大家好,又见面了,我是你们的朋友全栈君。
阅读笔记:基于知识图谱的知识推理
论文:A review: Knowledge reasoning over knowledge graph
基本概念、定义
- 人工智能算法必须具有推理能力,推理过程必须依赖于知识工程时代的先验知识和经验,大量知识图(KGs),如YAGO,WordNet,Freebase已经开发。KGs包含大量的先验知识,同时也能有效地组织数据。
- 知识图能够从大规模数据中挖掘、组织和有效地管理知识,以提高信息服务质量,为用户提供更智能的服务。所有这些方面都依赖于知识推理对知识图的支持,知识图是推理领域的核心技术之一。知识图的知识推理是为了识别错误,从现有数据中推断出新的结论。通过知识推理,可以导出实体间的新关系,并反馈丰富知识图,支持先进应用。
- 知识推理是利用已知知识推断出新知识的过程。
- 随着互联网数据规模的爆炸式增长,传统的基于人工构建知识库(KBs)的方法已不能适应大数据时代挖掘大量知识的需要。为此,数据驱动的机器推理方法逐渐成为知识推理研究的主流。
知识库的丰富内容为知识推理技术的发展提供了新的机遇和挑战。随着知识表示学习、神经网络等技术的普及,一系列新的推理方法应运而生。
前沿的知识图谱:
- WordNet
WordNet是一个于1985年创建英语词汇数据库。句法集是通过概念语义和词汇关系相互联系的,如狗和哺乳动物之间的IS-A关系或汽车与发动机的部分整体关系。WordNet在信息系统中有着广泛的应用:词义消歧、信息检索、文本分类、文本摘要、机器翻译甚至纵横字谜生成。最新版本WordNet3.0包含15万字,20万个语义关系。 - Freebase
Freebase是一个由社区成员组成的大型协作知识库,由Metaweb构建。包含从Wikipedia、NNDB、时尚模特目录和MusicBrainz等来源获取的数据,以及用户提供的数据。谷歌的知识图部分是由Freebase提供的。目前约有30亿个三元组。 - ** YAGO**
YAGO中的信息是从Wikipedia、WordNet和GeoNames中提取的。YAGO将WordNet的干净分类法与丰富的Wikipedia分类系统相结合,将实体超过35万个类。YAGO将时间维度和空间维度附加到其许多事实和实体上。它从10个不同语言的维基百科中提取并合并实体和事实。目前,YAGO拥有超过1.5亿个实体和关系。YAGO已被用于沃森人工智能系统。 - DBpedia
DBpedia是一个跨语言项目,旨在从Wikipedia项目创建的信息中提取结构化内容。DBpedia与外部数据集(包括Freebase、OpenCyc等)之间有超过4500万个链接。DBpedia使用资源描述框架(RDF)来表示提取的信息。DBpedia的实体在
一致的本体论,包括人、地方、音乐专辑、电影、电子游戏、组织、物种和疾病。DBpedia被用作ibmwatson的Jeopardy中的一个知识源! - wikidata
wikidata是一个多语言、开放、链接、结构化的知识库,可以被人和机器阅读和编辑。它支持超过280种语言版本的Wikipedia,并提供共同的结构化数据源。Wikidata继承了Wikipedia的众包协作机制,并支持基于triples的编辑。它依赖于项目和报表的概念。项表示实体。语句由一个编码的主属性值对组成。 - NELL
Never Ending Language Learning system是一个语义机器学习系统,它可以全天候运行,永远学习阅读网页。NEL的输入包括:
(1)一个初始的本体,它定义了NELL所属的数百个类别和关系希望阅读
(2)10至15种子的例子,每一个类别和关系。有了这些输入,内尔会自动从网络中提取三重事实。
基于知识图谱的知识推理:
目标是利用机器学习的方法来推断实体对之间的潜在关系,并根据现有数据自动识别错误知识,以补充KGs。例如,如果KG包含一个事实,如(Microsoft,IsBasedIn,Seattle),(Seattle,StateLocatedIn,Washington)和(Washington,CountryLocatedIn,USA),那么我们将获得缺少的链接(Microsoft,HeadquarterLocatedIn,USA)。
知识推理的对象不仅是实体之间的属性和关系,还包括实体的属性值和本体的概念层次。例如,如果一个实体的身份证号码属性已知,则可以通过推理获得该实体的性别、年龄和其他属性。
KG基本上是一个语义网络和一个结构化的语义知识库,可以正式解释现实世界中的概念及其关系。基于知识图的推理不仅局限于传统的基于逻辑和规则的推理方法,而且具有多样性。同时,知识图由实例组成,使推理方法更加具体。
近年来,研究人员实现了许多开放式信息抽取(OIE)系统,如textranner,WOE,极大地扩展了知识的数据源。
因此,知识库的丰富内容为知识推理技术的发展提供了新的机遇和挑战。随着知识表示学习、神经网络等技术的普及,一系列新的推理方法应运而生。
推理方法分为三类:
- 基于规则的推理
- 基于分布式表示的推理
- 基于神经网络的推理。
知识图推理的相关应用
- 知识图的完成
- 问题回答
- 推荐系统
基于规则的推理
基于一阶谓词逻辑规则的知识推理
早期的知识推理方法(包括本体推理)受到了广泛的关注,并产生了一系列的推理方法。此外,这些方法包括谓词逻辑推理、本体推理和随机游走推理,可用于知识图的推理。
例如,人际关系推理可以采用一阶谓词逻辑,将关系作为谓词,字符作为变量,用逻辑运算符来表达人际关系,然后设置关系推理的逻辑和约束条件来进行简单的推理。使用一阶谓词逻辑进行推理的过程是下式
(姚明,华斯博宁,上海)∧(上海,中国)⇒(姚明,国籍,中国)
一阶归纳学习(FOIL)(Schoenmackers,Etzioni,Weld,&Davis,2010)是谓词逻辑的一个典型工作,其目的是搜索KG中的所有关系,并获得每个关系的Horn子句集一种预测对应关系是否存在的特征模式。最后,利用机器学习方法得到关系判别模型。
FOIL的相关研究有很多。例如:
- nFOIL和tFOIL(Landwehr、Kersting和Raedt,2007)分别将朴素贝叶斯学习方案和树增强天真贝叶斯与箔片相结合。nFOIL通过朴素贝叶斯的概率得分来指导结构搜索。tFOIL放松了天真的Bayes假设,允许子句之间存在额外的概率依赖关系。
