大家好,又见面了,我是你们的朋友全栈君。
1. Introduction
在这篇文章中,我将介绍XGBoost(eXtreme Gradient Boosting),一种tree boosting的可扩展机器学习系统。这个系统可以作为开源的软件包使用。该系统的影响已经在大量的机器学习和数据挖掘挑战中被广泛地认可。这些获胜解决方案包括:商店销售预测; 高能物理事件分类; 网络文本分类; 顾客行为预测; 运动检测; 广告点击率预测; 恶意软件分类; 产品分类; 危险风险预测; 大规模的在线课程辍学率预测等。 虽然领域依赖数据分析和特征工程在这些解决方案中发挥着重要作用,但XGBoost是学习者的一致选择这一事实表明了XGBoost和tree boosting的影响和重要性。
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost正是本教程中介绍的boosted tree原则所激发的工具! 更重要的是,它在系统优化和机器学习原理方面都得到了深入的考虑。该库的目标是推动机器计算限制的极端,以提供可扩展,可移植和准确的库。XGBoost成功背后最重要的因素是它在所有场景中的可扩展性。 该系统在单台机器上运行速度比现有流行解决方案快十倍以上,并且在分布式或内存限制设置中可扩展至数十亿个示例。XGBoost的可扩展性归功于几个重要的系统和算法优化。 这些创新包括:
1.一种新颖的用于处理稀疏数据的树学习算法;
2.理论上合理的weighted quantile sketch过程使得能够在近似树学习中处理实例权重;
3.引入一个新颖的稀疏感知(sparsity-aware)算法用于并行树学习;
并行和分布式计算使学习更快,从而实现更快的模型探索;
4.我们提出了一种有效地缓存感知块结构用于核外树学习;
更重要的是,XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。
2.Tree Boosting in a Nutshell
我将在本节中介绍梯度树增强算法。 推导遵循现有文献中gradient boosting的相同思想。 XGboost对正则化目标进行了微小的改进,这些改进在实践中很有帮助。
2.1 正则化学习目标

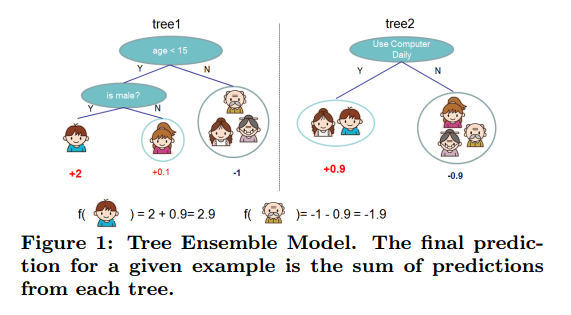
对于一个给定的有n个样本和m个特征的数据集,一个tree ensemble model使用K个累加的函数来预测输出:
,其中是CART(回归树)的空间。其中q代表每个树的结构,其可以将每个样本映射到对应的叶节点中,T是树中叶子节点的个数。每个对应于一个独立的树结构q和叶子权重w。不同于决策树,每个回归树在每一个叶节点上包含一个连续分数值,代表第i个结点的分数。是对样本x的打分,即模型预测值。对于每个样本,我们将使用多个树中决策规则来将它分类到叶节点中,并且通过累加对应叶子中的分数w来获得最终的预测(每个样本的预测结果就是每棵树预测分数的总和)。如Fig.1所示,为了学习模型中使用的函数集合,我们最小化下列正则化目标:
where
其中l是一个可微凸损失函数,度量预测值与目标值之间的差。第二项惩罚模型的复杂度(所有回归树的复杂度之和)。该项中包含了两个部分,一个是叶子结点的总数,一个是叶子结点得到的L2正则化项。这个额外的正则化项能够平滑每个叶节点的学习权重来避免过拟合。直观地,正则化的目标将倾向于选择采用简单和预测函数的模型。当正则化参数为零时,这个函数就变为传统的gradient tree boosting。
2.2 Gradient Tree Boosting
