大家好,又见面了,我是你们的朋友全栈君。
昨天nagios报警warning,没来得及留下报警截图,nagios值设定的值是


当1分钟多于15个进程等待,5分钟多于10个,15分钟多于5个则为warning状态
当1分钟多于30个进程等待,5分钟多于25个,15分钟多于20个则为critical状态
—————————————————————————————————————————————————————————-
MySQL主服务器load average 骤增

虽然没来得及排查出来最后又下去了,但是在增长的时候没有最后落实这个错误,着实很难过,在网上看许多资料,大部分都是一样的解释,转载的,抄袭的,心中也是错乱,最终就是一个问题在困扰,这三个数值,是本身内核计算完CPU单核的值,还是未除以CPU核数之前的值,这个问题在许多论坛和博文里,有不同的说法,但是大部分还是倾向于是除完的,实在无解,半夜求解同学胖伟,骚伟已翻墙,跑到国外技术网站,给了我这么一段话。

我蹩脚的翻译过来(不对的地方请多指正)
在多处理器系统上
负载相对于可用的处理器内核的数量是相对的
“100%利用”标志负载为1,只是标志在一个单一的核心系统
2标志是在双核,4是标志在四核等
因此,有一个 14 load average值和 24个 内核的负载平均,你的服务器是远离超载的
(一天的心结·······释然)
—————————————————————————————————————————————————————————-
以下是从不同地方摄取精华并重新整理已方便自己以后查阅
load average
以下命令均可获取load average系统平均负载
]# top
]# uptime
]# w
]# cat /proc/loadavg
/proc文件系统是一个虚拟的文件系统,不占用磁盘空间,它反映了当前操作系统在内存中的运行情况,查看/proc下的文件可以了解到系统的运行状态。查看系统平均负载使用“cat /proc/loadavg”命令,输出结果如下

前三个数字是1、5、15分钟内的平均进程数。后面的 1/331 一个的分子是正在运行的进程数,分母是进程总数;另一个是最近运行的进程ID号。
top获取:

系统平均负载被定义为:在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进
程数。
如果一个进程满足以下条件则其就会位于运行队列中:
上图椭圆部分3个数值分别表示系统在过去1分钟、5分钟、15分钟内运行进程队列中的平均进程数量。
运行队列嘛,没有等待IO,没有WAIT,没有KILL的进程通通都进这个队列。
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用’wait’)
- 没有被停止(例如:等待终止)
我们可以这样认为,就是 正在运行的进程 + 准备好等待运行的进程 在特定时间内(1分钟,5分钟,10分钟)的平均进程数
但是具体平均时候分母的值是按秒还是什么单位运算的?我也搞不清楚,大概就是这样算出来的值,不影响对系统初步性能瓶颈判断,此处先略过
在Linux中,进程分为三种状态, 一种是阻塞的进程blocked process,
一种是可运行的进程runnable process,
另外就是正在运行的进程running process。当进程阻塞时,进程会等待I/O设备的数据或者系统调用。
进程可运行状态时,它处在一个运行队列run queue中,与其他可运行进程争夺CPU时间。 系统的load是指正在运行running one和准备好运行runnable one的进程的总数。比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的load就是5,load average就是一定时间内的load数量均值
—————————————————————————————————————————————————————————-
看到一篇文章小汽车的举例说的很不错,但是更深层次的我觉得有个打电话的写的更加详细,现以小汽车举例
为了更好地理解系统负载,我们用交通流量来做类比。
单核CPU可以想象成单车道
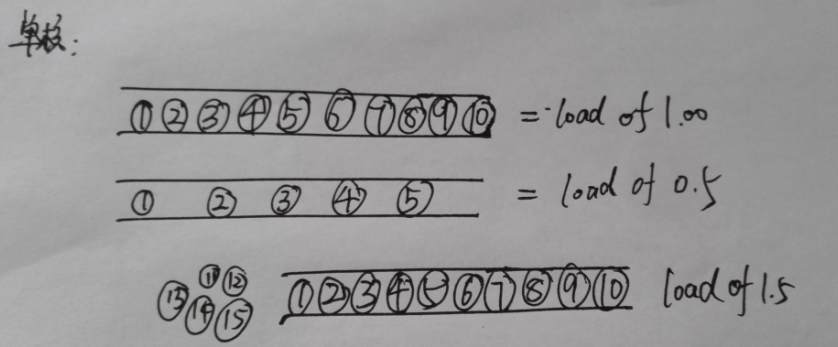
比如每个圆圈都是小汽车,第一种是满负荷但CPU时间片不用排队等待正好够用,第二种是%50空闲,第三个是超负荷50%,后面的就有队列等待了
1.单核CPU, 数字在0.00-1.00之间正常
0.00-1.00 之间的数字表示此时路况非常良好,没有拥堵,车辆可以毫无阻碍地通过。
1.00 表示道路还算正常,但有可能会恶化并造成拥堵。此时系统已经没有多余的资源了,管理员需要进行优化。
1.00以上 表示路况不太好了,如果到达2.00表示有桥上车辆一倍数目的车辆正在等待。这种情况你必须进行检查了。
2.多核CPU – 多车道 数字/CPU核数 在0.00-1.00之间正常

