大家好,又见面了,我是你们的朋友全栈君。

 RAID 基本思想就是把多个相对便宜的硬盘组合起来,使其组合成一个容量更大、更安全的硬盘组.目前已有的RAID硬盘组方案至少有几十种,其最常用的要数RAID5与RAID10硬盘组方案。软RAID(software-based RAID)是基于软件的RAID。它可能是最普遍的被使用的RAID阵列,这是由于现在的很多服务器操作系统都集成了RAID功能。
RAID 基本思想就是把多个相对便宜的硬盘组合起来,使其组合成一个容量更大、更安全的硬盘组.目前已有的RAID硬盘组方案至少有几十种,其最常用的要数RAID5与RAID10硬盘组方案。软RAID(software-based RAID)是基于软件的RAID。它可能是最普遍的被使用的RAID阵列,这是由于现在的很多服务器操作系统都集成了RAID功能。
硬RAID(这里只讨论基于总线的RAID)是由内建RAID功能的主机总线适配器(Host bus adapter)控制,直接连接到服务器的系统总线上的。
RAID 0
RAID 0 称为条带(stripe)存储,即把数据连续依次的分布存储到每个硬盘上(每一块硬盘都配备一个专门的磁盘控制器),形成条带状。 当系统有数据请求时,就可以被多个硬盘并行的处理,每个硬盘只需处理自己盘上的那部分数据,这种数据的并行操作,充分的提高了系统总线的负荷,从而提高了阵列整体的性能。 是目前存储速度最快的一种,一旦某个硬盘发生了故障损坏,所有数据将无法恢复.
数据将分成数据块依次保存到各个硬盘上。因为数据是分布到各个硬盘上的,所有数据的读写负荷也就分布在不同的硬盘上了,其负荷就比较平衡。由于没有进行数据容错处理,一旦其中一个盘的数据发送了损坏,即使其他盘完好无损,其所有数据也是无法恢复的。RAID0不适合用于对数据稳定性要求高的数据存储,一般可以用来存储一些视频监控等数据,从而提高了数据的存储速度。
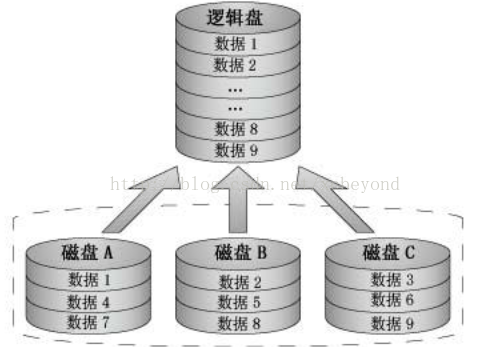
RAID 1
 RAID 1称为磁盘镜像:把一个磁盘的数据镜像到另一个磁盘上,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,具有很高的数据冗余能力。RAID 1有以下特点:RAID 1的每一个磁盘都具有一个对应的镜像盘,任何时候数据都同步镜像,系统可以从一组镜像盘中的任何一个磁盘读取数据。
RAID 1称为磁盘镜像:把一个磁盘的数据镜像到另一个磁盘上,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,具有很高的数据冗余能力。RAID 1有以下特点:RAID 1的每一个磁盘都具有一个对应的镜像盘,任何时候数据都同步镜像,系统可以从一组镜像盘中的任何一个磁盘读取数据。
磁盘所能使用的空间只有磁盘容量总和的一半,系统成本高
只要系统中任何一对镜像盘中至少有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行。
出现硬盘故障的RAID系统不再可靠,应当及时的更换损坏的硬盘,否则剩余的镜像盘也出现问题,那么整个系统就会崩溃。
更换新盘后原有数据会需要很长时间同步镜像,外界对数据的访问不会受到影响,只是这时整个系统的性能有所下降。
RAID 1磁盘控制器的负载相当大,用多个磁盘控制器可以提高数据的安全性和可用性。
