大家好,又见面了,我是你们的朋友全栈君。
一、准备
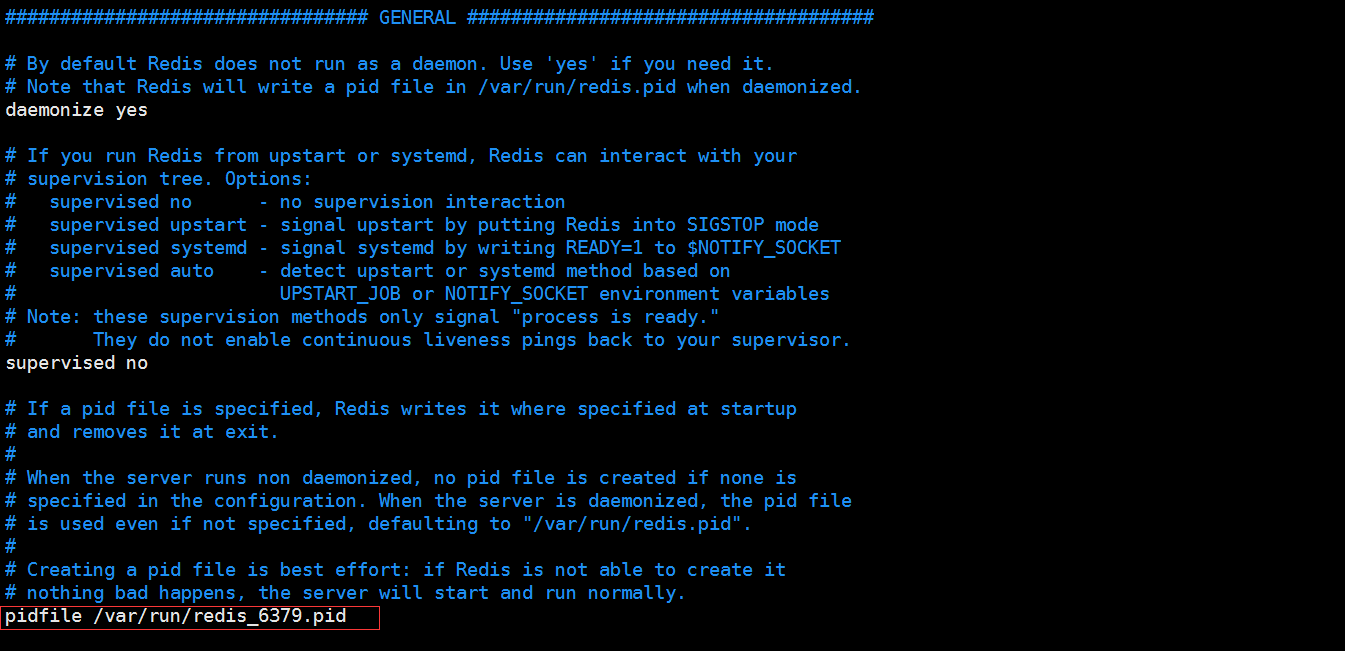
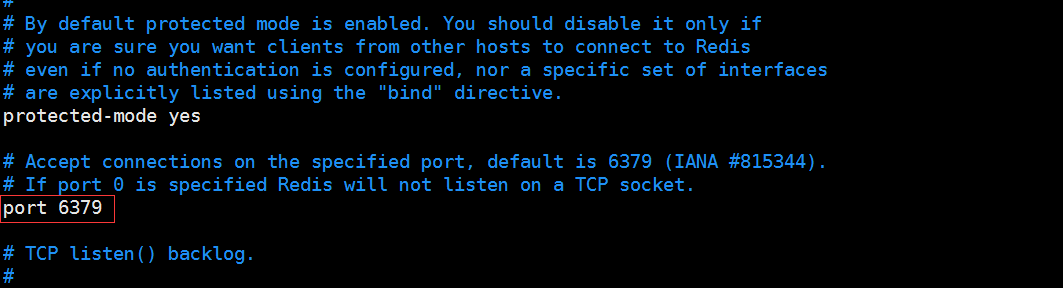
1、修改pidfile 和端口

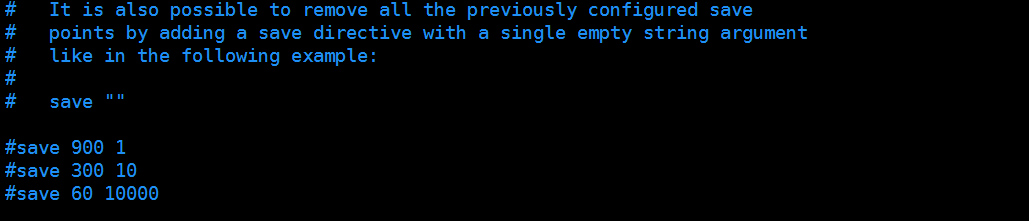
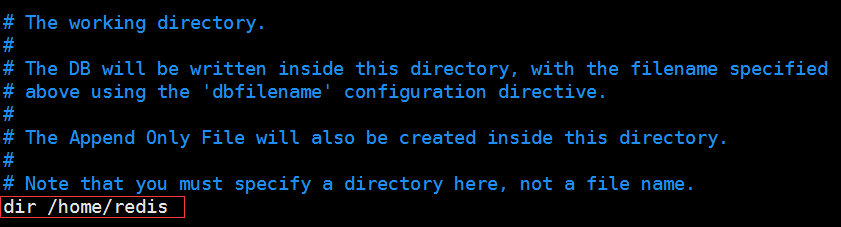
2、关闭RDB持久化修改持久化文件的保存位置
3、启动Redis
redis-server /etc/redis.conf4、使用客户端连接Redis
redis-cli二、主从复制(读写分离)
redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构.可以避免redis单点故障,构建读写分离架构,满足读多写少的应用场景.
1、主从复制原理

①slave发起请求和master建立连接,master验证通过后即可建立连接。
②slave发送同步sync的命令,这时主库会新起一个子进程,以快照的方式把数据导入到rdb文件中,并传输给从库
③从库将rdb文件导入到数据库中,并加载到内存
④在后面做同步的时候,master会把所有命令先buffer起来,不会往磁盘写,直接给slave。
备注:如果master重启,备份数据会重新dump。
2、Redis复制功能的几个重要方面
①一个Master可以有多个Slave;
②Redis使用异步复制。从2.8开始,Slave会周期性(每秒一次)发起一个Ack确认复制流(replication stream)被处理进度;
