大家好,又见面了,我是你们的朋友全栈君。
DeepLab系列
文章目录
DeepLabV1
简介
DeepLab系列在2015年的ICLR上被提出,主要是使用DCNNs和概率图模型(条件随机场)来实现图像像素级的分类(语义分割任务)。DCNN应用于像素级分类任务有两大障碍:信号下采样和空间“不敏感性”(不变性)。由于DCNNs的平移不变性,DCNNs被用到很多抽象的图像任务中,如imagenet大规模分类,coco目标检测等中。第一个问题涉及在每层DCNN上执行的最大池化和下采样(‘步长’)的重复组合所引起的信号分辨率的降,此模型通过使用空洞算法(”hole” algorithm,也叫”atrous” algorithm)来改进第一个问题,通过使用全连接条件随机场来改善分割效果。
总结DeepLabV1又三个优点:
(1)速度快,带空洞卷积的DCNN可以达到8fps,而后处理的全连接CRF只需要0.5s。
(2)准确性高:在PASCAL VOC取得第一名的成绩,高于第二名7.2%个点,在PASCAL VOC-2012测试集上达到71.6%的IOU准确性。
(3)简单:有两个模块构成整体模型,分别是DCNN和CRF
atrous algorithm
模型使用的DCNN是基于VGG-16结构的,但是为了提取像素级别的特征,对VGG16进行了改进,将最后的全连接层改为卷积层,结果是输出的采样间隔变成32像素,但是对于分割任务来说还不够,文章又参考了其他人的方法,将最后两个最大池化后面的下采样去掉,并且将卷积改为空洞卷积,目的就是为了在不使用pooling操作损失信息也能增加感受野,如下图所示: 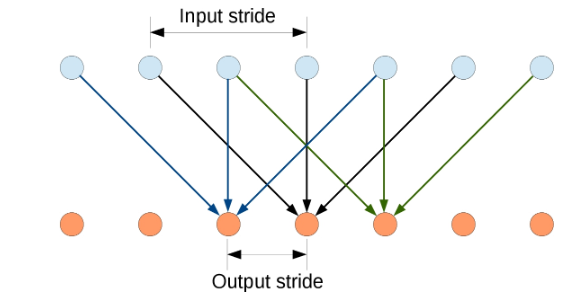

上图为1D空洞卷积,kernel_size=3,kernel size = 3, input stride = 2, output stride = 1。
关于空洞卷积的详解可以参考空洞卷积详解
二维示意图如下:
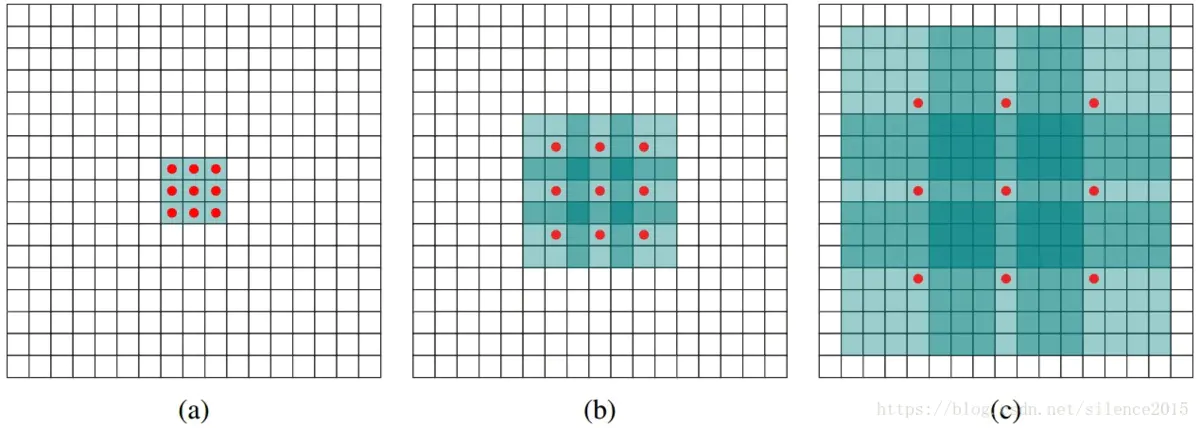
在空洞卷积参数中的rate,代表传统卷积核的相邻之间插入rate-1个空洞数。当rate=1时,相当于传统的卷积核。从卷积核角度看,相当于在标准卷积相邻点间添加rate-1个零,这样扩张后的卷积核与原图卷积,这样感受野就增大了。例如下图,rate=2时,原来的 3 ∗ 3 3*3 3∗3卷积就变成了 5 ∗ 5 5*5 5∗5,中间是添加的零。从原图角度看,相当于在原来的标准卷积上进行每隔rate-1进行卷积。
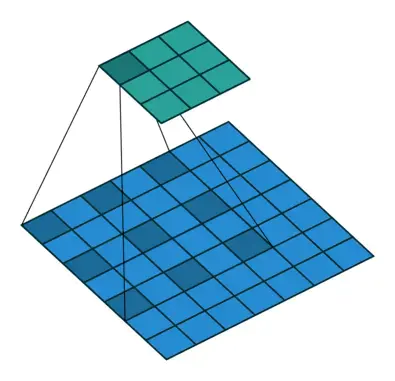
利用全卷积增加感受野并加速运算
在ImageNet上预训练的VGG16输出感受野是 224 ∗ 224 224*224 224∗224(具有零填充)和 404 ∗ 404 404*404 404∗404,在将网络转换为完全卷积的网络后,第一个完全连接的层具有4,096个 7 ∗ 7 7*7 7∗7大的空间大小的滤波器,并成为我们的密集分数图计算中的计算瓶颈。文章直接将 7 ∗ 7 7*7 7∗7下采样到 4 ∗ 4 4*4 4∗4(或者 3 ∗ 3 3*3 3∗3),这样输出就会变成 128 ∗ 128 128*128 128∗128(使用零填充)和 308 ∗ 308 308*308 308∗308,计算量会减少2-3倍。
条件随机场CRF
在卷积网络中,分类精度和定位精度之间存在自然的平衡:具有多个最大池层的更深层次模型已经证明在分类任务中最成功,但是它们增加的不变性和大的接收场使得从分数中推断出位置不容易。目前研究工作主要有两种解决方法:(1)使用CNN多层feature map融合来加强边界的估计;(2)使用超像素分割的方法。本文使用简单的将DCNN和条件随机场结合的方法,DCNN用于像素的分类与确定大概像素边界,全连接CRFs用于后处理,恢复精确的物体像素边界。