大家好,又见面了,我是你们的朋友全栈君。
首先我们来说说需求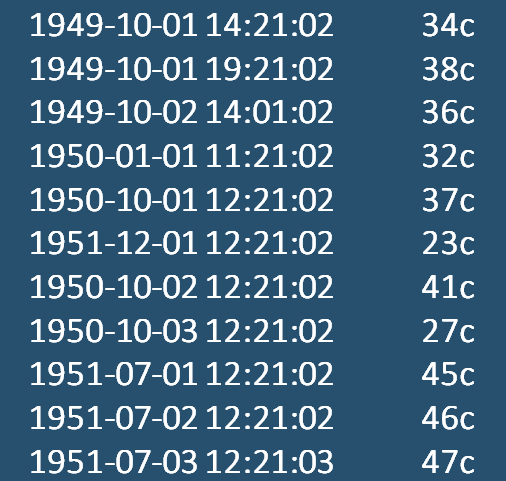

假设以上就是我们需要处理的数据,我们需要计算出每个月天气最热的两天。
这个案例用到的东西很多,如果你能静下心来好好看完,你一定会受益匪浅的
首先我们对自己提出几个问题
1.怎么划分数据,怎么定义一组???
2.考虑reduce的计算复杂度???
3.能不能多个reduce???
4.如何避免数据倾斜???
5.如何自定义数据类型???
—-记录特点
每年
每个月
温度最高
2天
1天多条记录怎么处理?
—-进一步思考
年月分组
温度升序
key中要包含时间和温度!
—-MR原语:相同的key分到一组
通过GroupCompartor设置分组规则
—-自定义数据类型Weather
包含时间
包含温度
自定义排序比较规则
—-自定义分组比较
年月相同被视为相同的key
那么reduce迭代时,相同年月的记录有可能是同一天的,reduce中需要判断是否同一天
注意OOM
—-数据量很大
全量数据可以切分成最少按一个月份的数据量进行判断
这种业务场景可以设置多个reduce
通过实现partition
一>>>MainClass的实现
package com.huawei.mr.weather;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午7:43:40
*/
public class MainClass {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 输入错误返回提示
if (args == null || args.length != 2) {
System.out.println("输入格式有误");
System.out.println("正确格式为:yarn jar weather.jar com.huawei.mr.weather.MainClass args[0] args[1]");
}
// 初始化hadoop默认配置文件,如果有指定的配置,则覆盖默认配置
Configuration conf = new Configuration(true);
// 创建Job对象,用到系统配置信息
Job job = Job.getInstance(conf);
// 指定job入口程序
job.setJarByClass(MainClass.class);
// 设置job名称
job.setJobName("weather");
// 指定文件从哪里读取,从hdfs加载一个输入文件给job
FileInputFormat.addInputPath(job, new Path(args[0]));
// 指定hdfs上一个不存在的路径作为job的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 自主设置reduce的数量
job.setNumReduceTasks(2);
// 指定map输出中key的类型
job.setMapOutputKeyClass(Weather.class);
// 指定map输出中value的类型
job.setMapOutputValueClass(Text.class);
// 设置map中的比较器,如果不设置默认采用key类型自带的比较器
/**
* 由于map里面的排序和这儿的排序不一样,称之为二次排序
*/
job.setSortComparatorClass(WetherComparator.class);
// 设置分区器类型 避免数据倾斜
job.setPartitionerClass(WeatherPartitioner.class);
job.setMapperClass(WeatherMapper.class);
job.setReducerClass(WeatherReduce.class);
job.waitForCompletion(true);
}
}
二 >>>Weather 自定义key的实现
package com.huawei.mr.weather;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午8:15:26
* map中输出key的自定义
*/
public class Weather implements WritableComparable<Weather> {
private String year;
private String month;
private String day;
private Integer weather;
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
public String getDay() {
return day;
}
public void setDay(String day) {
this.day = day;
}
public Integer getWeather() {
return weather;
}
public void setWeather(Integer weather) {
this.weather = weather;
}
@Override
public void write(DataOutput out) throws IOException {
// 把封装的数据序列化之后写出去
out.writeUTF(year);
out.writeUTF(month);
out.writeUTF(day);
out.writeInt(weather);
}
/*
* 读写的顺序要一致
*/
@Override
public void readFields(DataInput in) throws IOException {
// 把封装的数据序列化之后读进来
setYear(in.readUTF());
setMonth(in.readUTF());
setDay(in.readUTF());
setWeather(in.readInt());
}
@Override
public int compareTo(Weather that) {
int result = 0;
result = this.getYear().compareTo(that.getYear());
if (result == 0) {
result = this.getMonth().compareTo(that.getMonth());
if (result == 0) {
result = this.getDay().compareTo(that.getDay());
