大家好,又见面了,我是你们的朋友全栈君。
1 本代码功能
用多目标粒子群算法(mopso)寻找pareto最优解集
2 算法介绍
2.1 简单步骤:
(1)初始化群体粒子群的位置和速度,计算适应值
(2)根据pareto支配原则,计算得到Archive 集(存放当前的非劣解)
(3)计算pbest
(4)计算Archive集中的拥挤度
(5)在Archive集选择gbest
(6)更新粒子的速度、位置、适应值
(7)更新Archive集(还要注意防止溢出)
(8)满足结束条件,则结束;否则,转到第(3)步继续循环。
2.2 算法的详解可参考如下博客:
2.2.1 对多目标粒子群算法MOPSO的理解,https://blog.csdn.net/ture_2010/article/details/18180183
2.2.2 MOPSO算法学习总结,https://blog.csdn.net/sbcypress/article/details/50727907
2.2.3 Handling multiple objectives with particle swarm optimization
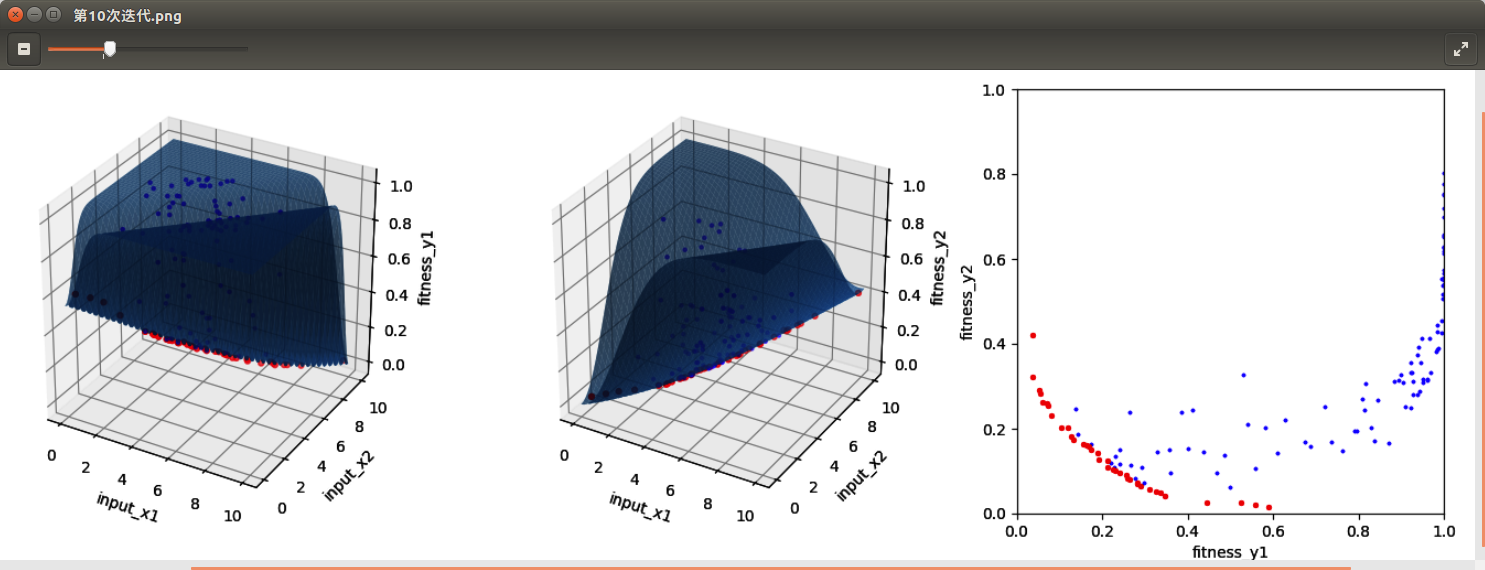
3 简单图示
为了便于图示观察,本源码使用一组简单的测试函数:输入坐标为2维(input_x1,input_x2),输出适应值为2维(fitness_y1,fitness_y2)。如下图所示,经过10轮迭代后,pareto边界已见轮廓,红 色点代表pareto最优解集。

4 代码如下
4.1 main.py
#encoding: utf-8
import numpy as np
from mopso import *
def main():
w = 0.8 #惯性因子
c1 = 0.1 #局部速度因子
c2 = 0.1 #全局速度因子
particals = 100 #粒子群的数量
cycle_ = 30 #迭代次数
mesh_div = 10 #网格等分数量
thresh = 300 #外部存档阀值
min_ = np.array([0,0]) #粒子坐标的最小值
max_ = np.array([10,10]) #粒子坐标的最大值
mopso_ = Mopso(particals,w,c1,c2,max_,min_,thresh,mesh_div) #粒子群实例化
pareto_in,pareto_fitness = mopso_.done(cycle_) #经过cycle_轮迭代后,pareto边界粒子
np.savetxt("./img_txt/pareto_in.txt",pareto_in)#保存pareto边界粒子的坐标
np.savetxt("./img_txt/pareto_fitness.txt",pareto_fitness) #打印pareto边界粒子的适应值
print "\n","pareto边界的坐标保存于:/img_txt/pareto_in.txt"
print "pareto边界的适应值保存于:/img_txt/pareto_fitness.txt"
print "\n","迭代结束,over"
if __name__ == "__main__":
main()
4.2 mopso.py
#encoding: utf-8
import numpy as np
from fitness_funs import *
import init
import update
import plot
class Mopso:
def __init__(self,particals,w,c1,c2,max_,min_,thresh,mesh_div=10):
self.w,self.c1,self.c2 = w,c1,c2
self.mesh_div = mesh_div
self.particals = particals
self.thresh = thresh
self.max_ = max_
self.min_ = min_
self.max_v = (max_-min_)*0.05 #速度下限
self.min_v = (max_-min_)*0.05*(-1) #速度上限
self.plot_ = plot.Plot_pareto()
def evaluation_fitness(self):
#计算适应值
fitness_curr = []
for i in range((self.in_).shape[0]):
fitness_curr.append(fitness_(self.in_[i]))
self.fitness_ = np.array(fitness_curr) #适应值
def initialize(self):
#初始化粒子坐标
self.in_ = init.init_designparams(self.particals,self.min_,self.max_)
#初始化粒子速度
self.v_ = init.init_v(self.particals,self.min_v,self.max_v)
#计算适应值
self.evaluation_fitness()
#初始化个体最优
self.in_p,self.fitness_p = init.init_pbest(self.in_,self.fitness_)
#初始化外部存档
self.archive_in,self.archive_fitness = init.init_archive(self.in_,self.fitness_)
#初始化全局最优
