大家好,又见面了,我是你们的朋友全栈君。
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
本笔记源于CDA-DSC课程,由常国珍老师主讲。该训练营第一期为风控主题,培训内容十分紧凑,非常好,推荐:CDA数据科学家训练营
——————————————————————————————————————————
一、风控建模流程以及分类模型建设
1、建模流程
该图源自课程讲义。主要将建模过程分为了五类。数据准备、变量粗筛、变量清洗、变量细筛、建模与实施。

2、分类模型种类与区别
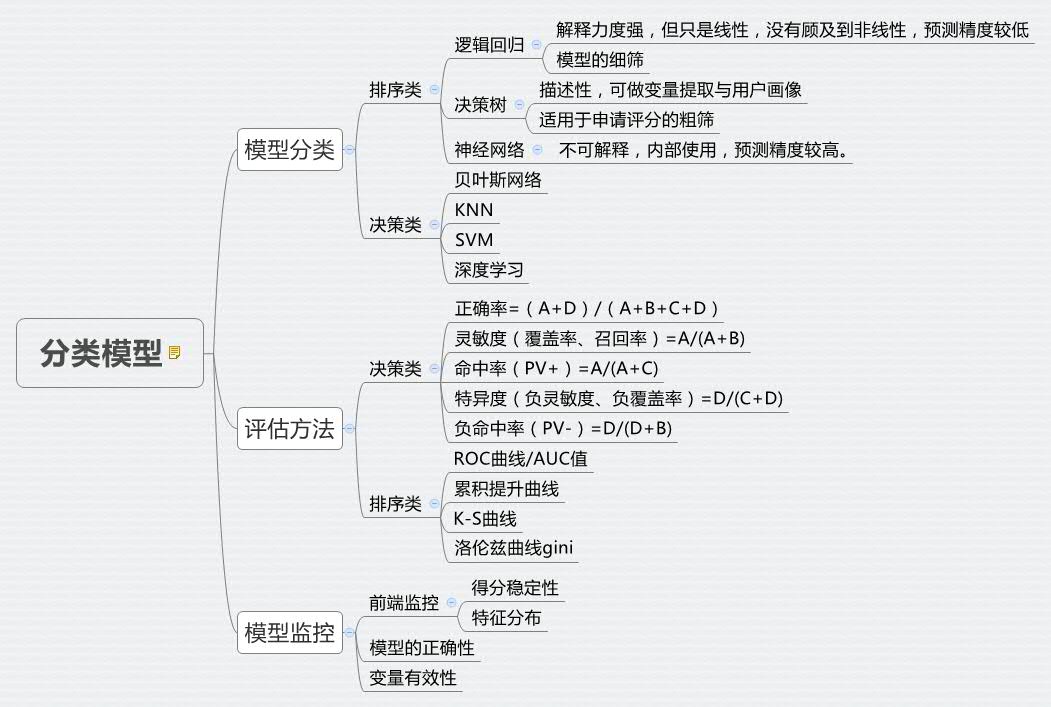
风控与其他领域一样,分类模型主要分为两大类:排序类、决策类、标注类(文本、自然语言处理)。
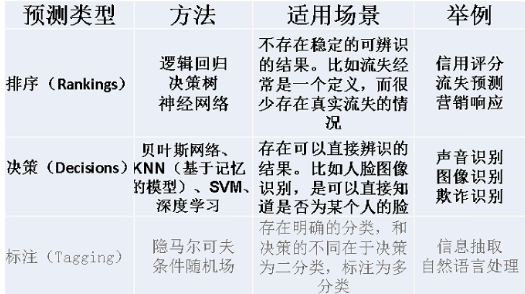
一般来说风控领域在意的是前两个模型种类,排序类以及决策类。
其中:巴塞尔协议定义了金融风险类型:市场风险、作业风险、信用风险。信用风险ABC模型有进件申请评分、行为评分、催收评分。
| 模型 | 解释 | 复杂度 | 应用场景 |
| Logistics回归 | 影响程度大小与显著性,解释力度强,但只是线性,没有顾及到非线性,预测精度较低 | 申请评分、流失预测 | |
| 决策树 | 1、描述性,重建用户场景,可做变量提取与用户画像 | 叶子的数量 | 流失模式识别 |
| 2、树的结构不稳定,可以得出变量重要性,可以作为变量筛选 | |||
| 随机森林 | 随机森林比决策树在变量筛选中,变量排序比较优秀 | ||
| 神经网络 | 1、不可解释,内部使用,预测精度较高。可以作为初始模型的金模型(用以评估在给定数据条件下,逻辑回归可达到的最精确程度) 2、线性(逻辑回归)+非线性关系,可用于行为评分的预测模型(行为评分对模型可解释性不强),可用于申请评分的金模型 3、使用场景:先做一个神经网络,让预测精度(AUC)达到最大时,再用逻辑回归 |
迭代次数 | 申请评分的金模型; 行为评分的预测模型 |
(1)信用风险——申请信用评分
申请评分可以将神经网络+逻辑回归联合使用。