等式2中的树集合模型以函数作为参数,所以不能直接使用传统的优化方法进行优化。而是采用加法学习方式(Additve training)训练,开始于一个常数预测,每次增加的一个新的函数学习当前的树,找到当前最佳的树模型加入带整体模型中:

因此,关键在于学习第t棵树,寻找最佳的,增加并最小化目标函数,其中是在第t次迭代时样本i的预测值:
第t轮的模型预测等于前t-1轮的模型预测加上。
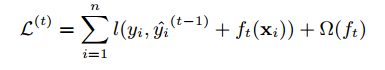
这意味着贪婪地添加最能改善我们模型的。对误差函数进行二阶泰勒近似展开:
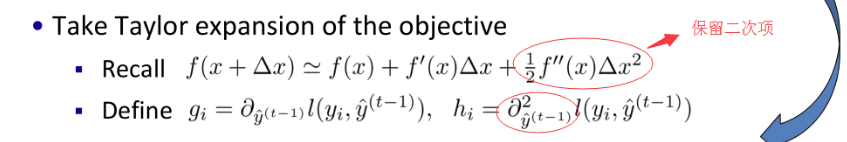
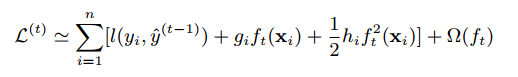
在损失函数中,gi和hi是一阶和二阶梯度统计。这就是XGboost的特点:通过这种近似,可以自行定义一些损失函数(例如,平方损失,逻辑损失),只要保证二阶可导。将常数项移除得到了第t步的简化的目标函数,:
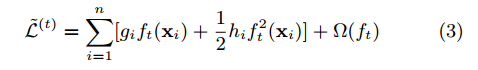
接着重新定义每棵树,通过定义为叶子节点j中的样本集合。我们可以重写等式(3)通过扩展惩罚项,根据叶节点重新组合目标函数:

对于一个固定的结构q(x),我们可以计算叶节点j的最优权重:
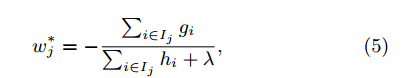
并且计算对应的最优值通过:
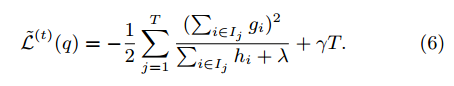
等式(6)可以被用作一个评分函数来度量树结构q的质量。该评分是针对更广泛的目标函数得出的,类似于评估决策树的杂质评分。
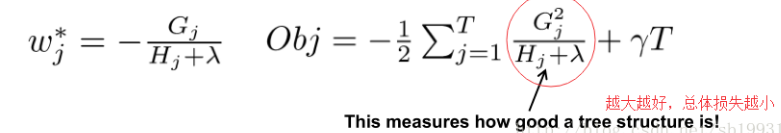
如Fig.2所示,我们只需要将每个叶子结点的梯度与二阶梯度相加,接着应用评分公式来获得质量分数。

但是通常不可能枚举所有可能的树结构q。 而是使用从单个叶结点开始,并迭代地向树添加分支的贪心算法。 假设和是拆分后左右节点的实例集。,拆分之后的损失减少为:
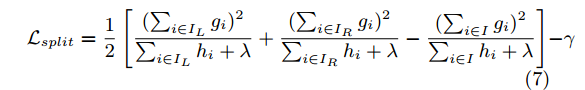
这个公式通常被用于评估分割候选集(选择最优分割点),其中前两项分别是切分后左右子树的的分支之和,第三项是未切分前该父节点的分数值,最后一项是引入额外的叶节点导致的复杂度。
2.3 Shinkage and Column Subsampling
除了第二节中提到的正则化目标,还另外使用了两种技术来进一步防止过度拟合。 第一种技术是收缩(Shinkage),在tree boosting的每个步骤之后,收缩比例通过因子η新增加权重。 与随机优化中的学习速率类似,shinkage降低了每棵独立树的影响,并为将来的树木留出了空间来优化模型。第二种技术是列特征抽样(Column Subsampling)。 这种技术用于RandomForest,它在商业软件TreeNet中实现,用于gradient boosting,但在现有的开源软件包中没有实现。 根据用户反馈,使用列抽样比传统的行抽样(也支持)更加能够防止过度拟合,而且还加速了稍后描述的并行算法的计算。
2.4 xgboost与gbdt对比
- 传统的GBDT以CART作为基分类器,xgboost还支持线性分类器。可以通过booster[default=gbtree]设置参数:gbtree:tree-based models;gblinear:linear models;
- GBDT只用到了一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶与二阶导数,并且指出自定义代价函数,只要它们可导。