以下图为例,第一列是原图和ground truth图,第二列第一行是DCNN输入Softmax前的特征图,第二行是输出Softmax后的特征图,第三列、第四列和第五列分别是DCNN的Score map和Belief map经过1、2、10次CRF迭代后的结果。很明显可以看到,经过CRF处理后的分割效果更好。如下图所示,DCNN输出的score map通常非常平滑并产生均匀的分类结果。在这种情况下,使用short-range CRF是不好的,因为我们的目标应该是恢复详细的局部结构而不是进一步平滑它,该算法的主要用于平滑处理,使用lacal-range CRF和 contrast-sensitive potentials虽然能够潜在改善定位问题,但是对应的thin-structures依旧是个问题,同时离散优化代价也是很大。

为了克服short-range CRF的缺点,文章使用全连接CRF整合到模型中。如下图所示,原图在经过DCNN之后输出score-map,经过双线性插值上采样16倍后到原图大小,然后经过全连接CRF,最终得到final-output。
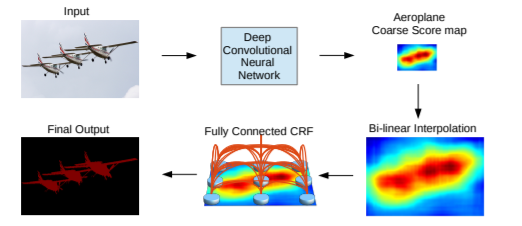
条件随机场可以优化物体的边界,平滑带噪声的分割结果,去掉物体中间的预测的孔洞,使得分割结果更加准确。公式如下图,x是像素点的标签,P(xi)是像素i处的标签分配概率, θ i \theta _{i} θi是对数概率, θ i j \theta _{ij} θij是一个滤波器,在括号中,它是两个内核的加权和。第一个核取决于像素值差和像素位置差,这是一种双边的filter。双边滤波器具有保留边缘的特性。可以促使具有相似颜色和位置的像素具有相同的label预测。第二个内核仅取决于像素位置差异,这是一个高斯滤波器,可以促进更加平滑的预测。那些σ(高斯核大小)和w(权重),通过交叉验证找到。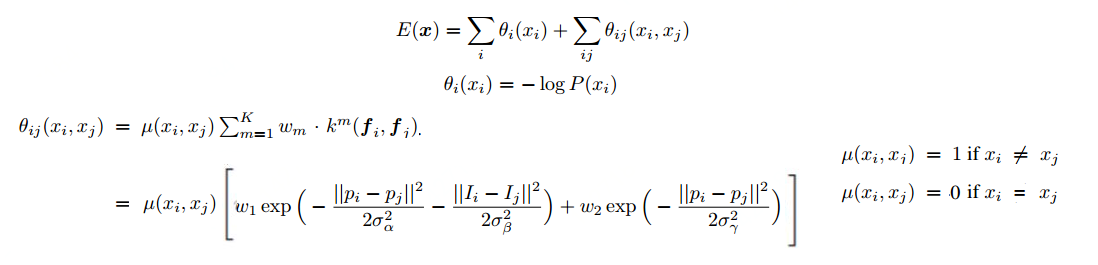
实验结果
多尺度预测
多尺度预测能够提升精度,但是加上CRF后提升的更多。