- kFOIL公司(Landwehr,Passerini,De Raedt& Frasconi,2010)将FOIL的规则学习算法和核方法结合起来,从关系表示中导出一组特征。因此,FOIL搜索可以作为内核方法中的特征的相关子句。
- Nakashole,Sozio,Suchanek,and Theobald(2012)提出了一种结合软推理规则和硬规则的不确定RDF知识库的查询时间一阶推理方法。软规则用于派生新事实,而硬规则用于强制实现一致性。
KG和推断事实之间的约束。Galárraga,Teflioudi,Hose,and Suchanek(2013)提出了在知识图上挖掘Horn规则的AMIE系统。将这些规则应用到知识库系统中,可以得到新的事实,用于知识图的补充和错误的检测。
传统的FOIL算法在小规模知识库上具有较高的推理精度。此外,实验结果表明,实体-关系关联模型具有较强的推理能力。然而,由于大规模知识图中实体和关系的复杂性和多样性,很难穷尽所有的推理模式。另外,穷举算法的高复杂度和低效率使得原FOIL算法不适合于大规模图的推理。
为了解决这个问题,Galárraga,Teflioudi,Hose,和 Suchanek(2015)通过一系列修剪和查询重写技术将AMIE扩展到AMIE+,以挖掘更大的知识库。此外,AMIE+通过考虑类型信息和使用联合推理提高了预测精度。demeter、Rocktäschel和Riedel(2016b)提出了一种可伸缩的方法,将一阶蕴涵引入关系表示中,以改进大规模KG推理。
同时,Wang和Li(2015)提出了一种新的规则学习方法RDF2Rules。RDF2Rules挖掘频繁谓词循环(FPC)来并行化此过程。由于适当的修剪策略,处理大规模KBs比AMIE+更有效。为了有效地形式化语义网和推理,一些研究者提出了一种可处理的语言,称为描述逻辑(DL)。描述逻辑是在命题逻辑和一阶谓词逻辑的基础上发展起来的本体推理的重要基础。描述逻辑的目标是平衡表示能力和推理复杂度。它能够为知识图提供定义良好的语义和强大的推理工具,满足本体构建、集成和演化的需要。因此,它是一种理想的本体语言。使用DL表示的知识库由术语公理(TBox)和断言公理(ABox)组成(Lee,Lewicki,Girolami,&Sejnowski,1999)。TBox由一组声明概念和角色的一般属性的包含断言组成。例如,断言是指说明一个概念表示另一个概念的专门化。ABox包含对单个对象的断言。知识库的一致性是知识图推理的基本问题。通过TBox和ABox将知识图中的复杂实体或关系推理转化为一致性检测问题,从而细化和实现知识推理。
Halaschek-Wiener,Parsia,Sirin,and Kalyanpur(2006)提出了一种描述逻辑推理算法用于在ABoxes断言的添加和删除下对知识图进行补充。它提供了对波动/流数据进行推理的关键步骤。Calvanese,De Giacomo,Lembo,Lenzerini,and Rosati(2006)提出了一种基于认知的一阶查询语言EQL,该语言能够解释查询描述逻辑的不完整性知识图表。为了扩展具有模糊能力的经典描述逻辑,提出了大量的模糊描述逻辑。Li,Xu,Lu,and Kang(2006)提出了一种新的离散tableau算法来解决FSHI知识库与一般TBoxes的可满足性问题,为模糊DLs中实现一般TBoxes推理提供了一种新的途径。此外,Stoilos、Stamou、Pan、Tzouvaras和Horrocks(2007)利用模糊集理论对DL进行了扩展,以表示知识和执行推理任务。为了装备描述逻辑来处理元知识,Krötzsch、Marx、Ozaki和Thost(2018)用有限的属性值对集合(称为属性描述逻辑)来丰富DL概念和角色,用于知识图推理。现有的DL推理机不为用户提供解释服务。为了解决这一问题,Bienvenu、Bourgaux和Goasdoué(2019)提出了一个框架,使推理系统在不一致容忍语义下具有解释能力。
基于规则的知识推理
基于规则的知识推理模型的基本思想是利用简单的规则或统计特征进行推理。
NELLs语言学习系统(NELLs)的推理组件(Mitchell等人,2015)学习概率规则,然后在人工筛选后实例化规则,最后从其他学习到的关系实例中推断出一个新的关系实例。
SpassYAGO通过将三元组抽象为等效规则类。Paulheim和Bizer(2014)提出SDType和SDValidate,利用属性和类型的统计分布来完成类型和错误检测。SDType使用属性的头实体和尾部实体位置中类型的统计分布来预测实体的类型。SDValidate计算每个语句的相对谓词频率(RPF),RPF值低表示不正确。
Jang和Megawati(2015)提出了一种评估质量的新方法知识图。他们在分析数据模式后,选择出现频率较高的模式作为生成的测试模式来评估知识图的质量。
Wang,Mazaitis,and Cohen(2013)和Wang,Mazaitis,Lao,and Cohen(2015)提出了使用个性化PageRank(ProPPR)进行知识图推理的编程。ProPPR的推理是基于一个个性化的PageRank过程,而不是由SLD解析定理证明器构造的证明。
Catherine和Cohen(2016)指出,ProPPR可用于执行知识图建议。他们把问题描述成一个概率推理和学习任务。Cohen(2016)提出张量对数,其中推理使用可微过程。受TensorLog的启发,Yang,Yang,and Cohen(2017)描述了一个框架,即神经逻辑程序设计,其中将逻辑规则的结构和参数学习结合在一个端到端可微模型中。
基于规则的推理方法还可以将人工定义的逻辑规则与各种概率图模型相结合,在构建的逻辑网络基础上进行知识推理,从而获得新的事实。
例如,Jiang、Lowd和Dou(2012)提出了一种基于马尔可夫逻辑的NELL清洗系统。这使得知识库能够利用联合概率推理,或者将马尔可夫逻辑网络(MLN)(Richardson&Domingos,2006)应用于web规模的问题。它只使用初始系统的本体论约束和置信度,以及标记的数据。
