大家好,又见面了,我是你们的朋友全栈君。
ES数据库安装
elastica search
elasticsearch的概念:
是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
1、elasticsearch和MongoDB/redis/memcache一样,是非关系性数据库
是一个接近实时的搜索平台,从所索引这个文档到能够被搜索到只有一个轻微的延迟,企业应用定位:采用restfullapi标准的可扩展和高可用的实时数据分析的全文搜索工具
2、可扩展:支持一主多从且扩容容易,只要cluster.nam一致且在同一个网络中就能自动加入当前集群;本身就是开源软件,也支持很多开源的第三方插件
3、高可用:在一个集群的多个节点中进行分布式存储,索引支持shards和复制,即使部分节点down掉,也能自动进行数据恢复和主从切换
4、采用restfullapi标准:通过http接口和json格式进行操作数据
5、数据存储的最小单位是文档,本质上是一个json文本
node节点 :单个的装有elasticsearch服务并且提供故障转移和扩展的服务器
cluster集群:一个集群就是由一个或者多个node组织在一起,共同工作,共同分享整个数据具有负载均衡功能的集群
index索引: 索引就是一个拥有几分相似特征的文档的集合
type类型:索引可以为拥有相同字段的文档定义一个类型;一个索引中可以创建多个type
document文档:一个文档是一个可被索引的基础信息单元
field 列:field是elasticsearch的最小单位,相当于数据的某一个列
shards分片:elastic search将索引分成若干份,每个部分就是一个shard
replicas复制:replicas 是索引里每个shard的拷贝(一份或者多份)
elasticsearch 应用场景
1、搜索:电商、百科、App搜索
2、高亮显示:GitHub
3、分析和数据挖掘:ELK
elasticsearch特点:
1、高性能,天然分布式
2、对运维友好,不需要会java开发语言,开箱即用
3、功能丰富
elasticsearch安装部署6.6版本
rpm -qc elasticsearch 查看配置文件有哪些
[root@localhost soft]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml 主配置文件
/etc/elasticsearch/jvm.options jvm虚拟机配置
/etc/elasticsearch/log4j2.properties
/etc/elasticsearch/role_mapping.yml
/etc/elasticsearch/roles.yml
/etc/elasticsearch/users
/etc/elasticsearch/users_roles
/etc/init.d/elasticsearch init启动脚本
/etc/sysconfig/elasticsearch
/usr/lib/sysctl.d/elasticsearch.conf 配置参数,不需要改动
/usr/lib/systemd/system/elasticsearch.service systemctl 启动文件
1、关闭防火墙
iptables -nL
iptables -F
iptables -X
iptables -Z
iptables -nL
2、下载软件
链接:https://pan.baidu.com/s/1PMpkPwAK03F_KYrZM-5hAw
提取码:lrai
mkdir /data/soft
[root@db-01 /data/soft]# ll -h
total 268M
-rw-r--r-- 1 root root 109M Feb 25 2019 elasticsearch-6.6.0.rpm
-rw-r--r-- 1 root root 159M Sep 2 16:35 jdk-8u102-linux-x64.rpm
3、安装jdk
rpm -ivh jdk-8u102-linux-x64.rpm
[root@db-01 /data/soft]# java -version
openjdk version "1.8.0_212"
OpenJDK Runtime Environment (build 1.8.0_212-b04)
OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
4、安装
rpm -ivh elasticsearch-6.6.0.rpm
5、启动并检查
