大家好,又见面了,我是你们的朋友全栈君。
小型简易爬虫源码(java版)
一,介绍:
>这是我的第一个爬虫,比较简单,没有队列,广度优先算法等,用list集合代替了队列。
>而且只爬取一个网址上面的图片,并不是将网址中的链接<href>加入队列,然后下载一个网址一个网址下载其中的图片。
>不过,这是前期的,处于摸索阶段,后期学完队列和广算后,在涉及一点多线程,肯定会比想象中的更实用。
二,代码:
Start_Crawler类:
package com.xhs.crawler;
import java.util.Scanner;
/**
* @author XHS_12302
* @version 1.0
* @date 2017_07_11
*
*
* @description 这是我的第一个爬虫,比较简单,没有队列,广度优先算法等,用list集合代替了队列。
* 而且只爬取一个网址上面的图片,并不是将网址中的链接<href>加入队列,然后下载一个网址一个网址下载其中的图片。
* 不过,这是前期的,处于摸索阶段,后期学完队列和广算后,在涉及一点多线程,肯定会比想象中的更实用
*/
public class Start_Crawler {
public static void main(String[] args) {
System.out.println("请输入网址:");
//获取用户要爬取的网址
Scanner in=new Scanner(System.in);
String url=in.next();
//通过用户的输入建立一个Get_Html的一个g对象
Get_Html g=new Get_Html(url);
//调用g中的get()方法模拟请求网站服务器,返回回应的字符串
String htmlstr=g.get();
//建立一个Html_analyze对象ha用来分析服务器返回来的字符串
Html_analyze ha=new Html_analyze(htmlstr);
/*for (String href :ha.analyzeHtmlHref()) {
System.out.println(href);
}*/
//调用ha.analyzeHtmlImage()方法将分析出来的图片地址放进list里面,传回来一个图片地址集合,
//然后新建下载。
new Download_pic().Download(ha.analyzeHtmlImage());
System.out.println("program has done!");
in.close();
}
}
Get_Html类:
package com.xhs.crawler;
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
public class Get_Html {
private String url_path;
private String htmlstr;
StringBuffer contentBuffer = new StringBuffer();
Get_Html(String url){
this.url_path=url;
}
public String get(){
FileWriter fw=null;
try {
fw=new FileWriter("C:\\Users\\Administrator\\Desktop\\crawler.txt");
URL url=new URL(url_path);
URLConnection hc=url.openConnection();
hc.setConnectTimeout(5000);
hc.setDoInput(true);
((HttpURLConnection) hc).setRequestMethod("GET");
