大家好,又见面了,我是你们的朋友全栈君。
Python+Tensorflow+Opencv的人脸识别
简单的人脸识别
一直想做机器学习的东东,最近由于工作的调整,终于有开始接触的机会了,哈哈。本文主要代码是来源于“就是这个七昂”的博文,传送门在此:https://blog.csdn.net/qq_42633819/article/details/81191308。”就是这个七昂”大大在他的博文中已经将人脸识别的过程讲的很清楚了。说来忏愧,在算法上我没有改变(我自己还没搞清楚,打算好好看看keras),因为在大大博文评论区看到好多人问怎么实现多个用户的人脸识别。刚开始我也在纳闷,怎么做呢?于是我就大胆尝试了一把,
准备工作
在做人脸识别前,你的有一个可以做的环境吧,在这里我当一次搬运工。开发环境的配置可以在网上找一堆,这里简单介绍一下我自己的。
-
安装Anaconda
官网下载地址 https://www.anaconda.com/download/
选择相应的Anaconda进行安装(可能会很慢)
网盘分享链接:https://pan.baidu.com/s/1gtvSnoo7f0-Iu8SvZtospw
密码:3pzr
我电脑是win10 64位系统,我选择安装的是Anaconda3-2019.03-Windows-x86_64.exe这个版本。下载好了安装包,就像安装普通软件一样,安装就行。

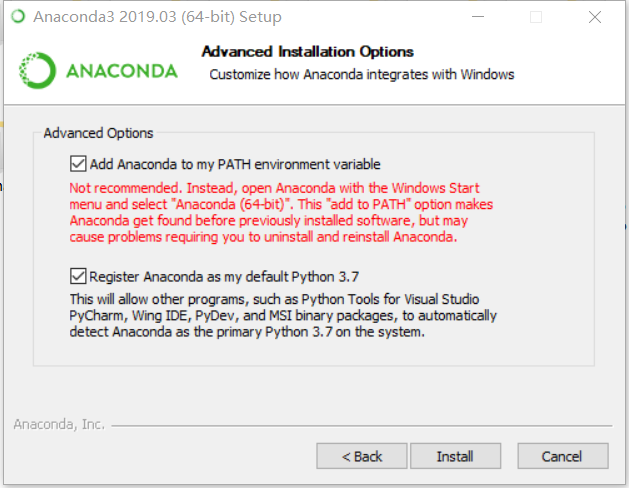
一路点下去,在Advanced Option界面时,如果你电脑里面没有其他版本Python就两个都选了。
那就等着吧,时间有点儿长,安装完了可以测试一下
打开cmd,输入conda --version -
安装Pycharm
首先去Pycharm官网,或者直接输入网址:http://www.jetbrains.com/pycharm/download/#section=windows,下载PyCharm安装包,根据自己电脑的操作系统进行选择,对于windows系统选择下图的框框所包含的安装包。这个也可以从网上找很多,而且安装很成功,个人学习的话,建议安装免费版本。 -