RAID 1技术支持”热替换“机制,即在不需要断电的情况下,可以对故障盘进行替换,更换完毕只要从镜像盘上恢复数据即可。当主硬盘损坏时,镜像硬盘就可以代替主硬盘工作。镜像硬盘相当于一个备份盘,可想而知,这种硬盘模式的安全性是非常高的,RAID 1的数据安全性在所有的RAID级别上来说是最好的。但是其磁盘的利用率却只有50%,是所有RAID级别中最低的。
RAID2
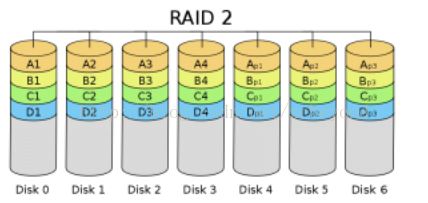 RAID 2称为带海明码校验的RAID技术,首先将数据条带化,分布到不同的硬盘上,RAID 2 应用了海明码校验来提供数据错误检查及恢复机制。这种校验技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施较为复杂。由于海明码校验技术的复杂,导致RAID 2成为了RAID技术中最为复杂的级别之一。
RAID 2称为带海明码校验的RAID技术,首先将数据条带化,分布到不同的硬盘上,RAID 2 应用了海明码校验来提供数据错误检查及恢复机制。这种校验技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施较为复杂。由于海明码校验技术的复杂,导致RAID 2成为了RAID技术中最为复杂的级别之一。
在RAID 2中,一个硬盘在一个时间戳内只存取一位数据信息。如下图所示,Disk 0、Disk 1、Disk 2、Disk 3为存储数据的硬盘(简称为数据阵列),每次每个硬盘只存取一位数据A1、A2、A3、A4……。同理,Disk 4、Disk 5、Disk 6为存储校验码的硬盘(简称为校验阵列),每一个硬盘用来存放相应的一位海明码。如果是4位的数据宽度,那么就需要4个数据硬盘和3个海明码校验硬盘,如果是64 位的位宽呢?数据阵列需要64块硬盘,校验阵列需要7块硬盘。
在数据写入时,RAID 2 在写入数据位同时还要计算出它们的汉明码并写入校验阵列,读取时也要对数据即时地进行校验及纠正,最后再发向系统。海明码只能纠正一个位的错误,所以RAID 2 也只能允许一个硬盘出问题,如果两个或以上的硬盘出问题,RAID 2 的数据就将受到破坏。但由于数据是以位为单位并行传输,所以传输率也相当快。
RAID3:带奇偶校验码的并行传送
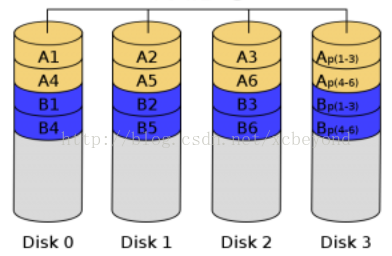 RAID 3,这种校验码与RAID2不同,只能查错不能纠错。它访问数据时一次处理一个带区,这样可以提高读取和写入速度,它像RAID 0一样以并行的方式来存放数据,但速度没有RAID 0快。
RAID 3,这种校验码与RAID2不同,只能查错不能纠错。它访问数据时一次处理一个带区,这样可以提高读取和写入速度,它像RAID 0一样以并行的方式来存放数据,但速度没有RAID 0快。
不同于 RAID 2,RAID 3使用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘及其他数据盘可以重新产生数据。 如果奇偶盘失效,则不影响数据使用。RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据,奇偶盘会成为写操作的瓶颈。 利用单独的校验盘来保护数据虽然没有镜像的安全性高,但是硬盘利用率得到了很大的提高,为 n-1。