- xgboost优于GBDT的一个特性是它在代价函数中加入了正则化项,用于控制模型的复杂度,新增的是叶子节点输出L2平滑。学习出来的模型更加简单,防止过拟合。
- 新增了shronkage和column subsampling,为了防止过拟合。
3.分裂查找算法(Split Finding Algorithms)
3.1 Basic Exact Greedy Algorithm
树学习中的关键问题之一是找到方程(7)所示的最佳分裂。为此,分裂查找算法枚举所有特征上的所有可能分割。我们称之为精确的贪心算法(exact greedy algorithm)。大多数现有的单机tree boosting实现,例如scikit-learn,R‘s gbm 以及XGBoost的单机版本都支持精确的贪心算法。 精确的贪心算法如Alg.1所示,计算连续特征的所有可能分裂在计算上要求很高。 为了有效地执行此操作,算法必须首先分别根据每个特征值对所有数据进行排序,并按排序顺序访问数据,以便累积等式(7)中结构分数的梯度统计数据。

3.2近似算法(Approximate Algorithm)
Exact greedy algorithm非常强大,因为它贪婪地枚举了所有可能的分裂点。 但是,当数据不能完全地送入内存中时,不可能有效地这样做。 在分布式设置中也会出现同样的问题。 为了在这两个设置中支持有效的gradient tree boosting,需要一个近似算法。
我们总结一个近似框架如算法2所示。总之,该算法首先根据特征分布的百分位数(percentiles)提出候选分裂点(具体标准将在3.3节中给出)。然后,该算法将连续特征映射到由这些候选点分割的桶中,汇总统计信息并根据汇总的信息在提案中找到最佳解决方案。

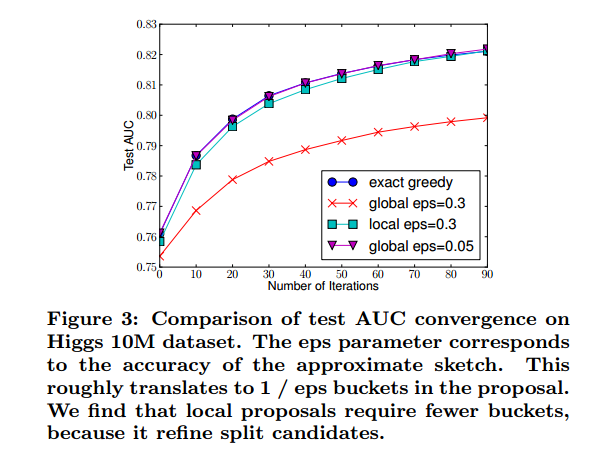
该算法有两种变体,具体取决于提议的时间。 全局变体在树构建的初始阶段提出所有候选分裂,并在所有级别使用相同的分裂查找提议。 而局部变体在每次分裂之后会重新提出。 全局方法比局部方法需要更少的提议步骤。然而,全局提议通常需要更多的候选点,因为候选点在每次拆分后都没有得到完善。 局部提案在拆分后对候选点进行了细化,并且可能更适合更深层次的树木。 图3给出了在Higgs boson数据集上不同算法的比较。我们发现局部提案确实需要较少的候选者。 当给予足够多的候选,全局提案可以与局部提案一样准确。
用于分布式树学习的大多数现有近似算法也遵循该框架。 值得注意的是,也可以直接构建梯度统计的近似直方图。 也可以使用分箱策略的其他变体而不是分位数。 分位数策略受益于可分发和可重构,我们将在下一小节中详细介绍。从Fig.3中,我们还发现,在给定合理的近似水平的情况下,分位数策略可以获得与精确贪心是算法相同的精度。该系统有效地支持单机设置的精确贪婪,以及所有设置的局部和全局提议方法的近似算法。用户可以根据自己的需要自由选择方法。
3.3 分布式加权直方图(Weighted Quantile Sketch)
可并行的近似直方图算法,树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。近似算法中的一个重要步骤就是提出候选分裂点。通常,特征的百分位数用于使候选点均匀地分布在数据上。正式的,让multi-set 代表每个训练样本的第k个特征值和二阶梯度统计。我们可以定义一个排名函数::
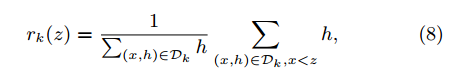
代表特征值k小于z的样本的比例。目标是找到候选划分点,例如:
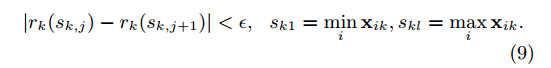
(根据特征k对数据进行划分,sk1代表具有最小k特征值的样本)在这里是一个近似因子。直观的,这意味着这有大约个候选点。每个数据点由加权。为什么代表权重?我们可以重写等式3为:
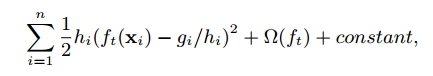
这是具有标签和权重的加权平方损失。 对于大型数据集,找到满足条件的候选分割是非常重要的。 当每个实例具有相等的权重时,称为quantile sketch的现有算法解决了该问题。 但是,对于加权数据集来说,不存在现有的quantile sketch。 因此,大多数现有的近似算法要么对随机数据子集进行排序(但是可能会出错),要么使用没有理论保证的启发式算法进行排序。
为了解决这个问题,我们介绍一种新颖的分布式加权quantile sketch 算法能够处理加权数据,并且具有一个可证明的理论保证(provable theoretical guarantee)。一般的想法是提出一种支持合并和修剪操作的数据结构,每个操作都被证明可以保持一定的准确度。
3.4 稀疏感知分裂发现(Sparsity-aware Split Finding)
在许多现实世界的问题中,输入x稀疏是很常见的。 稀疏性有多种可能的原因:1)数据中存在缺失值; 2)统计中频繁的零项; 3)特征工程,例如one-hot编码。 使算法了解数据中的稀疏模式非常重要。 为了做到这一点,我们建议在每个树节点中添加一个默认方向,如图4所示。当稀疏矩阵x中缺少一个值时,样本被分类为默认方向。
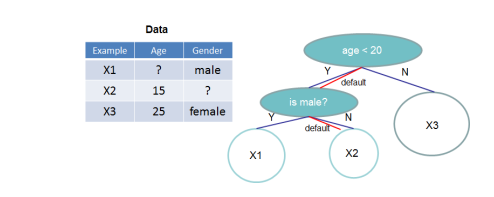
图4:具有默认方向的树结构,当需要区分的特征缺失时,样本将会分类到默认的方向。
每个分支中有两种默认方向选择,最佳默认方向是从数据中学来的。 该算法显示在Al.3中,关键的改进是只访问非缺失的条目。 所提出的算法将不存在的值视为缺失值并且学习处理缺失值的最佳方向。 当非存在对应于用户指定值时,也可以通过将枚举限制为一致的解决方案来应用相同的算法。

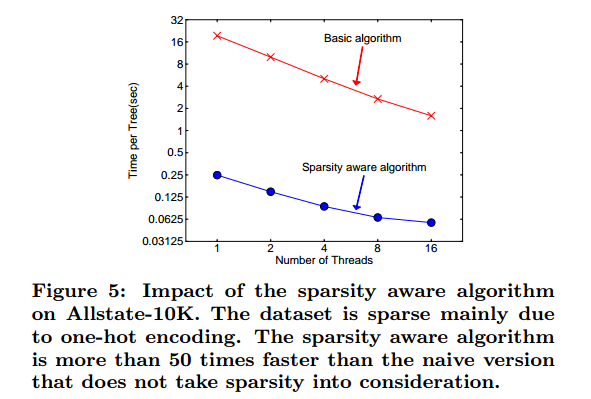
据我们所知,大多数现有的树学习算法要么仅针对稠密数据进行优化,要么需要特定的过程来处理限制性的情况,例如类别编码。 XGBoost以统一的方式处理所有稀疏模式。 更重要的是,我们的方法利用稀疏性使计算复杂度与输入中的非缺失条目的数量成线性关系。 图5显示了对Allstate-10K数据集的稀疏性和初始实现的比较(第6节中给出的数据集的描述)。我们发现稀疏感知算法运行速度比初始版本快50倍。 这证实了稀疏感知算法的重要性。
4.System design
4.1 Column Block for Parallel Learning
xgboost的并行不是tree粒度的并行,而是特征力度上的。决策树学习中最耗时的部分是将数据按照特征值进行排序。为了降低排序成本,xgboost将数据存储在内存单元中,我们称之为块(block)。每个块中的数据以压缩列(CSC)格式存储,每列按相应的特征值排序。此输入数据布局仅需要在训练之前计算一次,并且可以在以后的迭代中重复使用,大大的减少了计算量。这个block结构使得并行变成了可能。在进行结点的分裂时,需要计算每个特征的增益,最终选择增益最大的那个特征去做分裂,那么各个特征的增益计算就可以多进程进行。
在精确的贪婪算法中,我们将整个数据集存储在一个块中,并通过线性扫描预先排序的条目来运行拆分搜索算法。对所有叶子集体的进行拆分查找,因此对块进行一次扫描将收集所有叶子分支中的划分候选者的统计数据。图6显示了我们如何将数据集转换为格式并使用块结构找到最佳分割。