Chen和Wang(2014)提出了一种概率知识库(ProbKB),它允许一种高效的基于SQL的推理算法来完成知识,并批量应用MLN推理规则。Kuželka and Davis(2019)从理论上研究了马尔可夫逻辑权值学习的适用性在缺少数据的情况下从一个KB的网络。在学习权值后,MLN可以用来推断额外的事实来完成知识图。然而,由于逻辑规则中的子句值必须是布尔变量,所以在MLN中引入子句置信度比较困难。此外,布尔变量赋值的各种组合使得学习和推理难以优化。
为了解决这个问题,概率软逻辑(PSL)(Kimmig、Bach、Broecheler、Huang和Getoor,2012年)。PSL使用FOIL规则作为模板语言,在区间[0,1]范围内具有软真值的随机变量图形模型。在这种情况下,推理被认为是一个连续的优化任务,可以有效地处理。
为此,Pujara、Miao、Getoor和Cohen(2013a)使用PSL来共同推理候选事实及其相关的提取可信度,识别共同参照实体,并结合本体论约束。此外,他们还提出了一种分区技术(Pujara,Miao,Getoor,&Cohen,2013b)在考虑推理速度和精度的前提下,对大规模知识图进行推理。该方法首先生成以实体和关系为节点,本体约束为边的知识图。然后利用聚类技术中的边缘最小割对关系和标签进行划分。最后,利用PSL在知识图上定义一个联合概率分布来完成集合推理。Bach、Broecheler、Huang和Getoor(2017)提出了铰链损失马尔可夫随机场(HL-MRF),它可以利用布尔逻辑捕捉松弛的概率推理和模糊逻辑的精确概率推理,使它们成为离散和连续数据的有用模型。他们还引入了PSL,使HL MRF易于定义和用于大型KG。
基于本体的知识推理
知识图上的知识推理与本体密切相关,它与资源描述框架模式(RDFS)、Web本体语言(OWL)等本体语言有着密切的联系。知识图可以看作是知识存储的一种数据结构。尽管它没有形式语义,但它可以通过应用RDFS或OWL来推理规则为一公斤。Pujara等人。(2013b)证明了OWL-EL表示的本体适合于转换为KG并对其进行有效的推理。基于本体的推理方法主要是利用更抽象的频繁模式、约束或路径进行推理。当通过本体概念层进行推理时,OWL能够提供丰富的语句和知识表示能力。
Zou,Finin,and Chen(2004)提出了一个推理引擎F-OWL,它使用基于框架的系统对OWL本体进行推理。F-OWL支持知识库的一致性检查,通过解析提取隐藏的知识,并通过导入规则支持进一步的复杂推理。Sirin、Parsia、Grau、Kalyanpur和Katz(2007)提出了OWL-DL reasoner弹丸来支持基于动态知识图的增量式推理,通过重用前一步的推理结果,对过程进行增量更新。hen,Goldberg,Wang,and Johri(2016)提出了本体论寻路(OP)算法,该算法通过一系列优化和并行化技术将其推广到web规模的知识库:轮流使用推理规则的关系知识库模型,将挖掘任务划分为更小的单子任务的新规则挖掘算法,以及一个修剪策略在使用这些规则之前,会产生噪音和资源消耗。
Wei,Luo,and Xie(2016a)提出并实现了一个基于owl2rl推理规则的分布式知识图推理系统(KGRL)。由于更具表达性的规则,KGRL具有更强大的推理能力。它可以消除冗余数据并进行推理,通过优化,结果更加紧凑。此外,它还可以发现知识图中不一致的数据。
基于大规模本体论的可扩展推理方法是基于大规模知识的高效推理方法。周等。(2006)提出了一个用于大规模OWL本体的存储和推理系统Minerva。Minerva结合了DL推理机和规则引擎进行本体推理,以提高效率。为了提高推理的可扩展性和性能,Soma和Prasanna(2008)提出了两种OWL知识库推理过程的并行化方法。在数据划分方法,对知识图进行划分,并将完整的规则库应用于知识库的每个子集。在规则库划分方法中,对规则库进行分区,并行系统的每个节点将一个子集规则应用于原始KG。Chen,Chen,Zhang,Chen,and Wu(2013b)提出了一个大规模复杂生物医学知识图的OWL推理框架,该框架利用MapReduce算法和OWL属性链推理方法。最近,Marx、Krötzsch和Thost(2017)提出了一个更简单、基于规则的多属性谓词逻辑片段,可用于大型知识图上的本体论推理
基于随机游走算法的知识推理
大量的研究表明,将路径规则引入知识推理可以提高推理性能。受此启发,许多研究者将路径规则注入知识推理任务中。
路径排序算法(PRA)(Lao&Cohen,2010)是一种在图中执行推理的通用技术。为了学习知识库中某个特定边缘类型的推理模型,PRA会找到经常链接节点的边缘类型序列,这些节点是被预测的边缘类型的实例。然后PRA将这些类型作为logistic回归模型中的特征来预测图中的缺失边。典型的PRA模型由三个部分组成:特征提取、特征计算和特定关系分类。
- 第一步是找到一组潜在的有价值的路径类型来链接实体对。为此,PRA在图上执行路径约束随机游走,以记录从h开始到t的有限长度。
- 第二步是通过计算随机游走概率来计算特征矩阵中的值。给定一个节点对(h,t)和一个路径π,PRA将特征值计算为随机行走概率p(t | h,π),即当给定从h开始的随机值时到达t的可能性,以及π中包含的关系。计算如下
- 最后一步是利用logistic回归算法对每个关系进行训练,得到路径特征的权重。
PRA模型不仅精度高,而且大大提高了计算效率,为解决大规模知识图的推理问题提供了一种有效的解决方案。Lao,Mitchell,and ohen(2011)已经证明了一种基于约束和,加权的随机游走可以用来可靠地预测知识库的新信念。它们描述了一种数据驱动的寻路方法,而原始的PRA算法通过枚举生成路径。为了使PRA适用于大规模KGs上的推理,他们修改了PRA中的路径生成过程,使其只生成对任务可能有用的路径。具体地说,它们要求PRA模型中包含一条路径,前提是它至少检索到训练集中的一个目标实体,并且长度小于l,因为少量可能的关系路径有利于推理。最后,两个实体之间所有路径的加权概率和分数是两个实体之间存在关系的可能性的度量。
此外,Lao、Subramanya、Pereira和Cohen(2012)也证明了这一点.路径约束随机游走模型可以有效地预测新的信念,利用大规模文本分析语料库和背景知识相结合的优势。实验结果表明,该模型结合了文本中的句法模式和背景知识中的语义模式,能够高精度地推断出新的信念。
