大家好,又见面了,我是你们的朋友全栈君。


Deepfakes 简介
Deepfakes 是人工智能生成的任何人或名人的合成视频,它冒充真实的人,并让他们采取行动或说出他们从未做过的任何事情。
Deepfake 的创建过程在技术上很复杂,通常需要大量数据,然后将这些数据输入神经网络以训练和生成合成视频。
Deepfakes 的影响
Deepfakes 和 AI 虚拟形象可能会产生不同的影响,具体取决于其使用方式。虽然 deepfake 的负面影响可能令人恐惧,但它在其他情况下会很有用。
Deepfakes 的优点
-
Deepfakes 可以作为一种艺术形式,让过去的人们重获新生。例如,一幅蒙娜丽莎的画可以用来生成一个会说话的蒙娜丽莎的合成图像。
-
Deepfake 技术可用于在训练视频中创建 AI 头像。在疫情期间,总部位于伦敦的 Synthesia 等初创公司越来越受到企业界的关注,因为封锁和健康问题使涉及真人的视频拍摄变得更加困难。
-
Deepfakes 可用于创建个人头像,可以用于试穿衣服或新发型。
Deepfakes 还可用于调查新闻报道、金融等各个领域的身份保护和匿名化。
Deepfakes 的缺点
-
Deepfakes 可用于通过名人的换脸视频传播假新闻。
-
Deepfakes 也可能被误用于在社交媒体上发起错误信息宣传活动,从而改变公众舆论并导致负面后果。
创建 Deepfakes
尽管可以通过多种方式使用或误用Deepfakes,但随着 AI 日新月异的进步,创建它们变得越来越容易。
我们现在可以用一个人的小视频源创建一个Deepfakes。是的,随着神经网络的最新进展,这现在很容易实现。
让我们将解决方案分解为两部分
-
声音克隆
-
视频口型同步
Deepfakes 的语音克隆部分
SV2TTS 是一个深度学习框架,可以通过训练将音频量化并以数字和参数的形式表现出来,这些数字和参数的基础是一个人的声音的一小段音频。
语音样本的这种数字描述可用于指导和训练一个从文本到语音的模型,以使用任何文本数据作为输入,生成具有相同语音的新音频。因此,使用从样本源视频中提取的音频,可以使用 SV2TTS 轻松创建语音克隆。

图:SV2TTS 工作流程
SV2TTS 工作流程
-
扬声器编码器接收从源视频中提取的目标人物的音频,并将带有嵌入的编码输出传递给合成器。
-
合成器根据目标音频和成对的文本记录进行训练,并合成输入
-
神经声码器将合成器产生的频谱图转换为输出波形
Deepfakes 的视频口形同步部分
Wav2lip 是一种口型同步 GAN,它以人说话的音频样本和等长视频样本作为输入,并将人的口型与输入音频同步。因此,它会生成同一个人说出输入音频的合成视频,而不是原始样本视频中的实际音频。
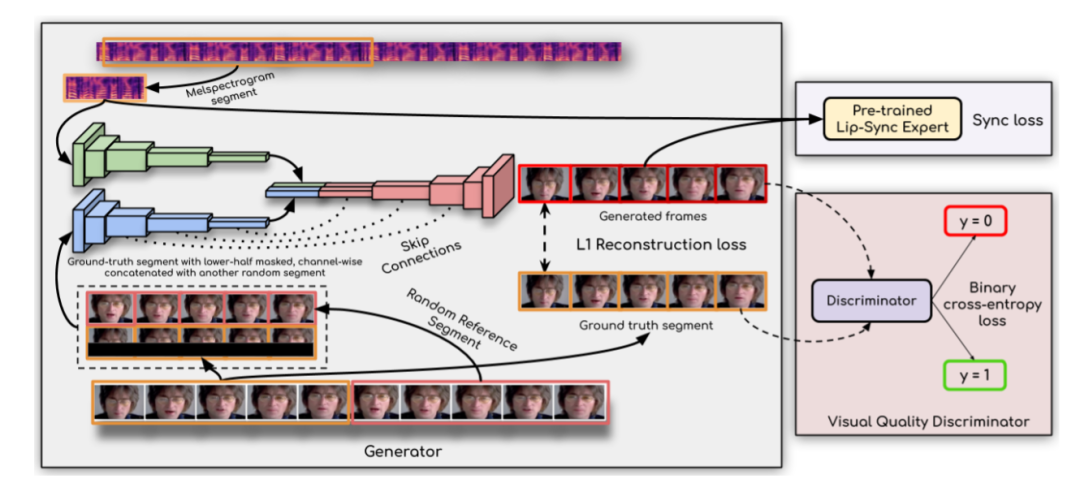
图:Wav2Lip 工作流程
视频口型同步工作流程
-
生成器使用身份编码器、语音编码器和面部解码器来生成视频帧
-
判别器在训练过程中因生成不准确而惩罚生成器
-
生成器-鉴别器的对抗训练导致最终输出视频具有尽可能高的准确度
示例合成视频
这是我制作的奥巴马与我们交谈的合成视频!用于创建语音克隆音频的文字记录显示:“Hey guys, this is Barack Obama. As you can see, this is not a real video. My creator, Suvojit, generated this synthetic video with Generative Adversarial Networks….”