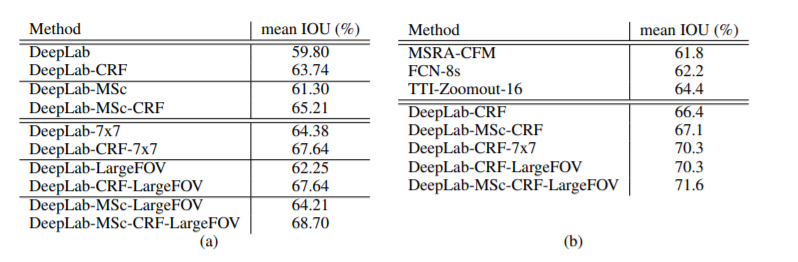
VOC数据集上对比
在当时DeepLab模型的提升可以说很大。

DeepLabV2
主要改进
(1)使用ResNet代替VGG16作为backbone,在特征提取基础模型上做改进,能够提升准确性。
(2)提出atrous spatial pyramid pooling (ASPP)来替代多尺度预测,可以大大增加感受野
简介
DeepLab系列面临的三大挑战:(1)降低的特征分辨率,(2)多尺度的对象的存在,以及(3)由于DCNN不变性而降低的定位精度。
第一个挑战是由最初为图像分类设计的连续DCNN层执行的最大池和下采样(‘步长’)的重复组合引起的,多层的最大池化和全连接层会导致空间信息的丢失,本文选择去掉大部分的最大池化并且使用空洞卷积来增加输出分辨率,保留更多的空间信息。
第二个挑战是由多个尺度的物体的存在引起的。解决这个问题的一种标准方法是向DCNN呈现相同图像的resize版本,然后聚合特征或score map。我们证明这种方法确实增加了我们系统的性能,但是以输入图像的多个resize版本的所有DCNN层计算特征响应为代价。参考spatial pyramid pooling,文章提出了atrous spatial pyramid pooling” (ASPP),将特征图通过并联的空洞卷积层,这些空洞卷积层使用不同的膨胀率,然后将输出结果融合来预测分割结果。
第三个挑战和DeepLabV1l类似,是因为DCNN的平移不变性,也是使用CRF来进行精细化处理。
模型主体
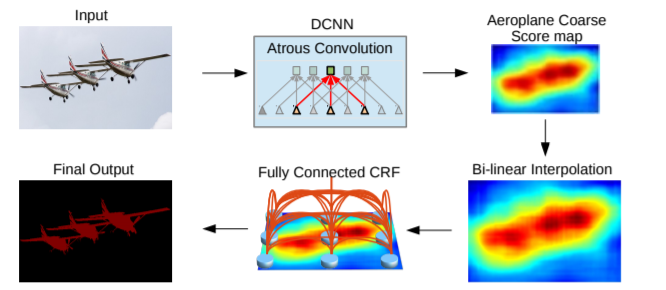
模型主体和DeepLabV1类似,不同点有两点不同,DeepLabV2的backbone变成了resnet,DeepLabv1输出步幅是16,需要双线性插值上采样16倍得到预测结果,DeepLabv2输出步幅是8,只需要上采样8倍,结果好了很多。
ASPP
为处理像素分割的多尺度物体信息,也就是刚才的挑战二,作者尝试了两种方案:
(1)方案1:使用共享相同参数的并行DCNN分支从多个resize的原始图像中提取DCNN score map。为了产生最终结果,我们将并行DCNN分支中的特征映射双线性插值到原始图像分辨率并融合它们,通过在每个位置获取不同尺度上的最大响应。多尺度处理显着提高了性能,但代价是计算所有DCNN层的特征响应,以满足多种输入规模;
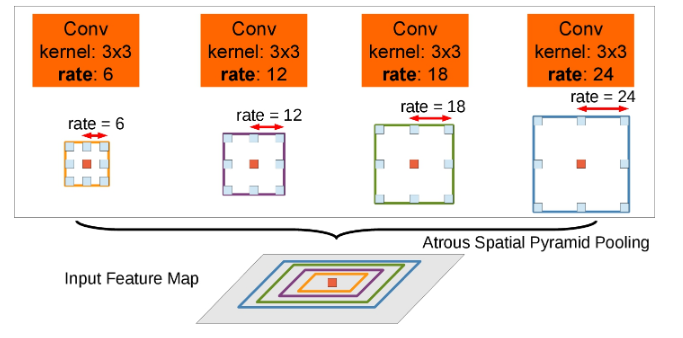
(2)方案2:这是本文最大的亮点,较DeepLabv1的最大的改变就是提出了ASPP,如下图所示是ASPP在feature map上的应用示意图。
图中为四路不同rate值的ASPP示意图,kernel_size=3,膨胀率分别为6、12、18、24,将feature map通过四路ASPP后,得到的结果在原feature map中的field-of-view用不同的颜色矩形框出来了,为了对中心像素(橙色)进行分类,ASPP通过采用具有不同速率的多个并行滤波器来利用多尺度特征。分割效果就会提高很多。
实验结果
作者在训练过程中使用了一些trick:一是对数据进行扩充和数据增强;二是超参数选取都参照DeepLabV1的超参数,控制膨胀率来调整FOV;三是LargeFOV是指采用膨胀速率r=12的膨胀卷积策略,在VGG-16的fc6采用该膨胀卷积,并将fc7和fc8改为1×1的全卷积,命名为DeepLab-LargeFOV。
下面是与主流模型对比:
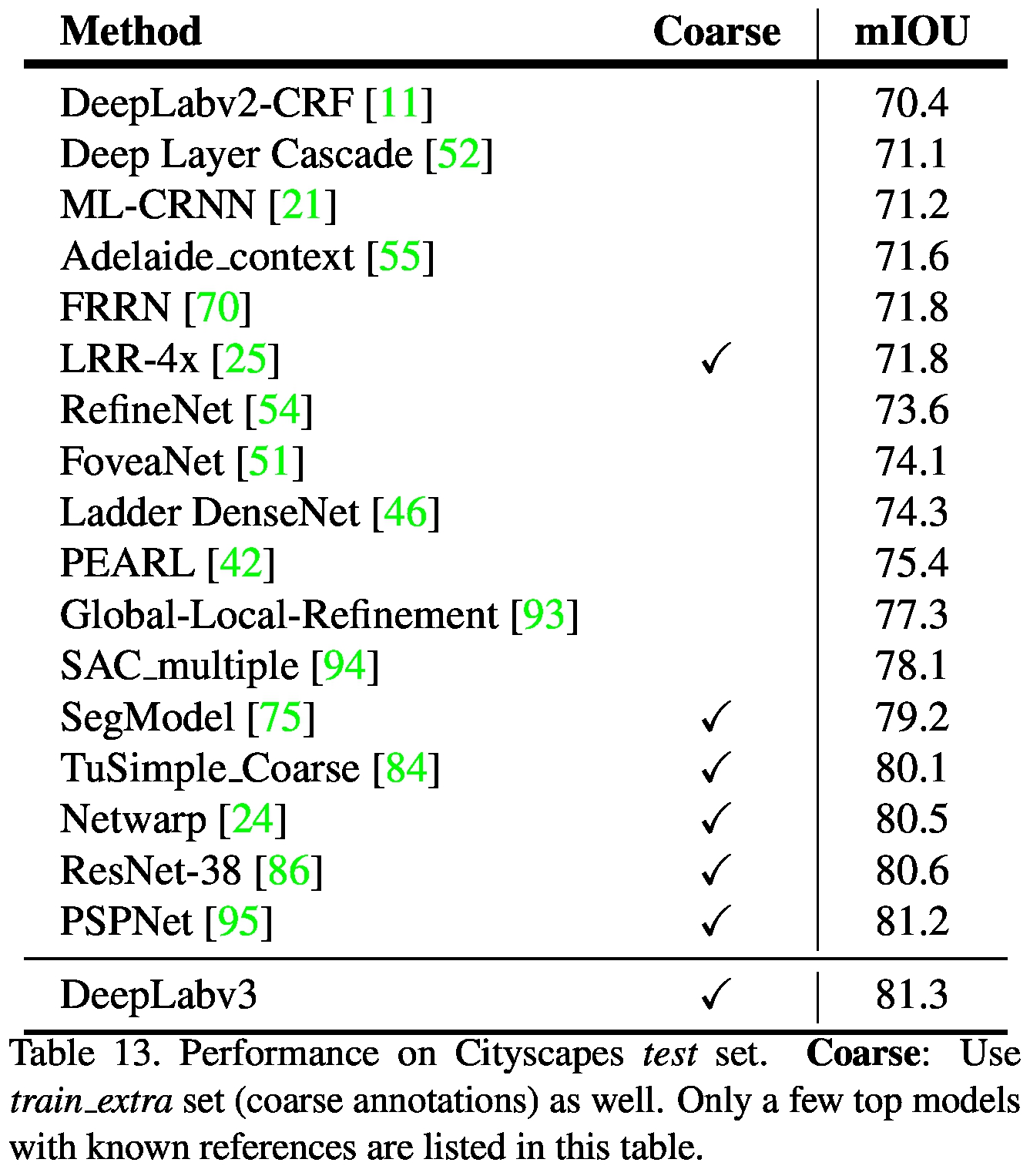
PASCAL VOC 2012 Test
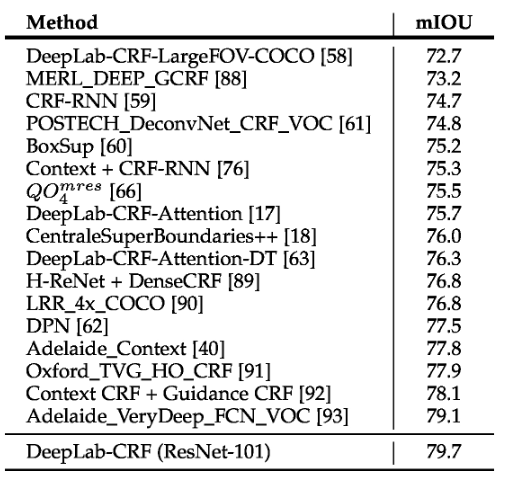
Cityscapes
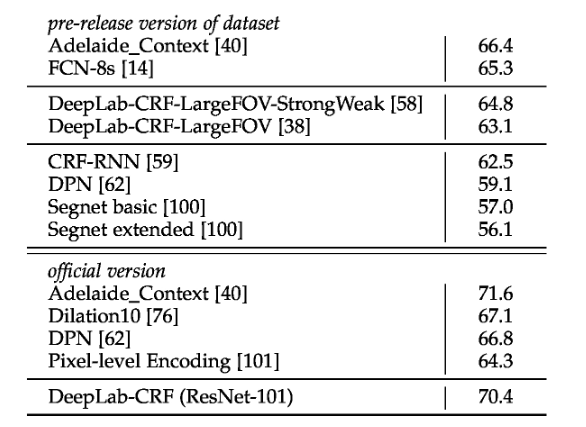
DeepLabV3
相应的改进
