大家好,又见面了,我是你们的朋友全栈君。
构建了最简单的网络之后,是时候再加上卷积和池化了。这篇,虽然我还没开始构思,但我知道,一定是很长的文章。
卷积神经网络(Convolutional Neural Layer, CNN),除了全连接层以外(有时候也不含全连接层,因为出现了Global average pooling),还包含了卷积层和池化层。卷积层用来提取特征,而池化层可以减少参数数量。
卷积层
先谈一下卷积层的工作原理。
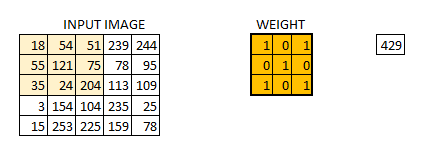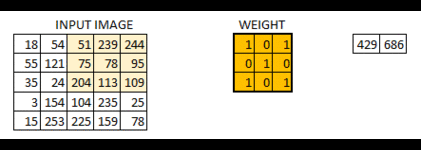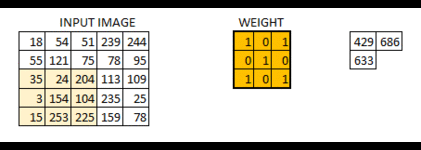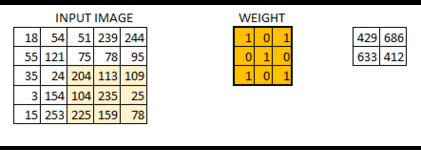
我们是使用卷积核来提取特征的,卷积核可以说是一个矩阵。假如我们设置一个卷积核为3*3的矩阵,而我们图片为一个分辨率5*5的图片。那么卷积核的任务就如下所示:
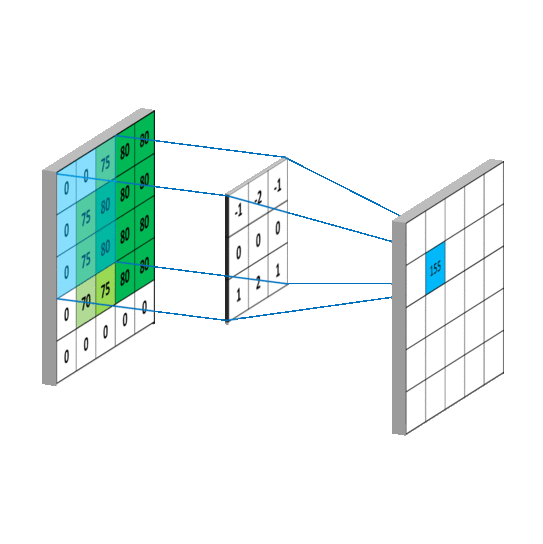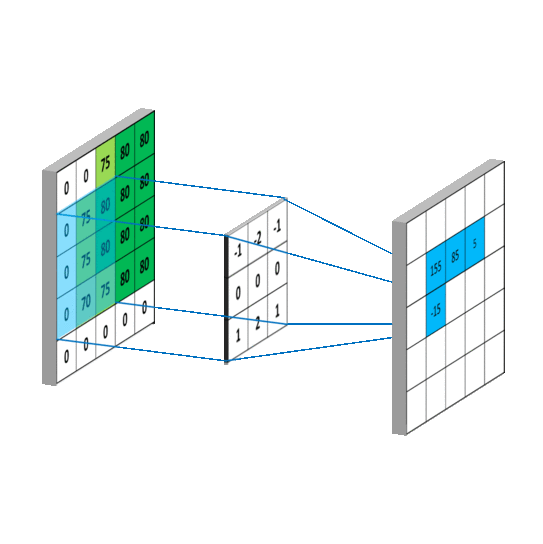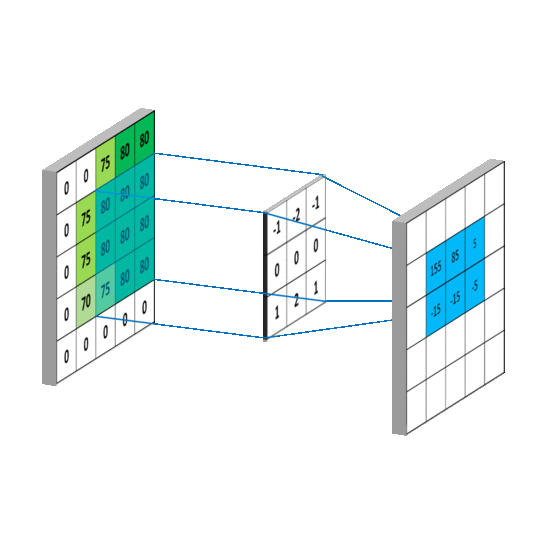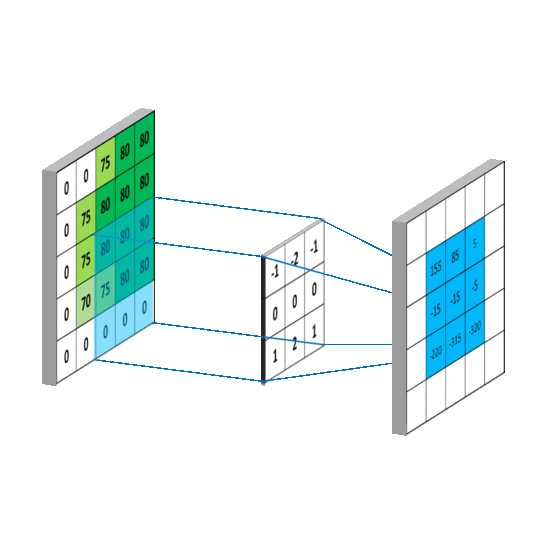
从左上角开始,卷积核就对应着数据的3*3的矩阵范围,然后相乘再相加得出一个值。按照这种顺序,每隔一个像素就操作一次,我们就可以得出9个值。这九个值形成的矩阵被我们称作激活映射(Activation map)。这就是我们的卷积层工作原理。也可以参考下面一个gif:
其中,卷积核为
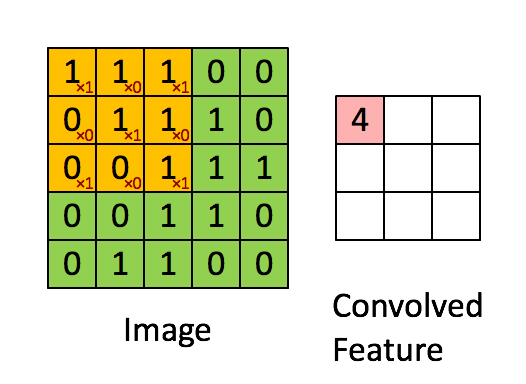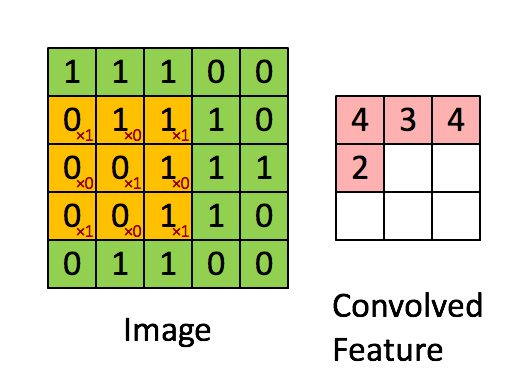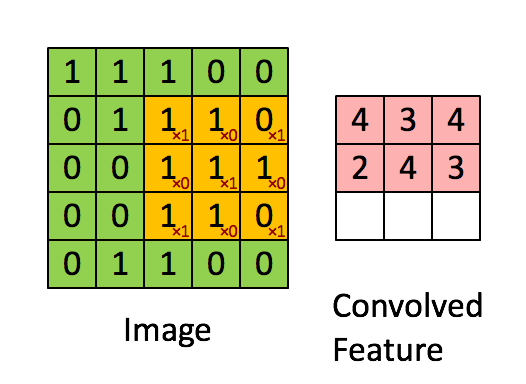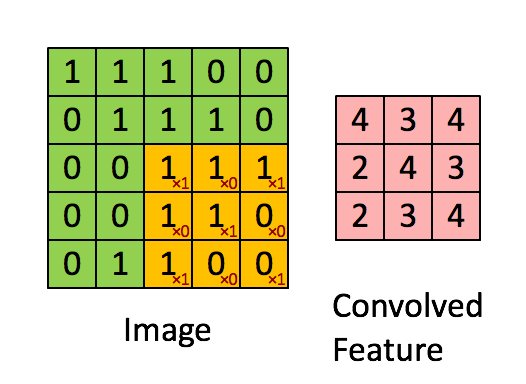
其实我们平时举例的卷积核已经被翻转180度一次了,主要是因为计算过程的原因。详细不用了解,但原理都一样。
