大家好,又见面了,我是你们的朋友全栈君。
为什么要先学fiddler?
学习接口测试必学http协议,如果直接先讲协议,我估计小伙伴们更懵,为了更好的理解协议,先从抓包开始。
结合抓包工具讲http协议更容易学一些。
抓firefox上https请求
fiddler是一个很好的抓包工具,默认是抓http请求的,对于pc上的https请求,会提示网页不安全,这时候需要在浏览器上安装证书。
一、网页不安全
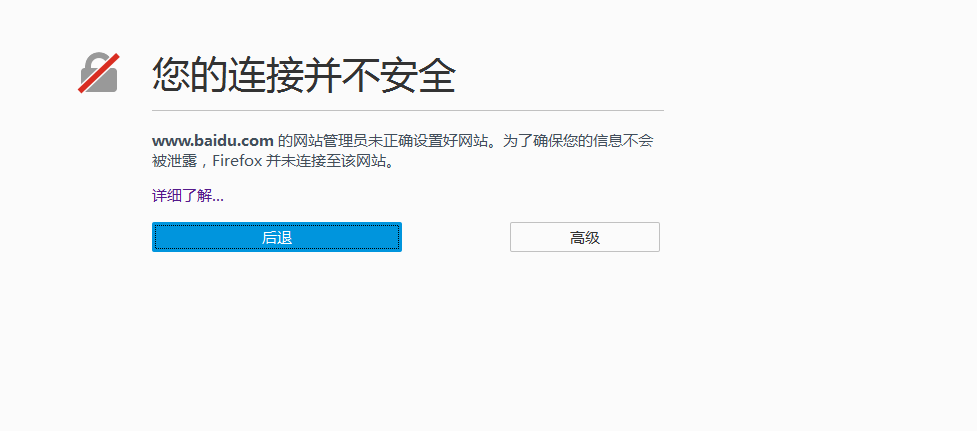
1.用fiddler抓包时候,打开百度网页:https://www.baidu.com
2.提示:网页不安全

二、fiddler设置
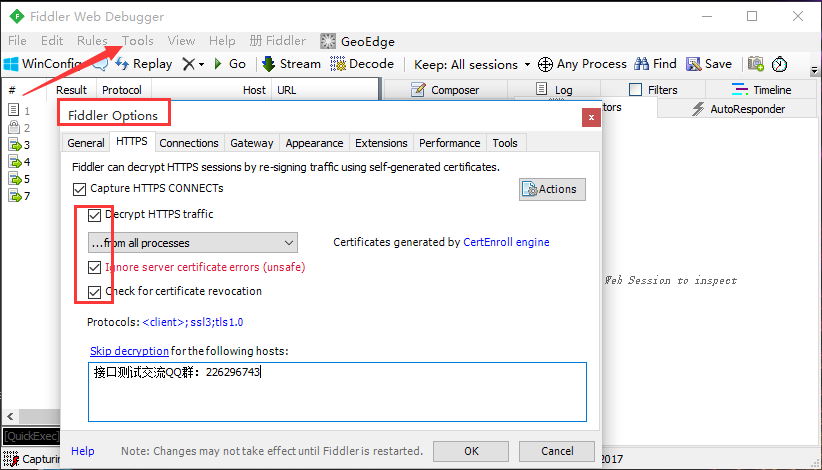
1.打开菜单栏:Tools>Fiddler Options>HTTPS
2.勾选Decrypt HTTPS traffic,里面的两个子菜单也一起勾选了
三、导出证书
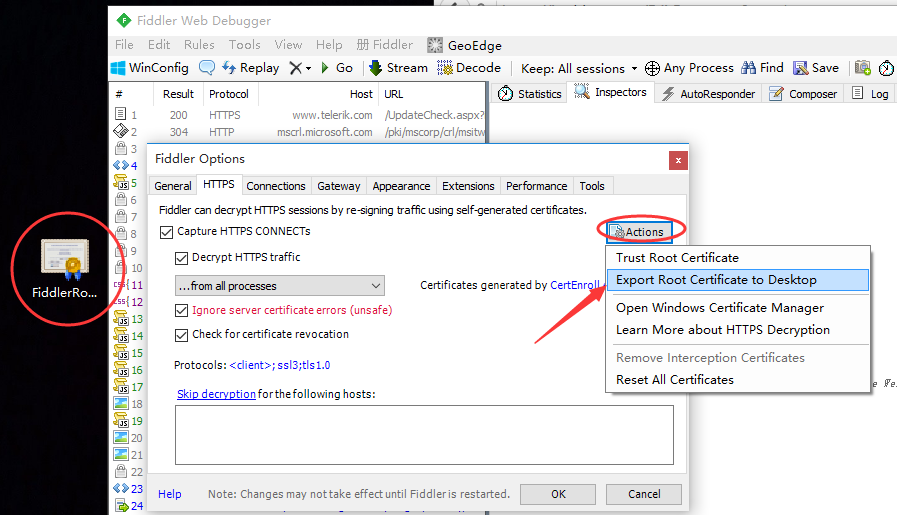
1.点右上角Actions按钮
2.选第二个选项,导出到桌面,此时桌面上会多一个文件:FiddlerRoot.cer,如图。
四、导入到firefox浏览器
1.打开右上角浏览器设置》选项》高级》证书》查看证书》证书机构》导入
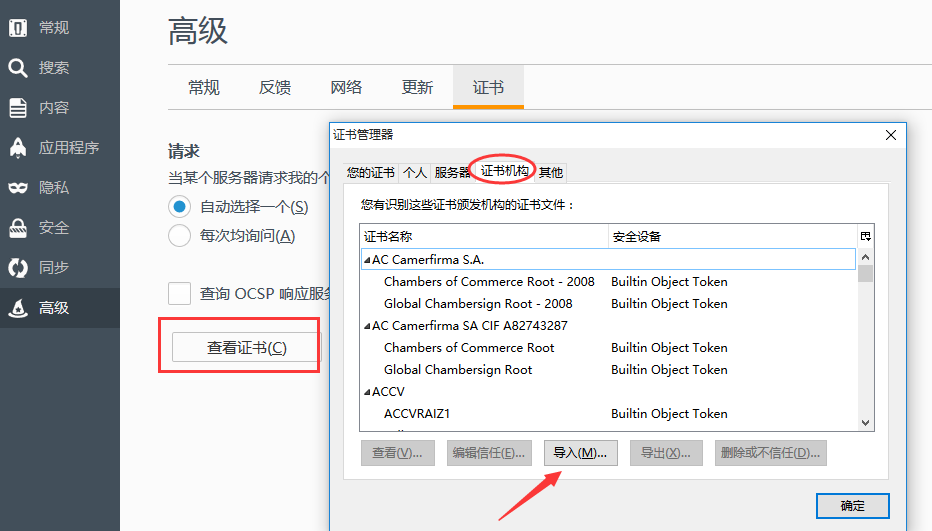
2.勾选文件导入
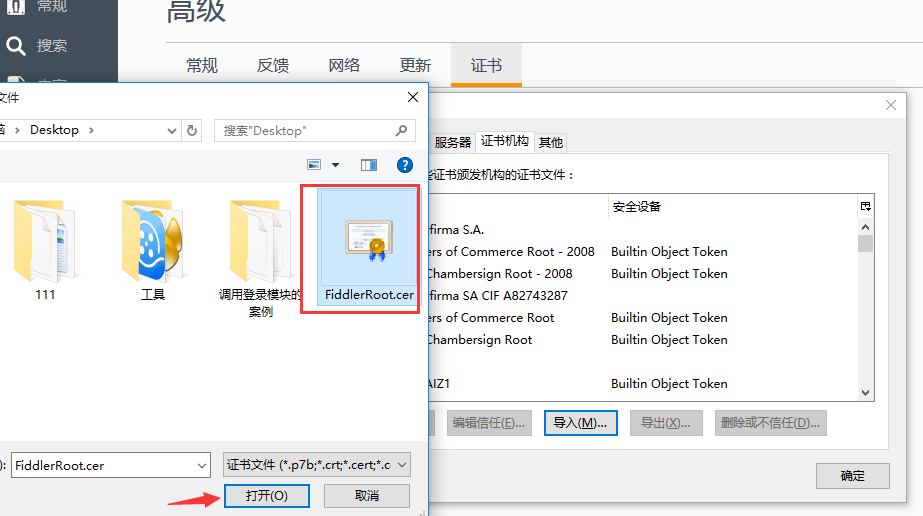
3.打开文件后,会弹出个框,勾选三个选项就完成操作啦。
如果还不能成功,那就重启浏览器,重启电脑了。
证书导出失败问题
前言
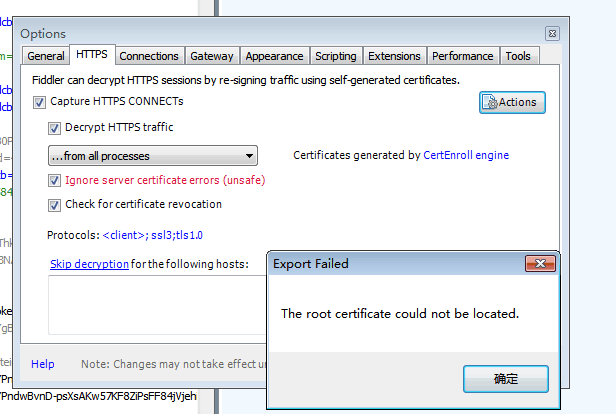
在点Actions时候出现Export Failed:The root certificate could not be located.最近有很多小伙伴在fiddler导出证书的时候,遇到无法导出的问题,收集了几种解决办法,供参考。
一、证书无法导出
1.在点Actions时候出现Export Failed:The root certificate could not be located.