当使用近似算法时,块结构也是有效的。在这种情况下可以使用多个块,每个块对应于数据集中的行的子集。不同的块可以跨机器分布,也可以在核外设置中存储在磁盘上。使用排序结构,quantile查找步骤变为对排序列的线性扫描。这对于候选者经常在每个分支处生成的局部提议算法尤其有用,其中。直方图聚合中的二分搜索也变为线性时间合并样式算法。
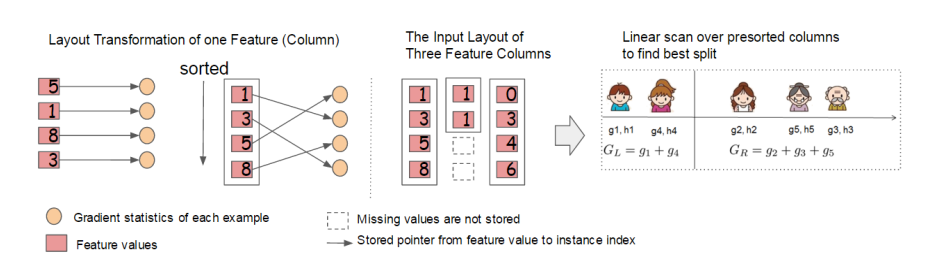
图6.并行计算的block结构。块中的每一列都根据对应的特征值进行排序。块中一列的线性扫描足以枚举所有分割点。
收集每列的统计数据可以并行化,提供了一种用于拆分查找的并行算法。 重要的是,列块结构还支持列子采样,因为很容易在块中选择列的子集。
4.2 缓存感知访问(Cache-aware Access)
虽然所提出的block结构有助于优化分裂查找的计算复杂度,但是新算法需要通过行索引间接提取梯度统计由于这些值是按特征的顺序访问的。 这是一种非连续的内存访问。 分裂枚举的简单实现在累积和非连续存储器read/write操作之间引入了immediate read/write依赖性(参见图8)。 当梯度统计信息不适合CPU缓存并发生缓存未命中时,这会减慢拆分查找速度。

图8.短距离数据依赖模式,可能由于缓存未命中而导致停顿。
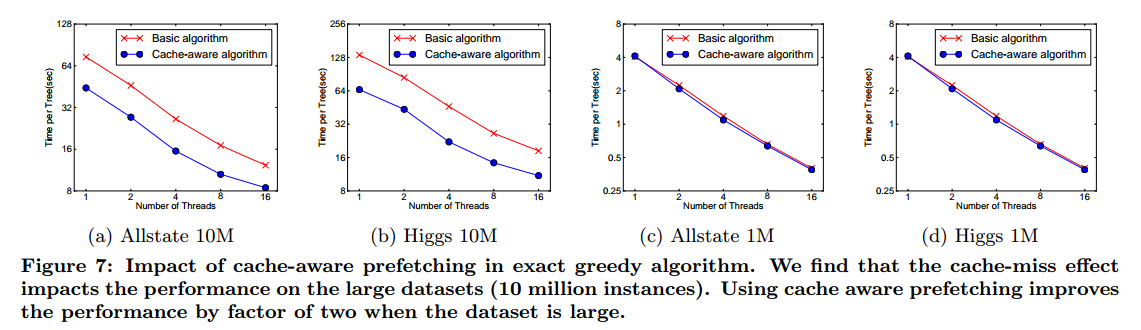
对于精确的贪心算法,我们可以通过缓存感知预取算法(cache-aware prefetching algorith,)来缓解这个问题。 具体来说,我们在每个线程中分配一个内部缓冲区,获取梯度统计信息到其中,然后以小批量(mini-batch)方式执行累积。 此预取将direct read/write依赖性更改为更长的依赖性,并在有大量行数时帮助减少运行时开销。 图7给出了Higgs和Allstate数据集上缓存感知与非缓存感知算法的比较。 我们发现,当数据集很大时,精确贪婪算法的缓存感知实现的运行速度是普通版本的两倍。
对于近似算法,我们通过选择正确的块大小来解决问题。 我们将块大小定义为块中包含的最大示例数,因为这反映了梯度统计的高速缓存存储成本。 选择过小的块大小会导致每个线程的工作量很小,并导致低效的并行化。 另一方面,过大的块会导致缓存未命中,因为梯度统计信息不送入CPU缓存。 块大小的良好选择平衡这两个因素。 我们比较了在两个数据集上块大小的各种选择。 结果如图9所示。该结果验证了我们的讨论,并表明每个块选择个示例可以平衡缓存属性和并行化。
4.3 用于核外计算的块(Blocks for Out-of-core Computation)
我们系统的一个目标是充分利用机器的资源来实现可扩展的学习。 除处理器和内存外,利用磁盘空间处理没有送进主存的数据也很重要。 为了实现核外计算,我们将数据分成多个块并将每个块存储在磁盘上。 在计算过程中,使用独立的线程将块预取到主内存缓冲区是很重要的,因此计算可以与磁盘读取同时发生。 但是,这并不能完全解决问题,因为磁盘读取占用了大部分计算时间。 减少开销并增加磁盘IO的吞吐量非常重要。 我们主要使用两种技术来改进核外计算。
Block Compression:我们使用的第一种技术是块压缩。 该块由列压缩,并在加载到主存时由独立线程动态解压缩。 这有助于将解压缩中的一些计算与磁盘读取成本进行交换。 我们使用通用压缩算法来压缩特征值。 对于行索引,我们通过块的开始索引来减去行索引,并使用16位整数来存储每个偏移量。 每块需要个样本,这被证实是一个很好的设置。 在我们测试的大多数数据集中,我们实现了大约26%到29%的压缩比。