self.in_g,self.fitness_g = init.init_gbest(self.archive_in,self.archive_fitness,self.mesh_div,self.min_,self.max_,self.particals)
def update_(self):
#更新粒子坐标、粒子速度、适应值、个体最优、外部存档、全局最优
self.v_ = update.update_v(self.v_,self.min_v,self.max_v,self.in_,self.in_p,self.in_g,self.w,self.c1,self.c2)
self.in_ = update.update_in(self.in_,self.v_,self.min_,self.max_)
self.evaluation_fitness()
self.in_p,self.fitness_p = update.update_pbest(self.in_,self.fitness_,self.in_p,self.fitness_p)
self.archive_in,self.archive_fitness = update.update_archive(self.in_,self.fitness_,self.archive_in,self.archive_fitness,self.thresh,self.mesh_div,self.min_,self.max_,self.particals)
self.in_g,self.fitness_g = update.update_gbest(self.archive_in,self.archive_fitness,self.mesh_div,self.min_,self.max_,self.particals)
def done(self,cycle_):
self.initialize()
self.plot_.show(self.in_,self.fitness_,self.archive_in,self.archive_fitness,-1)
for i in range(cycle_):
self.update_()
self.plot_.show(self.in_,self.fitness_,self.archive_in,self.archive_fitness,i)
return self.archive_in,self.archive_fitness4.3 init.py
#encoding: utf-8
import random
import numpy as np
import archiving
import pareto
def init_designparams(particals,in_min,in_max):
in_dim = len(in_max) #输入参数的维度
in_temp = np.zeros((particals,in_dim))
for i in range(particals):
for j in range(in_dim):
in_temp[i,j] = random.uniform(0,1)*(in_max[j]-in_min[j])+in_min[j]
return in_temp
def init_v(particals,v_max,v_min):
v_dim = len(v_max) #输入参数的维度
v_ = np.zeros((particals,v_dim))
for i in range(particals):
for j in range(v_dim):
v_[i,j] = random.uniform(0,1)*(v_max[j]-v_min[j])+v_min[j]
return v_
def init_pbest(in_,fitness_):
return in_,fitness_
def init_archive(in_,fitness_):
pareto_c = pareto.Pareto_(in_,fitness_)
curr_archiving_in,curr_archiving_fit = pareto_c.pareto()
return curr_archiving_in,curr_archiving_fit
def init_gbest(curr_archiving_in,curr_archiving_fit,mesh_div,min_,max_,particals):
get_g = archiving.get_gbest(curr_archiving_in,curr_archiving_fit,mesh_div,min_,max_,particals)
return get_g.get_gbest()
4.4 update.py
#encoding: utf-8
import numpy as np
import random
import pareto
import archiving
def update_v(v_,v_min,v_max,in_,in_pbest,in_gbest,w,c1,c2):
#更新速度值
v_temp = w*v_ + c1*(in_pbest-in_) + c2*(in_gbest-in_)
#如果粒子的新速度大于最大值,则置为最大值;小于最小值,则置为最小值
for i in range(v_temp.shape[0]):
for j in range(v_temp.shape[1]):
if v_temp[i,j]<v_min[j]:
v_temp[i,j] = v_min[j]
if v_temp[i,j]>v_max[j]:
v_temp[i,j] = v_max[j]