《公平信用报告法》制约,强调评分卡的可解释性。所以初始评分(申请评分)一般用回归,回归是解释力度最大的。
神经网络可用于银行行为评级以及不受该法制约监管的业务(P2P)。其次,神经也可以作为申请信用评分的金模型。
金模型的使用:一般会先做一个神经网络,让预测精度(AUC)达到最大时,再用逻辑回归。
建模大致流程:
一批训练集+测试集+一批字段——神经网络建模看AUC——如果额定的AUC在85%,没超过则返回重新筛选训练、测试集以及字段;
超过则,可以后续做逻辑回归。
(2)信用风险——行为评分
行为评分建模:行为信用评级不需要解释性,所以可以用非线性的神经网络。
——————————————————————————————————————————
二、分类模型评估体系
上述将分类模型做了归纳,不同的分类模型所采用的评估体系不同。
决策类:准确率/误分率、利润/成本
排序类:ROC指标(一致性)、Gini指数、KS统计量、提升度
1、决策类评估——混淆矩阵指标
混淆矩阵,如图:其中这些指标名称在不同行业有不同的名称解释
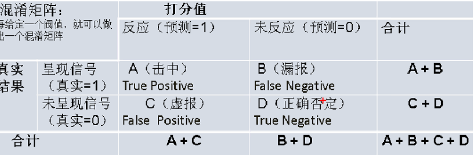
正确率=(A+D)/(A+B+C+D)
灵敏度(覆盖率、召回率)=A/(A+B)
命中率(PV+)=A/(A+C)
特异度(负灵敏度、负覆盖率)=D/(C+D)
负命中率(PV-)=D/(D+B)
在以上几个指标中不同行业看中不同的指标:
(1)灵敏度/召回率/覆盖率(——相对于命中率)
譬如灵敏度(召回率)这一指标就比正确率要重要,覆盖率(Recall)这个词比较直观,在数据挖掘领域常用。因为感兴趣的是正例(positive),比如在信用卡欺诈建模中,我们感兴趣的是有高欺诈倾向的客户,那么我们最高兴看到的就是,用模型正确预测出来的欺诈客户(True Positive)cover到了大多数的实际上的欺诈客户,覆盖率,自然就是一个非常重要的指标。
(2)命中率(——相对于覆盖率)
欺诈分析中,命中率(不低于20%),看模型预测识别的能力。