if (result == 0) {
// 如果年月日都相同,把温度按照高到低倒序排列
result = that.getWeather().compareTo(this.getWeather());
}
}
}
return result;
}
}
三 >>>自定义map中key的比较器用于排序
package com.huawei.mr.weather;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午8:29:41
* map中的比较器设置
*/
public class WetherComparator extends WritableComparator {
public WetherComparator() {
super(Weather.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
int result = 0;
Weather wa = (Weather) a;
Weather wb = (Weather) b;
// 分组比较器要保证同年同月为一组 和Weather里面的排序规则不一样
result = wa.getYear().compareTo(wb.getYear());
if (result == 0) {
result = wa.getMonth().compareTo(wb.getMonth());
if (result == 0) {
result = wb.getWeather().compareTo(wa.getWeather());
}
}
return result;
}
}
四>>>设置分区器避免数据倾斜
package com.huawei.mr.weather;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午8:47:46
* 分区器,避免数据倾斜
*/
public class WeatherPartitioner extends Partitioner<Weather, Text> {
@Override
public int getPartition(Weather key, Text value, int numPartitions) {
String month = key.getMonth();
int partitionNum = (month.hashCode() & Integer.MAX_VALUE) % numPartitions;
return partitionNum;
}
}
五>>>map里面对每一行的处理
package com.huawei.mr.weather;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午8:55:29 map里面的处理
*/
public class WeatherMapper extends Mapper<LongWritable, Text, Weather, Text> {
private SimpleDateFormat DATE_FORMAT = new SimpleDateFormat("yyyy-mm-dd");
private Weather wea = new Weather();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 每一行的数据格式为 1949-10-01 14:21:02 34c
String linStr = value.toString();
// {"1949-10-01 14:21:02","34c"}
String[] linStrs = linStr.split("\t");
// 得到温度
int weather = Integer.parseInt(linStrs[1].substring(0, linStrs[1].length() - 1));
// 获取时间
try {
Date date = DATE_FORMAT.parse(linStrs[0]);
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH);
int day = calendar.get(Calendar.DAY_OF_MONTH);
wea.setYear(year + "");
wea.setMonth(month + "");
wea.setDay(day + "");
wea.setWeather(weather);
// 把map中的值输出
context.write(wea, value);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
六>>>reduce里面的输出
package com.huawei.mr.weather;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author Lpf.
* @version 创建时间:2019年4月13日 下午8:55:35
* reduce 里面的处理
*/
public class WeatherReduce extends Reducer<Weather, Text, Text, NullWritable> {
@Override
protected void reduce(Weather key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Iterator<Text> iterator = values.iterator();
Text text = null;
String day = null;
while (iterator.hasNext()) {
text = iterator.next();
if (day != null) {
if (!day.equals(key.getDay())) {
// 输出本月温度最高的第二天
context.write(text, NullWritable.get());
break;
}
} else {
// 输出本月温度最高的第一天
context.write(text, NullWritable.get());
day = key.getDay();
}
}
}
}
年纪上来了 坐一下腰就酸的要死注释补充的不是很完整,有不明白的留言,乐意解答
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133993.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