尽管PRA方法具有很好的可解释性,但随机游走推理的一个主要问题是特征稀疏性。为了解决这个问题,Gardner、Talukdar、Krishnamurthy和Mitchell(2014)将向量相似性引入KGs上的随机行走推理中,以减少使用表面文本的固有特征稀疏性。也就是说,当在随机游动中跟随一系列的边类型时,它们允许游动跟随与给定边类型在语义上和谐的边,这是由边缘类型的向量空间嵌入定义的。这种方法结合了分布相似性和符号逻辑推理的概念,降低了PRA构造的特征空间的稀疏性。一方面,对整个知识图进行推理比较耗时,而且推理通常与局部信息有关,因此可以在KG上进行局部推理。另一方面,全局信息的规模较粗,与细粒度的局部信息相结合,可以提高推理的准确性。基于以上两个原因,Gardner和Mitchell(2015)定义了一种更简单、更有效的算法,称为子图特征提取(SFE)。SFE只是PRA的第一步。当给定一些节点对时,它们首先执行局部搜索来刻画实体节点周围的图。然后,他们在这些局部子图上运行一组特征抽取器,以获得每个实体对的特征向量。它不仅在时间复杂度上,而且在推理性能上都大大优于PRA。
Liu,Han,Jiang,Liu,and Geng(2017b)研究了现有随机行走模型所采用的基本假设的两个潜在问题。首先,该算法通过随机抽样的方式提取关系路径特征,提高了计算效率,同时牺牲了KG中已有信息的利用率。第二,采用监督学习方法建立关系推理模型,模型的有效性取决于训练数据,尤其是受数据稀疏性影响的数据。在此基础上,提出了双向语义假设和关系图推理假设,设计并实现了两层随机行走算法(TRWA)。模型如图1所示。
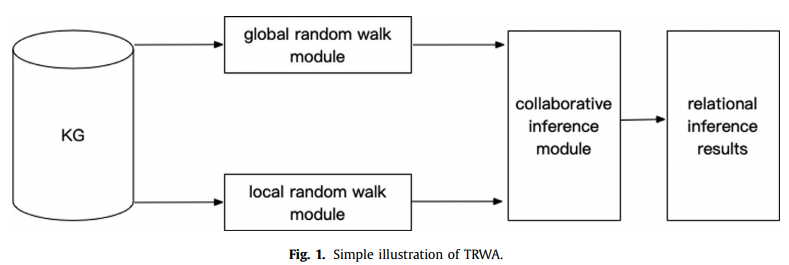

将局部特征建模和局部特征提取两种方法相结合进行局部特征提取。最后,对全局模块和局部模块进行加权合并,得到完整的逻辑规则推理算法。
没有引导的纯随机游动在寻找有用公式时效率很低,甚至可能由于引入噪声而误导推理。虽然有人提出了一些启发式规则来引导随机游动,但由于公式的多样性,这些规则的性能仍然不理想。为了解决这个问题,Wei,Zhao,and Liu(2016b)提出了一种新的面向目标的推理算法,在每一步都以特定的推理目标为方向在随机行走的过程中。具体地说,为了实现这种目标引导机制,该算法在随机行走的每一步动态估计每个邻居的电位。因此,该算法更倾向于遍历有助于推断目标和防止转移到噪声结构的结构。以往关于PRA的研究往往忽略了某些关系之间有意义的联系,无法为不太频繁的关系获得足够的训练数据。Wang,Liu,Luo,Wang,and Lin(2016)提出了一种新的多任务学习框架,称为耦合PRA(CPRA)。CPRA使用多任务机制执行推理。它由关系聚类和关系耦合两个模块组成。前者用于自动发现高度相关的关系,后者用于耦合这些关系的学习。通过进一步耦合这些关系,CPRA在推理性能方面明显优于PRA。
总的来说,基于逻辑的知识推理的发展趋势规则是逐步抛弃人工规则,利用模式识别技术,利用机器学习的方法,对训练模型进行规则或特征的自动挖掘。该模型将知识图表示为一个复杂的异构网络,可以通过转移概率、最短路径和广度优先搜索算法来完成推理任务。
然而,这种表示方法还存在缺陷。首先,基于逻辑规则的推理方法计算复杂度仍然较高,可扩展性较差。其次,知识图中的节点往往服从长尾分布,即只有少数实体和关系的出现频率较高,而大多数实体和关系出现的频率较低。因此,稀疏性严重影响推理性能。另外,如何处理多跳推理问题仍然是逻辑模型面临的一个更大的挑战。因此,Lin等人。(2015a)和Das,Neelakantan,Belanger,and McCallum(2017)将路径长度限制为最多3步,以反映不同对象之间的逻辑联系。因此,学者们主要关注的是基于数据稀疏性的扩展性推理方法
基于表示学习的推理
由于缺乏并行语料库,以往的挖掘和发现未知知识的工作都依赖于逻辑规则和随机遍历图。近年来,基于嵌入的方法在自然语言处理中得到了广泛的关注。如图2所示,这些模型将语义网络中的实体、关系和属性投影到连续向量空间中,以获得分布式表示。研究人员提出了大量基于分布表示的推理方法,包括张量分解、距离模型和语义匹配模型。
基于张量分解的知识推理
在推理过程中,通常将KG表示为张量,然后通过张量分解来推断未知事实。张量分解是将高维阵列分解成多个低维矩阵的过程。采用三向张量X,其中两个节点由域的连接实体构成,第三种模式保持关系。张量项Xi jk=1表示事实(第i个实体,第k个谓词,第j个实体)存在。如果不是,对于未知的和看不见的关系,则条目设置为零。然后,根据因子分解得到的向量计算三元组分数,选择得分较高的候选项作为推理结果。
RESCAL模型(nickle,Tresp,&Kriegel,2011)是张量因子分解模型的代表性方法。图3示出了该方法。RESCAL将高维、多关系数据分解为三阶张量,降低了数据维数,保留了原始数据的特征。它可以用于知识图的推理,取得了较好的效果。Nickel、Tresp和Kriegel(2012)证明了RESCAL因子分解形式的张量分解是语义网二元关系数据的一种合适的推理方法,并证明了因子分解能够成功地推理出YAGO上看不见的三元组。
Chang,Yih,Yang,and Meek(2014)提出了一种新的知识推理模型TRESCAL,该模型具有高效性和可扩展性。他们用两个创新点来推广张量分解模型。首先,他们从损失中删除不满足关系约束的三元组。其次,他们引入了一种数学技术,显著降低了时间计算复杂度和空间计算复杂度。
Nickel和Tresp(2013)还扩展了基于logistic回归的RESCAL张量因子分解。RESCAL-Logit使用不同的优化策略来提高推理精度。在Wu,Zhu,Liao,Zhang,and Lin(2017)中,提出了基于张量因子分解路径的预测。它使用PRA来寻找连接源节点和目标节点的所有路径。然后,利用张量分解对这些路径进行分解,进行推理。
Jainet al. (2017)为知识库推理开发了矩阵分解(MF)和张量分解(TF)的新组合。结果表明,该算法能够获得较好的混合推理性能。
基于距离模型的知识推理
TransE 、 TransH 、 TransR 、 TransD