pycharm环境配置
打开Pycharm,随便先创建一个工程或者.py文件
 点击File→Setting,打开界面在这个选择你刚才安装的anconda,具体可以找找教程(我承认,我懒了)
点击File→Setting,打开界面在这个选择你刚才安装的anconda,具体可以找找教程(我承认,我懒了)
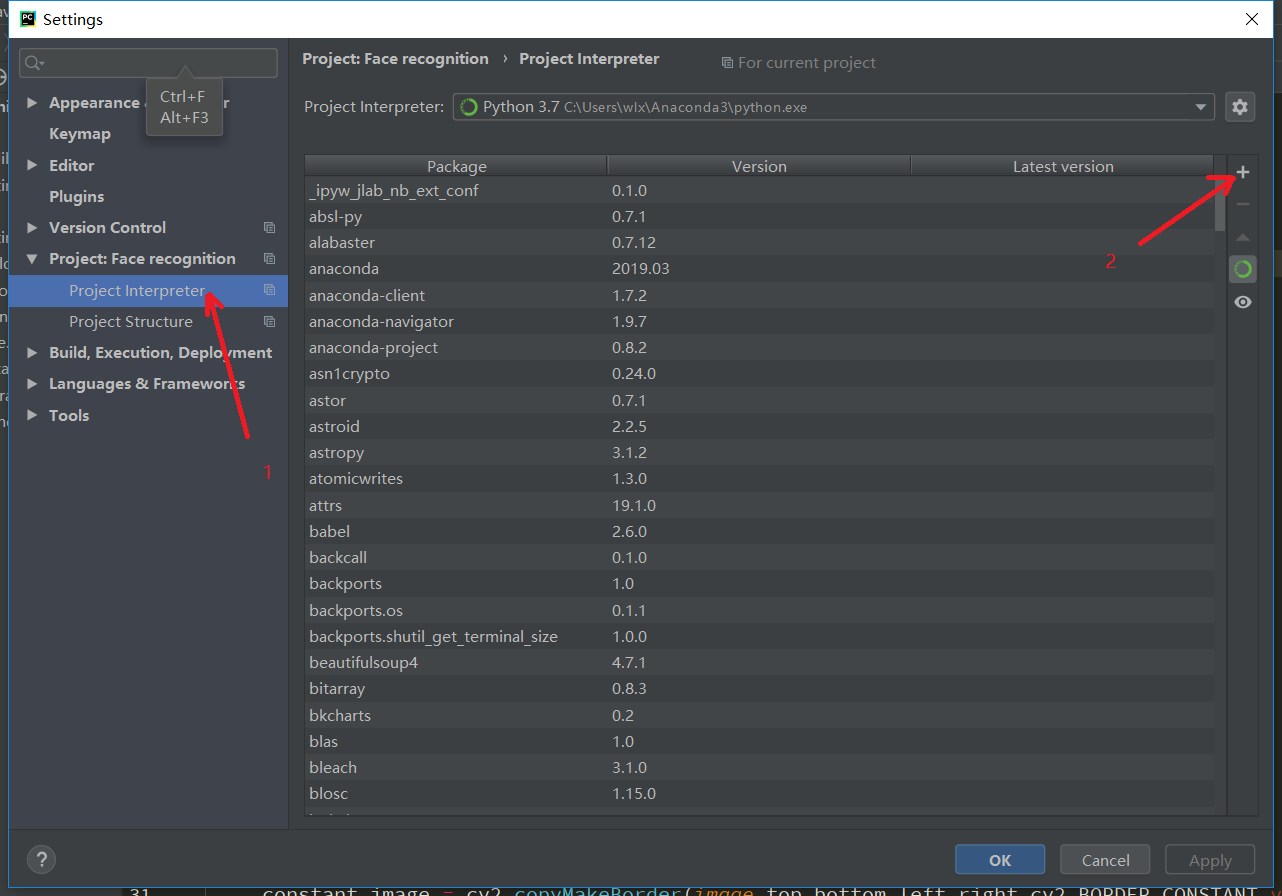 同时你可以在箭头2的位置添加我们这个项目的第三方库。
同时你可以在箭头2的位置添加我们这个项目的第三方库。
你需要到的库有:(我python3.7.1,以下是我安装的版本)
1.tensorflow 1.13.1
2.keras 2.2.4
3.scikit-learn 0.20.3
4.numpy(这个随便)
5.opecv-python 4.1.0.25
OK,差不多就这些。
开始——先获取必要的人脸图像
人脸识别其实就是分类和聚类的过程。
人脸图像获取的代码,我分为了三个脚本,代码如下:
首先是一个newuser_information_collection.py,这个脚本将调用其他脚本
###################################################
#相当于公司人力组织一次所有员工人脸信息采集
###################################################
from gain_face import CatchPICFromVideo
while True:
print("是否录入员工信息(Yes or No)?")
if input() == 'Yes':
#员工姓名(要输入英文,汉字容易报错)
new_user_name = input("请输入您的姓名:")
print("请看摄像头!")