但其实我们输入的图像一般为三维,即含有R、G、B三个通道。但其实经过一个卷积核之后,三维会变成一维。它在一整个屏幕滑动的时候,其实会把三个通道的值都累加起来,最终只是输出一个一维矩阵。而多个卷积核(一个卷积层的卷积核数目是自己确定的)滑动之后形成的Activation Map堆叠起来,再经过一个激活函数就是一个卷积层的输出了。
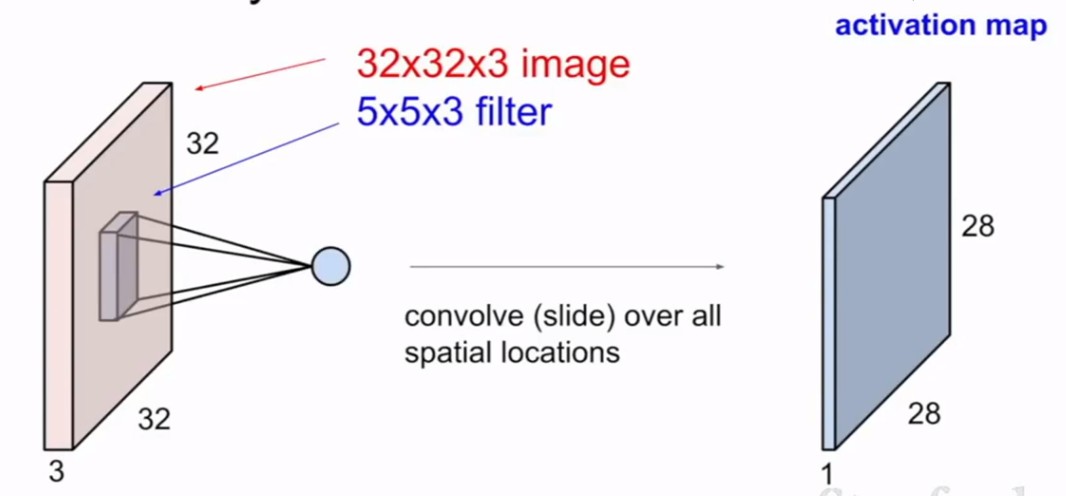
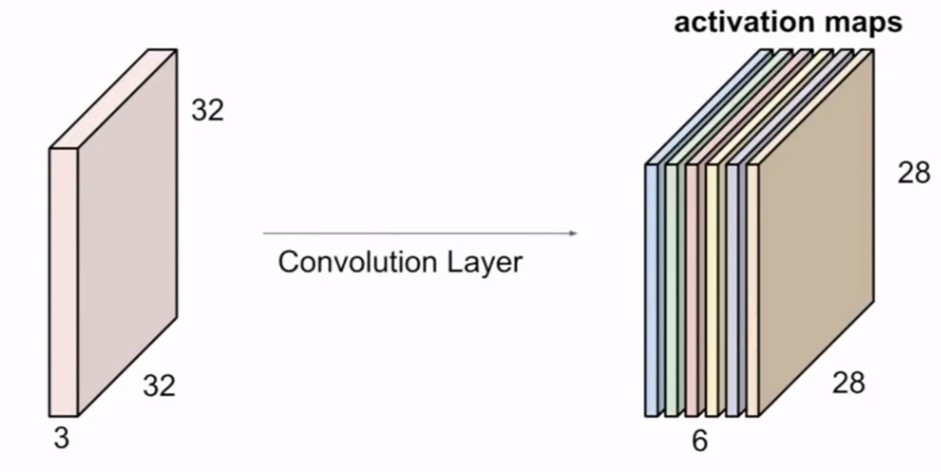
卷积层还有另外两个很重要的参数:步长和padding。
所谓的步长就是控制卷积核移动的距离。在上面的例子看到,卷积核都是隔着一个像素进行映射的,那么我们也可以让它隔着两个、三个,而这个距离被我们称作步长。
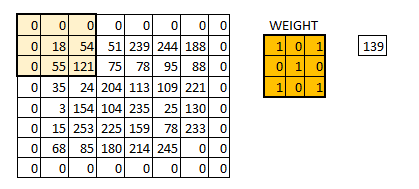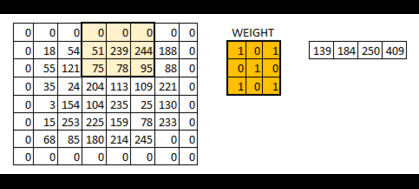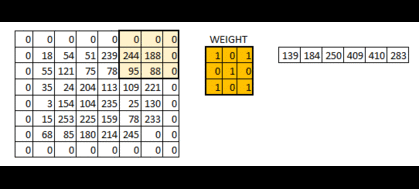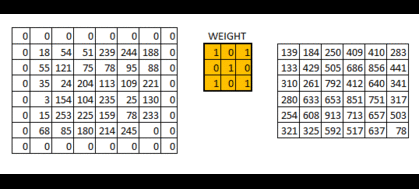
而padding就是我们对数据做的操作。一般有两种,一种是不进行操作,一种是补0使得卷积后的激活映射尺寸不变。上面我们可以看到5*5*3的数据被3*3的卷积核卷积后的映射图,形状为3*3,即形状与一开始的数据不同。有时候为了规避这个变化,我们使用“补0”的方法——即在数据的外层补上0。
下面是示意图:
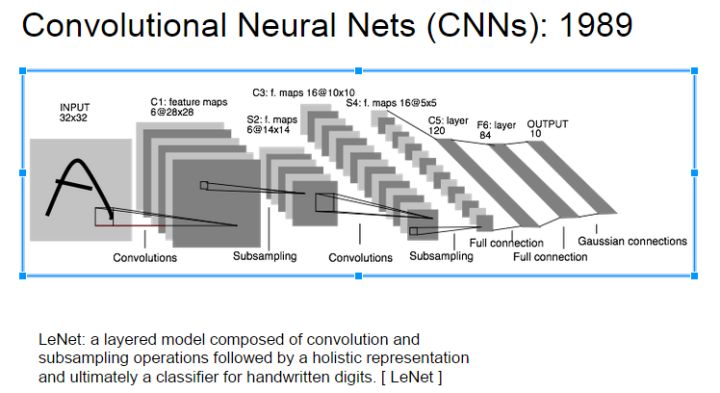
了解卷积发展史的人都应该知道,卷积神经网络应用最开始出现是LeCun(名字真的很像中国人)在识别手写数字创建的LeNet-5。

后面爆发是因为AlexNet在ImageNet比赛中拔得头筹,硬生生把误差变成去年的一半。从此卷积网络就成了AI的大热点,一大堆论文和网络不断地发挥它的潜能,而它的黑盒性也不断被人解释。
能否对卷积神经网络工作原理做一个直观的解释? – Owl of Minerva的回答 – 知乎里面通过我们对图像进行平滑的操作进而解释了卷积核如何读取特征的。
我们需要先明确一点,实验告诉我们人类视觉是先对图像边缘开始敏感的。在我的理解中,它就是说我们对现有事物的印象是我们先通过提取边界的特征,然后逐渐的完善再进行组装而成的。而我们的卷积层很好的做到了这一点。