TranSparse(Ji,Liu,He,&Zhao,2016)是一种解决这些问题的方法,它由TranSparse(share)模型和TranSparse(separate)模型组成。为了克服这种异构性,在TranSparse(share)中,转移矩阵的稀疏度由关系连接的实体对的个数决定,关系的两边共享相同的转移矩阵。为了解决关系不平衡的问题,在TranSparse(separate)中,每个关系都有两个独立的稀疏传输矩阵,一个用于head,另一个用于tail。
Xiao,Huang,Hao,and Zhu(2015)认为当前基于翻译的方法存在着过于简单化的损失度量,并且对每个维度的处理是一致的。为了解决这个问题,他们提出了TransA,一种自适应的度量方法嵌入,它利用自适应马氏度量和椭圆等势面提供了一种更灵活的推理方法。
TransE利用不灵活的欧几里德距离作为度量,在处理复杂关系时有局限性。为了同时解决这些缺陷,Fang,Zhao,Tan,Yang,and Xiao(2018)将TransA扩展到TransAH,这是一种改进的基于翻译的知识图推理方法。它通过增加一个对角权值矩阵来代替加权欧几里德距离,并引入了面向关系的超平面。最后,在大规模知识图上的实验验证了TransAH适合于推理。
值得注意的是,Xiao,Huang,and Zhu(2016)提出了一种生成贝叶斯非参数无限混合体,称为TransG,以解决多关系语义问题。他们没有为一个关系只分配一个翻译向量,而是利用高斯分布来处理多个关系语义,为一个关系生成多个翻译组件。因此,TransG避免了r的语义成分混淆,不同的语义具有不同的特征
TransG中的组件,提高了推理性能。TransG的得分函数定义为:

实体和关系可能包含以前模型中经常忽略的不确定性。然而,在知识推理中引入不确定性信息是非常重要的,因为不确定性可以提高推理的精度。因此,He,Liu,Ji,and Zhao(2015a)提出用KG2E来模拟多维高斯分布空间中实体和关系的确定性。在KG2E中,每个实体或关系都用高斯表示分布,其中平均值代表其位置,协方差表示其确定性。实验结果表明,KG2E能有效地模拟知识推理过程中实体和关系的不确定性。
Chen,Chen,Shi,Sun,and Zaniolo(2019)提出了一种新的不确定KG推理模型UGKE,该模型保留了不确定性信息。他们还引入了概率软逻辑来推断训练期间体重三倍的人的信心分数。现有的模型只学习时间未知事实的三倍,而忽略了知识图中的时间信息。然而,知识库中的事实总是随着时间的推移而动态变化。最近,一系列的研究将时间信息纳入推理过程。
t-TransE(Jiang et al.,2016b)通过与TransE共同学习关系排序来学习时间感知嵌入。他们试图将时间顺序强加给时间敏感的关系,如wasBornIn→workAt→diedIn。为了更好地模拟知识进化,TAE-TransE(Jiang et al.,2016a)假设时间顺序关系相互关联并动态演化。
Know Evolve(Trivedi,Dai,Wang,&Song,2017)使用双线性嵌入学习方法对知识成分的非线性时间演化进行建模。他们使用一个深层的循环体系结构来捕捉实体的动态特征。
Chekol、Pirrò、Schoenfisch和Stuckenschmidt(2017)提出了一种基于MLN的不确定时间知识图推理方法。Leblay和Chekol(2018)尝试使用图的非时间部分的边信息来学习时间嵌入。HyTE(Dasgupta,Ray,&Talukdar,2018)直接编码时间信息来学习时间感知嵌入。
基于语义匹配模型的知识推理
SE使用两个独立的矩阵为每个关系r投射头和尾实体,这不能有效地表示实体和关系之间的语义联系。
语义匹配能量(SME)(Bordes,Glorot,Weston,&Bengio,2012;2014)首先用向量表示实体和关系,然后将实体和关系之间的关联建模为语义匹配能量函数。SME定义了语义匹配能量函数的线性形式和双线性形式。潜在因子模型(Jenatton、Roux、Bordes和Obozinski,2012)采用双线性结构捕捉数据的各种相互作用顺序。
DistMult(Yang,Yih,He,Gao,&Deng,2015)通过将Mr限制为对角矩阵来简化RESCAL,这减少了参数的数量,并且在验证现有知识库上的不可见事实方面显示出良好的推理能力和可扩展性。Nickel,Rosasco,and Poggio(2016b)提出全息嵌入(HolE)来学习知识图的组合向量空间表示。HolE应用循环相关来生成合成表示。通过使用相关性作为合成算子,空穴可以捕捉到丰富的相互作用,但同时保持了推理的效率和易于训练的特点。现有的基于表示的关系推理模型存在的主要问题是,它们往往忽视实体和关系的语义多样性,从而限制了推理能力。
Liu,Han,Yang,Liu,and Wu(2017c)提出了知识图中关系推理的新假设,它认为每一个关系都反映了对应实体的某些特定注意方面的语义联系,可以通过有选择地对嵌入成分进行加权来建模,以缓解语义解析问题。据此,提出了一种语义方面感知的关系推理算法,有效地提高了知识图上关系推理的准确性。
Liu,Wu,Yang(2017a)从类比推理的角度研究知识推理的解决方案。他们制定类似的结构,并在评分函数中利用它们来优化实体和关系的潜在表示。为了处理各种并矢关系,包括对称关系和反对称关系,Trouillon等人。(2017年);Trouillon、Welbl、Riedel、Gaussier和Bouchard(2016年)提出了基于复杂嵌入的复合物。在复数中,每一个实体和关系都用一个复数向量来表示,并且得分功能是:
取向量x的虚数部分,其中x(r)是向量的虚数部分。它只使用厄米点积,因为它涉及两个向量之一的共轭转置。因此,反对称关系的事实可以处理得很好
基于多源信息的知识推理
各种辅助信息,如逻辑规则、文本描述、实体类型等可以结合起来,进一步提高性能。在本节中,我们将讨论如何集成这些信息。
逻辑规则可以捕捉自然语言丰富的语义,支持复杂的推理,但由于依赖于逻辑背景知识,在大规模知识图的推理中往往表现较差。相比之下,分布表示是有效的,并且可以进行泛化。因此,将逻辑规则注入到嵌入中进行推理受到了广泛的关注。
