大家好,又见面了,我是你们的朋友全栈君。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122044727
目录
第1章 关键参考信息
1.1 项目详细
论文:Image-to-Image Translation with Conditional Adversarial Networks
论文链接:https://arxiv.org/abs/1611.07004
代码链接:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
1.2 GAN工作原理
1.3 pix2pix的演进
第2章 pix2pix简介
2.1 概述
论文发表在CVPR2017,简称pix2pix,是将GAN应用于有监督的图像到图像翻译的经典论文,有监督表示训练数据是成对的。相当于给输入图片打了一个标签图片。有了标签图片,神经网络在图像转换的时候,就有了学习的依据,知道如何在输入图片和输出图片之间建立某种关联。
2.2 什么是图像到图像的翻译?
图像到图像的翻译(image-to-image translation)是GAN很重要的一个应用方向,其实就是基于一张输入图像得到想要的输出图像的过程,可以看做是图像和图像之间的一种映射(mapping)。
我们常见的图像修复、超分辨率其实都是图像到图像翻译的例子。
这篇论文列举了一些图像到图像翻译的例子,包括从标签到图像的生成、图像边缘或轮廓到完整图像的生成等过程。如下图所示:
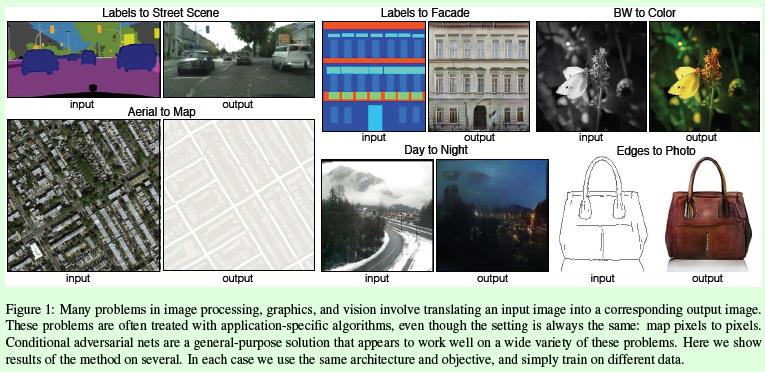