二、无法导出问题解决方案
1.首先确保安装的 Fiddler 是较新的版本,先关闭fiddler
2.下载并安装Fiddler证书生成器
下载地址:http://www.telerik.com/docs/default-source/fiddler/addons/fiddlercertmaker.exe?sfvrsn=2
3.点Tools>Fiddler Options
4.勾选Capture HTTPS traffic
5.点Actions按钮,Export Root Certificate Desktop按钮导出到桌面
三、删除证书
1.有些小伙伴可能之前装过一些fiddler证书,安装的姿势不对,导致新的证书不起作用,这时候需要先删掉之前的证书了
方法一:从fiddler里打开证书管理界面
方法二、从文件管理器输入:certmgr.msc并回车
2.搜索之前安装的fiddler证书,找到之后全部删除
3.重新下载证书生成器:http://www.telerik.com/docs/default-source/fiddler/addons/fiddlercertmaker.exe?sfvrsn=2
一路傻瓜式安装,遇到警告什么的直接忽略就行。
4.安装好证书后,按照1.1章节Fiddler抓包1-抓firefox上https请求的浏览器导入证书就行了(弄好之后,重启电脑就OK了)
只抓APP的请求
前言
fiddler在抓手机app的请求时候,通常也会抓到来自PC的请求,导致会话消息太多,那么如何把来自pc的请求过滤掉,只抓来自APP的请求呢?
必备环境:
1.电脑上已装fiddler
2.手机和电脑在同一局域网
设置
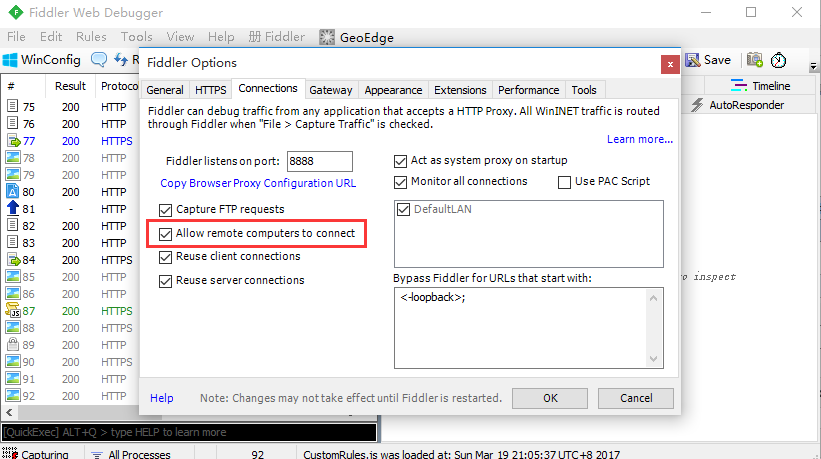
1.fiddler>Tools>Fiddler Options>Connections 勾选Allow remote computers to connect。
2.记住这里的端口号:8888,后面会用到。
查看电脑IP
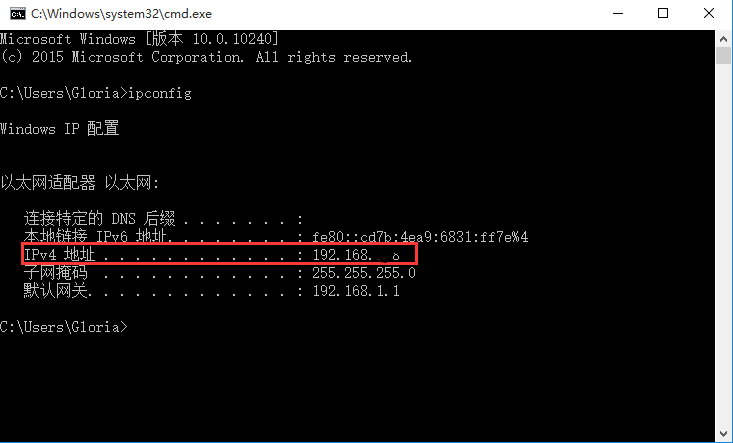
1.打开cmd,输入:ipconfig,记住这个IPv4地址。
ipconfig
设置代理
1.手机设置->WLAN设置->选择该wifi,点右边的箭头(有的手机是长按弹出选项框)。
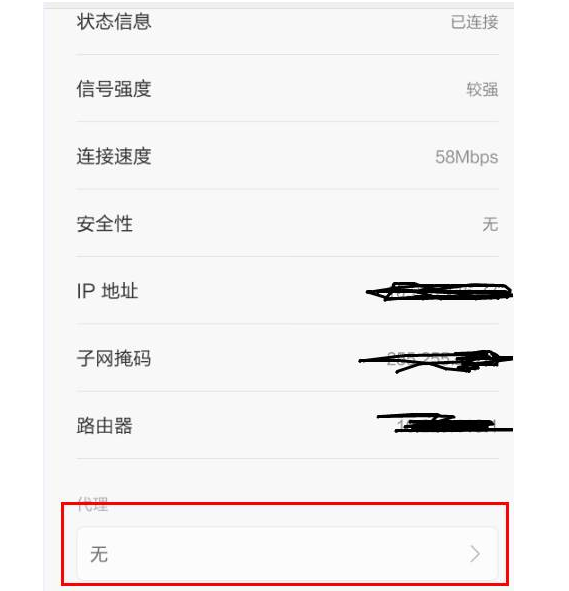
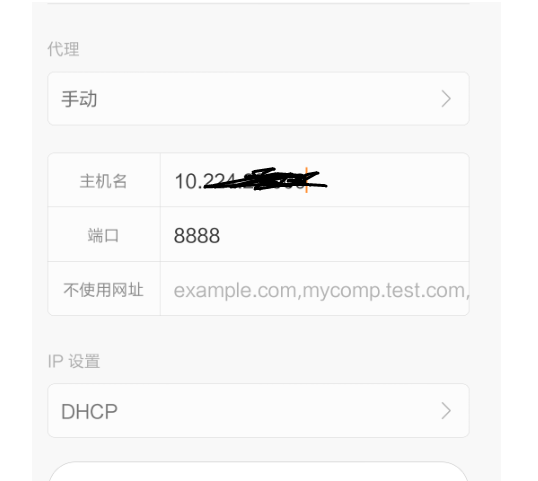
2.选择修改网络配置:
配置主机名:与主机电脑IP地址保持一致
端口号:8888
3.保存后就可以抓到来自手机的请求了。