Rocktäschel,Bošnjak,Singh,and Riedel(2014)使用一阶逻辑规则指导实体和关系学习,然后进行逻辑推理。此外,他们还提出了一种学习实体对和关系嵌入的范式,该范式结合了矩阵分解和一阶逻辑领域知识的优势(Rocktäschel,Singh,&Riedel,2015)。提出了两种注入逻辑背景知识的预分解推理和联合优化技术。对于预分解推理,它们首先对训练数据进行逻辑推理,然后将事实作为附加数据进行推理。他们提出了一个联合目标,奖励满足给定逻辑知识的预测,从而学习不需要在测试时进行逻辑推理的嵌入。
demeter,Rocktäschel,and Riedel(2016a)提出了一种基于矩阵分解的高效方法,将蕴涵规则整合到分布式表示中进行知识库推理。知识的外部关系是用常识来推理的。Wang和Cohen(2016)提出了一种矩阵分解方法来学习一阶逻辑嵌入。图7显示了框架的概述。具体来说,他们首先使用ProPPR的结构梯度法(Wang,Mazaitis,&Cohen,2014a)从知识图中生成一组推理公式。然后,他们使用这组公式、背景图和训练示例生成ProPPR证明图。为了对公式进行推理,他们将训练示例映射到二维矩阵的行中,并将推理公式映射到列中。最后,将这些学习到的嵌入转化为公式的参数,利用学习的公式嵌入进行一阶逻辑推理。Guo,Wang,Wang,Wang,and Guo(2016)提出了KALE,一种通过知识和逻辑联合建模来学习实体和关系进行推理的新方法。KALE由三个关键部分组成:三元建模模块、规则建模模块和联合学习模块。对于三重模型,他们遵循TransE来模拟三重模型。为了对规则进行建模,他们使用了t-范数模糊逻辑(Hájek,2013),该逻辑将复杂公式的真值定义为其组成部分的真值通过基于逻辑连接词的特定t-范数的组合。在将三元组和规则统一为原子和复杂公式之后,KALE将学习实体和关系嵌入的全局损失最小化。真理值越大,基本规则就越满足。以这种方式嵌入预测新的事实,甚至不能直接由纯粹的推断。文本信息和类型信息等多源信息作为对三元组结构信息的补充,对KGs推理具有重要意义。
Wang,Zhang,Feng,and Chen(2014b)介绍了一种新的方法,即联合嵌入知识图和文本语料库,以便在同一向量空间中表示实体和单词或短语。具体来说,他们定义了一个连贯的概率转换模型(pTransE),它由三个部分组成:知识模型、文本模型和对齐模型。知识模型用于事实建模,对齐模型保证实体和单词或短语的嵌入位于同一空间,并促使两个模型相互增强。实验结果表明,该方法对新事实的推理是非常有效的,并且能够进行类比推理。
此外,Wang和Li(2016)提出了一种新的文本增强知识嵌入(TEKE)方法,利用文本语料库中丰富的上下文信息。结合丰富的文本信息,扩展知识图的语义结构,更好地支持推理。在TEKE中,他们首先对语料库中的实体进行注释,然后构建一个由实体和单词组成的共现网络,将知识图形和文本信息连接在一起。基于共现网络,它们定义了实体和关系的文本上下文,并将上下文整合到知识图中结构。最后知识推理采用常规的基于翻译的优化过程。在多个数据集上的实验表明,TEKE成功地解决了知识推理的结构稀疏性问题。他,冯,邹,和赵(2015b)整合不同的知识图来同时推断新的事实。他们提出了两个改进的质量的推理知识图。首先,利用关系和实体之间的类型一致性约束来初始化矩阵中的负数据,以减少数据的稀疏性。其次,将不同知识库之间关系的相似性引入矩阵分解模型,利用不同知识库之间的互补性。Xie,Liu,Jia,Luan,and Sun(2016)提出了一种新的方法TKRL来利用层次实体类型中的丰富信息。它们使用递归分层编码器和加权分层编码器为实体构造特定类型的投影矩阵。实验结果表明,类型信息在两种预测任务中都具有显著性。
Tang,Chen,Cui,and Wei(2019)进一步提出了一种新的预测潜在三元组的模型MKRL,该模型整合了多源信息,包括实体描述、层次类型和文本关系。
一般来说,表示学习发展迅速,在大规模知识图的知识表示和推理中显示出巨大的潜力。基于分布式表示的推理方法还有很长的路
- 知识表示学习优点
- 有效地解决数据稀疏性问题
- 知识推理和语义计算方面的效率高于基于逻辑的模型
- 知识表示学习缺点
- 可解释性较差(实体和关系向量的值缺乏明确的物理意义)
基于神经网络和强化学习的推理
神经网络作为一种重要的机器学习算法
基本上模仿人脑进行感知和认知。它在自然语言处理领域得到了广泛的应用,并取得了显著的效果。神经网络具有很强的捕捉能力。它通过非线性变换将输入数据的特征分布从原始空间转换到另一个特征空间,并自动学习特征表示。因此,它适用于抽象任务,如知识推理。神经网络用于知识图推理已有很长一段时间了。
(Nickel,Murphy,Tresp,&Gabrilovich,2016a)。在SE模型中,两个实体向量的参数之间不存在交互作用。为了缓解距离模型的问题,Socher、Chen、Manning和Ng(2013)引入了一个单层模型(SLM),该模型通过标准单层神经网络的非线性隐式连接实体向量。SLM可以用来推理两个实体之间的关系。
然而,非线性只提供了实体向量之间微弱的相互作用。为此,Socher等人。(2013)引入用于推理的表达性神经张量网络(NTN),如图8所示。NTN模型用双线性张量层代替标准的线性神经网络层,该层直接将两个实体向量跨多个维度联系起来。NTN通过平均词向量来初始化每个实体的表示,从而提高了性能。
Chen,Socher,Manning,and Ng(2013a)改进了NTN,方法是使用从文本中以无监督方式学习的词向量初始化实体表示,并且在这样做时,甚至可以查询现有关系以查找在知识图中看不到的实体。知识图和复杂特征空间的不断增加使得推理方法的参数规模变得非常大。
(Shi&Weninger,2017b)提出了一种称为ProjE的共享变量神经网络模型,通过对结构的简单改变,实现了更小的参数大小。
刘等。(2016a)提出了一种新的深度学习方法,称为神经关联模型(NAM),用于人工智能中的概率推理。他们研究了两种NAM结构,即深度神经网络(DNN)和关系调制神经网络(RMNN)。在NAM框架中,所有符号事件都在低维向量空间中表示,以解决现有方法所面临的表示能力不足的问题。在多个推理任务上的实验表明,DNN和RMNN的性能都优于传统方法。
基于卷积神经网络的知识推理
基于递归神经网络的知识推理
基于强化学习的知识推理
知识图推理的应用