-
https://youtu.be/5BpxgU-0vbc
深入了解 SV2TTS 的步骤和代码
让我们深入了解 SV2TTS 和 Wav2Lip 的步骤和代码。
源视频
选择源视频——视频可以是任意长度,并且应该只有目标角色在前面发言,并尽可能少的中断。
请注意,生成的最终合成视频将与输入视频的大小相同,因此你可以根据需要裁剪视频。
音频提取
从源视频中提取音频。该音频将作为 SV2TTS 生成语音克隆的训练数据。
导入库
对于 SV2TTS,在Notebook中导入必要的库。
# importing all the necessary librariesimport os
from os.path import exists, join, basename, splitext
import sys
from IPython.display import display, Audio, clear_output
from IPython.utils import io
import ipywidgets as widgets
import numpy as np
from dl_colab_notebooks.audio import record_audio, upload_audio
from synthesizer.inference import Synthesizer
from encoder import inference as encoder
from vocoder import inference as vocoder
from pathlib import Path克隆 SV2TTS 存储库
克隆基于SV2TTS的实时语音克隆repo并安装requirements。
sys.path.append(name_of_proj)#url of svt2tts
git_repo_url = 'https://github.com/CorentinJ/Real-Time-Voice-Cloning.git'
name_of_proj = splitext(basename(git_repo_url))[0]# clone repo recursively and install dependenciesif not exists(name_of_proj):
# clone and install
!git clone -q --recursive {git_repo_url}
# install dependencies
!cd {name_of_proj}!pip install -q -r requirements.txt
!pip install -q gdown
!apt-get install -qq libportaudio2
!pip install -q https://github.com/tugstugi/dl-colab-notebooks/archive/colab_utils.zip加载预训练模型
下载并加载预训练的模型和合成器。
# load pretrained model
encoder.load_model(project_name / Path("encoder/saved_models/pretrained.pt"))
# create synthesizer object
synthesizer = Synthesizer(project_name / Path("synthesizer/saved_models/pretrained/pretrained.pt"))
# load model to vocoder
vocoder.load_model(project_name / Path("vocoder/saved_models/pretrained/pretrained.pt"))上传音频和计算嵌入
设置采样率,编码器嵌入,以及上传或记录音频的选项。在这种情况下,我们将上传音频。
# choose appropriate sample rate
SAMPLE_RATE = 22050
# create option to upload or record audio, enter audio duration
rec_upl = "Upld (.mp3 or .wav)" #@param ["Recrd", "Upld (.mp3 or .wav)"]
record_seconds = 600#@param {type:"number", min:1, max:10, step:1}
embedding = None
# compute embeddings
def _compute_embedding(audio):
display(Audio(audio, rate=SAMPLE_RATE, autoplay=True))
global embedding
embedding = None
embedding = encoder.embed_utterance(encoder.preprocess_wav(audio, SAMPLE_RATE))
#function for recording your own voice and computing embeddings
def _record_audio(b):
clear_output()
audio = record_audio(record_seconds, sample_rate=SAMPLE_RATE)
_compute_embedding(audio)
#function for uploading audio and computing embeddings
def _upload_audio(b):
clear_output()
audio = upload_audio(sample_rate=SAMPLE_RATE)
_compute_embedding(audio)
if record_or_upload == "Record":
button = widgets.Button(description="Record Your Voice")
button.on_click(_record_audio)
display(button)
else:
#button = widgets.Button(description="Upload Voice File")
#button.on_click(_upload_audio)
_upload_audio("")生成语音克隆
最后,合成音频并生成输出波形
# text for the voice clone to read out in the synthetically generated audio
text = "Hey guys this is Barack Obama. As you can see, this is not a real video. My creator, Suvojit generated this synthetic video with Generative Adversarial Networks. Like and share this video, and message Suvojit if you want to know more details. Bye" #@param {type:"string"}
def synthesize(embed, text):
print("Synthesizing new audio...")