#采集员工图像的数量自己设定,越多识别准确度越高,但训练速度贼慢
window_name = '信息采集' #图像窗口
camera_id = 0 #相机的ID号
images_num = 200 #采集图片数量
path = 'C:\\Users\\Administrator\\Documents\\Python Project\\Face recognition\\data\\' + new_user_name #图像保存位置
CatchPICFromVideo(window_name,camera_id,images_num,path)
else:
break
这个脚本可以让你不断写入图像数据,自定义每组数据大小,自动以你输入命名文件夹,这样就有了多个人脸的分类。
下面是gain_face.py的代码
################
#获取人的脸部信息,并保存到所属文件夹
################
import cv2
import sys
from createfolder import CreateFolder
from PIL import Image
def CatchPICFromVideo(window_name,camera_idx,catch_pic_num,path_name):
#检查输入路径是否存在——不存在就创建
CreateFolder(path_name)
cv2.namedWindow(window_name)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
# 告诉OpenCV使用人脸识别分类器
classfier = cv2.CascadeClassifier("C:\Program Files (x86)\Python\Python37\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml")
#识别出人脸后要画的边框的颜色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将当前桢图像转换成灰度图像
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=2, minSize=(32, 32))
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
if w > 200:
# 将当前帧保存为图片
img_name = '%s\%d.jpg' % (path_name, num)
#image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
image = grey[y:y+h,x:x+w] #保存灰度人脸图
cv2.imwrite(img_name, image)
num += 1
if num > (catch_pic_num): # 如果超过指定最大保存数量退出循环
break
#画出矩形框的时候稍微比识别的脸大一圈
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, 'num:%d' % (num), (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 超过指定最大保存数量结束程序
if num > (catch_pic_num): break
# 显示图像
cv2.imshow(window_name, frame)
#按键盘‘Q’中断采集
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
#判断本程序是独立运行还是被调用
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id face_num_max path_name\r\n" % (sys.argv[0]))
else:
CatchPICFromVideo("截取人脸", 0, 200, 'C:\\Users\\Administrator\\Documents\\Python Project\\Face recognition\\data\\huangsongmao')
在gain_face中调用了createfold脚本,用来检查写入的地址是否存在,不存在就建立。
下面是createfold.py的代码
import os
def CreateFolder(path):
#去除首位空格
del_path_space = path.strip()
#去除尾部'\'
del_path_tail = del_path_space.rstrip('\\')
#判读输入路径是否已存在
isexists = os.path.exists(del_path_tail)
if not isexists:
os.makedirs(del_path_tail)
return True
else:
return False
OK,人脸数据获取就完成了,只要运行newuser_information_colletion.py就可以了。
训练——分类吧
想训练我们保存好的人脸图像,就得先把它们读取出来,然后写到一个数组array中,对吧。
load_dataset.py
import sys
import numpy as np
import os
import cv2
################################################
#读取待训练的人脸图像,指定图像路径即可
################################################
IMAGE_SIZE = 64
#将输入的图像大小统一
def resize_image(image,height = IMAGE_SIZE,width = IMAGE_SIZE):
top,bottom,left,right = 0,0,0,0
#获取图像大小
h,w,_ = image.shape
#对于长宽不一的,取最大值
longest_edge = max(h,w)
#计算较短的边需要加多少像素
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
#定义填充颜色
BLACK = [0,0,0]
#给图像增加边界,使图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
constant_image = cv2.copyMakeBorder(image,top,bottom,left,right,cv2.BORDER_CONSTANT,value=BLACK)
return cv2.resize(constant_image,(height,width))
#读取数据
images = [] #数据集
labels = [] #标注集
def read_path(path_name):
for dir_item in os.listdir(path_name):
full_path = path_name + '\\' + dir_item
if os.path.isdir(full_path):
read_path(full_path)
else:
#判断是人脸照片
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image)
images.append(image)
labels.append(path_name)
return images,labels
#为每一类数据赋予唯一的标签值
def label_id(label,users,user_num):
for i in range(user_num):
if label.endswith(users[i]):
return i
#从指定位置读数据
def load_dataset(path_name):
users = os.listdir(path_name)
user_num = len(users)
images,labels = read_path(path_name)
images_np = np.array(images)
#每个图片夹都赋予一个固定唯一的标签
labels_np = np.array([label_id(label,users,user_num) for label in labels])
return images_np,labels_np