抓APP上的HTTPS请求
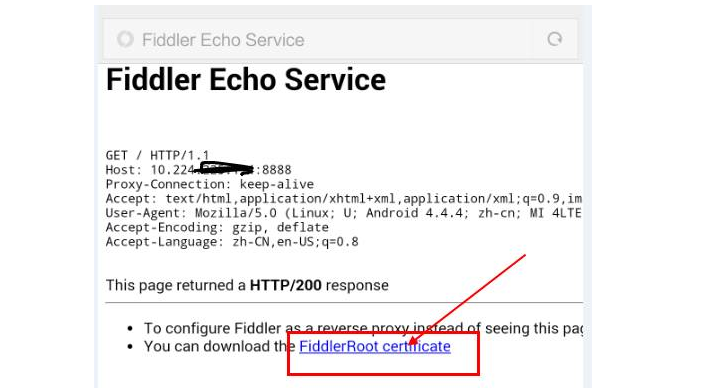
1.如果app都是http请求,是不需要安装证书,能直接抓到的,如果是https请求,这时候手机就需要下载证书了。
2.打开手机浏览器输入:http://10.224.xx.xx:8888 ,这个中间的host地址就是前面查到的本机地址。
3.出现如下画面,点箭头所指的位置,点击安装就可以了。
设置过滤
1.手机上设置代理后,这时候fiddler上抓到的是pc和app所有的请求,如果pc上打开网址,会很多,这时候就需要开启过滤功能了。
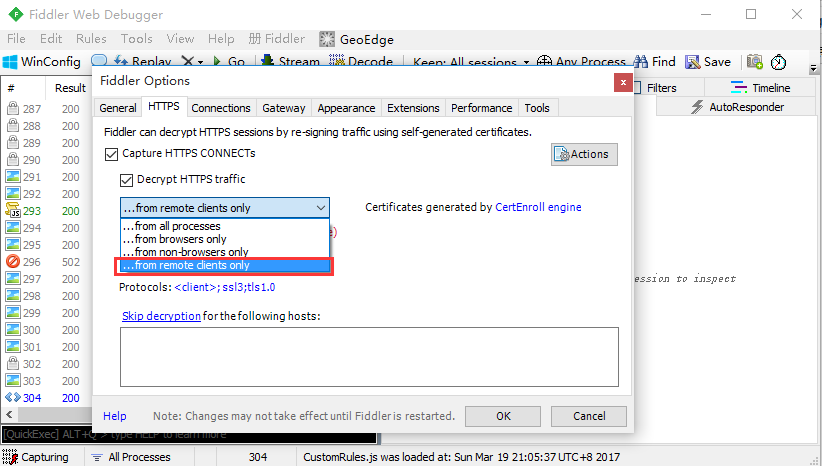
2.打开fiddler>Tools>Fiddler Options>HTTPS>…from remote clients only,勾选这个选项就可以了
- from all processes :抓所有的请求
- from browsers only :只抓浏览器的请求
- from non-browsers only :只抓非浏览器的请求
- from remote clients only:只抓远程客户端请求
(注意:如果手机设置代理后,测完之后记得恢复原样,要不然手机无法正常上网。)
查看get与post请求
前言
前面两篇关于Fiddler抓包的一些基本配置,配置完之后就可以抓到我们想要的数据了,接下来就是如何去分析这些数据。
本篇以博客园的请求为例,简单分析get与post数据有何不一样,以后也能分辨出哪些是get,哪些是post了。
get请求
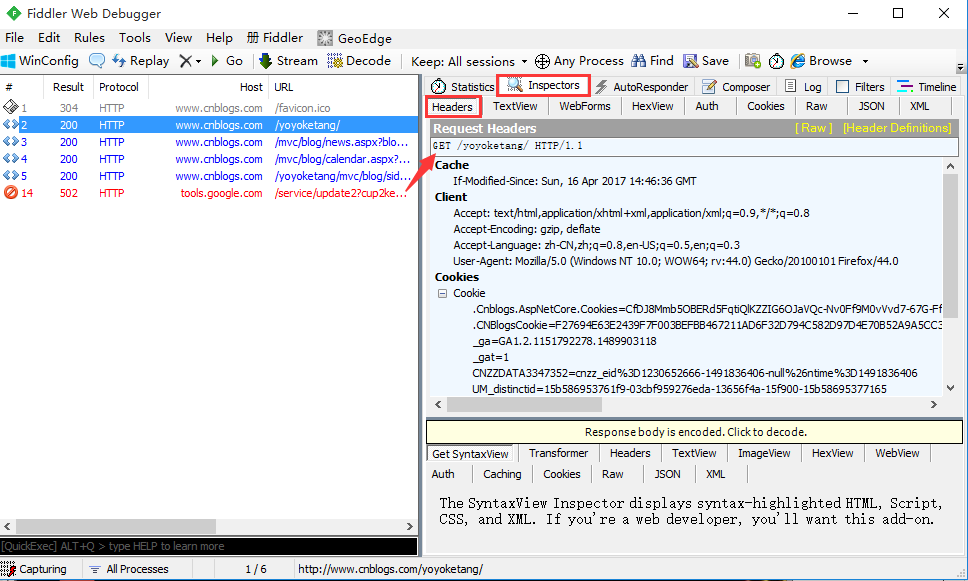
1.打开fiddler工具,然后浏览器输入博客首页地址:http://www.cnblogs.com/yoyoketang/
2.点开右侧Inspectors下的Headers区域,查看Request Headers
3.Request Headers区域里面的就是请求头信息,可以看到打开博客园首页的是get请求
post请求
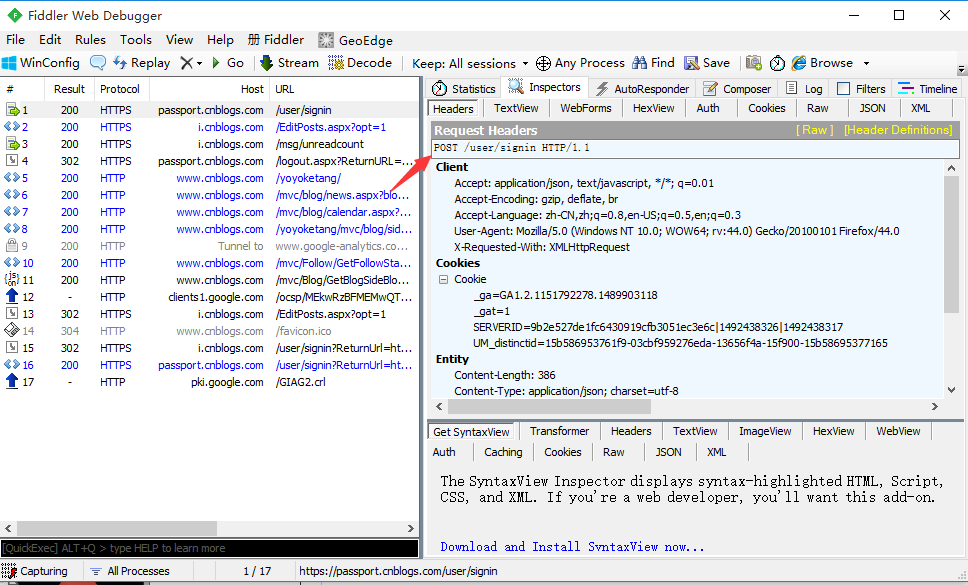
1.打开登录首页:https://passport.cnblogs.com/user/signin
2.输入账号和密码登录成功后,查看fiddler抓包的请求头信息,可以看出是post请求
如何找出需要的请求
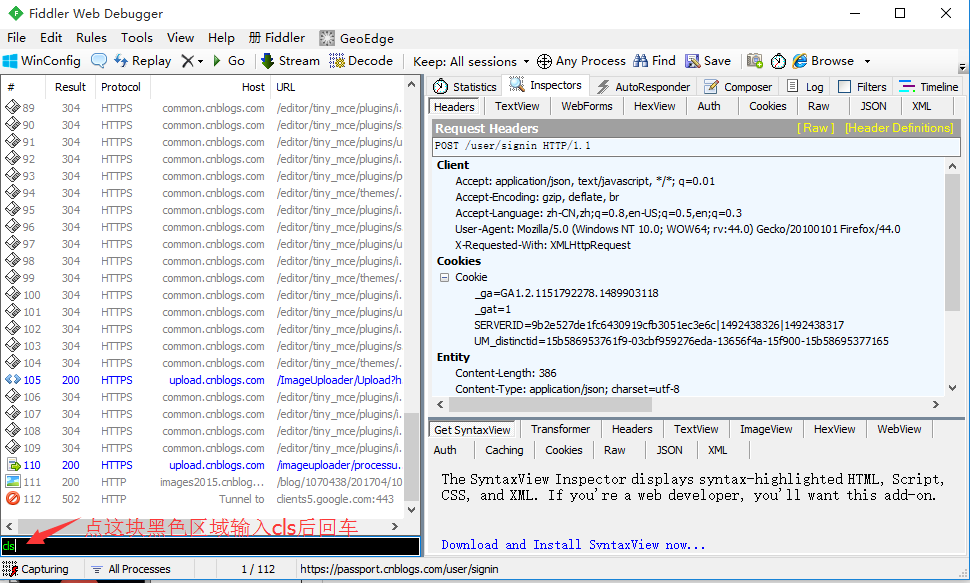
1.打开fiddler后,左边会话框区域刷刷刷的很多请求,那么如何有效的找出自己需要的请求呢?