③不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图状结构
④复制在Master端是非阻塞模式的,这意味着即便是多个Slave执行首次同步时,Master依然可以提供查询服务;
⑤复制在Slave端也是非阻塞模式的:如果你在redis.conf做了设置,Slave在执行首次同步的时候仍可以使用旧数据集提供查询;你也可以配置为当Master与Slave失去联系时,让Slave返回客户端一个错误提示;
⑥当Slave要删掉旧的数据集,并重新加载新版数据时,Slave会阻塞连接请求(一般发生在与Master断开重连后的恢复阶段);
⑦复制功能可以单纯地用于数据冗余(dataredundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability):比如说,繁重的 SORT 命令可以交给附属节点去运行。
⑧可以通过修改Master端的redis.config来避免在Master端执行持久化操作(Save),由Slave端来执行持久化。
三、主从架构
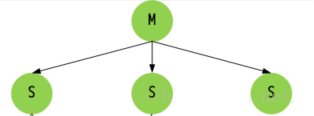
1、准备3个配置文件端口分别为
6379 (Master)
6380 (Slave)
6381 (Slave)2、修改原来的redis.conf文件 ,拷贝出2个redis.conf文件
mv /etc/redis.conf /etc/redis.6379.conf
cp /etc/redis.6379.conf /etc/redis.6380.conf
cp /etc/redis.6379.conf /etc/redis.6381.conf3、修改6380 和 6381 配置文件
