大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
六千多字的大篇……诚意满满啊……
橘生淮南则为橘,生于淮北则为枳,叶徒相似,其实味不同。所以然者何?水土异也。——《晏子春秋·内篇杂下》
水土不服、南北差异,(包括地域歧视)是自古以来的一个大命题……正如在(伪)吃货的眼中,中国的地图是这样的:

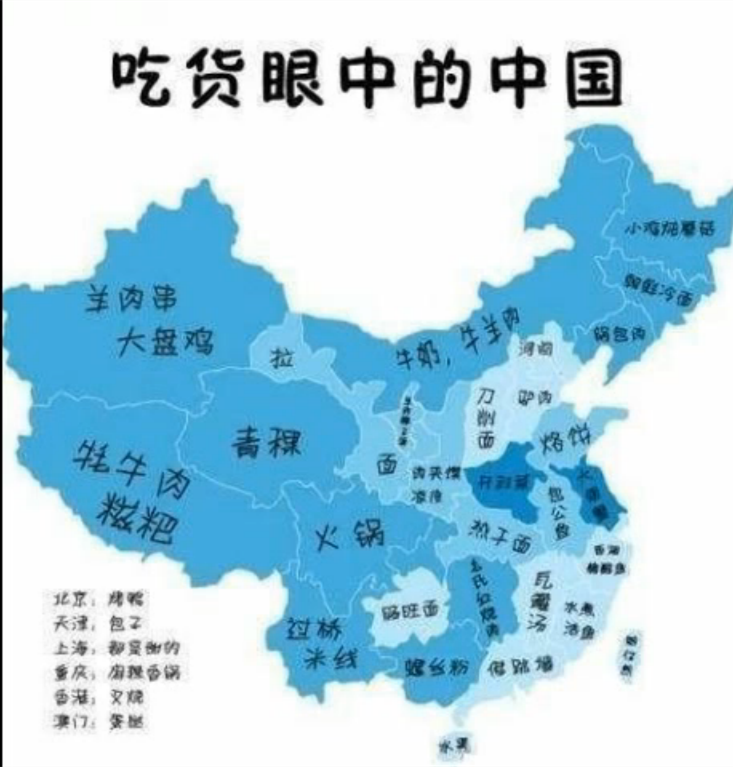
为什么说上面是伪?吃货呢,因为在真?吃货眼中的中国地图,是这样的:
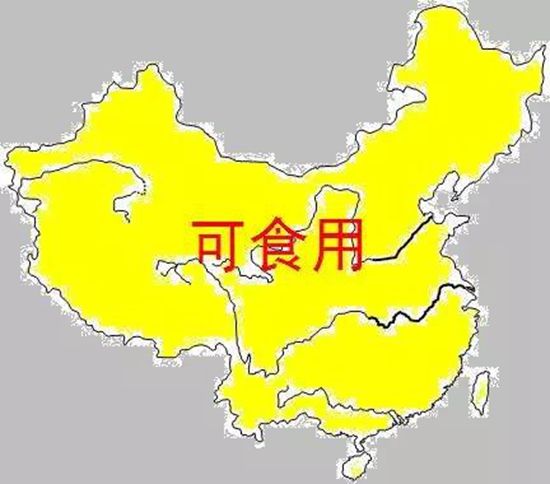
这就是具有全局眼(胃)光(口)和局部眼(胃)光(口),对食品口味这些词语的定义了……我们一直以来都在赞美全局思维,批判局部思维,比如《盲人摸象》啥的,但是在分析的时候,确正好相反,很多时候,全局的思路会带来各种问题。
从概念来说,进行分析的时候,全局模式(Global model)在分析之前,就假定了变量的关系具有同质性(homogeneity),从而掩盖了变量间关系的局部特性,所得到的结果,就是研究区域内的某种“平均”。如下面所示:
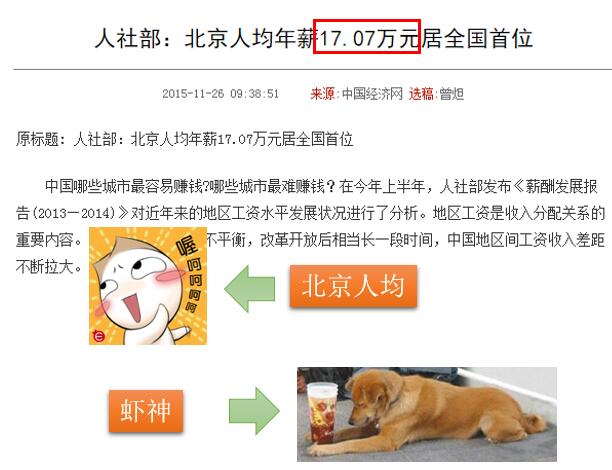
如果说,上面的平均还没有涉及到空间层面,下面这种情况也是经常遇见的:
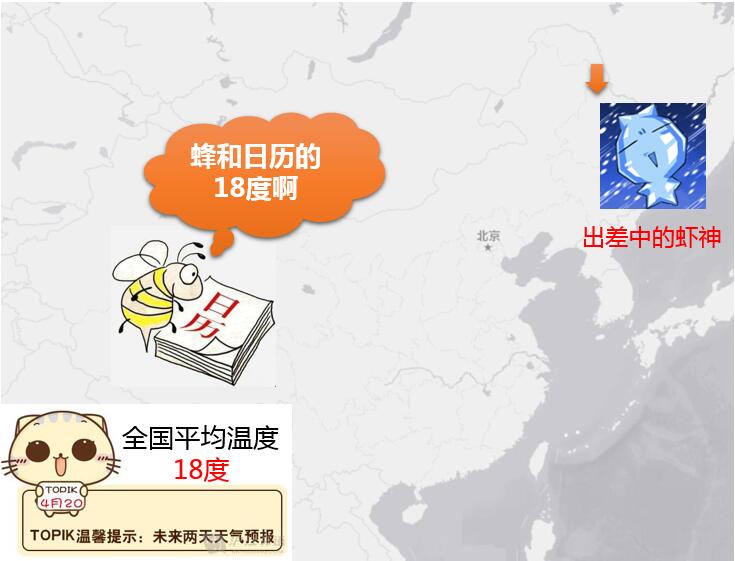
这种因为地理位置的变化,而引起的变量间关系或结构的变化称之为空间非平稳性(spatial nonstationarity)),注意,这个图词语空间异质性,之间是不能画等号的。初略说起来,可以认为空间非平稳性是空间异质性的一种表现形式。
在空间上出现的非平稳性,通常被认为由以下三个方面的原因引起的:
1、随机抽样的误差引起的。抽样误差是无法避免的,也是无法观察的,所以统计学上一般只假定它服从某一分布,没必要去死纠这种变化,因为对分析本身的关系作用不大。
2、是由于各地区不同的自然环境、人文环境等差异所引起的变量间的关系随着地理位置的变化而变化。这种变化反应是数据本身的空间特性,所以在空间分析中是需要着重注意的地方。
3、用于分析的模型与实际不符,或者忽略了模型中应有的一些回归变量而导致的空间非平稳性。
传统分析领域里面,应对非平稳性方法有以下两种
第一就是所谓的局部回归分析。
方法一就是把研究区域根据某种指标,划分成若干个同质性的区域,然后分别进行回归,正如我上一篇文章所做的那样,安装行政区划进行划分,然后分别在每个区域里面进行回归。但是这种方法的缺点也灰常明显:行政区划或者自然区域的面积一般都不相等,这样就会导致在均匀采样的时候,各个区域内的样本数量都不一致……对同回归一模型,采用不同规模的样本来进行拟合,得到的估计参数肯定也是不一样的。这样就很难让人信服分区回归得到的参数估计变化,是因为空间关系的空间非平稳性导致的。