用双核举例,双核的负载已经比单核提高一倍了,那多核的也是同理。
多核CPU的话,满负荷状态的数字为 “1.00 * CPU核数”,即双核CPU为2.00,四核CPU为4.00。
3、安全的系统平均负载
这里没有完全的定论,一般来讲70%左右的负载也就是0.7左右应该是没问题的,要根据实际生产环境中实际需求来进行浮动设定
4、应该看哪一个数字,1分钟,5分钟还是15分钟?
和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都
希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会
有问题,这时候你应该会很焦急。
“所以你说的理想负荷为 1.00 ?”
嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有
经验的系统管理员都会将这条线划在 0.70:
“需要进行调查法则”: 如果长期你的系统负载在 0.70 上下,那么你需要在事情变得更糟糕之
前,花些时间了解其原因。
“现在就要修复法则”:1.00 。 如果你的服务器系统负载长期徘徊于 1.00,那么就应该马上解决
这个问题。否则,你将半夜接到你上司的电话,这可不是件令人愉快的事情。
“凌晨三点半锻炼身体法则”:5.00。 如果你的服务器负载超过了 5.00 这个数字,那么你将失去
你的睡眠,还得在会议中说明这情况发生的原因,总之千万不要让它发生。
先脱离下主题,我们来讨论下多核心处理器与多处理器的区别。从性能的角度上理解,一台主 机拥
有多核心的处理器与另台拥有同样数目的处理性能基本上可以认为是相差无几。当然实际 情况会复杂得
多,不同数量的缓存、处理器的频率等因素都可能造成性能的差异。
但即便这些因素造成的实际性能稍有不同,其实系统还是以处理器的核心数量计算负载均值 。这使
我们有了两个新的法则:
“有多少核心即为有多少负荷”法则: 在多核处理中,你的系统均值不应该高于处理器核心的总数
量。
“核心的核心”法则: 核心分布在分别几个单个物理处理中并不重要,其实两颗四核的处理器 等
于 四个双核处理器 等于 八个单处理器。所以,它应该有八个处理器内核。
5、怎样知道我的CPU是几核呢?
使用以下命令可以直接获得CPU核心数目
#cat /proc/cpuinfo |grep “physical id”|sort |uniq|wc –l
查看逻辑CPU的个数
#cat /proc/cpuinfo |grep “processor”|wc –l
查看CPU是几核
#cat /proc/cpuinfo |grep “cores”|uniq
查看CPU的主频
#cat /proc/cpuinfo |grep MHz|uniq
直接获得CPU核心数 (该命令即可全部算出多少核)
#grep ‘model name’ /proc/cpuinfo | wc -l
取得CPU核心数目N,观察后面2个数字,用数字/N,如果得到的值小于0.7即可无忧。
一般来讲我们观察五分钟或者十五分钟的平均数值。坦
白讲,如果前一分钟的负载情况是 1.00,那么仍可以说明认定服务器情况还是正常的。 但是如果十五
分钟的数值仍然保持在 1.00,那么就值得注意了要考虑是否这应该增加的处理器数量
了
整理到这里,想起了一个好文章,大概也讲的是CPU利用率和load Average的区别
链接为http://wenku.baidu.com/view/6597f58884254b35eefd34f7.html
写的很好,为我们更深层次的理解该指标有一定意义,我摘一些精华部分出来供以后自己学习