2.首先第一步:清屏(cls),在左下角命令行输入cls,清空屏幕
(清屏也可以使用快捷键Ctrl+X)
3.第二步在浏览器输入url地址的时候,记住这个地址,如打开博客首页:http://www.cnblogs.com/yoyoketang/
在点击登录按钮的时候,不要做多余的操作了,然后查看fiddler会话框,这时候有好几个请求。
4.如上图,红色框框这个地方就是host地址,红色圈圈地方就是url的路径(yoyoketang),也就是博客首页的地址了,那这个请求就是博客首页的请求了。
get和post请求参数区别
1.关于get和post的功能上区别就不说了,大家自己查资料,这里主要从fiddler抓包的层面查看请求参数上的区别
2.get请求的Raw参数查看,主要分三部分:
- 第1部分是请求url地址
- 第2部分是host地址
- 第3部分是请求头部信息header
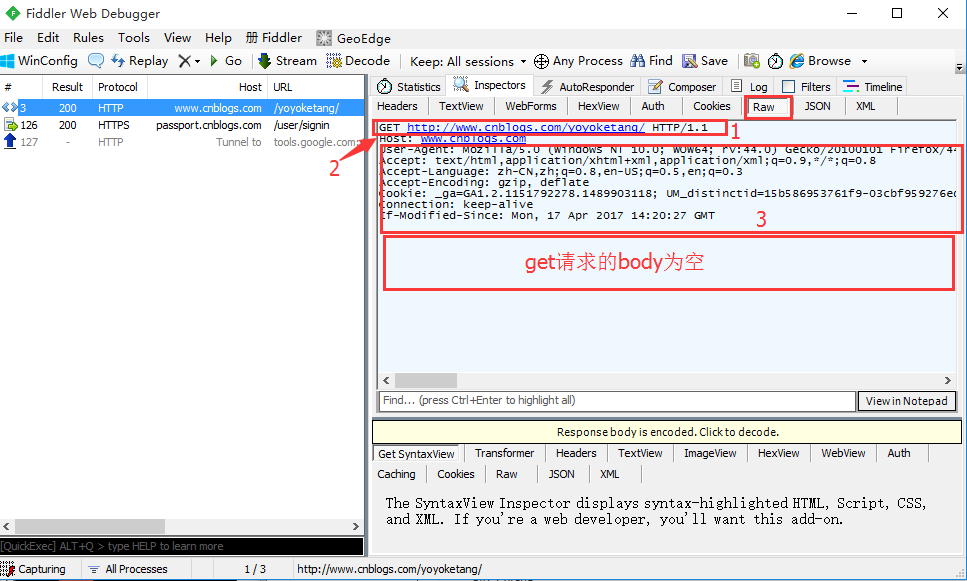
3.再查看博客登录请求的Raw信息,post的信息分四部分。
–前面3块内容都一样,第3部分和第4部分中间会空一行
–第4部分内容就是post请求的请求body(get请求是没body的)
工具介绍(request和response)
前言
本篇简单的介绍下fiddler界面的几块区域,以及各自区域到底是干什么用的,以便于更好的掌握这个工具
工具简介
- 第一块区域是设置菜单,这个前面3篇都有介绍
- 第二块区域是一些快捷菜单,可以点下快捷功能键
- 第三块左边是抓捕的请求会话列表,每一个请求就是一个会话
- 第四块右边上方区域是request请求的详细信息,可以查看Headers、Cookies、Raw、JSON等
- 第五块右边下方区域就是response信息,可以查看服务端返回的json数据或其它信息
- 第六块区域左下角黑色的那块小地方,虽然很不起眼,容易被忽略掉,这地方是命令行模式,可以输入简单的指令如:cls,执行清屏的作用等