样本数是一回事,另一回事就是行政区划的本来就有各种的特殊情况,正如钱穆大师在《中国历代政治得失》里面说的,中国的省级行政区划划分,本来就是一个不祥的称谓(钱穆大师考据的行省,全称是“行中书省”,就是中书省的派出所。划分行省:
“……并不是说把全国划分成几个地方行政区,乃是这几区地方各驻有中央宰相,即成为中央宰相府的活动分张所。所以行中书省正名定义,并不是地方政府,而只是流动的中央政府。换言之,是中央侵入了地方。中央需要派一个大员来镇压某地方,就派一个外驻的宰相。在元代,共计有如是的十个分张所,并不是全国地方行政分成为十个区。行省制度在法理上的实际情形是如此。
……再深一层言之。这种行省设施,实际上并不是为了行政方便,而是为了军事控制。
……南京也是一军事重镇,但如广德不守,或者芜湖放弃了,南京也不能保,而广德、芜湖也都不在江苏的管辖内。任何一省都如此。给你这一半,割去你那一半。好使全国各省,都成支离破碎。既不能统一反抗,而任何一区域也很难单独反抗。这是行省制的内在精神。”)
这种支离破碎的划分,导致现在一直流传这个“南京是安徽省省会”这样一个笑话……一口淮北方言的南京,和吴方言区的苏锡常,怎么看也不像一个区域的样子。
所以按照行政区划的划分来做,先不论各种人文环境,在行政区划的交界处,会因为不同区域内的参数估计不一样,而产生突然的“跳变”。但是实际上很多空间关系在行政区划或者自然区域的交界处的变化是缓慢而连续的。
为了克服分区回归的一些问题,人们有提出了移动窗口回归。
这种回归方法在每一个样本的周边定义一个回归区域,这个区域由窗口的大小和性质决定,以窗口内的样本数据建立回归方程进行参数估计。
这两种方法,都是用阶段回归的参数估计,来进行对比,以探测空间关系的非平稳性。