return v_temp
def update_in(in_,v_,in_min,in_max):
#更新位置参数
in_temp = in_ + v_
#大于最大值,则置为最大值;小于最小值,则置为最小值
for i in range(in_temp.shape[0]):
for j in range(in_temp.shape[1]):
if in_temp[i,j]<in_min[j]:
in_temp[i,j] = in_min[j]
if in_temp[i,j]>in_max[j]:
in_temp[i,j] = in_max[j]
return in_temp
def compare_pbest(in_indiv,pbest_indiv):
num_greater = 0
num_less = 0
for i in range(len(in_indiv)):
if in_indiv[i] > pbest_indiv[i]:
num_greater = num_greater +1
if in_indiv[i] < pbest_indiv[i]:
num_less = num_less +1
#如果当前粒子支配历史pbest,则更新,返回True
if (num_greater>0 and num_less==0):
return True
#如果历史pbest支配当前粒子,则不更新,返回False
elif (num_greater==0 and num_less>0):
return False
else:
#如果互不支配,则按照概率决定是否更新
random_ = random.uniform(0.0,1.0)
if random_ > 0.5:
return True
else:
return False
def update_pbest(in_,fitness_,in_pbest,out_pbest):
for i in range(out_pbest.shape[0]):
#通过比较历史pbest和当前粒子适应值,决定是否需要更新pbest的值。
if compare_pbest(fitness_[i],out_pbest[i]):
out_pbest[i] = fitness_[i]
in_pbest[i] = in_[i]
return in_pbest,out_pbest
def update_archive(in_,fitness_,archive_in,archive_fitness,thresh,mesh_div,min_,max_,particals):
#首先,计算当前粒子群的pareto边界,将边界粒子加入到存档archiving中
pareto_1 = pareto.Pareto_(in_,fitness_)
curr_in,curr_fit = pareto_1.pareto()
#其次,在存档中根据支配关系进行第二轮筛选,将非边界粒子去除
in_new = np.concatenate((archive_in,curr_in),axis=0)
fitness_new = np.concatenate((archive_fitness,curr_fit),axis=0)
pareto_2 = pareto.Pareto_(in_new,fitness_new)
curr_archiving_in,curr_archiving_fit = pareto_2.pareto()
#最后,判断存档数量是否超过了存档阀值。如果超过了阀值,则清除掉一部分(拥挤度高的粒子被清除的概率更大)
if((curr_archiving_in).shape[0] > thresh):
clear_ = archiving.clear_archiving(curr_archiving_in,curr_archiving_fit,mesh_div,min_,max_,particals)
curr_archiving_in,curr_archiving_fit = clear_.clear_(thresh)
return curr_archiving_in,curr_archiving_fit
def update_gbest(archiving_in,archiving_fit,mesh_div,min_,max_,particals):
get_g = archiving.get_gbest(archiving_in,archiving_fit,mesh_div,min_,max_,particals)
return get_g.get_gbest()4.5 archiving.py
#encoding: utf-8
import numpy as np
import random
class mesh_crowd(object):
def __init__(self,curr_archiving_in,curr_archiving_fit,mesh_div,min_,max_,particals):
self.curr_archiving_in = curr_archiving_in #当前存档中所有粒子的坐标
self.curr_archiving_fit = curr_archiving_fit #当前存档中所有粒子的坐标
self.mesh_div = mesh_div #等分因子,默认值为10等分
self.num_ = self.curr_archiving_in.shape[0] #cundangzhong######粒子数量
self.particals = particals ########