Block Sharding:第二种技术是以另一种方式将数据分片到多个磁盘上。 为每个磁盘分配一个预取程器线程,并将数据提取到内存缓冲区中。 然后,训练线程交替地从每个缓冲区读取数据。 这有助于在多个磁盘可用时增加磁盘读取的吞吐量。
5. 相关工作
我们的系统实现梯度增强,在函数空间中执行额外的优化。梯度树增强已成功用于分类,学习排名,结构化预测以及其他领域。 XGBoost采用正则化模型来防止过度拟合。 这类似于以前关于正则化贪婪森林的工作,但简化了并行化的目标和算法。 列采样是一种从RandomForest 借来的简单而有效的技术。 虽然稀疏性学习在其他类型的模型中是必不可少的,例如线性模型,但很少有关于树学习的工作以原则的方式考虑了这个方面。 该文提出的算法是第一种处理各种稀疏模式的统一方法。
有几个关于并行树学习的现有工作。大多数这些算法都属于本文所述的近似框架。值得注意的是,也可以按列对数据进行分区,并应用精确的贪婪算法。我们的框架也支持这一点,并且可以使用诸如缓存感知预知之类的技术来使这种类型的算法受益。虽然大多数现有工作都集中在并行化的算法方面,但我们的工作在两个未开发的系统方向上得到了改进:核外计算和缓存感知学习。这为我们提供了有关如何联合优化系统和算法的见解,并提供了一个端到端系统,可以处理具有非常有限的计算资源的大规模问题。表1中总结了系统与现有开源实现之间的比较。
Quantile summary是数据库社区中的经典问题。然而,近似树提升算法揭示了一个更普遍的问题-在加权数据上找到分位数。据我们所知,本文提出的加权分位数草图是解决该问题的第一种方法。加权分位数摘要也不是特定于树学习的,并且可以在将来有益于数据科学和机器学习中的其他应用。
System Implementation: XGBoost实现为开源软件包。该包是便携式和可重复使用的。 它支持各种加权分类和排名目标函数,以及用户定义的目标函数。 流行的语言都支持,例如python,R,Julia,并且自然地与语言本地数据科学管道例如scikit-learn集成。 分布式版本构建在rabit库之上,用于allreduce。 XGBoost的可移植性使其可用于许多生态系统,而不仅仅是只能绑定到特定平台。分布式XGBoost在Hadoop,MPI Sun Grid引擎上本机运行。最近,还在jvm bigdata堆栈上启用了分布式XGBoost,例如Flink和Spark。 分布式版本也已集成到阿里巴巴的云平台天池中。相信未来会有更多的整合。
6. 总结
在本文中,描述了在构建XGBoost时学到的经验教训,XGBoost是一个可扩展的tree booosting系统,被数据科学家广泛使用,并提供了许多问题的最新结果。 提出了一种用于处理稀疏数据的新型稀疏感知算法,和用于近似学习的理论上合理的加权分位数草图(weighted quantile sketch)。 我们的经验表明,缓存访问模式,数据压缩和分片是构建可扩展的端到端系统以实现tree boosting的基本要素。 这些元素也可以应用于其他机器学习系统。通过结合这些见解,XGBoost能够使用最少量的资源解决现实世界的规模问题。
参考资料:
原始论文:XGBoost: A Scalable Tree Boosting System
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134279.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