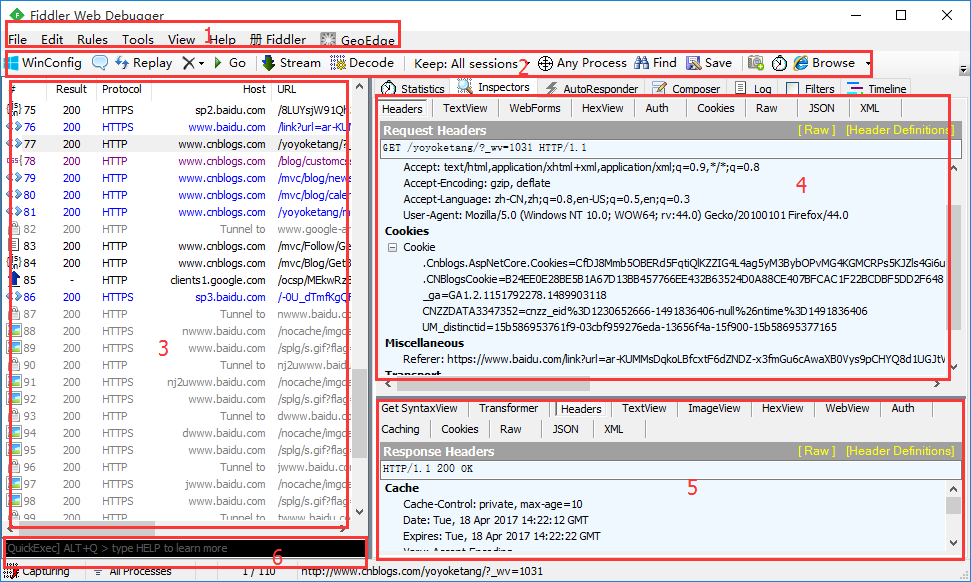
会话框
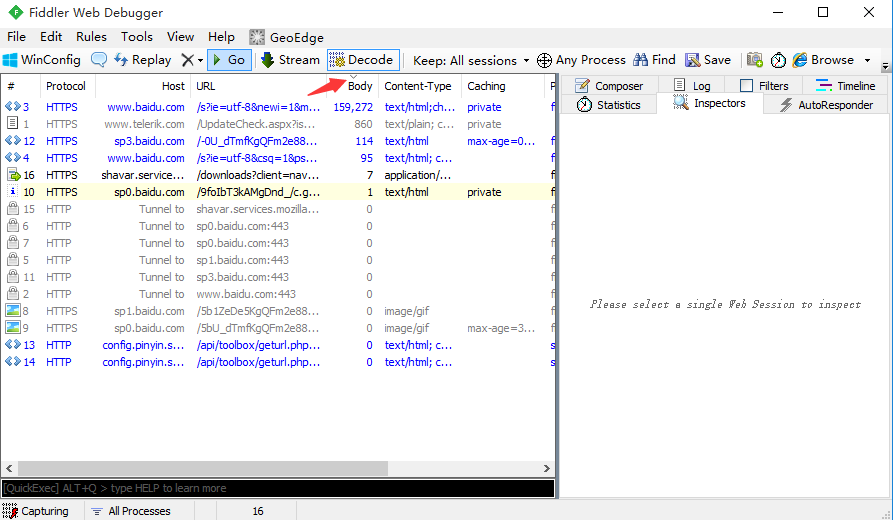
1.会话框主要查看请求的一些请求的一些基本信息,如# 、result、protocol、host、url、body、 caching、content-type、process
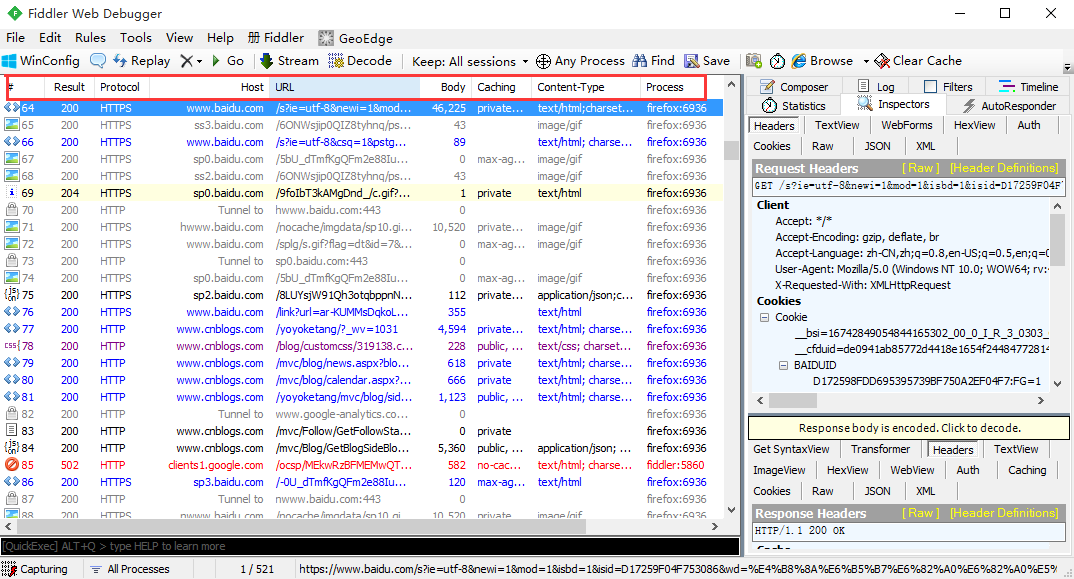
2、会话框列表最左侧,#号这一栏是代表这个请求大概是什么内容,<>这个符号就是我们一般要测试的请求与响应的类型。
3.result:这里是服务器返回的代码,如
- 200,请求ok;2xx一般是服务器接受成功了并处理
- 3xx,重定向相关
- 4xx,404最常见的的就是找不到服务器,一般是请求地址有问题
- 5xx,这个一般是服务器本身的错误
4.protocol:这个是协议类型,如http、https
5.host:主机地址或域名
6.url:请求的路径
7.body:该条请求产生的数据大小
8.caching:缓存相关
9.content-type:连接类型
10.process:客户端类型
Request 和Response
1.Request是客户端发出去的数据,Response是服务端返回过来的数据,这两块区域功能差不多
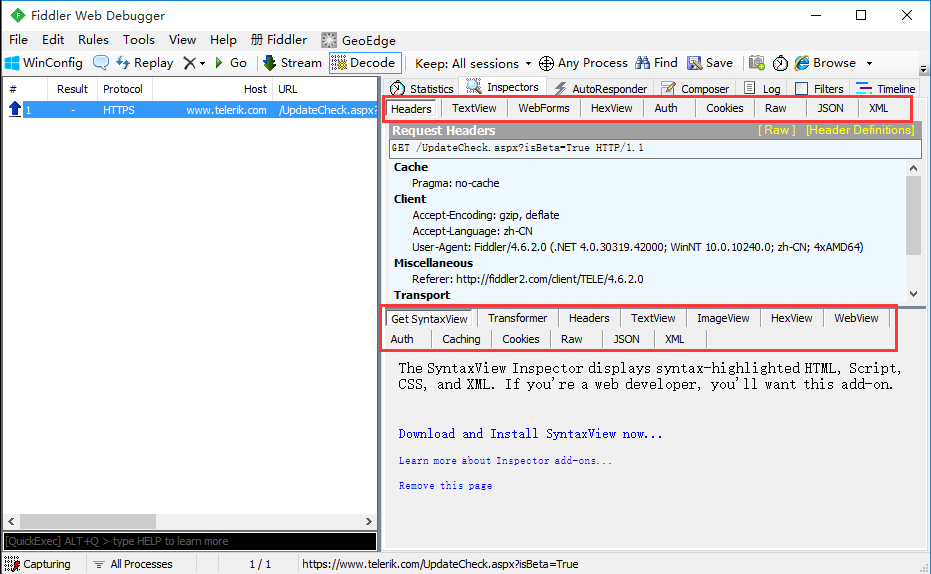
2.headers:请求头,这里包含client、cookies、transport等
3.webfroms:请求参数信息表格展示,更直观。可以直接该区域的参数
4.Auth:授权相关,如果显示如下两行,说明不需要授权,可以不用关注(这个目前很少见了)
- No Proxy-Authorization Header is present.
- No Authorization Headeris present.