self.id_archiving = np.zeros((self.num_)) #各个粒子的id编号,检索位与curr_archiving的检索位为相对应
self.crowd_archiving = np.zeros((self.num_)) #拥挤度矩阵,用于记录当前粒子所在网格的总粒子数,检索位与curr_archiving的检索为相对应
self.probability_archiving = np.zeros((self.num_)) #各个粒子被选为gbest的概率,检索位与curr_archiving的检索位为相对应
self.gbest_in = np.zeros((self.particals,self.curr_archiving_in.shape[1])) #初始化gbest矩阵_坐标
self.gbest_fit = np.zeros((self.particals,self.curr_archiving_fit.shape[1])) #初始化gbest矩阵_适应值
self.min_ = min_
self.max_ = max_
def cal_mesh_id(self,in_):
#计算网格编号id
#首先,将每个维度按照等分因子进行等分离散化,获取粒子在各维度上的编号。按照10进制将每一个维度编号等比相加(如过用户自定义了mesh_div_num的值,则按照自定义),计算出值
id_ = 0
for i in range(self.curr_archiving_in.shape[1]):
id_dim = int((in_[i]-self.min_[i])*self.num_/(self.max_[i]-self.min_[i]))
id_ = id_ + id_dim*(self.mesh_div**i)
return id_
def divide_archiving(self):
#进行网格划分,为每个粒子定义网格编号
for i in range(self.num_):
self.id_archiving[i] = self.cal_mesh_id(self.curr_archiving_in[i])
def get_crowd(self):
index_ = (np.linspace(0,self.num_-1,self.num_)).tolist() #定义一个数组存放粒子集的索引号,用于辅助计算
index_ = map(int, index_)
while(len(index_) > 0):
index_same = [index_[0]] #存放本次子循环中与index[0]粒子具有相同网格id所有检索位
for i in range(1,len(index_)):
if self.id_archiving[index_[0]] == self.id_archiving[index_[i]]:
index_same.append(index_[i])
number_ = len(index_same) #本轮网格中的总粒子数
for i in index_same: #更新本轮网格id下的所有粒子的拥挤度
self.crowd_archiving[i] = number_
index_.remove(i) #删除本轮网格所包含的粒子对应的索引号,避免重复计算
class get_gbest(mesh_crowd):
def __init__(self,curr_archiving_in,curr_archiving_fit,mesh_div_num,min_,max_,particals):
super(get_gbest,self).__init__(curr_archiving_in,curr_archiving_fit,mesh_div_num,min_,max_,particals)
self.divide_archiving()
self.get_crowd()
def get_probability(self):
for i in range(self.num_):
self.probability_archiving = 10.0/(self.crowd_archiving**3)
self.probability_archiving = self.probability_archiving/np.sum(self.probability_archiving) #所有粒子的被选概率的总和为1
def get_gbest_index(self):
random_pro = random.uniform(0.0,1.0) #生成一个0到1之间的随机数
for i in range(self.num_):
if random_pro <= np.sum(self.probability_archiving[0:i+1]):
return i #返回检索值
def get_gbest(self):
self.get_probability()
for i in range(self.particals):
gbest_index = self.get_gbest_index()
self.gbest_in[i] = self.curr_archiving_in[gbest_index] #gbest矩阵_坐标
self.gbest_fit[i] = self.curr_archiving_fit[gbest_index] #gbest矩阵_适应值
return self.gbest_in,self.gbest_fit
class clear_archiving(mesh_crowd):
def __init__(self,curr_archiving_in,curr_archiving_fit,mesh_div_num,min_,max_,particals):