RAID 3使用一个专门的磁盘存放所有的校验数据,而在剩余的磁盘中创建带区集分散数据的读写操作。当一个完好的RAID 3系统中读取数据,只需要在数据存储盘中找到相应的数据块进行读取操作即可。但当向RAID 3写入数据时,必须计算与该数据块同处一个带区的所有数据块的校验值,并将新值重新写入到校验块中,这样无形虽增加系统开销。当一块磁盘失效时,该磁盘上的所有数据块必须使用校验信息重新建立,如果所要读取的数据块正好位于已经损坏的磁盘,则必须同时读取同一带区中的所有其它数据块,并根据校验值重建丢失的数据,这使系统减慢。当更换了损坏的磁盘后,系统必须一个数据块一个数据块的重建坏盘中的数据,整个系统的性能会受到严重的影响。RAID 3最大不足是校验盘很容易成为整个系统的瓶颈,对于经常大量写入操作的应用会导致整个RAID系统性能的下降。RAID 3适合用于数据库和WEB服务器等。
是将数据先做XOR 运算,产生Parity Data后,在将数据和Parity Data 以并行存取模式写入成员磁盘驱动器中,因此具备并行存取模式的优点和缺点。进一步来说,RAID 3每一笔数据传输,都更新整个Stripe﹝即每一个成员磁盘驱动器相对位置的数据都一起更新﹞,因此不会发生需要把部分磁盘驱动器现有的数据读出来,与新数据作XOR运算,再写入的情况发生﹝这个情况在 RAID 4和RAID 5会发生,一般称之为Read、Modify、Write Process,我们姑且译为为读、改、写过程﹞。因此,在所有 RAID级别中,RAID 3的写入性能是最好的。
RAID 3 的 Parity Data 一般都是存放在一个专属的Parity Disk,但是由于每笔数据都更新整个Stripe,因此,RAID 3的 Parity Disk 并不会如RAID 4的 Parity Disk,会造成存取的瓶颈。
RAID 3 的并行存取模式,需要RAID 控制器特别功能的支持,才能达到磁盘驱动器同步控制,而且上述写入性能的优点,以目前的Caching 技术,都可以将之取代,因此一般认为RAID 3的应用,将逐渐淡出市场。
RAID 3 以其优越的写入性能,特别适合用在大型、连续性档案写入为主的应用,例如绘图、影像、视讯编辑、多媒体、数据仓储、高速数据撷取等等。
RAID4
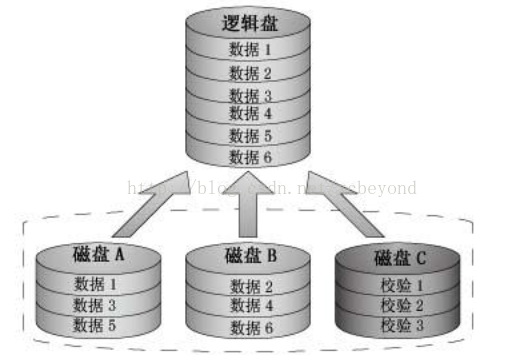 RAID4是带奇偶校验码的独立磁盘结构,RAID4是RAID 3和RAID 0的结合,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘,RAID4的特点和RAID3也挺象,不过在失败恢复时,它的难度可要比RAID3大得多了,控制器的设计难度也要大许多,而且访问数据的效率不怎么好。
RAID4是带奇偶校验码的独立磁盘结构,RAID4是RAID 3和RAID 0的结合,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘,RAID4的特点和RAID3也挺象,不过在失败恢复时,它的难度可要比RAID3大得多了,控制器的设计难度也要大许多,而且访问数据的效率不怎么好。
RAID4和RAID3很像,不同的是,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。在图上可以这么看,RAID3是一次一横条,而RAID4一次一竖条。它的特点和RAID3也挺象,不过在失败恢复时,它的难度可要比RAID3大得多了,控制器的设计难度也要大许多,而且访问数据的效率不怎么好。
创建 RAID 4 需要三块或更多的磁盘,它在一个驱动器上保存校验信息,并以RAID 0方式将数据写入其它磁盘,如图所示。因为一块磁盘是为校验信息保留的,所以阵列的大小是(N-l)*S,其中S是阵列中最小驱动器的大小。就像在 RAID 1中那样,磁盘的大小应该相等.