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
netstat -lntup|grep 9200
[root@db01 /data/soft]# curl 127.0.0.1:9200
{
"name" : "pRG0qLR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "mNuJSe07QM61IOxecnanZg",
"version" : {
"number" : "6.6.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "a9861f4",
"build_date" : "2019-01-24T11:27:09.439740Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
端口说明:
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯
ES集群之间是通过9300进行通讯
ES自定义配置
1、查看ES有哪些配置
[root@db01 ~]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml #ES的主配置文件
/etc/elasticsearch/jvm.options #jvm虚拟机配置
/etc/sysconfig/elasticsearch #默认一些系统配置参数
/usr/lib/sysctl.d/elasticsearch.conf #配置参数,不需要改动
/usr/lib/systemd/system/elasticsearch.service #system启动文件
2、自定义配置文件
cp /etc/elasticsearch/elasticsearch.yml /opt/
cat >/etc/elasticsearch/elasticsearch.yml<<EOF node.name: node-1 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 10.0.0.51,127.0.0.1 http.port: 9200 EOF
3、重启服务
systemctl restart elasticsearch.service
4、解决内存锁定失败
重启后查看日志发现提示内存锁定失败
[root@db01 ~]# tail -f /var/log/elasticsearch/elasticsearch.log
[2019-11-14T09:42:29,513][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
解决方案:
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
systemctl daemon-reload
systemctl restart elasticsearch.service
安装es-head插件安装
链接:https://pan.baidu.com/s/1PMpkPwAK03F_KYrZM-5hAw
提取码:lrai
注意:需要修改配置文件添加允许跨域参数
http.cors.enabled: true
http.cors.allow-origin: "*"
1.es-head 三种方式
1.npm安装方式
2.docker安装
3.google浏览器插件(推荐)
从google商店安装es-head插件
将安装好的插件导出到本地
修改插件文件名为zip后缀
解压目录
拓展程序-开发者模式-打开已解压的目录
连接地址修改为ES的IP地址
2.具体操作命令
Head插件在5.0以后安装方式发生了改变,需要nodejs环境支持,或者直接使用别人封装好的docker镜像
插件官方地址
https://github.com/mobz/elasticsearch-head
使用docker部署elasticsearch-head
docker pull alivv/elasticsearch-head
docker run --name es-head -p 9100:9100 -dit elivv/elasticsearch-head
使用nodejs编译安装elasticsearch-head
cd /opt/
wget https://nodejs.org/dist/v12.13.0/node-v12.13.0-linux-x64.tar.xz
tar xf node-v12.13.0-linux-x64.tar.xz