# synthesize the spectrograms
specs = synthesizer.synthesize_spectrograms([text],
)
generated_wav = vocoder.infer_waveform(specs[0])
# generate output waveform
generated_wav = np.pad(generated_wav, (0, synthesizer.sample_rate), mode="constant")
clear_output()
display(Audio(generated_wav, rate=synthesizer.sample_rate, autoplay=True))
if embedding is None:
print(“upload the audio”)
else:
synthesize(embedding, text)唇形同步:克隆 Wav2Lip Repo
现在是生成口型同步视频的时候了。克隆 Wav2Lip 存储库并下载预训练模型以实现高度准确的唇形同步。挂载 Google 驱动器并上传和复制内容。
#download: https://github.com/Rudrabha/Wav2Lip#training-on-datasets-other-than-lrs2
!git clone https://github.com/Rudrabha/Wav2Lip.git
# copy checkpoints from google drive to session storage
!cp -ri "/content/gdrive/MyDrive/Files/Wav2lip/wav2lip_gan.pth" /content/Wav2Lip/checkpoints/
!cp -ri "/content/gdrive/MyDrive/Files/Wav2lip/wav2lip.pth" /content/Wav2Lip/checkpoints/
!cd Wav2Lip && pip install -r requirements.txt
!wget "https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth" -O "Wav2Lip/face_detection/detection/sfd/s3fd.pth"预处理音频和视频数据
现在设置要处理的文件。
%cd sample_data/
%rm input_audio.wav
%rm input_video.mp4
from google.colab import files
uploaded = files.upload()
%cd ..
!cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face "/content/sample_data/input_video.mp4" --audio "/content/sample_data/input_audio.wav"
from google.colab import files
# download the voice generated in previous steps to session storage
files.download('/content/Wav2Lip/results/result_voice.mp4')
from IPython.display import HTML
from base64 import b64encode
# read binary of the audio file
mp4 = open('/content/Wav2Lip/results/result_voice.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML(f"""
<video width="50%" height="50%" controls>
<source src="{data_url}" type="video/mp4">
</video>
""")上传 Wav2Lip 的输入文件
上传 input_vide o.mp4 & input_audio.wav 文件。输入音频是在上一步从 SV2TTS 生成的。
%cd sample_data/
from google.colab import files
uploaded = files.upload()
%cd ..生成口型同步视频
使用预训练模型创建 wav2lip 视频。
# set the args for checkpoint and input files and generate the lip sync video
!cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth将 Deepfake 下载到你的 PC
就是这样!现在你可以将 deepfake 下载到你的谷歌驱动器和你的电脑上。
files.download('/content/Wav2Lip/results/result_voice.mp4')因此,音频克隆和唇形同步 GAN 的组合可用于制作一个deepfake ,从一个人的 10 秒短视频中生成任何人所说的任意内容(自定义内容)。
参考
SV2TTS 论文: https://arxiv.org/pdf/1806.04558.pdf
Wav2Lip 论文: https://arxiv.org/pdf/2008.10010.pdf
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141558.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
