有其他接口类似Serializable接口的子接口Externalizable接口,比Serializable复杂一些,这里不再介绍。还有关于java对象版本化的东西感兴趣的可以百度。java nio的东西这里没有涉及,后续会结合到线程再发一篇文章专门解析这个东西。
转载自:http://davidisok.iteye.com/blog/2106489
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134287.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