移动窗口,一直以来都是进行平滑的主要方法,在回归中采用这种方法,可以解决样本数量变化的问题,也可以解决边界突然跳变的问题,但是依然无法避免相邻回归点上参数估计的跳变问题,即在整个研究区域内参数估计值的曲面依然是不连续光滑的。
移动窗口本质上一人是一种全局性的回归,只不是将这个区域缩小了而已。用这种方法,我们认为整个区域内的存在空间非平稳性,但是在回归的区域内却是平稳的——所有的的样本点上的参数都相同,那么这样推导的结果就是整个区域的空间关系是稳定的——于是矛盾就产生了。
另一种方法,就是采用变参数回归模型,也就是地理加权回归的前身。这种方法也是将地理位置作为全局模型中的参数加入建模和运算。这种方法推动了回归模型的研究,但是作为一种趋势拟合方法,如果空间模型的参数变化更加复杂一些,这个方法就歇菜了。
最后,在总结了前人关于局部回归和变参研究的基础上,美国科学院院士,英国圣安德鲁斯大学的A. Stewart Fotheringham教授在1996年,正式提出了地理加权回归模型(Geographical Weighted Regression , GWR)。
以下是科普时间:
相片中红圈里面的老帅哥就是Fotheringham教授(本相片是2011年11月,Fotheringham教授加盟有着600年历史的英国名校圣安德鲁斯大学(University of St. Andrews, UK)地理系,并在该校建立地理信息学研究中心(Centre of GeoInformatics,CGI),这是当时Fotheringham教授(后排右一)与多位新加盟教授与圣安德鲁斯大学校长(前排左三)等合影留念。英国圣安德鲁斯大学是一所有着很高贵族传统的学校,迄今已经有600年历史,是苏格兰第一学府。)

Fotheringham教授1976年毕业于英国阿伯丁大学地理系,1978年和1980年分别获得加拿大McMaster大学硕士和博士学位,博士毕业后,仅用了8年时间,1988年34岁时就成为美国纽约州立大学Buffalo分校(SUNY Baffalo)地理系正教授,专攻GIS与空间分析。
1994年,Fotheringham教授回到英国纽卡斯尔大学,担任地理系教授,在此期间,他最为经典的工作——研究空间异质性的地理加权回归(GWR)方法的系列论文相继发表,其中一篇论文的单篇被引用了1300多次,是GIS与空间分析领域最为经典的工作。
在2013年4月30日,Fotheringham教授当选美国科学院院士,这是5年来再次有GIS与空间分析专家当选美国科学院院士。(上一次是2008年,美国亚利桑那州立大学(ASU)地理学院院长Luc Anselin教授当选美国科学院院士——局部莫兰指数的提出者,Geoda之父)。
而这个GWR到底是啥东西?有啥原理?如何使用?如何解读呢?请听下回分解。
还有……进来虾神发现很多同学对这个东西比较着急,但是也没办法,刚刚开年,虾神的工作也比较忙,所以一周也就能写一篇两篇的……请大家稍安勿躁……
最后贴出虾神最喜欢的一部小说里面的经典台词:
人类的一切智慧是包含在这四个字里面的:‘等待’和‘希望’!——法,大仲马 《基督山伯爵》

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184911.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