(1)网络变得更深,对原来的resnet进行改进,又堆叠了三个block4在block4后面,分别为block5,6,7,同时调整采样率,原始的有五次下采样,修改后只进行四次下采样,block4后就不会进行下采样了。
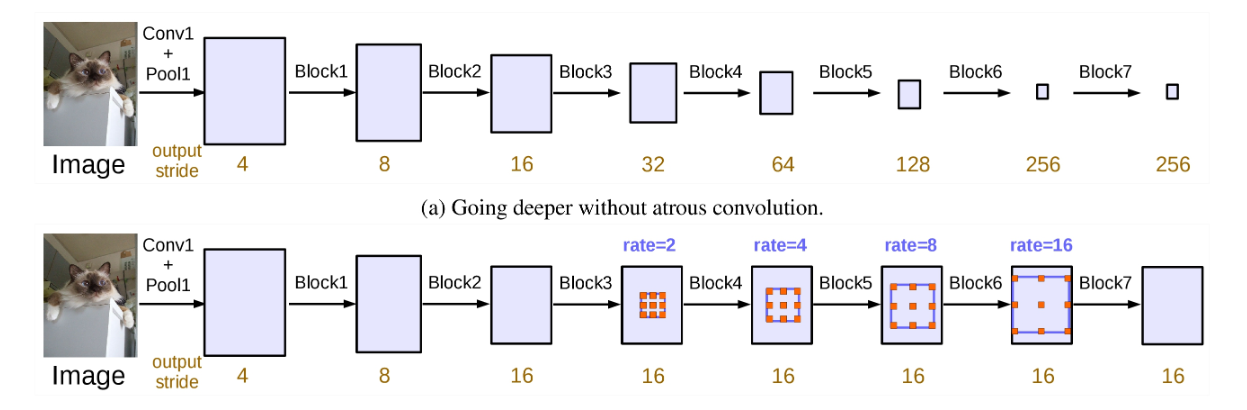
(2)Multi-grid Method: 我们在block4-block7中使用不同的rate,最后的rate等于单位rate和corresponding rate 的乘积:举例来说:Multi-grid=[1,2,4], output_stride=16, 则最后的rate=2 * [1,2,4] = [2,4,8]。
(3)ASPP的改进,如下图所示,在最后多了个 1 ∗ 1 1*1 1∗1卷积和全局平均池化,当rate=feature map size时,dilation conv就变成了11 conv,所以这个11conv相当于rate很大的空洞卷积。作者设计了如下图的ASPP结构
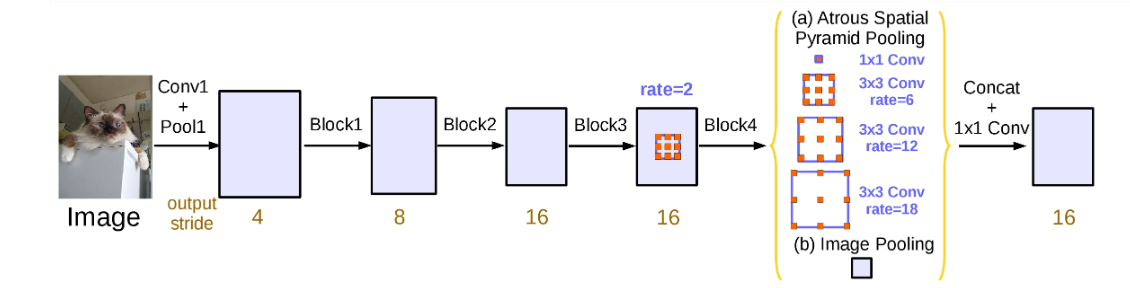
二和三两种方法的结构合并并不会带来提升,相比较来说,ASPP的纵式结构要好一点。所以deeplab v3一般也是指aspp的结构,也就是三这种结构。
实验
output stride与最终结果的关系如下图, output_stride 越大,结果越差,这证明了保留空间尺寸的必要性。

网络深度和Multi-grid与结果的关系如下图,可以看到随着网络的加深,结果越来越好,但是提升也越来越有限;使用multi-grid效果均好于(1,1,1),简单的doubling unit rates 不是很有效,更深的网络和multi-grid会提升效果。
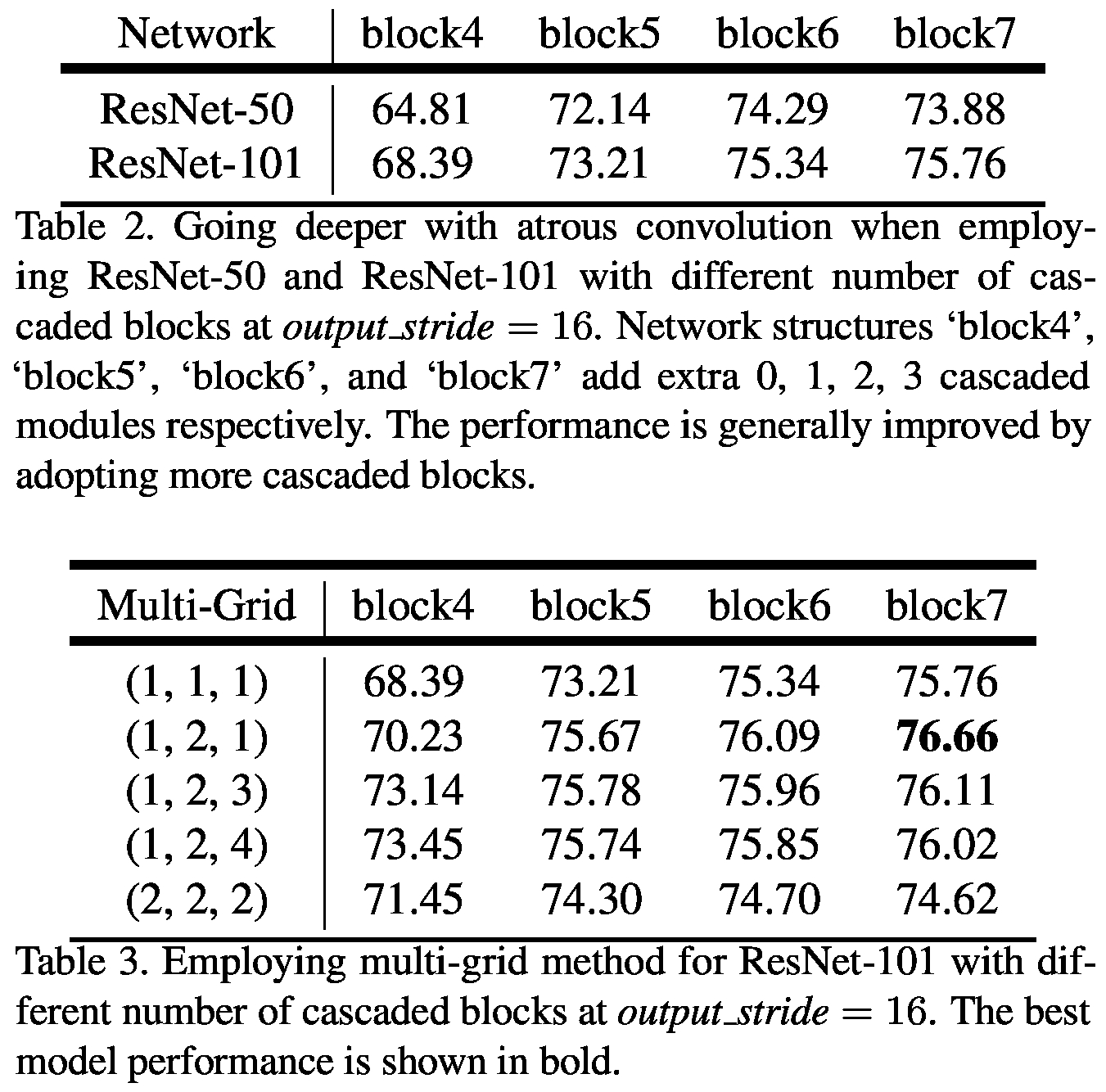
我们可以看到在不同的ASPP设置下的效果,同时multi-grid和image pooling的效果也可以看到,可以得出过大的增加dilation也是不好的。

最后与不同模型之间对比如下图