在数据库营销里,你预测到b+d个客户是正例,就给他们邮寄传单发邮件,但只有其中d个会给你反馈(这d个客户才是真正会响应的正例),这样,命中率就是一个非常有价值的指标。 以后提到这个概念,就表示为PV+(命中率,Positive Predicted Value)*。
2、排序类指标评估
ROC指标(一致性)、Gini指数(洛伦兹曲线)、KS统计量、提升度四类指标。
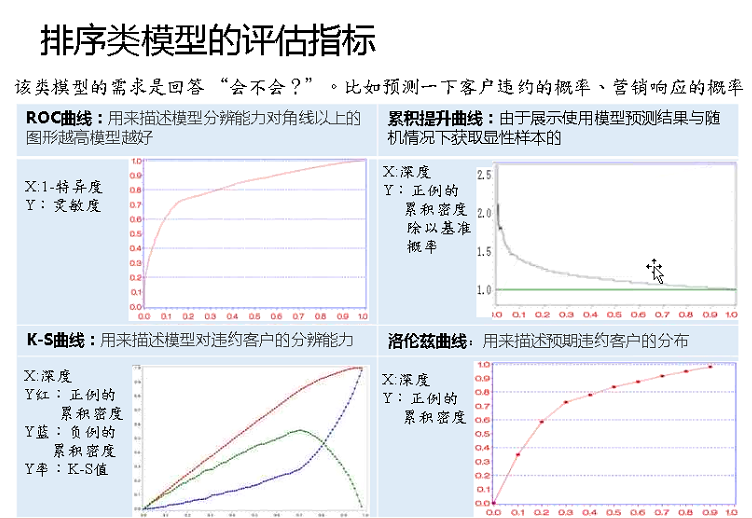
(1)ROC曲线
对角线模型,最差,风控喜欢的指标。由决策类指标的灵敏度(召回率/覆盖率)与特异度(负灵敏度、负召回率)来构造。
求覆盖率等指标,需要指定一个阈值(threshold)。随着阈值的减小,灵敏度和1-特异度也相应增加(也即特异度相应减少)。
把基于不同的阈值而产生的一系列灵敏度和特异度描绘到直角坐标上,就能更清楚地看到它们的对应关系。把sensitivity和1-Specificity描绘到同一个图中,它们的对应关系,就是传说中的ROC曲线,全称是receiver operating characteristic curve,中文叫“接受者操作特性曲线”。
AUC值,为了更好的衡量ROC所表达结果的好坏,Area Under Curve(AUC)被提了出来,简单来说就是曲线右下角部分占正方形格子的面积比例。该比例代表着分类器预测精度。(R语言︱ROC曲线——分类器的性能表现评价)
(2)累积提升曲线
营销最好的图,很简单。它衡量的是,与不利用模型相比,模型的预测能力“变好”了多少(分类模型评估——混淆矩阵、ROC、Lift等)。
将概率从大到小铺开x,提升度可以有一些“忽悠”的成本,哈哈~可以微调,可以自己调节提升度的区间
(3)K-S曲线
风控喜欢的指标。K-S曲线的最大值代表K-S统计量。
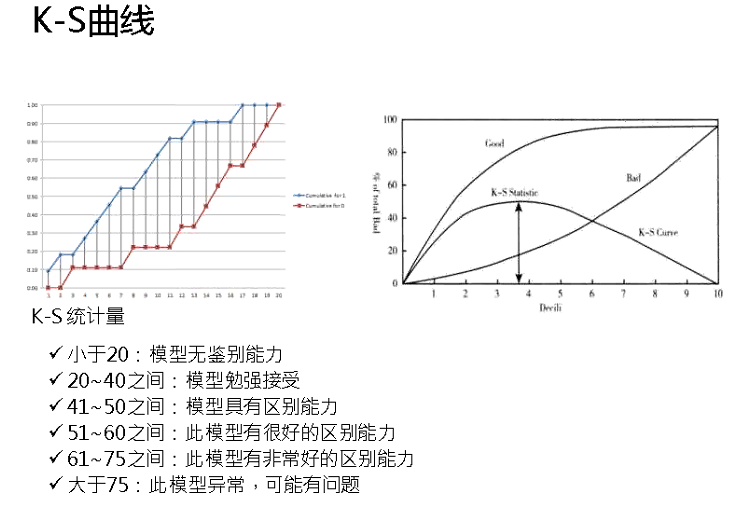
(4)洛伦兹曲线gini
风控喜欢的指标,TP率给了一个累积比,跟提升度差不多。
——————————————————————————————————————————
三、信用风险模型检测
监测可以分为前端、后端监控。
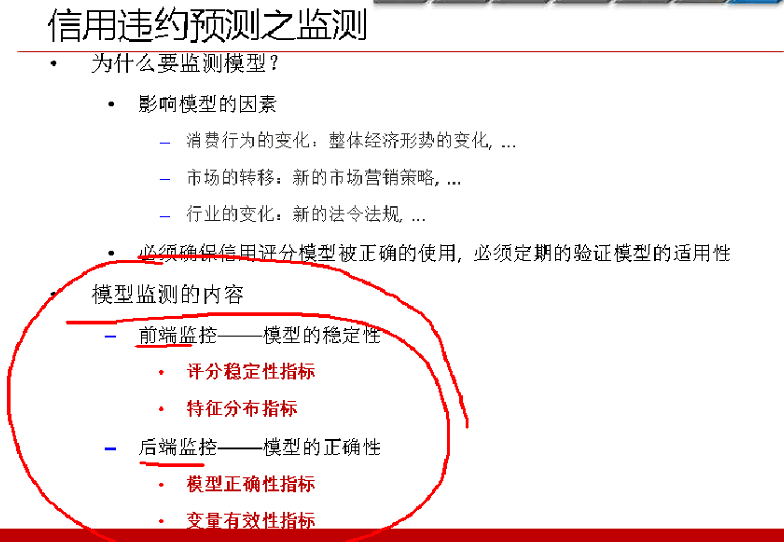
前端监控,授信之前,别的客户来了,这个模型能不能用?