如果一个驱动器出现故障,那么可以使用校验信息来重建所有数据。如果两个驱动器出现故障,那么所有数据都将丢失。不经常使用这个级别的原因是校验信息存储在一个驱动器上。每次写入其它磁盘时,都必须更新这些信息。因此,在大量写入数据时很容易造成校验磁盘的瓶颈,所以目前这个级别的RAID很少使用了。
RAID 4 是采取独立存取模式,同时以单一专属的Parity Disk 来存放Parity Data。RAID 4的每一笔传输资料较长,而且可以执行Overlapped I/O,因此其读取的性能很好。
RAID 5
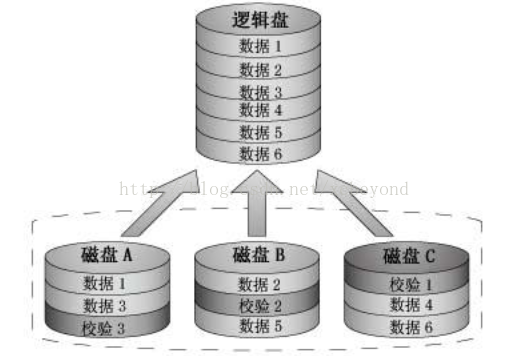 RAID 5把校验块分散到所有的数据盘中。RAID 5使用了一种特殊的算法,可以计算出任何一个带区校验块的存放位置。这样就可以确保任何对校验块进行的读写操作都会在所有的RAID磁盘中进行均衡,从而消除了产生瓶颈的可能。RAID5的读出效率很高,写入效率一般,块式的集体访问效率不错。RAID 5提高了系统可靠性,但对数据传输的并行性解决不好,而且控制器的设计也相当困难。
RAID 5把校验块分散到所有的数据盘中。RAID 5使用了一种特殊的算法,可以计算出任何一个带区校验块的存放位置。这样就可以确保任何对校验块进行的读写操作都会在所有的RAID磁盘中进行均衡,从而消除了产生瓶颈的可能。RAID5的读出效率很高,写入效率一般,块式的集体访问效率不错。RAID 5提高了系统可靠性,但对数据传输的并行性解决不好,而且控制器的设计也相当困难。
RAID5 与 RAID4 之间最大的区别就是校验信息均匀分布在各个驱动器上,如上图所示,这样就避免了RAID 4中出现的瓶颈问题。如果其中一块磁盘出现故障,那么由于有校验信息,所以所有数据仍然可以保持不变。如果可以使用备用磁盘,那么在设备出现故障之后,将立即开始同步数据。如果两块磁盘同时出现故障,那么所有数据都会丢失。RAID5 可以经受一块磁盘故障,但不能经受两块或多块磁盘故障。
RAID 5是采取独立存取模式,但是其Parity Data 是分散写入到各个成员磁盘驱动器,因此,除了具备Overlapped I/O 多任务性能之外,同时也脱离如RAID 4单一专属Parity Disk的写入瓶颈。但是,RAID 5在做资料写入时,仍然稍微受到”读、改、写过程”的拖累。
由于RAID 5 可以执行Overlapped I/O 多任务,因此当RAID 5的成员磁盘驱动器数目越多,其性能也就越高,因为一个磁盘驱动器在一个时间只能执行一个 Thread,所以磁盘驱动器越多,可以Overlapped 的Thread 就越多,当然性能就越高。但是反过来说,磁盘驱动器越多,数组中可能有磁盘驱动器故障的机率就越高,整个数组的可靠度,或MTDL (Mean Time to Data Loss) 就会降低。
由于RAID 5将Parity Data 分散存在各个磁盘驱动器,因此很符合XOR技术的特性。例如,当同时有好几个写入要求发生时,这些要写入的数据以及Parity Data 可能都分散在不同的成员磁盘驱动器,因此RAID 控制器可以充分利用Overlapped I/O,同时让好几个磁盘驱动器分别作存取工作,如此,数组的整体性能就会提高很多。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131892.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