5.cookies:查看cookie详情
6.raw:查看一个完整请求的内容,可以直接复制
7.json:查看json数据
8.xml:查看xml文件的信息
decode解码
1.如果response的TextView区域出现乱码情况,可以直接点下方黄色区域解码
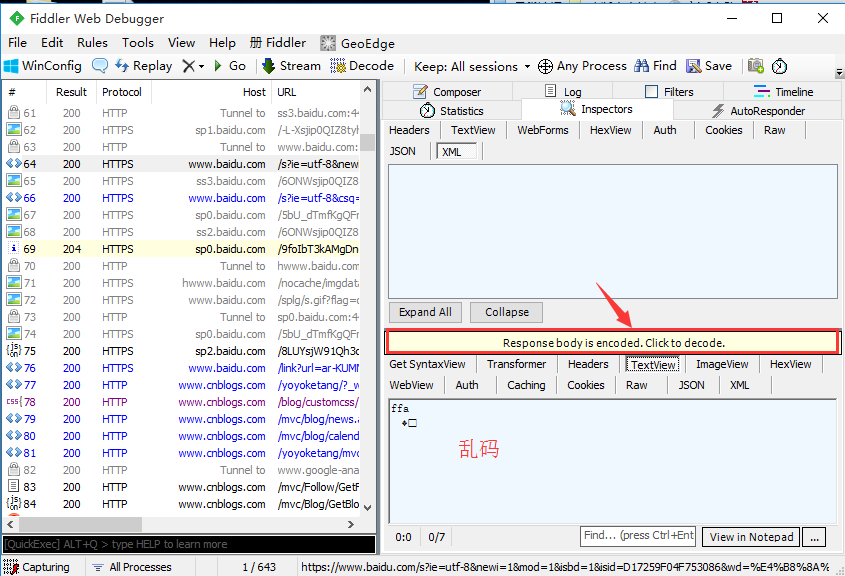
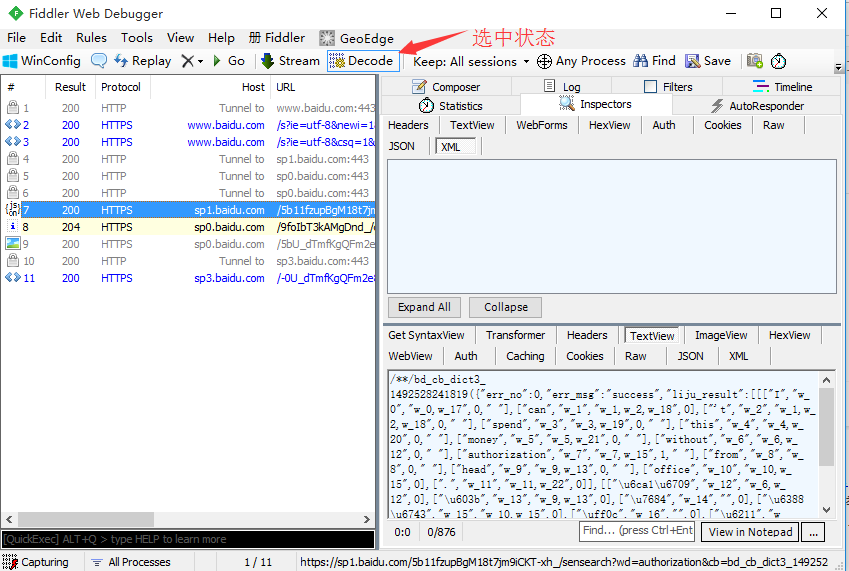
2.也可以选中上方快捷菜单decode,这样后面的请求都会自动解码了
接口测试(Composer)
前言
Fiddler最大的优势在于抓包,我们大部分使用的功能也在抓包的功能上,fiddler做接口测试也是非常方便的。
对应没有接口测试文档的时候,可以直接抓完包后,copy请求参数,修改下就可以了。
Composer简介
点开右侧Composer区域,可以看到如下界面,就是测试接口的界面了
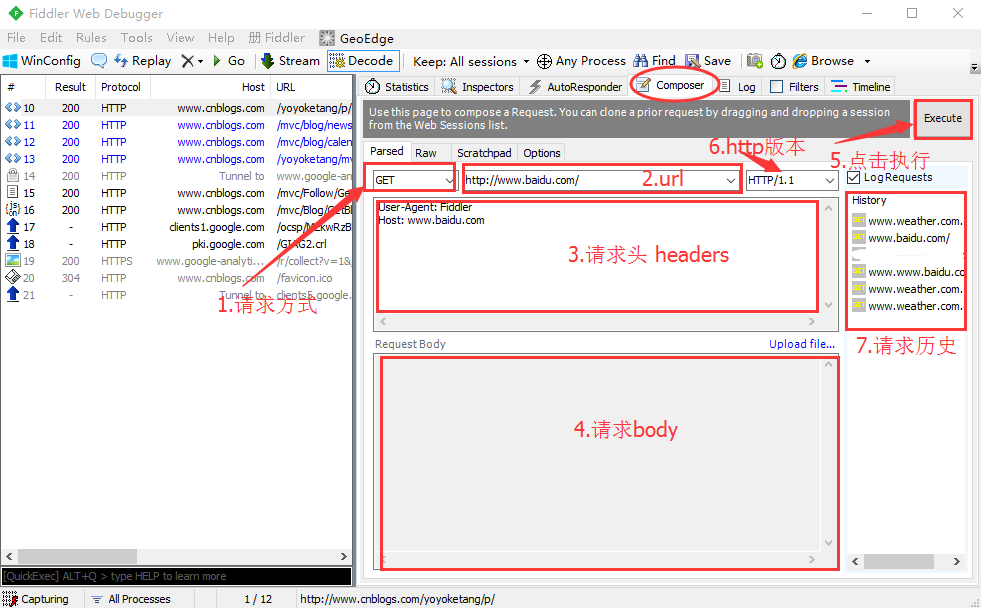
1.请求方式:点开可以勾选请求协议是get、post等
2.url地址栏:输入请求的url地址
3.请求头:第三块区域可以输入请求头信息
4.请求body:post请求在此区域输入body信息
5.执行:Execute按钮点击后就可以执行请求了
6.http版本:可以勾选http版本
7.请求历史:执行完成后会在右侧History区域生成历史记录
模拟get请求
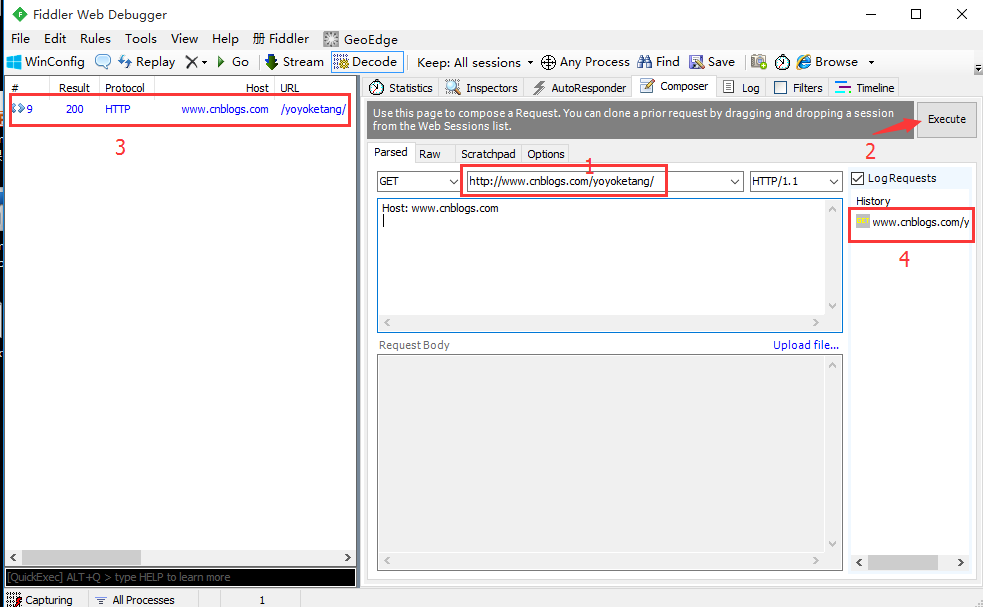
1.在Composer区域地址栏输入博客首页:http://www.cnblogs.com/yoyoketang/
2.选择get请求,点Execute执行,请求就可以发送成功啦
