大家好,又见面了,我是你们的朋友全栈君。
一、算法名称
Pix2pix算法(Image-to-Image Translation,图像翻译)
来源于论文:Image-to-Image Translation with Conditional Adversarial Networks
二、算法简要介绍、研究背景与意义
2.1介绍
图像处理、图形学和视觉中的许多问题都涉及到将输入图像转换为相应的输出图像。这些问题通常使用特定于应用程序的算法来处理,尽管设置总是相同的:将像素映射到像素。条件对抗性网(cGAN)是一种通用的解决方案,它似乎能很好地解决各种各样的此类问题。本文介绍基于cGAN的pix2pix模型算法,针对不同的图片生成任务进行测试。
图像处理、计算机图形学和计算机视觉中的许多问题都可以归结为将输入图像“翻译”成相应的输出图像。正如一个概念可以用英语或法语表达一样,一个场景可以被渲染成RGB图像、梯度场、边缘图、语义标记图等。类比自动语言翻译,同样可以定义image-to-image翻译作为翻译的一个可能表示的任务场景到另一个,得到足够的训练数据。
卷积神经网络(CNNs)已经成为各种图像预测问题背后的常用工具,cnn学会了将损失函数最小化,这是一个衡量结果质量的目标,尽管学习过程是自动的,但设计有效损失仍然需要大量的手工努力。换句话说,我们仍然需要告诉CNN我们希望它最小化什么。如果要求CNN最小化预测像素和真实像素之间的欧几里德距离,就会产生模糊的结果。这是因为欧氏距离是通过平均所有可能的输出而最小化的,这会导致模糊。提出损失函数来迫使CNN做我们真正想做的事情。
如果我们只指定一个高级目标,比如“使输出与现实难以区分”,然后自动学习一个适合于满足这个目标的损失函数,那将是非常可取的。这正是最近提出的生成式对抗网络(GANs)所做的。GANs学习了一种损失,它试图对输出图像的真伪进行分类,同时训练生成模型来最小化这种损失。模糊的图像是不能容忍的,因为它们看起来很明显是假的。由于GANs学会了适应数据的损失,他们可以应用于许多任务,而这些任务在传统上需要非常不同的损失函数。条件GANs (cGANs)学习的是条件生成模型。这使得cGANs适合于图像到图像的转换任务,其中对输入图像设定条件并生成相应的输出图像。本报告主要介绍一种条件生成对抗网络延申模型pix2pix,并解释相关原理与计算公式,测试数据并展示。
2.2研究背景与意义
图像到图像的转换问题通常用像素分类或回归来表述,这些公式将输出空间视为“非结构化”,即每个输出像素被认为是有条件地独立于给定输入图像的所有其他像素。相反,有条件GANs学会了结构性损失。结构化损失会影响输出的联合配置。已经存在大量文献考虑了这类损失,方法包括条件随机场、SSIM度量、特征匹配、非参数损失、卷积伪先验、基于匹配协方差统计的损失。有条件GAN的不同之处在于损失是可习得的,并且在理论上可以惩罚输出和目标之间任何可能的不同结构。以前和现在的作品都将GANs限制在离散标签,文本,以及图像上。图像条件模型处理了法线映射的图像预测,未来帧预测,产品照片生成,以及稀疏标注的图像生成。同样也有几篇论文使用了GANs来进行图像到图像的映射,但只是应用了普通的GAN技术,依赖于其他法则(如L2回归)来强制输出以输入为条件。每一种方法都是为特定的应用量身定做的。Pix2pix框架的不同之处在于,没有什么是特定于应用程序的。这使得设置比大多数其他设置简单得多。在生成器和鉴别器的几种架构选择上,本次实验的方法也与之前的工作有所不同。pix2pix模型生成器使用基于“U-Net”的架构,而鉴别器使用卷积的“PatchGAN”分类器,它只在图像patch的尺度上对结构进行惩罚。之前提出了一个类似的PatchGAN建筑来获取当地的风格统计。在本次实验结果中展示了这种方法在更广泛的问题上是有效的。
三、问题描述