这是两个不同的卷积核滑动整个图像后出来的效果,可以看出,经过卷积之后图像的边界变得更加直观。我们也可以来看下VGG-16网络第一层卷积提取到的特征:

由此来看,我们也知道为什么我们不能只要一个卷积核。在我的理解下,假使我们只有一个卷积核,那我们或许只能提取到一个边界。但假如我们有许多的卷积核检测不同的边界,不同的边界又构成不同的物体,这就是我们怎么从视觉图像检测物体的凭据了。所以,深度学习的“深”不仅仅是代表网络,也代表我们能检测的物体的深度。即越深,提取的特征也就越多。
Google提出了一个项目叫Deepdream,里面通过梯度上升、反卷积形象的告诉我们一个网络究竟想要识别什么。之前权重更新我们讲过梯度下降,而梯度上升便是计算卷积核对输入的噪声的梯度,然后沿着上升的方向调整我们的输入。详细的以后再讲,但得出的图像能够使得这个卷积核被激活,也就是说得到一个较好的值。所以这个图像也就是我们卷积核所认为的最规范的图像(有点吓人):

其实这鹅看着还不错,有点像孔雀。
池化层 (pooling layer)
前面说到池化层是降低参数,而降低参数的方法当然也只有删除参数了。
一般我们有最大池化和平均池化,而最大池化就我认识来说是相对多的。需要注意的是,池化层一般放在卷积层后面。所以池化层池化的是卷积层的输出!
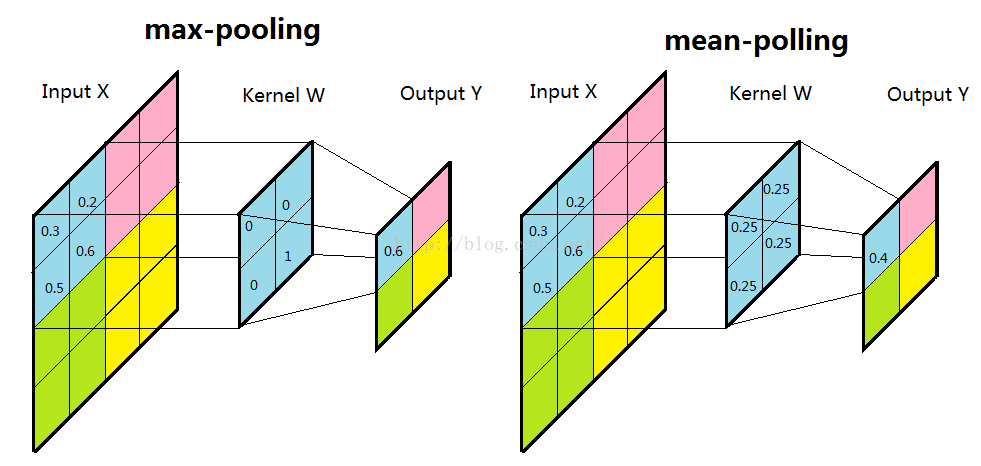
扫描的顺序跟卷积一样,都是从左上角开始然后根据你设置的步长逐步扫描全局。有些人会很好奇最大池化的时候你怎么知道哪个是最大值,emmm,其实我也考虑过这个问题。CS2131n里面我记得是说会提前记录最大值保存在一个矩阵中,然后根据那个矩阵来提取最大值。
至于要深入到计算过程与否,应该是没有必要的。所以我也没去查证过程。而且给的都是示例图,其实具体的计算过程应该也是不同的,但效果我们可以知道就好了。
至于为什么选择最大池化,应该是为了提取最明显的特征,所以选用的最大池化。平均池化呢,就是顾及每一个像素,所以选择将所有的像素值都相加然后再平均。
池化层也有padding的选项。但都是跟卷积层一样的,在外围补0,然后再池化。
代码解析
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