3.请求发送成功后,左边会话框会生成一个会话记录,可以查看抓包详情
4.右侧history区域会多一个历史请求记录
5.会话框选中该记录,查看测试结果:
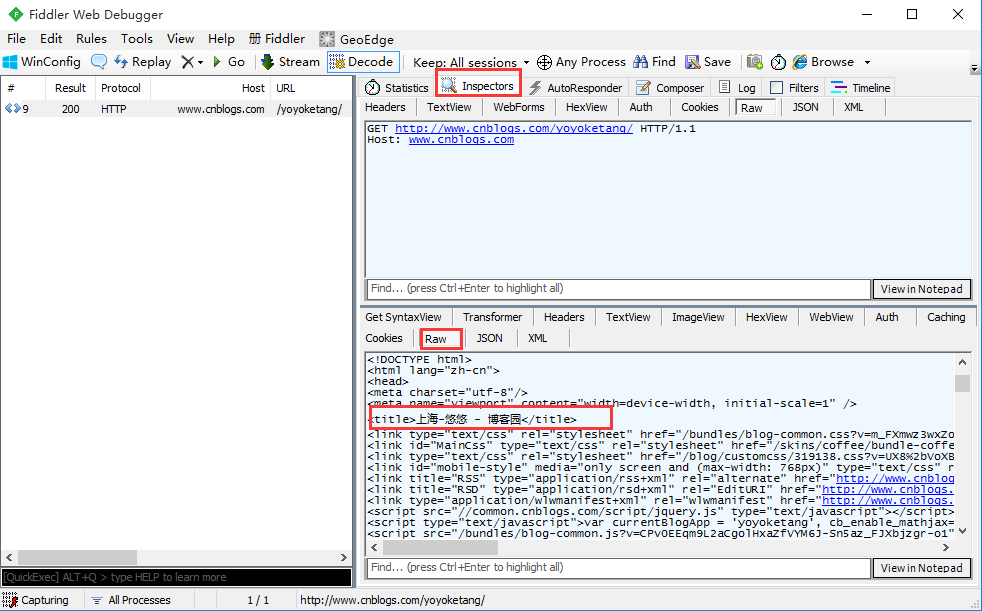
- 选中该会话,点开Inspectors
- response区域点开Raw区域
- Raw查看的是HTML源码的数据
- 也可以点WebView,查看返回的web页面数据
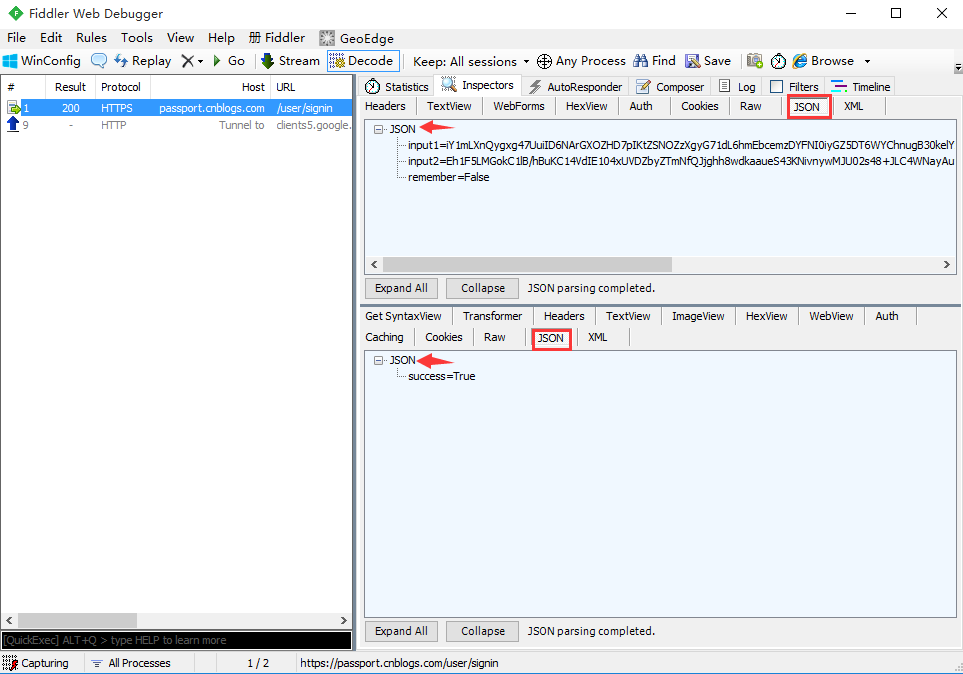
Json数据
1.有些post的请求参数和返回参数是Json格式的,如博客园的登录请求:https://passport.cnblogs.com/user/signin
2.在登录页面手动输入账号和密码,登录成功。
3.找到这个登录成功的会话,查看json数据如下图:
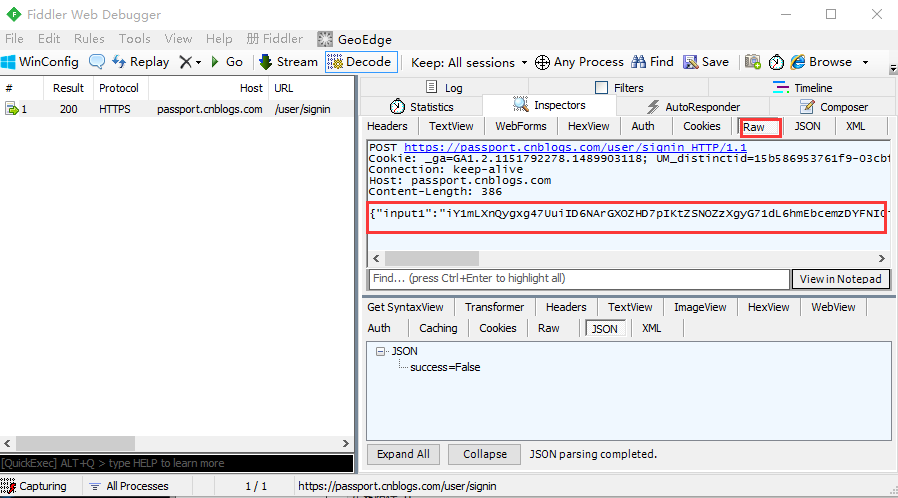
模拟post请求
1.请求类型勾选post
2.url地址栏输入对应的请求地址
3.body区域写登录的json参数,json参数直接copy上一步抓包的数据,如下图红色区域
4.header请求头区域,可以把前面登录成功后的头部抓包的数据copy过来
(注意,有些请求如果请求头为空的话,会请求失败的)
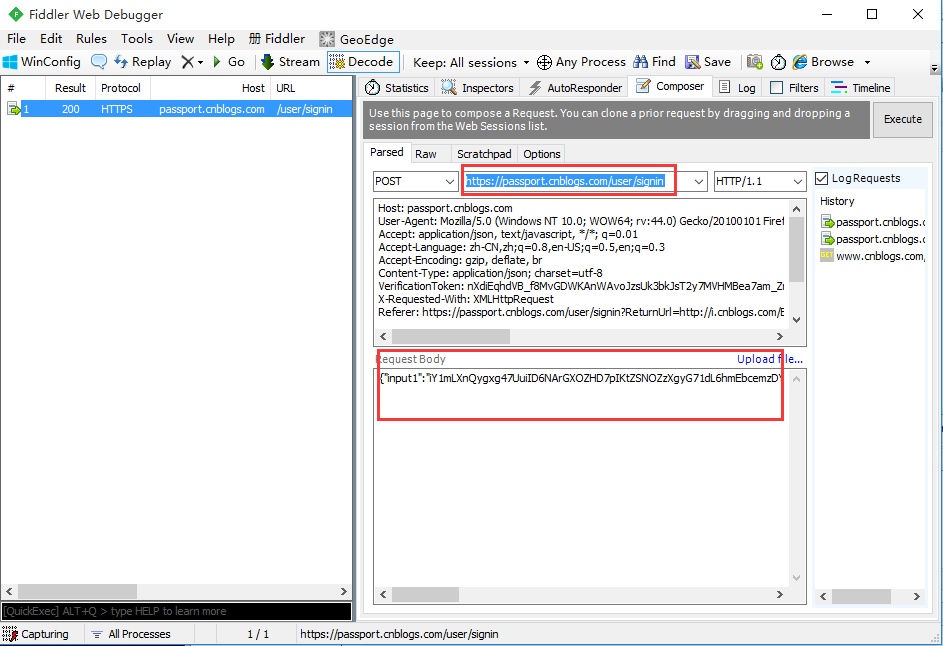
5.执行成功后查看测试结果:
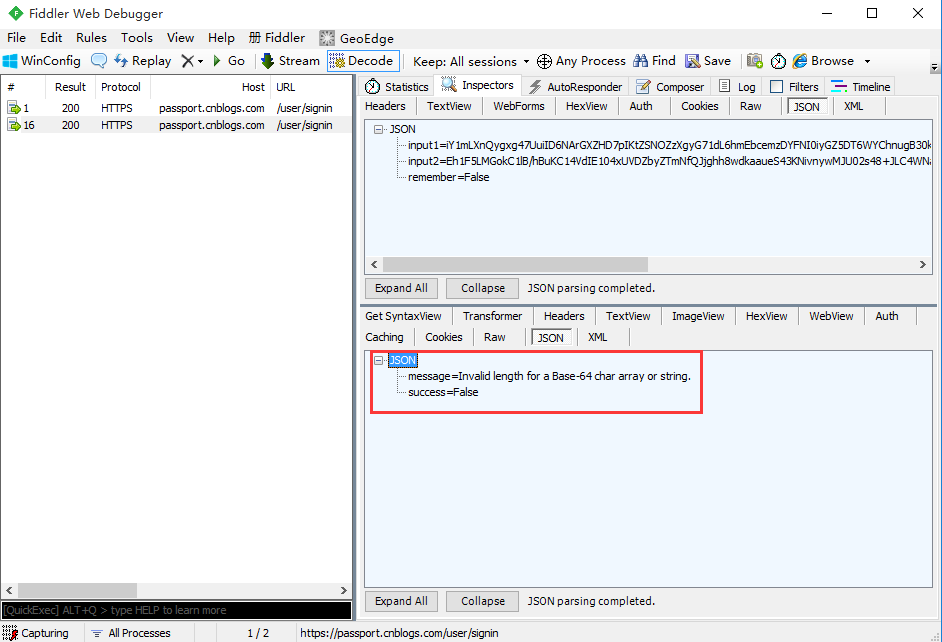
–执行成功如第三所示的图,显示success=True
–执行失败如下图所示,显示
message=Invalid length for a Base-64 char array or string.