后端监控,建模授信之后,打了分数,看看一年之后,分数是否发生了改变。
1、前端监控
长期使用的模型,其中的变量一定不能波动性较大。比如,收入这个指标,虽然很重要,但是波动性很大,不适合用在长期建模过程中。
如果硬要把收入放到模型之中,要放入收入的百分位制(排名)。
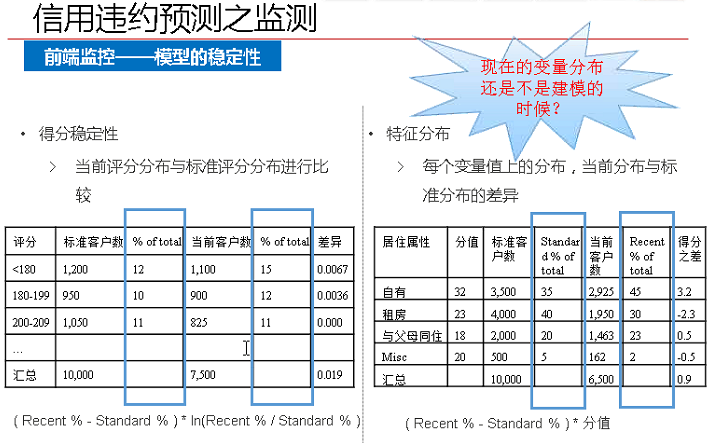
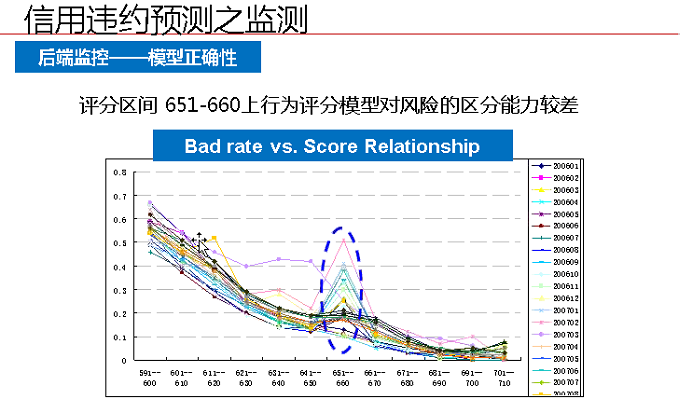
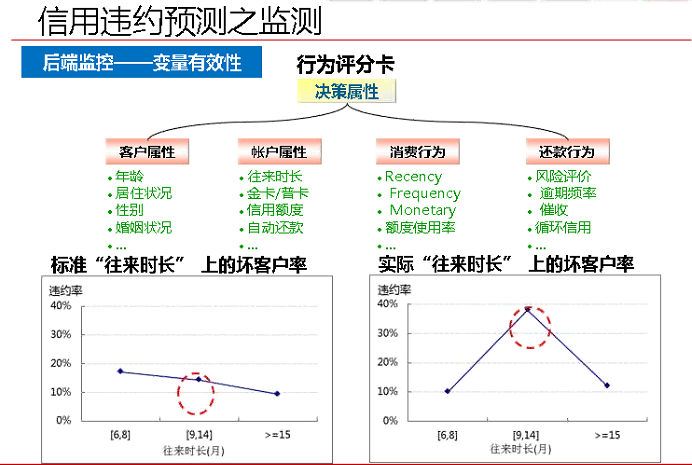
2、后端监控
主要监控模型的正确性以及变量选择的有效性。出现了不平滑的问题,需要重新考虑
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
</div>
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131174.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