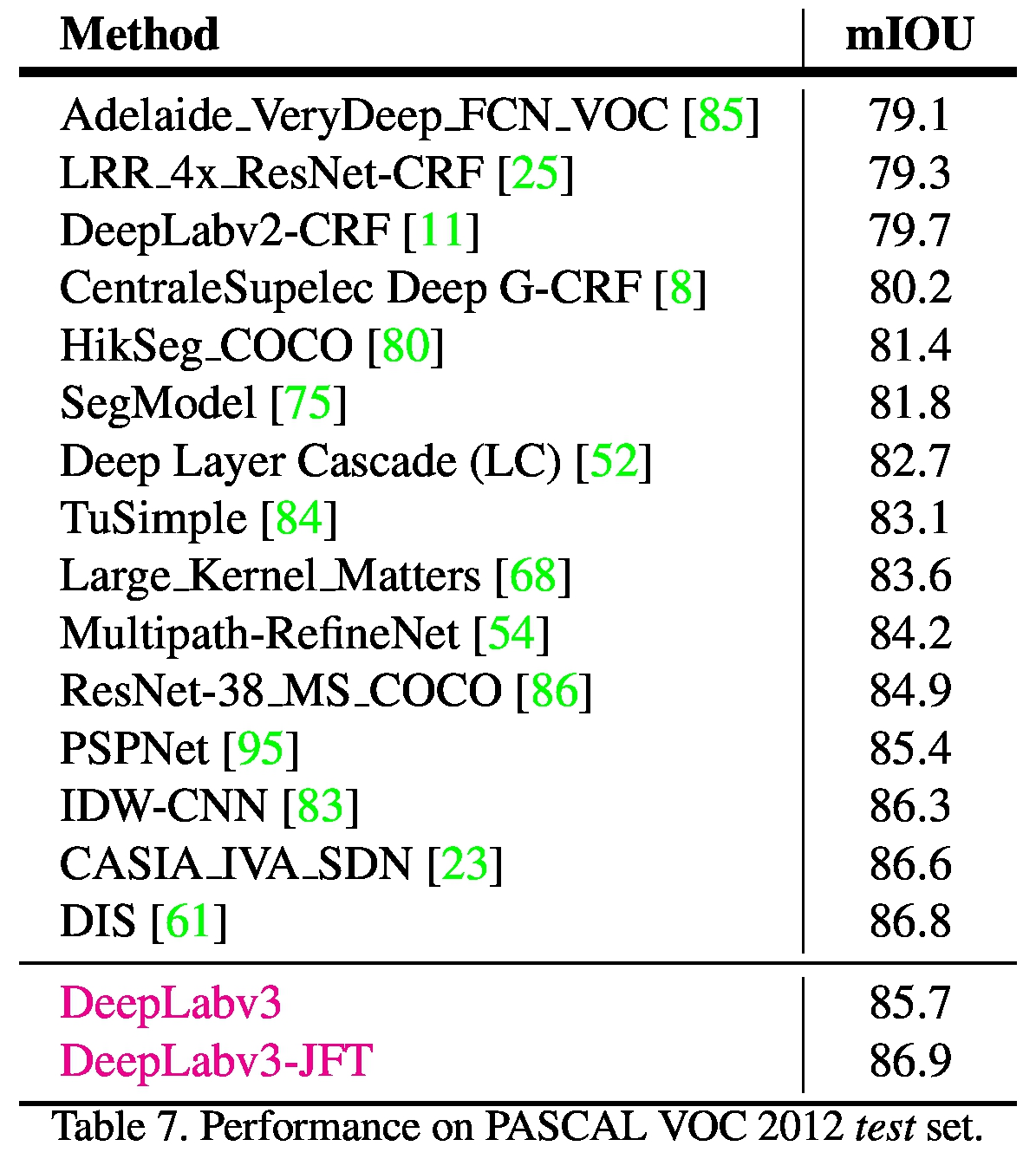
DeepLabV3在ASPP中引入了BN,对模型的效果有提升,在模型最后使用image pooling来补充dilation丢失的信息也对模型的表现有很大帮助。
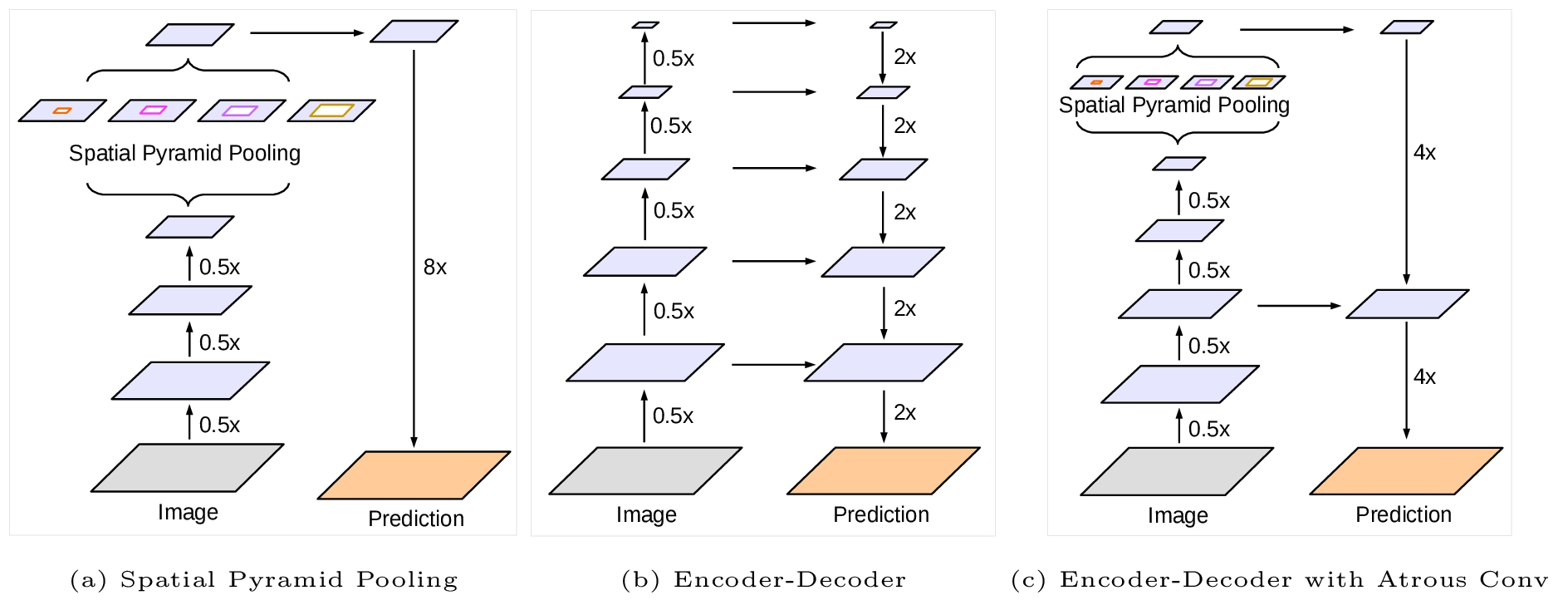
DeepLabV3+(DeepLabV3 plus)
相应改进
(1)在DilatedFCN基础上引入了EcoderDecoder,网络结构增加了decoder模块,整体结构变成Encoder-Decoder模块。
(2)DeepLabv3所采用的backbone是ResNet网络,在v3+模型尝试了改进的Xception,Xception网络主要采用depthwise separable convolution。
整体结构
DeepLabV3+的整体架构如下图所示,它的encoder模块主要包含带有空洞卷积的DCNN模块和带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP),前者可以使用分类网络例如ResNet和Xception作为backbone,后者主要是引入了多尺度信息,V3+创新性的引入了Decoder模块,将高维特征和低维特征进行融合,提升分割精度。
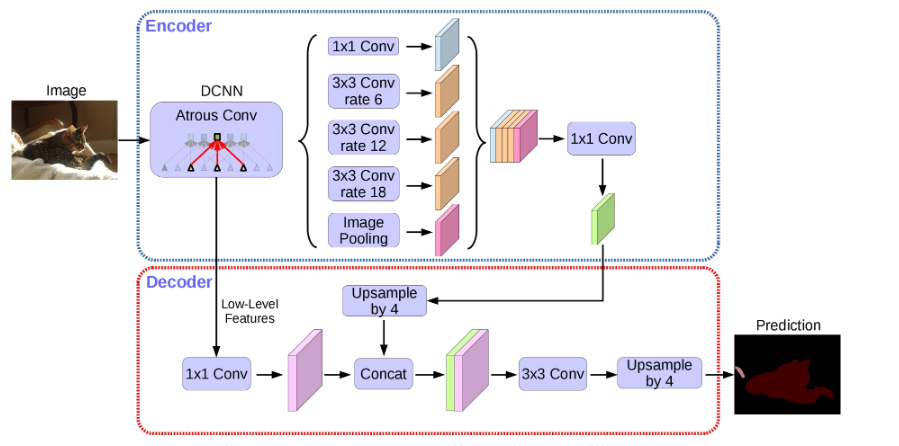
解码器结构
图中a)是v3的纵式结构,(b)是常见的编码—解码结构,(c)是本文提出的基于deeplab v3的encode-decode结构。如下图所示。首先将encoder得到的特征双线性插值得到4x的特征,然后与encoder中对应大小的低级特征concat,如ResNet中的第一层特征,由于encoder得到的特征数只有256,而低级特征维度可能会很高,为了防止encoder得到的高级特征被弱化,先采用1×1卷积对低级特征进行降维。两个特征concat后,再采用3×3卷积进一步融合特征,最后再双线性插值得到与原始图片相同大小的分割预测。