图1
如图1所示,训练一个cGAN将轮廓图映射为照片。鉴别器D学习对假图片(由生成器合成)和真实图片组进行分类。生成器G,学会欺骗鉴别器。与普通GAN不同,生成器和鉴别器都观察输入的轮廓图与生成图片或真实图片,普通GAN直接输入生成图片或真实图片。
四、算法设计与步骤
4.1目标函数
条件GAN的目标函数,一般的cGAN的目标函数如下,生成器 G 不断的尝试minimize下面的目标函数,而D则通过不断的迭代去maximize这个目标函数,即G∗= arg minG maxD LcGAN (G, D):

同时也比较一个无条件变量,其中判别器不观察x:

将GAN目标与更传统的损失混合是有益的。鉴别器的工作保持不变,但生成器的任务不仅欺骗鉴别器,而且在L2意义上接近地面真值输出。我在本测试实验中选择使用L1距离而不是L2,因为L1可以减少模糊:

最终目标函数为:

没有z,网络仍然可以学习从x到y的映射,但会产生确定性的输出,因此无法匹配除脉冲函数以外的任何分布。输入图像用y表示,输入图像的边缘图像用x表示,pix2pix在训练时需要成对的图像(x和y)。x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起作为G的输入,可以得到更多样的输出)得到生成图像G(x),然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。另外真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。因此判别器D的训练目标就是在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),在输入是一对真实图像(x和y)时输出大的概率值(比如最大是1)。生成器G的训练目标就是使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。
4.2网络结构

图2
如图2所示,生成器可选择两种经典架构,在本次实验中我所选择的是U-Net结构,生成器和鉴别器都使用卷积形式的模块。
4.2.1生成器
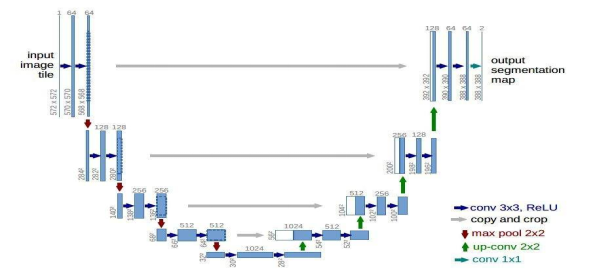
图3
生成器网络结构图如图3所示,U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显。图像到图像转换问题的一个定义特征是它们将高分辨率输入网格映射到高分辨率输出网格。另外,对于本次实验考虑的问题,输入和输出在表面外观上是不同的,但都是相同的底层结构的渲染。因此,输入中的结构大致与输出中的结构对齐。围绕这些考虑因素来设计生成器架构。在U-Net网络中,输入经过一系列层,逐步向下采样,直到瓶颈层,在此过程反转。这样的网络要求所有的信息流通过所有的层,包括瓶颈。对于许多图像翻译问题,输入和输出之间有大量的低级信息共享,因此直接通过网络传输这些信息是可取的。
4.2.2判别器
利用马尔科夫性的判别器(PatchGAN),pix2pix采用的策略是,用重建来解决低频成分,用GAN来解决高频成分。一方面,使用传统的L1 loss来让生成的图片跟训练的图片尽量相似,用GAN来构建高频部分的细节。

另一方面,使用PatchGAN来判别是否是生成的图片。PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。具体实现的时候,本次实验使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。
五、实验设计与实验结果
1.实验环境
XiaoXin-15IIL 2020
处理器:Intel® Core™ i5-1035G1 CPU @ 1.00GHz 1.19 GHz
机带RAM:16.0 GB (15.8 GB可用)
系统类型:64位操作系统基于x64的处理器
显卡:MX 350
训练:对于建筑物生成任务训练了20个批次,用时10分钟,对于食物上色任务训练了10个批次,用时10分钟。
2.数据集
2.1建筑物生成数据集
采用公共数据集Facades