super(get_gbest,self).__init__(curr_archiving_in,curr_archiving_fit,mesh_div_num,min_,max_)
self.divide_archiving()
self.get_crowd()
def get_probability(self):
for i in range(self.num_):
self.probability_archiving = self.crowd_archiving**2
def get_clear_index(self): #按概率清除粒子,拥挤度高的粒子被清除的概率越高
len_clear = (self.curr_archiving_in).shape[0] - self.thresh #需要清除掉的粒子数量
clear_index = []
while(len(clear_index)<len_clear):
random_pro = random.uniform(0.0,np.sum(self.probability_archiving)) #生成一个0到1之间的随机数
for i in range(self.num_):
if random_pro <= np.sum(self.probability_archiving[0:i+1]):
if i not in clear_index:
clear_index.append(i) #记录检索值
return clear_index
def clear_(self,thresh):
self.thresh = thresh
self.archiving_size = archiving_size
self.get_probability()
clear_index = get_clear_index()
self.curr_archiving_in = np.delete(self.curr_archiving_in[gbest_index],clear_index,axis=0) #初始化gbest矩阵_坐标
self.curr_archiving_fit = np.delete(self.curr_archiving_fit[gbest_index],clear_index,axis=0) #初始化gbest矩阵_适应值
return self.curr_archiving_in,self.curr_archiving_fit4.6 pareto.py
#encoding: utf-8
import numpy as np
def compare_ (fitness_curr,fitness_ref):
#判断fitness_curr是否可以被fitness_ref完全支配
for i in range(len(fitness_curr)):
if fitness_curr[i] < fitness_ref[i]:
return True
return False
def judge_(fitness_curr,fitness_data,cursor):
#当前粒子的适应值fitness_curr与数据集fitness_data进行比较,判断是否为非劣解
for i in range(len(fitness_data)):
if i == cursor:
continue
#如果数据集中存在一个粒子可以完全支配当前解,则证明当前解为劣解,返回False
if compare_(fitness_curr,fitness_data[i]) == False:
return False
return True
class Pareto_:
def __init__(self,in_data,fitness_data):
self.in_data = in_data #粒子群坐标信息
self.fitness_data = fitness_data #粒子群适应值信息
self.cursor = -1 #初始化游标位置
self.len_ = in_data.shape[0] #粒子群的数量
self.bad_num = 0 #非优解的个数
def next(self):
#将游标的位置前移一步,并返回所在检索位的粒子坐标、粒子适应值
self.cursor = self.cursor+1
return self.in_data[self.cursor],self.fitness_data[self.cursor]
def hasNext(self):
#判断是否已经检查完了所有粒子
return self.len_ > self.cursor + 1 + self.bad_num
def remove(self):
#将非优解从数据集删除,避免反复与其进行比较。
self.fitness_data = np.delete(self.fitness_data,self.cursor,axis=0)
self.in_data = np.delete(self.in_data,self.cursor,axis=0)
#游标回退一步
self.cursor = self.cursor-1
#非优解个数,加1
self.bad_num = self.bad_num + 1
def pareto(self):
while(self.hasNext()):
#获取当前位置的粒子信息
in_curr,fitness_curr = self.next()
#判断当前粒子是否pareto最优
if judge_(fitness_curr,self.fitness_data,self.cursor) == False :
