大家好,又见面了,我是你们的朋友全栈君。
一、概述
在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑、在一段时间内禁止访问。
应对的方法有两种:
1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率。
2. 搭建一个IP代理池,使用不同的IP轮流进行爬取。
环境说明
操作系统:centos 7.6
ip地址:192.168.31.230
说明:运行redis和ip代理池
操作系统:windows 10
ip地址:192.168.31.230
说明:运行Scrapy 爬虫项目
二、搭建IP代理池
介绍
在github上,有一个现成的ip代理池项目,地址:https://github.com/jhao104/proxy_pool
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
搭建redis
注意:此项目运行时,依赖于redis。这里直接用docker搭建
docker run -d --name redis -p 6380:6379 redis --requirepass 123456
说明:
映射端口6080,redis密码为:123456
运行ip代理池
由于ip代理池项目,在dockerhub上面有现成的镜像,直接拿来使用即可。
启动命令示例:
docker run --env DB_CONN=redis://:password@ip:port/db -p 5010:5010 jhao104/proxy_pool:latest
注意:这里要根据实际情况,指定redis的连接信息。
所以:根据上面的环境说明,正确的redis连接信息为:DB_CONN=redis://:123456@192.168.31.230:6380/0
因此启动命令为:
docker run -d --env DB_CONN=redis://:123456@192.168.31.230:6380/0 -p 5010:5010 jhao104/proxy_pool:latest
注意:请根据实际情况,修改redis连接信息,-d表示后台运行。
使用
api
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
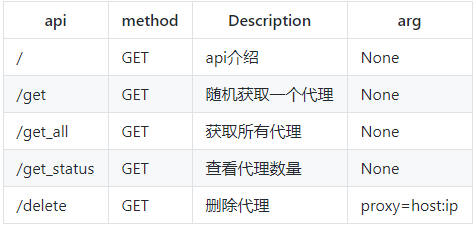

随机获取一个代理,访问页面
http://192.168.31.230:5010/get/
效果如下:

其中,proxy字段,就是我们需要的代理了
那么在爬虫项目中,获取到这个字段,就可以使用了。
三、项目演示
那么如何知道,我的爬虫项目,用了ip代理,去访问指定的网站呢?
一般来说,打开:https://www.ip138.com/ 就能看到我的公网ip了。但是通过代码爬取这个页面,得到我的公网ip比较麻烦。
有一个简单网页:http://httpbin.org/get 直接访问它,它会返回一段json数据,里面就包含了我的公网ip地址。

那么下面,我将创建一个Scrapy 项目,应用ip代理池,去访问 http://httpbin.org/get,并打印出公网ip地址。
创建项目
打开Pycharm,并打开Terminal,执行以下命令
scrapy startproject ip_proxy
cd ip_proxy
scrapy genspider httpbin httpbin.org
在scrapy.cfg同级目录,创建bin.py,用于启动Scrapy项目,内容如下:
#在项目根目录下新建:bin.py
from scrapy.cmdline import execute
# 第三个参数是:爬虫程序名
execute(['scrapy', 'crawl', 'blog',"--nolog"])
在items.py同级目录,创建proxy_handle.py,内容如下:
import json
import requests
def get_proxy():
response = requests.get("http://192.168.31.230:5010/get/").text
result = json.loads(response)
# print(result, type(result))
return result['proxy']
def delete_proxy(proxy):
requests.get("http://192.168.31.230:5010/delete/?proxy={}".format(proxy))
创建好的项目树形目录如下:
./
├── bin.py
├── ip_proxy
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── proxy_handle.py
│ ├── settings.py
│ └── spiders
│ ├── httpbin.py
│ └── __init__.py
└── scrapy.cfg
修改httpbin.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapy import Request # 导入模块
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
# start_urls = ['http://httpbin.org/']
# 自定义配置,注意:变量名必须是custom_settings
custom_settings = {
'REQUEST_HEADERS': {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
}
}
def start_requests(self):
r1 = Request(url="http://httpbin.org/get",
headers=self.settings.get('REQUEST_HEADERS'), )
yield r1
def parse(self, response):
# print(response.text,type(response.text))
result = json.loads(response.text)
# print(result,type(result))
origin = result['origin']
print("公网ip: ",origin)
修改middlewares.py
这里,我主要修改下载中间件的内容
class IpProxyDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
proxy = "http://" + get_proxy()
request.meta['download_timeout'] = 10
request.meta["proxy"] = proxy
print('为 %s 添加代理 %s ' % (request.url, proxy))
# print('元数据为', request.meta.get("proxy"))
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('返回状态码', response.status)
return response
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
print('代理%s,访问%s出现异常:%s' % (request.meta['proxy'], request.url, exception))
import time
time.sleep(5)
delete_proxy(request.meta['proxy'].split("//")[-1])
request.meta['proxy'] = 'http://' + get_proxy()
return request
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
说明:在请求之前,从ip代理池中获取一个随机ip。当ip代理访问异常时,从ip代理池中,删除这个代理ip。
修改settings.py,应用下载中间件
DOWNLOADER_MIDDLEWARES = {
'ip_proxy.middlewares.IpProxyDownloaderMiddleware': 543,
}
执行bin.py,启动爬虫项目,效果如下:
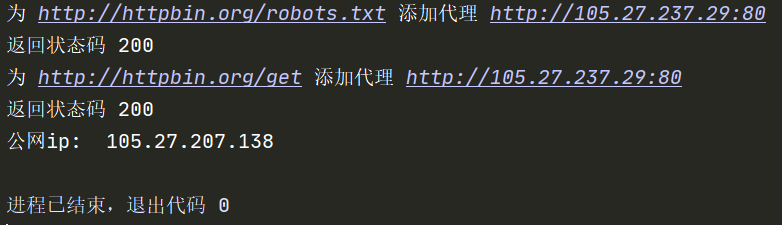
注意:每次访问一个链接时,ip地址是不一样的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133351.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