mv node-v12.13.0-linux-x64 node
echo 'export PATH=$PATH:/opt/node/bin' >> /etc/profile
source /etc/profile
npm -v
node -v
git clone git://github.com/mobz/elasticsearch-head.git
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm install
npm run start &
kibana与ES交互
链接:https://pan.baidu.com/s/1PMpkPwAK03F_KYrZM-5hAw
提取码:lrai
1、安装kibana
rpm -ivh kibana-6.6.0-x86_64.rpm
2、配置kubana
[root@localhost soft]# grep -nEv '#|^$' /etc/kibana/kibana.yml
2:server.port: 5601
7:server.host: "10.0.0.51"
28:elasticsearch.hosts: ["http://10.0.0.51:9200"]
37:kibana.index: ".kibana"
3、启动kibana
systemctl start kibana
端口:5601
4、测试命令
curl -XGET 'http://10.0.0.51:9200/_count?pretty' -H 'Content-Type: application/json' -d ' { "query": { "match_all": {} } } '
mysql es
库 index 索引
表 type
字段 json key
行 doc文档
使用HTTP的协议
GET 查看
PUT 提交
POST 提交
DELETE 删除
方法 索引/类型/doc
PUT twitter/_doc/1
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}


所有以下划线开头都是系统默认的
{
"_index": "oldzhang",
"_type": "info",
"_id": "1",
"_version": 1,
"_score": 1,
"_source": {
"name": "zhang",
"age": "29"
}
}
故障案例
一开始使用ES库关联mysql 一开始使用的指定id 后来发现数据库的查询变的慢,根据调研,采用post随机id
elasticsearch 和数据库怎么进行关联
根据id进行关联,但是会进行id比较 不能出现id冲突
根据post 的随机id 不会进行id比较 关联mysql时增加一个字段 解决关联问题
查询命令
1、创建测试语句
POST oldzhang/info/
{
"name": "zhang",
"age": "29",
"pet": "xiaoqi",
"job": "it"
}
POST oldzhang/info/
{
"name": "xiao1",
"age": "30",
"pet": "xiaoqi",
"job": "it"
}
POST oldzhang/info/
{
"name": "xiao2",
"age": "26",
"pet": "xiaoqi",
"job": "it"
}
POST oldzhang/info/
{
"name": "xiao4",
"age": "35",
"pet": "xiaoqi",
"job": "it"
}
POST oldzhang/info/
{
"name": "ya",
"age": "28",
"pet": "xiaomin",
"job": "it"
}
POST oldzhang/info/
{
"name": "xiaomin",
"age": "26",
"pet": "xiaowang",
"job": "SM"
}
POST oldzhang/info/
{
"name": "hemengfei",
"age": "38",
"pet": "xiaohe",
"job": "3P"
}
POST oldzhang/info/
{
"name": "xiaoyu",
"age": "28",
"pet": "bijiben",
"job": "fly"
}
2、简单查询
GET oldzhang/_search/
3、条件查询
GET oldzhang/_search
{
"query": {
"term": {
"name": {
"value": "xiaomin"
}