知识图推理方法从已有的三元组中推理出未知关系,不仅为大规模异构知识图中的资源提供了高效的关联发现能力,而且完成了知识图的生成。保证了图形推理等技术的一致性和一致性。推理技术通过对领域知识和规则的建模来进行领域知识推理,支持自动决策、数据挖掘和链路预测。知识图具有强大的智能推理能力,可以广泛应用于许多下游任务。在本节中,我们将这些任务分为In-KG应用程序和Out-KG应用程序,如下所述
KG内应用
-
KG补全
构造大规模知识图需要不断更新实体之间的关系。然而,尽管这些知识库看似庞大,却缺少大量的信息。例如,Freebase中超过70%的人没有已知的出生地,99%的人没有已知的种族(West等人,2014年)。在知识库中填充最小事实的一种方法是根据现有的三元组推断未知事实,这称为知识图完成,也称为链接预测(Liu,Sun,Lin,&Xie,2016b)。
由于数据源的噪声和提取过程的不精确性,知识图中也存在噪声知识和知识矛盾现象(Dong et al.,2014)。NELL的一个主要问题是,随着其持续运行,所获得的知识的准确性逐渐降低。在第一个月后,NELL的估计精度为0.9;两个月后,精度下降到0.71。根本原因是提取模式不是完全可靠的,因此有时会提取错误的实例。假实例将被用来提取越来越多不可靠的抽取模式和错误实例,最终控制知识库。NELL利用周期性的人工监督来减轻不正确的三胞胎。然而,人的监督是非常昂贵的。因此,需要使用知识图推理方法来自动清理有噪声的知识库。 -
实体分类
实体分类的目的是确定某个实体的类别(如人、地点),例如巴拉克奥巴马是一个人,夏威夷是一个地点。由于关系编码实体类型(表示为IsA)包含在KG中,并且已经包含在嵌入过程中,因此它可以被视为一个特殊的实体预测任务。因此,实体分类显然是图谱补全问题。
KG外应用
-
医学领域
目前,医学领域已成为知识图应用最为活跃的领域,也是人工智能领域的研究热点。当应用于医学知识图时,知识推理方法可以帮助医生收集健康数据、诊断疾病和控制错误(Yuan et al.,2018)。
例如,Kumar、Singh和Sanyal(2009)提出了一种基于案例推理和基于规则推理的混合方法来构建重症监护病房(ICU)的临床决策支持系统。García-Crespo、Rodríguez、Mence、Gómez Berbís和Colomo Palacios(2010)设计了一个基于逻辑推理和概率细化的本体驱动的鉴别诊断系统(ODDIN)。Martínez Romero等人。(2013)构建基于本体的急性心脏病危重病人智能监护治疗系统,专家知识由OWL本体和一组SWRL规则表示。基于这些知识,推理机执行推理过程,并向医生提供关于患者治疗的建议。阮、孙、王、方、尹(2016)将中医药知识图中存储的数据转换为推理规则,然后与患者数据结合,根据知识图推断出辅助处方。
即使是同一种疾病,由于医学领域对主观判断的依赖性,医生也可能根据病人的病情做出不同的诊断。因此,医学知识图必须处理大量重复的矛盾信息,这增加了医学推理模型的复杂性。传统的知识推理方法虽然促进了医学诊断过程的自动化,但也存在学习能力不足、数据利用率低等缺陷。面对越来越多的医学数据,不可避免地会出现一些信息缺失,诊断时间过长。为了解决上述问题,我们需要探索和研究高效的医学推理模型。 -
互联网金融
金融学也是知识图表的一个活跃领域
知识图中的投资关系和雇佣关系可以通过聚类算法识别利益相关者群体。当某些节点发生变化或发生大型事件时,可以通过路径排序和子图发现方法推断出更改实体之间的关联。
在金融业,反欺诈是一项重要的任务。通过知识推理,人们可以验证信息的一致性,从而提前识别欺诈行为(Kapetanakis、Samakovitis、Gunasekera和Petridis,2012)。
此外,知识推理在证券投资领域也发挥着重要作用(He,Ni,Cao,&Ma,2016)。例如,Ding,Zhang,Liu,and Duan(2016)提出了一种将知识图信息和事件嵌入相结合的股票预测模型。然而,这项工作并没有捕捉到文本中的结构信息,这些信息对于影响股票的涨跌非常重要。因此,Liu,Zeng,Yang,and Carrio(2018)提出了一种元组和文本的联合学习模型,使用TransE模型和卷积神经网络捕捉事件元组中的结构化信息。预测结果可以为企业决策提供依据,改善投资计划。知识图推理提高了金融业的资源配置效率,增强了风险管理和控制能力,有效地促进了金融业的发展。
然而,由于金融行业数据的标准化程度较低,且分散在多个数据系统中,现有的数据分析和推理方法难以满足大规模数据分析的要求。针对这一问题,需要引入外部知识库来实现跨领域大规模知识图的推理。 -
智能问答系统
基于知识库的问答(KBQA)分析查询问题,然后从知识库中找到答案。然而,由于知识图的不完整性,KBQA还需要推理技术的支持。例如,沃森在《危难中战胜了人类》,知识推理在其中扮演了重要角色。危险性的问题涉及多个领域,要求考生分析和推理蕴涵、反讽和谜语。智能问答系统,如苹果的Siri、微软的Cortana和亚马逊的Alexa,都需要知识图推理的支持。
知识推理技术的发展为智能答疑系统的发展奠定了技术基础。例如,Jain(2016)提出了事实记忆网络,它通过从Freebase中提取和推理相关事实来回答问题。它在同一向量空间中表示问题和三元组,生成候选事实,然后利用多跳推理找出答案。回答Zhang Koan(2018a)的问题,并提出Kang-Kan网络的变分推理(Dai-end-La)。VRN首先识别主题实体。在给定主题实体的情况下,通过知识图上的多跳推理,可以得到问题的答案。
Narasimhan,Lazebnik,and Schwing(2018)提出了一种基于图卷积网(GCN)的算法(Kipf&Welling,2016),用于视觉问答中的推理。在回答问题时,他们将可视化的情境与以知识库形式编码的一般知识相结合。
然而,智能答疑系统还存在一些问题需要解决。
- 首先,KBQA主要关注单一事实问题。具体来说,回答这个问题只需要三分之一的知识图谱。同时,对于需要多步骤推理的复杂问题,比如在回答“姚明妻子的女儿叫什么名字?”?“,KBQA表现不佳。最近,张,戴,托曼,宋(2018b)模仿人脑来解决这个问题。
- 第二,现有的知识库是由事实知识和缺乏常识组成的。然而,常识在人脑推理过程中起着重要作用,常识知识难以规范化。因此,将常识知识引入知识库中进行推理是智能答疑中的一个关键问题。