int returnCode=((HttpURLConnection) hc).getResponseCode();
if(returnCode==200){
InputStream input=hc.getInputStream();
InputStreamReader istreamReader = new InputStreamReader(input, "utf-8");
BufferedReader buffStr = new BufferedReader(istreamReader);
String str = null;
while ((str = buffStr.readLine()) != null)
contentBuffer.append(str);
htmlstr=contentBuffer.toString();
fw.write(htmlstr);
input.close();
istreamReader.close();
buffStr.close();
fw.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return htmlstr;
}
}
Html_analyze类:
package com.xhs.crawler;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Html_analyze {
private String src;
Html_analyze(String src){
this.src=src;
}
public List<String> analyzeHtmlImage(){
String regex="http[s]{0,1}://[^\\s]*\\.(jpg|bmp|png)";
//String sr="http://img5.imgtn.bdimg.com/it/u=1380084653,2448555822&fm=26&gp=0.jpg";
List<String> listImgUrl=new ArrayList<>();
Pattern p=Pattern.compile(regex);
Matcher m=p.matcher(src);
while(m.find()){
System.out.println(m.group());
listImgUrl.add(m.group());
}
System.out.println("\n\n总共找到记录:"+listImgUrl.size()+"\n");
return listImgUrl;
}
public List<String> analyzeHtmlHref(){
//分析href标签 并且加入listHref
String regex="<a.*?href=\"(.*?)\">";
List<String> listHref=new ArrayList<>();
Pattern p=Pattern.compile(regex);
Matcher m=p.matcher(src);
while(m.find()){
listHref.add(m.group());
}
return listHref;
}
}
Download_pic类:
package com.xhs.crawler;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.List;
public class Download_pic {
public void Download(List<String> listImgSrc) {
int count = 1;
for (String url_path : listImgSrc) {
InputStream in = null;