图4
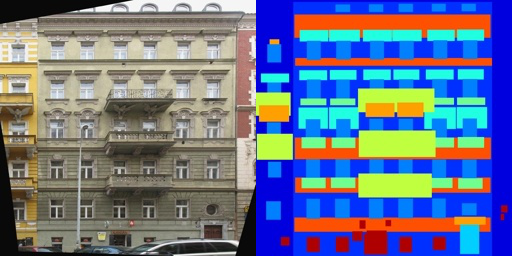
图5
如图4所示,训练数据集中共包含400组类似图片组,左边的图片作为真实图片带入判别器训练,右边图片作为带标签的条件图片,即图片轮廓图,分别带入生成器和判别器进行带标签的训练,测试数据集如图5所示,将右侧图片带入训练完毕后的生成器,生成相应的图片,与左侧的真实图片进行比较,最后输出为一个html文件将测试轮廓图、生成图片和真实图片进行整合查看测试结果。
2.2食物上色数据集

图6

图7
如图6所示,训练数据集中共包含7472张彩色实物图,右边为实物图,我将右边的彩色图RGB三通道数据全部转为灰度图数据,左边的图片为灰度图数据,将灰度图作为带标签的条件图片,即图片轮廓图,分别带入生成器和判别器进行带标签的训练,右边图片作为真实图片带入判别器训练,测试数据集如图5所示,将左侧图片带入训练完毕后的生成器,生成相应的图片,与右侧的真实图片进行比较,最后输出为一个html文件将测试轮廓图、生成图片和真实图片进行整合查看测试结果。
3.评价指标
观察生成图片与原图对比,对于建筑物生成实验,若能够生成完整建筑图并且能够与原图相近,则视为结果效果比较好。对于食物上色实验,若能够生成完整的上色食物图,且能够接近与原图颜色则视为效果比较好。
4.实验结果分析(实验结果可查看附件测试图片文件夹或html文件)
4.1建筑物生成

图8
如图8所示,左边一竖图片为标签图,右边一竖图片为原图,中间为测试结果,根据测试结果可知,已能够初步还原建筑图,随着训练批次的增加,效果可能更加明显。(建筑物生成图测试结果可在文件夹facades_test中查看,所有测试数据量过大,附件中只给出了十组对比图)
4.2食物上色

图9
如图9所示,左边一竖图片为标签图,右边一竖图片为原图,中间为测试结果,根据测试结果可知,已能够初步还原食物原图,随着训练批次的增加,效果可能更加明显。(食物上色图测试结果可在文件夹colorlization_food_test中查看,所有测试数据量过大,附件中只给出了十组对比图)
六、算法优化(可选)
pix2pix能够解决一类“图像翻译”问题。但是pix2pix模型要求训练样本必须是“严格成对”的,这种样本往往比较难以获得。如果采用改进算法cycleGAN则不必使用成对样本也可以进行“图像翻译”。
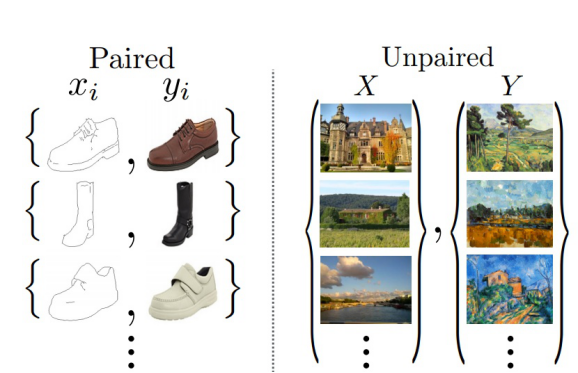
图10
如图10所示,有一些你想转换风格的真实图片,这两种图片是没有任何交集的。在之前提到的Pix2Pix方法的关键是提供了在这两个域中有相同数据的训练样本。CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移。主要是运用了两个判别器,改写相关loss函数如下:



相关算法设计不再做解释,本次实验主要针对pix2pix算法做研究与实验,cycleGAN可作为下一阶段的研究目标。
八、总结与展望
pix2pix巧妙的利用了GAN的框架来为“Image-to-Image translation”的一类问题提供了通用框架。利用U-Net提升细节,并且利用PatchGAN来处理图像的高频部分。但同时训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的照片。本次实验中采用了大量标签数据,这在现实生活中应用效果不一定好,采用cycleGAN的话可以有效解决数据标签的问题,实现由一个类别转换为另一个类别的图片翻译,接下来的任务是对cycleGAN进行研究,总结相关算法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128386.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