summary_dir = './summary'
#批次
batch_size = 100
n_batch = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32, [None, 784], name='input')
y = tf.placeholder(tf.float32, [None, 10], name='label')
def net(input_tensor):
conv_weights = tf.get_variable('weight', [3, 3, 1, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv_biases = tf.get_variable('biase', [32], initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(input_tensor, conv_weights, strides=[1, 1, 1, 1], padding='SAME')
relu = tf.nn.relu(tf.nn.bias_add(conv, conv_biases))
pool = tf.nn.max_pool(relu, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')
pool_shape = pool.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
pool_reshaped = tf.reshape(pool, [-1, nodes])
W = tf.Variable(tf.zeros([nodes, 10]), name='weight')
b = tf.Variable(tf.zeros([10]), name='bias')
fc = tf.nn.softmax(tf.matmul(pool_reshaped, W) + b)
return fc
reshaped = tf.reshape(x, (-1, 28, 28, 1))
prediction = net(reshaped)
loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y, 1), logits=prediction, name='loss')
loss = tf.reduce_mean(loss_)
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='accuracy')
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(31):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print('Iter' + str(epoch) + ",Testing Accuracy" + str(acc))这相对于我第一个只用全连接的网络只多了一个net函数,还有因为卷积层的关系进来的数据x需要改变形状。只讲这两部分:
reshaped = tf.reshape(x, (-1, 28, 28, 1))
prediction = net(reshaped)由于我们feedict上面是,feed_dict={x: mnist.test.images, y: mnist.test.labels},而这样子调用tensorflow的句子我们得到的x是固定的形状。因此我们应用tf.reshape(x_need_reshaped,object_shape)来得到需要的形状。
其中的 −1 − 1 表示拉平,不能用None,是固定的。
conv_weights = tf.get_variable('weight', [3, 3, 1, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv_biases = tf.get_variable('biase', [32], initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(input_tensor, conv_weights, strides=[1, 1, 1, 1], padding='SAME')
relu = tf.nn.relu(tf.nn.bias_add(conv, conv_biases))