CPU利用率和Load Average的区别
CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力
测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。
我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。
—————————————————————————————————————————————————————————-
在理解了load Average各值得含义之后,我们用top命令来了解系统的整体状态
#top
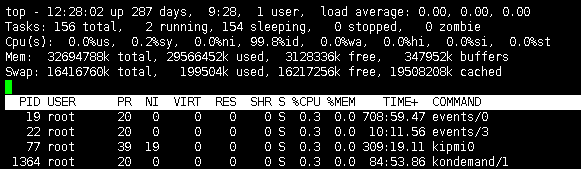
1. 12:28为当前系统运行时间
2. up 系统运行时间为287天9小时28分钟
3. user 当前登录用户数
4. load average 0.00 0.00 0.00 系统负载,任务队列不同时间段平均长度,分别为1分钟,5分钟,15分钟前到现在
5. Tasks 156 total, 当前进程总数
6. 2 running 正在运行的进程数
7 . 154 sleeping 睡眠的进程数
8. 0 stop 停止的进程数
9. 0zombie 僵尸进程数
10 Cpu(s): 0.0%us, 用户空间占用CPU百分比
11 0.2%sy, 内核空间占用CPU百分比
0.0%ni, 用户进程空间内改变过优先级的进程占用CPU百分比
99.8%id 空闲CPU
0.0%wa 等待输入输出的CPU时间百分比
0.0%hi 硬中断
0.0%si 软中断
0.0%st 实时
备注:(英文解释)
us: is meaning of "user CPU time"
sy: is meaning of "system CPU time"
ni: is meaning of" nice CPU time"
id: is meaning of "idle"
wa: is meaning of "iowait"
hi:is meaning of "hardware irq"
si : is meaning of "software irq"
st : is meaning of "steal time
12. Mem 32694788k total, (32G) 内存总容量
29566452k used, (28G)使用的物理内存总量
3128336k free, (3G) 空闲内存总量
347952k buffers, (340M) 用做内核缓存的内存量
13.Swap 16416760k total (16G) 交换分区总量
199504k used (195M) 使用的交换分区总量
1621725k free (1.5G) 空闲的交换分区总量
19508208 cached (19G) 缓冲的交换区总量
备注:Linux内存计算方法
多数的linux系统在free命令后会发现free(剩余)的内存很少,而自己又没有开过多的程序或服务。linux的内存管理机制与windows的有所不同。具体的机制我们无需知道,我们需要知道的是,linux的内存管理机制的思想包括(不敢说就是)内存利用率最大化。内核会把剩余的内存申请为cached,而cached不属于free范畴。当系统运行时间较久,会发现cached很大,对于有频繁文件读写操作的系统,这种现象会更加明显。
直观的看,此时free的内存会非常小,但并不代表可用的内存小,当一个程序需要申请较大的内存时,如果free的内存不够,内核会把部分cached的内存回收,回收的内存再分配给应用程序。所以对于linux系统,可用于分配的内存不只是free的内存,还包括cached的内存(其实还包括buffers)。即:
可用内存;=free的内存+cached的内存+buffers的内存
我们free一下

方框里的是真正可用内存,也是上面3个椭圆free+buffers+cached的和
Cache:高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
Buffer:缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
Free中的buffer和cache:(它们都是占用内存):
buffer : 作为buffer cache的内存,是块设备的读写缓冲区
cache: 作为page cache的内存, 文件系统的cache
如果 cache 的值很大,说明cache住的文件数很多。如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi会非常小。
 左图是服务器显示出来的有点乱,我开一台VMware虚拟机进行截图说明
左图是服务器显示出来的有点乱,我开一台VMware虚拟机进行截图说明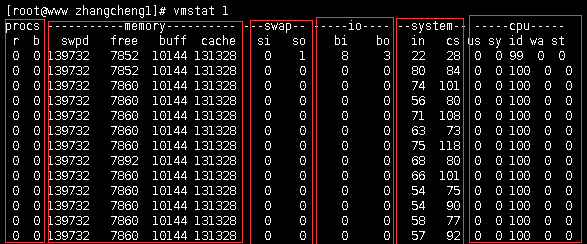
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu(难道load也是来这里采集的数据?)
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的
值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,
如果此时IO中bi比较小,说明文件系统效率比较好。
so由内存交换区进入内存数量。
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出
来分析。
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果
长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在
CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这
可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比
每隔2秒统计一次磁盘IO信息,直到按Ctrl+C终止程序,d选项表示统计磁盘信息, k表示以每秒KB的形式显
示,t要求打印出时间信息,2 表示每隔 2 秒输出一次。
第一次输出的磁盘IO负载状况提供了关于自从系统启动以
来的统计信息。随后的每一次输出则是每个间隔之间的平均IO负载状况。
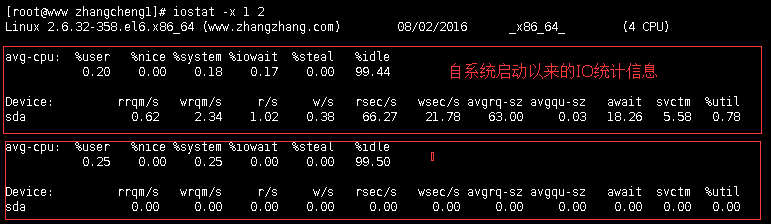
3.r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
4.w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
5.rsec/s: 每秒读扇区数。即 delta(rsect)/s
6.wsec/s: 每秒写扇区数。即 delta(wsect)/s
9.avgrq-sz:平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
11avgqu-sz:平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
12.await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
13.svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
14.%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即
delta(use)/s/1000 (因为use的单位为毫秒)
可能存在瓶颈。
%idle(空闲)小于70% IO压力就较大了,一般读取速度有较多的wait.
IO压力高)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160616.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