}
}
}
GET oldzhang/_search
{
"query": {
"term": {
"job": {
"value": "it"
}
}
}
}
4、多条件查询
GET /oldzhang/_search
{
"query" : {
"bool": {
"must": [
{
"match": {
"pet": "xiaoqi"}},
{
"match": {
"name": "zhang"}}
],
"filter": {
"range": {
"age": {
"gte": 27,
"lte": 30
}
}
}
}
}
}
}
增删改查
1、自定义的ID更新
PUT oldzhang/info/1
{
"name": "zhang",
"age": 30,
"job": "it",
"id": 1
}
2.随机ID更新
#先根据自定义的Id字段查出数据的随机ID
GET oldzhang/_search/
{
"query": {
"term": {
"id": {
"value": "2"
}
}
}
}
#取到随机ID后更改数据
PUT oldzhang/info/CVDdknIBq3aq7mPQaoWw
{
"name": "yayay",
"age": 30,
"job": "it",
"id": 2
}
MongoDB ES etcd 都是使用jso格式
而Redis是使用
日志的两种格式:
多行匹配格式
json格式
集群相关名词
1、默认分片和副本规则
5分片
1副本
2、集群健康状态
绿色: 所有数据都完整,且副本数满足
黄色: 所有数据都完整,但是副本数不满足
红色: 一个或多个索引数据不完整
3、节点类型
主节点: 负责调度数据分配到哪个节点
数据节点: 实际负责处理数据的节点
默认: 主节点也是工作节点
4、数据分片
主分片: 实际存储的数据,负责读写,粗框的是主分片
副本分片: 主分片的副本,提供读,同步主分片,细框的是副本分片
5、副本
主分片的备份,副本数量可以自定义
部署ES集群
1、安装java
rpm -ivh jdk-8u102-linux-x64.rpm
2、安装ES
rpm -ivh elasticsearch-6.6.0.rpm
3、配置内存锁定
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity
4、集群配置文件
node-1
[root@localhost soft]# grep -nEv '#|^$' /etc/elasticsearch/elasticsearch.yml
1:cluster.name: elk
2:node.name: node-1
3:path.data: /var/lib/elasticsearch
4:path.logs: /var/log/elasticsearch
5:bootstrap.memory_lock: true
6:network.host: 10.0.0.51,127.0.0.1
7:http.port: 9200
8:discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.52"]
9:discovery.zen.minimum_master_nodes: 1
node-2
grep -nEv '#|^$' /etc/elasticsearch/elasticsearch.yml
17:cluster.name: elk
23:node.name: node-2
33:path.data: /var/lib/elasticsearch
37:path.logs: /var/log/elasticsearch
43:bootstrap.memory_lock: true
55:network.host: 10.0.0.52,127.0.0.1
59:http.port: 9200
68:discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.52"]
72:discovery.zen.minimum_master_nodes: 1
discovery.zen.minimum_master_nodes: 1
这个参数的作用:如果集群想正常工作,至少需要几台机器正常
集群的节点个数的一半以上,也就是大多数
这两台机器能互相通讯
建议:
不要偶数个节点
解释修改参数:尽量使得集群节点数为奇数个
total number of master-eligible nodes / 2 + 1
所有可能会成为master节点的个数 / 2 + 1
5、启动
systemctl daemon-reload