modified Xception
由于V3+主要使用的是Xcetion为backbone,所以重点探讨Xception的改进,如下图所示,分为三个部分:entry flow、middle flow、exit flow,与传统的Xception不同的有:
(1)更多的层数:middle flow 重复了16次,original Xception是8次。
(2)所有max pooling操作都由stride=2的深度可分离卷积替换。
(3)在每次3×3深度卷积之后添加额外BN和ReLU,类似于MobileNet。这个重新加上ReLU真是玄学。
具体的实现可以参考源码Xception的实现。

实验
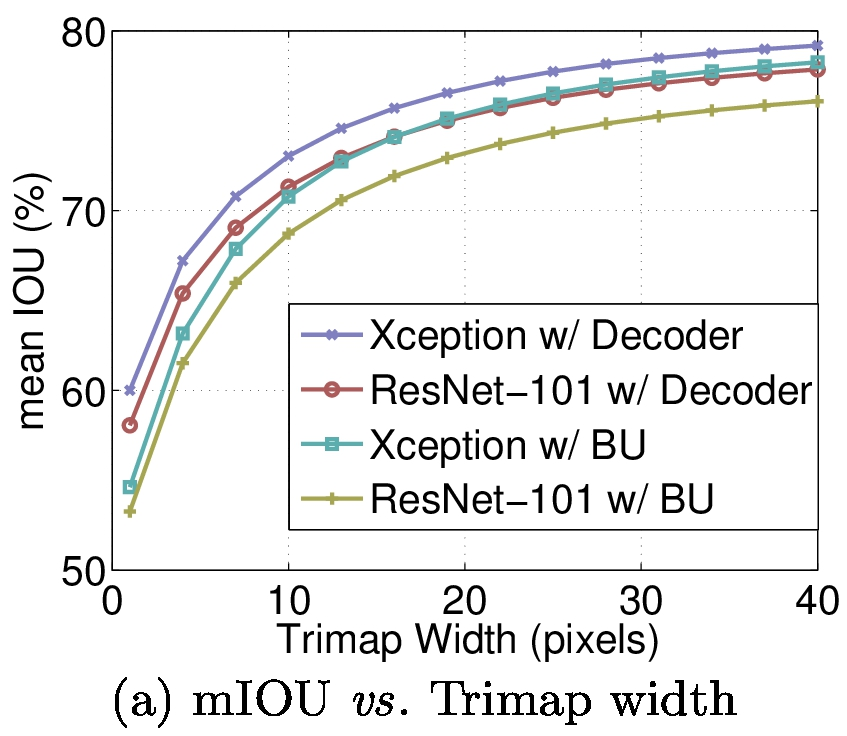
在PASCAL VOC 2012 Test的实验结果,第一张图是不同模型的对比,第二张是不同backbone对比,可以看到以modified Xception为backbone的模型表现是最好的,在我做的实验中也是这样,同样条件下,resnet101_backbone在780个epoch达到0.9的MIou,Xception65在256个epoch就达到了,并且最终效果也比resnet好。现在最新的resnest在我的实验中效果比Xception更好,这也和resnest的文章中所说的相符,我尝试了四种backbone,效果分别是resnest>Xception>resnext>resnet,大家可以试一下。deeplab的分割效果还是很好的。

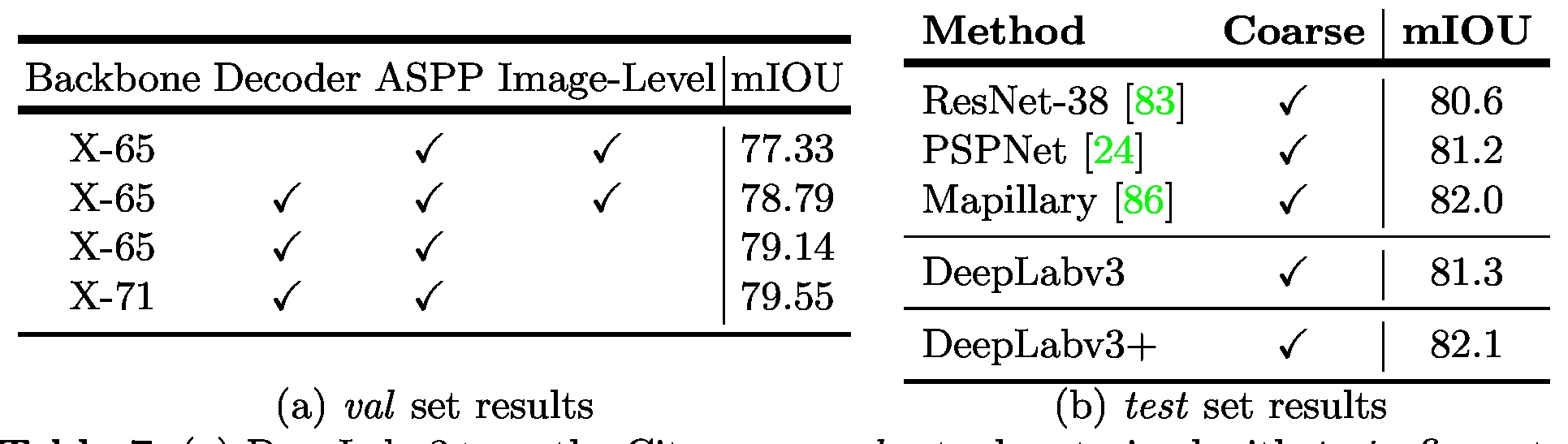
在 Cityscapes 上的结果对比如下图:
参考
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128458.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