self.remove()
return self.in_data,self.fitness_data
4.7 fitness_funs.py
#encoding: utf-8
import numpy as np
#为了便于图示观察,试验测试函数为二维输入、二维输出
#适应值函数:实际使用时请根据具体应用背景自定义
def fitness_(in_):
degree_45 = ((in_[0]-in_[1])**2/2)**0.5
degree_135 = ((in_[0]+in_[1])**2/2)**0.5
fit_1 = 1-np.exp(-(degree_45)**2/0.5)*np.exp(-(degree_135-np.sqrt(200))**2/250)
fit_2 = 1-np.exp(-(degree_45)**2/5)*np.exp(-(degree_135)**2/350)
return [fit_1,fit_2]4.8 plot.py
#encoding: utf-8
import numpy as np
import os
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import fitness_funs as fit
class Plot_pareto:
def __init__(self):
#绘制测试函数的曲面,(x1,x2)表示两位度的输入,(y1,y2)表示两位的适应值,
self.x1 = np.linspace(0,10,100)
self.x2 = np.linspace(0,10,100)
self.x1,self.x2 = np.meshgrid(self.x1,self.x2)
self.m,self.n = np.shape(self.x1)
self.y1,self.y2 = np.zeros((self.m,self.n)),np.zeros((self.m,self.n))
for i in range(self.m):
for j in range(self.n):
[self.y1[i,j],self.y2[i,j]] = fit.fitness_([self.x1[i,j],self.x2[i,j]])
if os.path.exists('./img_txt') == False:
os.makedirs('./img_txt')
print '创建文件夹img_txt:保存粒子群每一次迭代的图片'
def show(self,in_,fitness_,archive_in,archive_fitness,i):
#共3个子图,第1、2/子图绘制输入坐标与适应值关系,第3图展示pareto边界的形成过程
fig = plt.figure(13,figsize = (17,5))
ax1 = fig.add_subplot(131, projection='3d')
ax1.set_xlabel('input_x1')
ax1.set_ylabel('input_x2')
ax1.set_zlabel('fitness_y1')
ax1.plot_surface(self.x1,self.x2,self.y1,alpha = 0.6)
ax1.scatter(in_[:,0],in_[:,1],fitness_[:,0],s=20, c='blue', marker=".")
ax1.scatter(archive_in[:,0],archive_in[:,1],archive_fitness[:,0],s=50, c='red', marker=".")
ax2 = fig.add_subplot(132, projection='3d')
ax2.set_xlabel('input_x1')
ax2.set_ylabel('input_x2')
ax2.set_zlabel('fitness_y2')
ax2.plot_surface(self.x1,self.x2,self.y2,alpha = 0.6)
ax2.scatter(in_[:,0],in_[:,1],fitness_[:,1],s=20, c='blue', marker=".")
ax2.scatter(archive_in[:,0],archive_in[:,1],archive_fitness[:,1],s=50, c='red', marker=".")
ax3 = fig.add_subplot(133)
ax3.set_xlim((0,1))
ax3.set_ylim((0,1))
ax3.set_xlabel('fitness_y1')
ax3.set_ylabel('fitness_y2')
ax3.scatter(fitness_[:,0],fitness_[:,1],s=10, c='blue', marker=".")
ax3.scatter(archive_fitness[:,0],archive_fitness[:,1],s=30, c='red', marker=".",alpha = 1.0)
#plt.show()
plt.savefig('./img_txt/第'+str(i+1)+'次迭代.png')
print '第'+str(i+1)+'次迭代的图片保存于 img_txt 文件夹'
plt.close()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134058.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
