大家好,又见面了,我是你们的朋友全栈君。
TTS(Text To Speech)是一个序列到序列的匹配问题。处理TTS的方法一般分为两部分:文本分析和语音合成(speech synthesis)。文本分析可能采用NLP方法。
而在语音合成(speech synthesis)上有两种主要的方法:一种是非参数化的,基于样例的方法,如拼接语音合成;另一种是参数化的、基于模型的方法,如统计参数语音合成。
拼接语音合成:
基于统计规则的大语料库拼接语音合成系统
超大规模音库制作:语料设计;音库录制;精细切分;韵律标注;
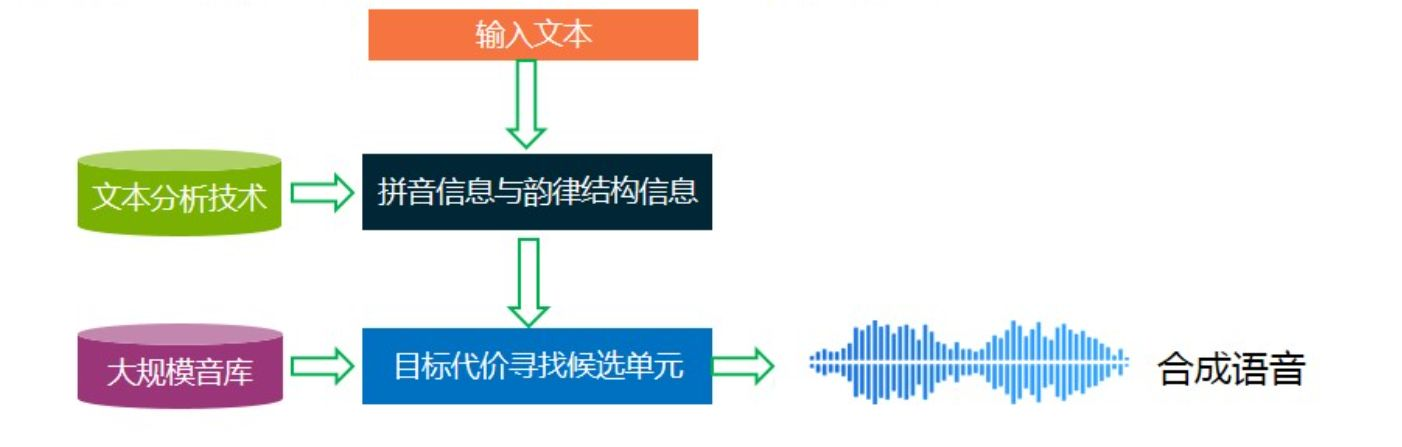

优点:音质最佳,录音和合成音质差异小,正常句子的自然度也好
缺点:非常依赖音库的规模大小和制作质量,尺寸大,无法在嵌入式设备中应用,仍然存在拼接不连续性
参数语音合成
对于引得频谱特性参数进行建模,生成参数合成器,来构建文本序列映射到语音的映射关系
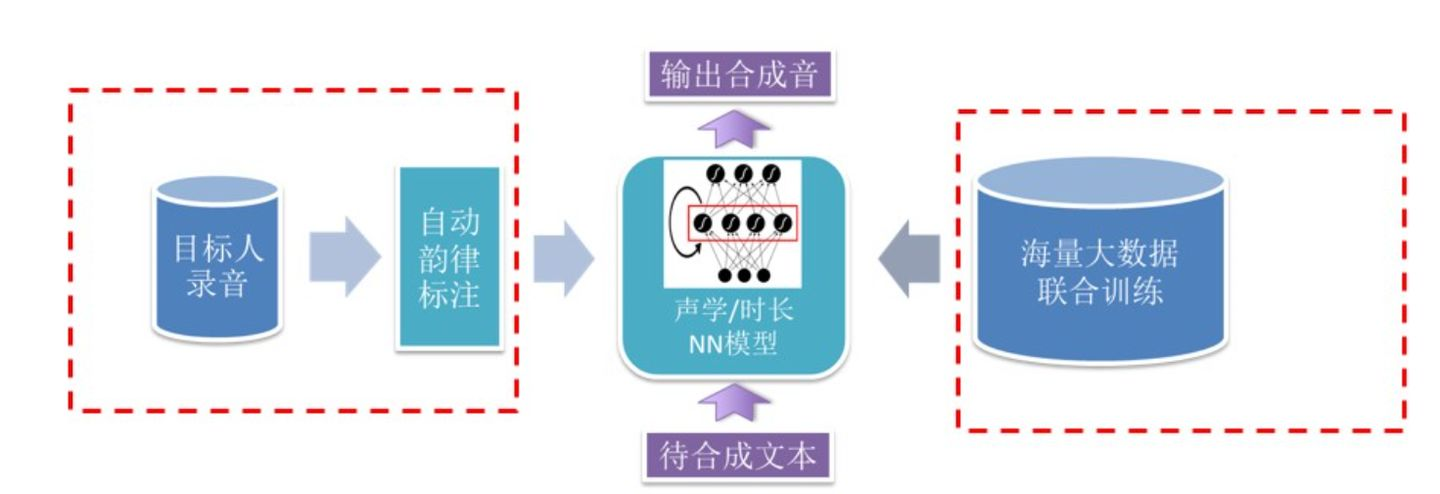
优点:尺寸小,语音自然度好
缺点:音质不如拼接合成
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153162.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