pool = tf.nn.max_pool(relu, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')大部分都是应用内置的函数,来初始化weight(就是卷积核)和biases(偏置项)。偏置项我们没有提到,但其实就是多了一个参数来调控,因此我们讲卷积层的时候也没怎么讲。按照代码就是出来Activation Map之后再分别加上bias。池化也是用到了最大池化。
注意一下relu。它也是一个激活函数,作用可以说跟之前讲的softmax一样,不过它在卷积层用的比较多,而且也是公认的比较好的激活函数。它的变体有很多。有兴趣大家可以自己去查阅资料。以后才会写有关这方面的文章。
pool_shape = pool.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
pool_reshaped = tf.reshape(pool, [-1, nodes])
W = tf.Variable(tf.zeros([nodes, 10]), name='weight')池化层的输出我们并不知道它是如何的形状(当然,你也可以动手算)。因此就算把池化层拉成一维的矩阵,我们也不知道W需要如何的形状。因此,我们查看pool(即池化层的输出)的形状,我暗地里print了一下为[None, 14, 14, 32],因此pool拉平后,就是[None, 14*14*32, 10]。为了接下来进行全连接层的计算,我们的W的形状也应该为[14*14*32, 10]。这段代码的原理就是如此。
准确率也一样取后15次:
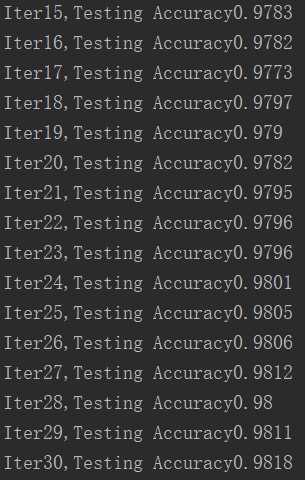
emmm, 不用跟之前比了,明显比以前好很多了。下一章决定总结一下,优化的方法好了。
参考
https://mlnotebook.github.io/post/CNN1/(可惜是全英)
能否对卷积神经网络工作原理做一个直观的解释? – Owl of Minerva的回答 – 知乎
CS231n
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127639.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