FileOutputStream fo = null;
String imageName = url_path.substring(
url_path.lastIndexOf("/") + 1, url_path.length());
try {
byte[] data = new byte[500];// 1024
File f = new File(
"C:\\Users\\Administrator\\Desktop\\crawler\\");
if (!f.exists()) {
f.mkdir();
}
fo = new FileOutputStream(new File(f.getAbsolutePath() + "\\"
+ imageName));
URL url = new URL(url_path);
HttpURLConnection con = (HttpURLConnection) url
.openConnection();
con.setConnectTimeout(5000);
con.setDoInput(true);
con.setRequestMethod("GET");
// con.setRequestProperty("user-agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 设置代理
int numCode = con.getResponseCode();
in = con.getInputStream();// int length
int lengthZ = 0;
if (numCode == 200) {
while ((lengthZ = in.read(data)) != -1) {
fo.write(data, 0, lengthZ); // write(data,0,length);
fo.flush();
}
System.out.println("下载成功:\t" + imageName + "\t剩余:\t"
+ (listImgSrc.size() - count));
} else {
System.out.println("访问失败,返回码不是200");
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println(imageName + "下载失败");
} finally {
try {
if (in != null)
in.close();
if (fo != null)
fo.close();
count++;
} catch (IOException e) {
// TODO Auto-generated catch block
// e.printStackTrace();
System.out.println("关闭流出现点问题··");
}
}
}
}
}
三:截图
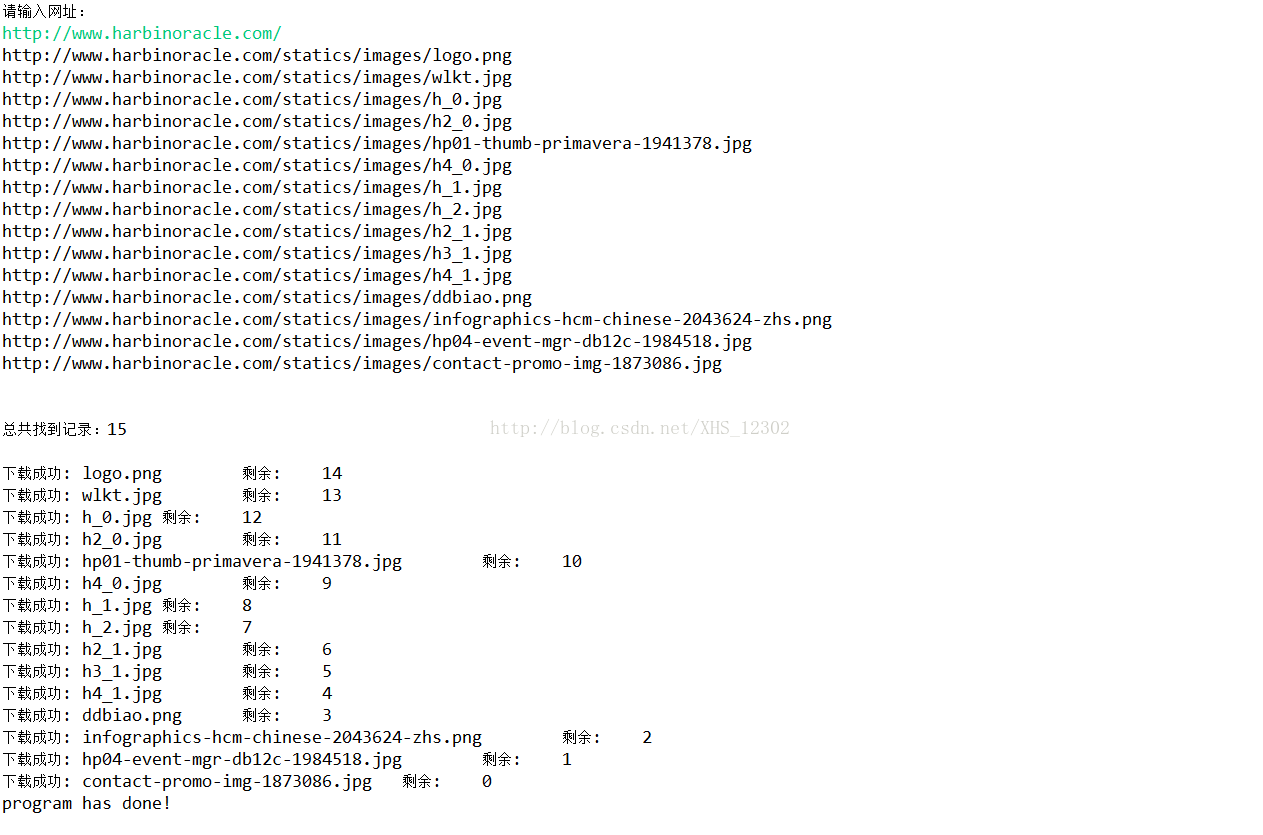


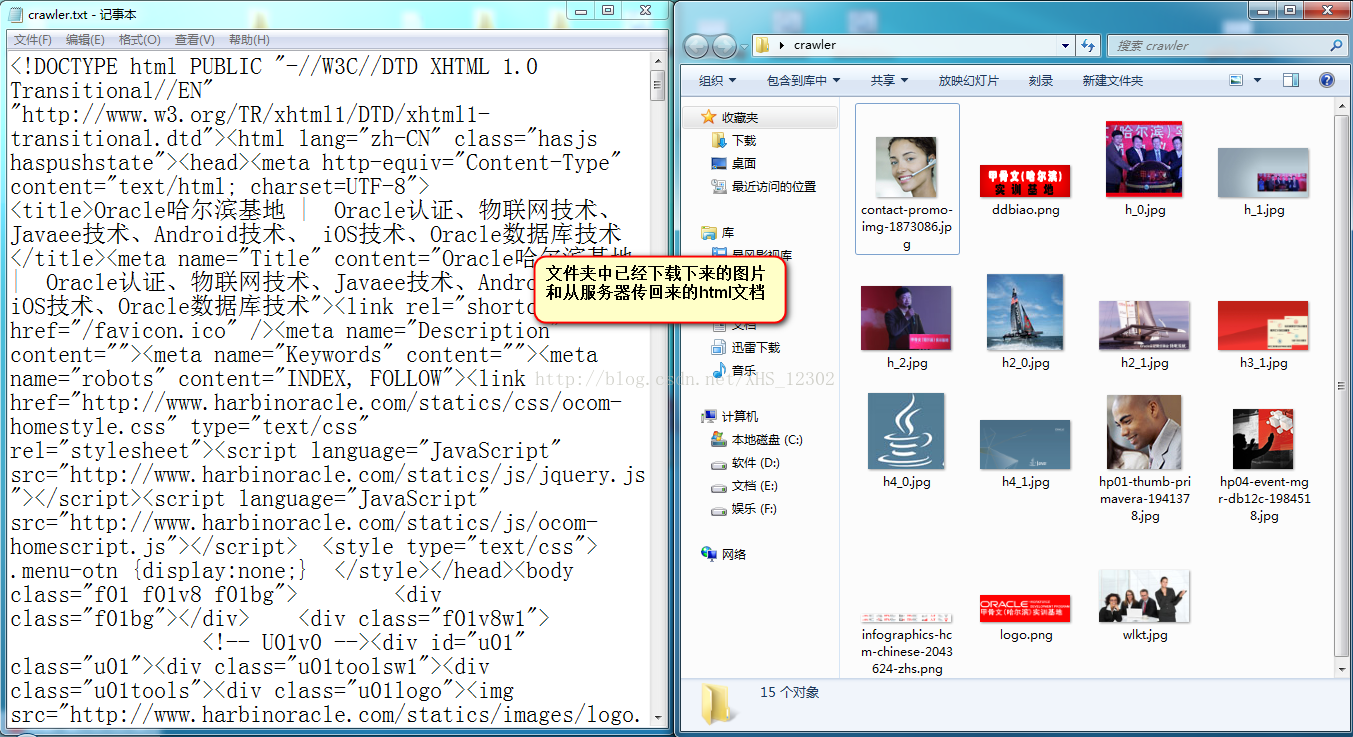
这个只是简易的小东西,不过感觉挺好玩的。
感兴趣的朋友可以自己试试,如果不能满足你要求,
这儿给你提供一种想法,你可以利用这种特性爬
取csdn博客文章访问量。^_^
感兴趣的朋友可以自己试试,如果不能满足你要求,
这儿给你提供一种想法,你可以利用这种特性爬
取csdn博客文章访问量。^_^
联系邮箱:xhsgg12302@outlook.com
2017_07_11
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131808.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