2.3 pix2pix的基本思想
GAN算法的生成器是基于一个随机噪声生成图像,难以控制输出。
pix2pix基于GAN实现图像翻译,更准确地讲是基于cGAN(conditional GAN,也叫条件GAN),因为cGAN可以通过添加条件信息来指导图像生成,因此在图像翻译中就可以将输入图像作为条件,学习从输入图像到输出图像之间的映射,从而得到指定的输出图像。
其他基于GAN完了来做图像翻译,基本上通过方式来指导或约束图像生成,而不是利用cGAN,这是pix2pix和其他基于GAN做图像翻译的差异。
第3章 pix2pix的算法
3.1 pix2pix网络
pix2pix算法的示意图如下图所示:
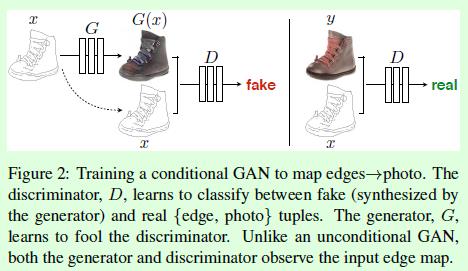
在上图中,以基于图像边缘或轮廓生成完整图像为例,介绍pix2pix的工作流程(过程):
前置说明:
输出图像用y表示,输入图像的边缘图像用x表示,pix2pix在训练时需要成对的图像(x和y)。
步骤:
(1)x作为生成器G的输入得到生成图像G(x)
改进之一:用有意义的图像替代GAN网络的随机噪声。
GAN网络的随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起作为G的输入,可以得到更多样的输出。
![[Pytorch系列-64]:生成对抗网络GAN - 图像生成开源项目pytorch-CycleGAN-and-pix2pix : 有监督图像生成pix2pix的基本原理[通俗易懂]](https://img-blog.csdn.net/20180914044532406)
但这也就产生了新的问题:我们怎样建立输入和输出的对应关系?
- 此时G网络的输出如果是下面这样,D网络会判断是真图:
![[Pytorch系列-64]:生成对抗网络GAN - 图像生成开源项目pytorch-CycleGAN-and-pix2pix : 有监督图像生成pix2pix的基本原理[通俗易懂]](https://img-blog.csdn.net/2018091404455092)
- 此时G网络的输出如果是下面这样,D网络亦然会判断是真图:
![[Pytorch系列-64]:生成对抗网络GAN - 图像生成开源项目pytorch-CycleGAN-and-pix2pix : 有监督图像生成pix2pix的基本原理[通俗易懂]](https://img-blog.csdn.net/2018091404460784)
很显然,此时输出的猫,与输入的猫之间,虽然都是猫这种抽象关系,属于“神似”,但“形状不相似”。怎么才能让输出与输入之间有“形似”呢?
(2)将G(x)和x基于通道维度合并在一起,送入判决网络。
改进之二:判决网络的输入不仅仅是生成图片,还包括输入图片。
(3)判决器对合并后的图片进行判决
判别器D,根据输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。
改进之三:判决器判决生成图片是否为真实图片的条件
- 输出图片符合真实图片的特征
- 输出图片与输入图片具备成对的特征。
(4)判决网络的训练
改进之四:用于训练的样本图片必须是成对出现的图片,而不是单独的图片,如下图所示:
也就是说,pix2pix的判决网络,不仅仅是判决输入图片局部真实图片的特征,还就要判决,输入与输出整合在一起之后是否为真实图片。
也就说,判别器D的训练目标就是:
- 在输入不是一对真实图像(x和G(x))时输出小的概率值(比如最小是0),
- 在输入是一对真实图像(x和y)时输出大的概率值(比如最大是1)。
(5)生成器G的训练
生成器G的训练目标就是:使得生成的G(x)和x作为判别器D的输入时,判别器D输出的概率值尽可能大,这样就相当于成功欺骗了判别器D。
与GAN网络相比,生成器G并没有改进 。
3.2 G网络的训练与优化目标(使用训练样本)
![[Pytorch系列-64]:生成对抗网络GAN - 图像生成开源项目pytorch-CycleGAN-and-pix2pix : 有监督图像生成pix2pix的基本原理[通俗易懂]](https://img-blog.csdnimg.cn/413b5579953c4bf5b0effc753543c32a.png)
G网络的训练与优化目标: 尽可能的伪装
- 浅蓝色网络:在锁定D网络的情况下,通过调整W/B参数,确保G网络生成的图片,能够骗过D网络,使得D网盘判断为真实图片,与标签图片“神似”
- 浅绿色网络:在锁定D网络的情况下,通过调整W/B参数,确保G网络生成的图片,与标签图片“形似”。
- 综合loss_G最小
3.3 D网络的训练与优化目标(使用训练样本)
![[Pytorch系列-64]:生成对抗网络GAN - 图像生成开源项目pytorch-CycleGAN-and-pix2pix : 有监督图像生成pix2pix的基本原理[通俗易懂]](https://img-blog.csdnimg.cn/b76bd4a9e8c0485cadd0c058d32e8ec9.png)
D网络的训练与优化目标:能够尽快识别真假。
- 在锁定G网络的情况下,如果D网络的输入=真实输入图片+生成图片, 则判决为假
- 在锁定G网络的情况下,如果D网络的输入=真实输入图片+成对图片, 则判决为真
- 综合loss_D最小
3.4 pix2pix网络的对抗
pix2pix与GAN网络一样,通过G网络与D网络的对抗,不断的优化和演进,最后得到最优的网络。
3.5 训练好后模型的输出
(1)创作的图片:来自G网络
(2)仿真效果(概率):来自D网络
第4章 pix2pix网络的使用
最后放一下pix2pix的生成图像,可以基于图像边缘得到图像、基于语义分割的标签得到图像、背景去除、图像修复等。更多结果可以参考原论文,效果还是很不错的。
(1)案例1:输入脸部轮廓,输出完整的脸部图片

(2)输入街景轮廓,输出完整的街景图片

作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122044727
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128296.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