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s path_name\r\n" % (sys.argv[0]))
else:
images,labels = load_dataset('C:\\Users\\Administrator\\Documents\\Python Project\\Face recognition\\data')
#print(labels)
数据和对应的标注都以array形式对出来了,是不是该分类训练了啊。
face_train.py
########################
#人脸特征训练
########################
import random
import os
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
from load_dataset import load_dataset, resize_image
IMAGE_SIZE = 64
class Dataset:
def __init__(self, path_name):
# 训练集
self.train_images = None
self.train_labels = None
# 验证集
self.valid_images = None
self.valid_labels = None
# 测试集
self.test_images = None
self.test_labels = None
# 数据集加载路径
self.path_name = path_name
# 图像种类
self.user_num = len(os.listdir(path_name))
#当前库采用的维度顺序
self.input_shape = None
# 加载数据集并按照交叉验证的原则划分数据集并进行相关预处理工作
def load(self, img_rows=IMAGE_SIZE, img_cols=IMAGE_SIZE,
img_channels=3):
#数据种类
nb_classes = self.user_num
#加载数据集到内存
images, labels = load_dataset(self.path_name)
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size=0.3,
random_state=random.randint(0, 100))
# _, test_images, _, test_labels = train_test_split(images, labels, test_size=0.5,
# random_state=random.randint(0, 100))
# 当前的维度顺序如果为'th',则输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
# 这部分代码就是根据keras库要求的维度顺序重组训练数据集
if K.image_dim_ordering() == 'th':
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
#test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
#test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
# 输出训练集、验证集、测试集的数量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid samples')
#print(test_images.shape[0], 'test samples')
# 我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将
# 类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
#test_labels = np_utils.to_categorical(test_labels, nb_classes)
# 像素数据浮点化以便归一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
#test_images = test_images.astype('float32')
# 将其归一化,图像的各像素值归一化到0~1区间
train_images /= 255
valid_images /= 255
#test_images /= 255
self.train_images = train_images
self.valid_images = valid_images
#self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
#self.test_labels = test_labels
# CNN网络模型类
class Model:
def __init__(self):
self.model = None
# 建立模型
def build_model(self, dataset,nb_classes=4):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
#以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(Convolution2D(32, 3, 3)) # 3 2维卷积层
self.model.add(Activation('relu')) # 4 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(Convolution2D(64, 3, 3)) # 9 2维卷积层
self.model.add(Activation('relu')) # 10 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果
#输出模型概况
self.model.summary()
# 训练模型
def train(self, dataset, batch_size=20, nb_epoch=10, data_augmentation=True):
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) # 完成实际的模型配置工作
# 不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法创造新的
# 训练数据,有意识的提升训练数据规模,增加模型训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
shuffle=True)
# 使用实时数据提升
else:
# 定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
# 次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center=False, # 是否使输入数据去中心化(均值为0),
samplewise_center=False, # 是否使输入数据的每个样本均值为0
featurewise_std_normalization=False, # 是否数据标准化(输入数据除以数据集的标准差)
samplewise_std_normalization=False, # 是否将每个样本数据除以自身的标准差
zca_whitening=False, # 是否对输入数据施以ZCA白化
rotation_range=20, # 数据提升时图片随机转动的角度(范围为0~180)
width_shift_range=0.2, # 数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
height_shift_range=0.2, # 同上,只不过这里是垂直
horizontal_flip=True, # 是否进行随机水平翻转
vertical_flip=False) # 是否进行随机垂直翻转
# 计算整个训练样本集的数量以用于特征值归一化、ZCA白化等处理
datagen.fit(dataset.train_images)
# 利用生成器开始训练模型
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size=batch_size),