vim /etc/redis.6380.conf
通过命令替换 6379 为 6380
:%s/6379/6380/g最底下出现 表示修改成功, wq退出并保存

4、用一样的方式修改6381 的配置文件
5、启动3个redis实例
redis-server /etc/redis.6379.conf
redis-server /etc/redis.6380.conf
redis-server /etc/redis.6381.conf6、通过ps 命令查看redis进程
ps -ef | grep redis7、主从的配置有2种方法:
①在所有从节点的redis.conf(redis.6380.conf和redis.6381.conf)中设置 slaveof
②使用redis-cli客户端连接到Redis服务中,执行slaveof命令
这种方式在重启之后就会失去主从复制关系
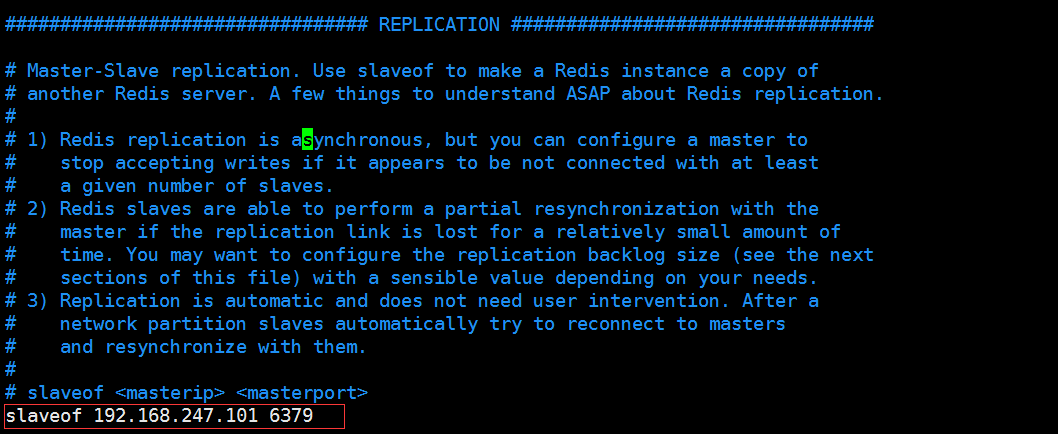

8、查看主从信息:INFO replication
①主库查询
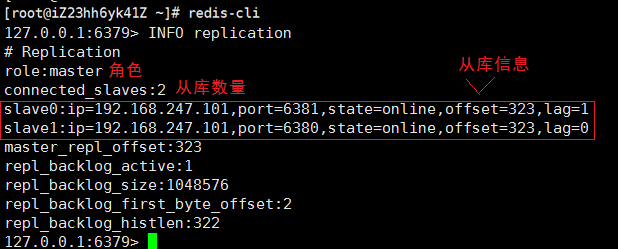
②从库显示的信息
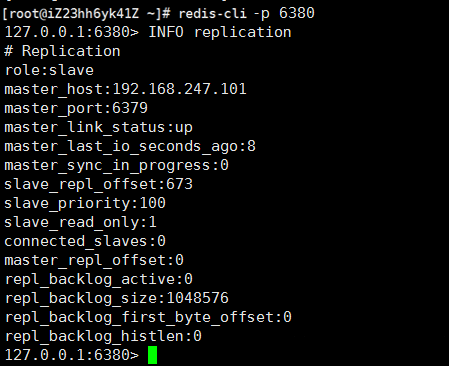
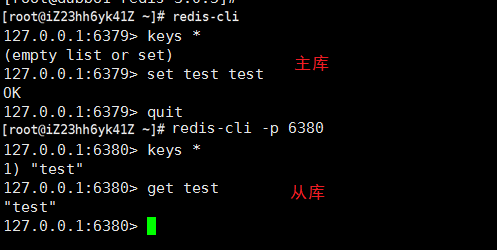
③测试主从关系
在主库写入数据 ,然后在从库读取数据
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127911.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