systemctl restart elasticsearch
6、查看日志
tail -f /var/log/elasticsearch/elasticsearch.log
7、查看集群
ES-head查看是否有2个节点
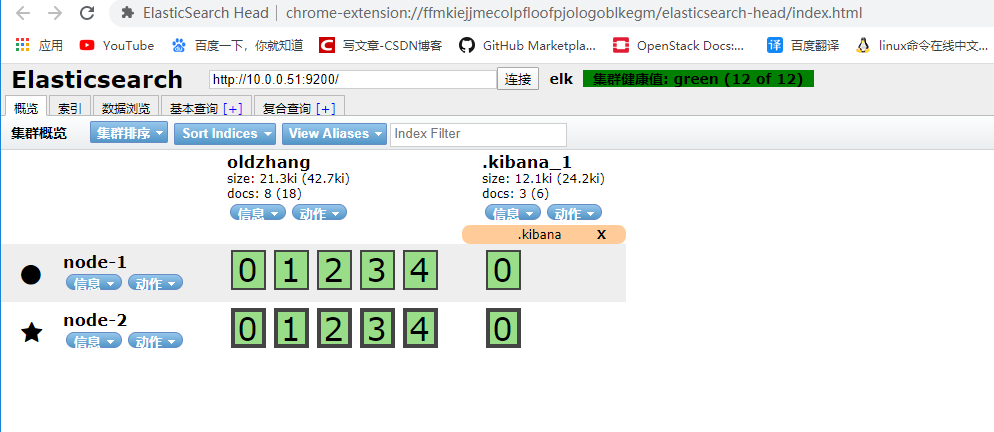

集群注意事项
1.插入和读取数据在任意节点都可以执行,效果一样
2.es-head可以连接集群内任一台服务
3.主节点负责读写
如果主分片所在的节点坏掉了,副本分片会升为主分片
4.主节点负责调度
如果主节点坏掉了,数据节点会自动升为主节点
5.通讯端口
默认会有2个通讯端口:9200和9300
9300并没有在配置文件里配置过
如果开启了防火墙并且没有放开9300端口,那么集群通讯就会失败
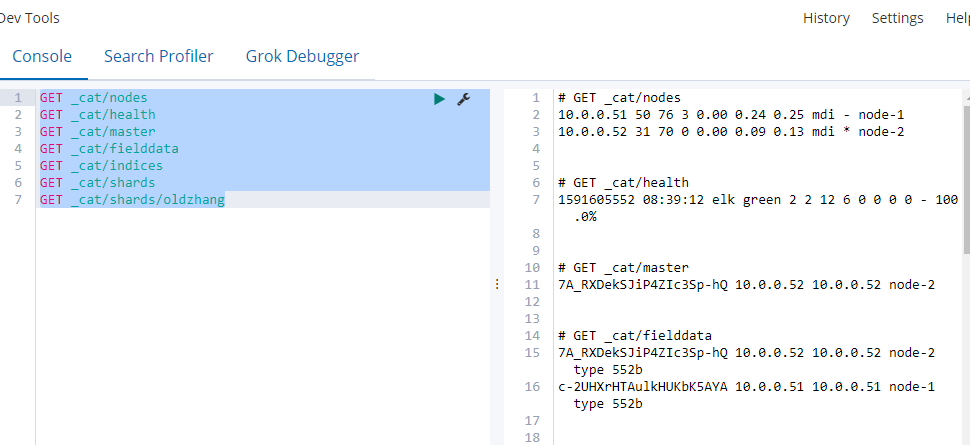
查看集群各种信息
GET _cat/nodes
GET _cat/health
GET _cat/master
GET _cat/fielddata
GET _cat/indices
GET _cat/shards
GET _cat/shards/oldzhang
扩容第三台机器
1、安装java
rpm -ivh jdk-8u102-linux-x64.rpm
2、安装ES
rpm -ivh elasticsearch-6.6.0.rpm
3、配置内存锁定
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity
4、db03集群配置文件
cat > /etc/elasticsearch/elasticsearch.yml <<EOF cluster.name: elk node.name: node-3 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 10.0.0.53,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.53"] discovery.zen.minimum_master_nodes: 1 EOF
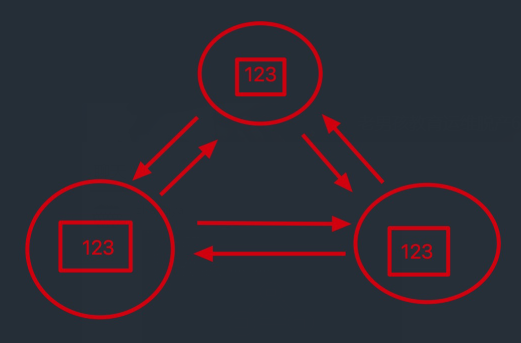
解释:
discovery.zen.ping.unicast.hosts: ["10.0.0.51", "10.0.0.53"]
能和集群内任意一个节点ping通即可 通过51可以和集群内所有的机器进行获取(感觉和病毒感染一样)
5、添加接点注意
1.对于新添加的节点来说:
只需要直到集群内任意一个节点的IP和他自己本身的IP即可
对于以前的节点来说:
什么都不需要更改
2.最大master节点数设置
3个节点,设置为2
3.默认创建索引为1副本5分片
4.数据分配的时候会出现2中颜色
紫色: 正在迁移
黄色: 正在复制
绿色: 正常
5.3节点的时候
0副本一台都不能坏
1副本的极限情况下可以坏2台: 1台1台的坏,不能同时坏2台,在数据复制完成的情况下,可以坏2台
2副本的情况可以同时坏2台
当数据库node2(假设为主库)down掉一个后 这时node1为主库,如果此时有数据写入,等到node2修复好之后,自动同步数据。
磁盘不能写的太满,会导致复制数据出现问题,保证足够的空间使用
动态修改最小发现节点数
GET _cluster/settings
PUT _cluster/settings
{
"transient": {
"discovery.zen.minimum_master_nodes": 2
}
}
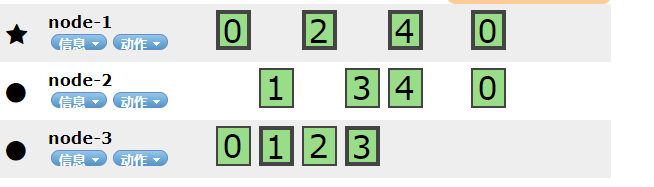
出现这种情况是因为:主分片为5,副本为1 所以三个节点的情况下 一个为主分片 一个为副本,另外一个就是没有主分片和副本
3个节点的ES集群,极限情况下,最多允许坏几台?
如果选举参数配置为1的情况下,极限坏2台,不能同时坏,坏一台,等数据同步后,才能坏第二台
红色: 一个或多个索引数据不完整
如果集群编程红色了,只是说明索引数据不完整,
1、副本数和分片数都是可以调整的
2、分片数只有在创建索引的时候才能定义 索引一旦创建完成 分片数不能修改
复习:
ES集群故障转移和恢复注意事项
elasticsearch 是一款成熟的数据库,不只是elk的数据库
黄(副本数不满足)—-绿(正常)—-紫(迁移)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133264.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...