samples_per_epoch=dataset.train_images.shape[0],
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels))
MODEL_PATH = './aggregate.face.model.h5'
def save_model(self, file_path=MODEL_PATH):
self.model.save(file_path)
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose=1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
# 识别人脸
def face_predict(self, image):
# 依然是根据后端系统确定维度顺序
if K.image_dim_ordering() == 'th' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image) # 尺寸必须与训练集一致都应该是IMAGE_SIZE x IMAGE_SIZE
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE)) # 与模型训练不同,这次只是针对1张图片进行预测
elif K.image_dim_ordering() == 'tf' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
# 浮点并归一化
image = image.astype('float32')
image /= 255
#给出输入属于各个类别的概率
result_probability = self.model.predict_proba(image)
#print('result:', result_probability)
#给出类别预测(改)
if max(result_probability[0]) >= 0.9:
result = self.model.predict_classes(image)
print('result:', result)
# 返回类别预测结果
return result[0]
else:
return -1
if __name__ == '__main__':
user_num = len(os.listdir('./data/'))
dataset = Dataset('./data/')
dataset.load()
model = Model()
model.build_model(dataset,nb_classes=user_num)
# 先前添加的测试build_model()函数的代码
model.build_model(dataset,nb_classes=user_num)
# 测试训练函数的代码
model.train(dataset)
model.save_model(file_path='./model/aggregate.face.model.h5')
注意:上面的代码,我没有进行训练结果的测试,想要测试的小伙伴们,把我屏蔽的代码解开就好了。
另外解释一下
# 图像种类
self.user_num = len(os.listdir(path_name))
这是获取path_name下有多少个文件夹,因为我们统一在data文件夹下只放各个图像文件夹,所以在训练的时候,分多少种类别就由self.user_num说了算
#数据种类
nb_classes = self.user_num
对了,这里好像有些小伙伴会和我一样错点儿错误,那就是
model.save_model(file_path='./model/aggregate.face.model.h5')
model文件夹,你建立了吗?没建立的,请在工程文件写新建,不要建立在data文件夹下哦。
另外,我在人脸识别函数face_predict()中修改了返回值的返回方式
#给出类别预测(改)
if max(result_probability[0]) >= 0.9:
result = self.model.predict_classes(image)
print('result:', result)
# 返回类别预测结果
return result[0]
else:
return -1
这样子就能让返回结果比较让人可信了。
运行face_train.py脚本吧,等待…(反正我电脑很慢,这怎么能用到工程上呢?)我在这里就不上图了,以上所有代码都是我实际使用过的。
当在model文件夹下生成了.h5文件,OK训练完成!
下面应该就是激动人心的时刻了
识别大脸
上代码face_recognition.py
import cv2
import sys
import os
from face_train import Model
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\r\n" % (sys.argv[0]))
sys.exit(0)
#加载模型
model = Model()
model.load_model(file_path='./model/aggregate.face.model.h5')
# 框住人脸的矩形边框颜色
color = (0, 255, 0)
# 捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
# 人脸识别分类器本地存储路径
cascade_path = "C:\Program Files (x86)\Python\Python37\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml"
# 循环检测识别人脸
while True:
ret, frame = cap.read() # 读取一帧视频
if ret is True:
# 图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
# 使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=2, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
# 截取脸部图像提交给模型识别这是谁
image = frame[y: y + h, x: x + w] #(改)
faceID = model.face_predict(image)
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
#face_id判断(改)
for i in range(len(os.listdir('./data/'))):
if i == faceID:
# 文字提示是谁
cv2.putText(frame,os.listdir('./data/')[i],
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
cv2.imshow("login", frame)
# 等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
# 如果输入q则退出循环
if k & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
好了,运行该代码就能识别几位小伙伴的大脸了。代码中我修改了一点儿,主要是判断谁的脸的部分。
#face_id判断
for i in range(len(os.listdir('./data/'))):
if i == faceID:
# 文字提示是谁
cv2.putText(frame,os.listdir('./data/')[i],
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
因为我们在标注图像id的时候就是按照os.listdir(’./data/’)列表中显示的顺序,所以识别出的id和os.listdir(’./data/’)列表的索引号匹配,匹配到谁就在图像上标出谁os.listdir(’./data/’)[i]。
终于搬运完了,因为第一次接触机器学习,所以才疏学浅,希望大佬们多多指教。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133810.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