- 推荐系统
基于知识图的推荐系统将用户和项目连接起来,整合多个数据源,丰富语义信息。通过推理技术可以获得隐含信息,提高推荐精度。基于知识图推理的推荐有几种典型案例,如购物推荐、电影推荐、音乐推荐等。
Wang等人。(2018a)提出了知识感知路径递归网络(kpn),它不仅通过考虑实体和关系来生成路径表示,而且基于路径进行推理以推断用户偏好。与现有的只注重利用知识图进行更准确推荐的方法不同,Xian,Fu,Muthukrishnan,de Melo,
Zhang(2019)提出了一种策略引导路径推理(PGPR)方法,该方法可以在知识图上进行推理并进行解释。PGPR是一个灵活的图形推理框架,可以扩展到许多其他基于图的任务,如产品搜索和社会推荐。借助于推理技术,可以在推荐系统中使用多源异构数据。但是,它还处于初步发展阶段,面临着许多挑战。在未来的推荐系统中,如何解决冷启动问题和基于知识的显式推理是未来研究的重点
值得探索。
7. 其他应用
知识推理技术在其他一些智能场景中也起着重要作用。例如,知识推理技术可以用来理解用户在搜索引擎中的查询意图。此外,它还可以用于其他计算语言学任务,如剽窃检测、情感分析、文档分类、口语对话系统等。
具体而言,Franco Salvador、Gupta、Rosso和Banchs(2016a);Franco Salvador、Rosso和Montes-y Gómez(2016b)研究了将知识图推理方法和连续表示方法相结合的混合模型,用于跨语言剽窃检测任务。
Cambria、Olsher和Rajagopal(2014)展示了如何使用Sentinet 3和COGBASE推断句子的极性。
Franco Salvador、Cruz、Troyano和Rosso(2015)提出使用元学习,通过添加通过推理获得的基于知识的特征来解决单域和跨域极性分类任务,从而结合和丰富现有方法。
Franco Salvador,Rosso,and Navigli(2014)利用多语言知识图,即BabelNet,获得与语言无关的文档知识表示,以解决两个任务:可比文档检索和跨语言文本分类。
Ma、Crook、Sarikaya和Fosler Lussier(2015)提出了推理知识图来构成口语对话系统的一部分。
Wang等人。(2018b)提出了一种基于社会知识图的图推理模型(GRM),从图像中推理出两个人之间的关系。随着深层神经网络在自然语言处理任务中的广泛应用,知识推理将迎来更广阔的前景。
总结
随着知识库的发展,知识图推理在多个知识驱动的任务中得到了广泛的研究和应用,大大提高了它们的性能。在这一部分中,我们首先对这些识别差距的方法进行了简要的总结,然后提出了知识图推理的研究机会。
在本文中,我们对现有的技术进行了广泛的综述,包括基于规则的推理方法、基于分布式表示的推理方法和基于神经网络的推理方法。我们总结了每种模型的优缺点、代表作和应用,如表3所示。
总结
综上所述,这三类推理方法既有区别又有相似之处,在推理任务中是互补的。其关联性在于将知识图抽象为拓扑,然后利用实体间的拓扑关系对特征进行建模和参数学习。其主要区别在于基于神经网络的知识推理模型将CNN或RNN集成到表示学习模型或逻辑规则模型中,通过深度学习模型的自学习能力提取特征,然后利用其记忆推理能力建立实体关系预测模型。表示学习模型将实体和关系映射到低维向量空间,并基于语义表达进行推理。其优点是在生成知识表示向量时,可以充分利用KG中的结构信息。缺点是建模时不能引入先验知识来实现推理。逻辑规则模型使用抽象或具体的Horn子句作为推理模型,本质上是基于规则的推理。它的优点是可以模拟人类的逻辑推理行为,并引入人类的先验知识来辅助推理。缺点是它没有解决对领域专家的依赖性、计算复杂度高、泛化能力差等一系列问题。
研究机会
虽然现有的模型已经显示出它们在KGs上的推理能力,但仍有许多可能的改进有待于探索。在这一部分,我们将讨论知识图推理的挑战,并提供潜在的研究机会。
- 动态知识推理
现有的知识图推理方法主要针对静态多关系数据,而忽略了知识图中包含的有用时间信息。然而,知识不是一成不变的,它会随着时间而发展。我们注意到KG事实并非普遍正确,因为它们往往只在特定的时间范围内有效。例如,(巴拉克奥巴马,美国总统)只有在2009年到2016年才是真实的。因此,在推理过程中将时间信息纳入会计核算是完全可以想象的。针对这一问题的研究还不多见,但还处于初步阶段,动态知识图的推理方法还有待进一步探索。
- 零射击推理
现有的知识图推理模型往往需要大量高质量的样本进行训练和学习,而这需要耗费大量的时间和人力。近年来,零镜头学习在计算机视觉、自然语言处理等领域引起了广泛的关注。零射击学习可以从一个看不见的班级或只有几个实例的班级学习。在推理过程中,实际问题是无法获得大量的训练样本,导致许多知识推理模型失效。当然,文本描述和多模态信息等附加信息可以帮助处理零镜头场景。此外,有必要设计一个更适合于从KGs中推理实体的新框架。
- 多源信息推理
随着移动通信技术的飞速发展,人们可以随时在网上上传和共享文本、音频、图像、视频等多媒体内容。如何有效地利用这些丰富的信息成为一个关键而富有挑战性的问题。多源信息已显示出其有助于对KGs进行推理的潜力,而现有的利用这些信息的方法仍处于初步阶段。我们可以
设计更有效、更优雅的模型来更好地利用这些信息。
- 多语言知识图推理
有很多KG,比如Freebase,DBpedia都通过从Wikipedia中提取结构化信息来构建多语言版本。多语种KGs在机器翻译、跨语言剽窃检测、信息提取等领域发挥着重要作用。然而,据我们所知,关于多语种KG的推理工作还很少。例如,(Abouenour,Nasri,Bouzoubaa,Kabbaj,&Rosso,2014)构建了一个支持语义推理的阿拉伯语问答系统,并(Chen,Tian,Chang,Skiena,&Zaniolo,2018a)提出了一种基于法语和德语KG的跨语言推理方法。因此,多语种知识图推理也是一项有意义但富有挑战性的工作。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132012.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