success=False
get请求(url详解)
前言
上一篇介绍了Composer的功能,可以模拟get和post请求,get请求有些是不带参数的,这种比较容易,直接放到url地址栏就行。有些get请求会带有参数,本篇详细介绍url地址格式。
url详解
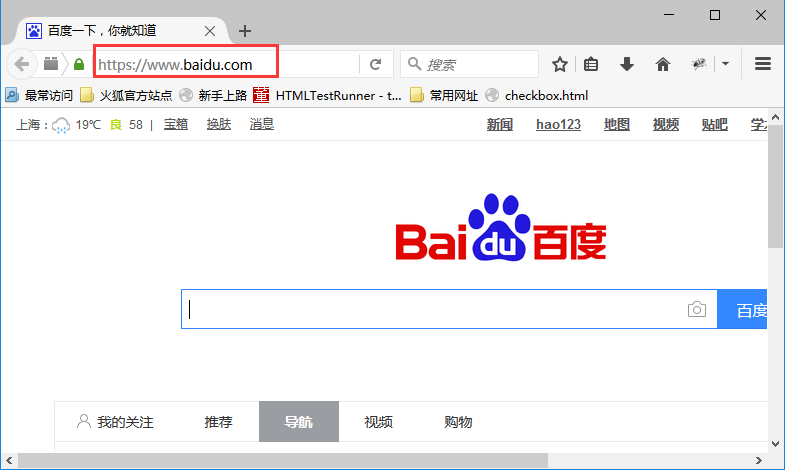
1.url就是我们平常打开百度在地址栏输入的:https://www.baidu.com,如下图,这个是最简单的url地址,打开的是百度的主页
2.再看一个稍微复杂一点的url,在百度输入框输入:上海悠悠博客园
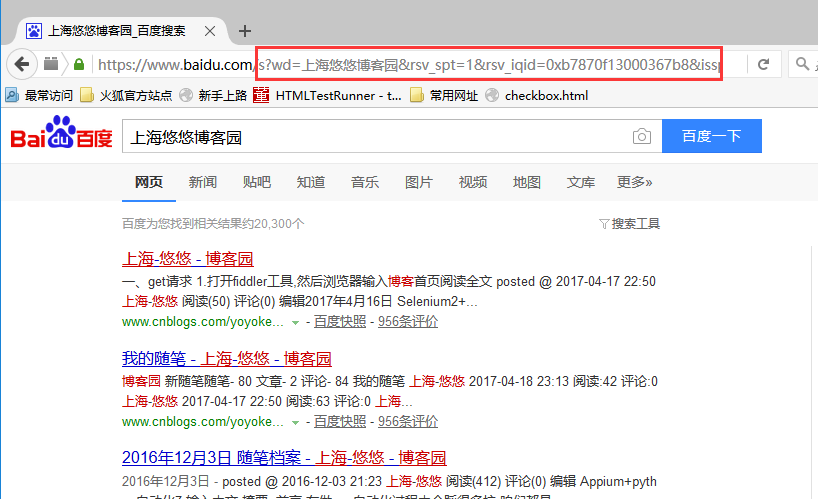
3.查看url地址栏,对比之前的百度首页url地址,后面多了很多参数。当然最主要的参数是:wd=上海悠悠博客园(后面的一大串可以暂时忽略)。
4.那么问题来了,这些参数有什么作用呢?
可以做个简单的对比,在地址栏分别输入:
https://www.baidu.com
https://www.baidu.com/s?wd=上海悠悠博客园
对比打开的页面有什么不一样,现在知道作用了吧,也就是说这个多的”/s?wd=上海悠悠博客园”就是搜索的结果页面
url解析
1.以”https://www.baidu.com/s?wd=上海悠悠博客园”这个url请求的抓包为例
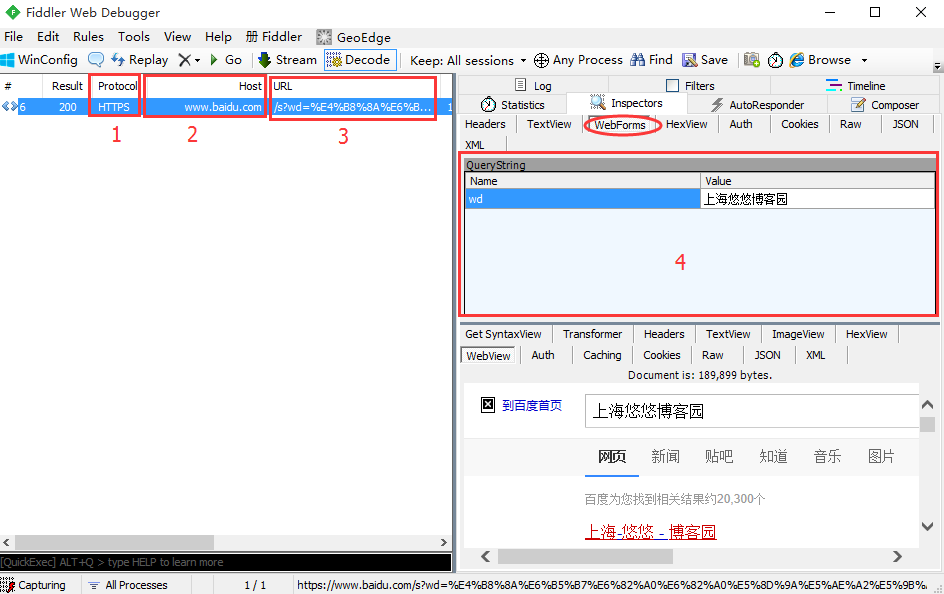
2.那么一个完整的url地址,基本格式如下:
https://host:port/path?xxx=aaa&ooo=bbb
- http/https:这个是协议类型,如图中所示
- host:服务器的IP地址或者域名,如图中2所示
- port:HTTP服务器的默认端口是80,这种情况下端口号可以省略。
如果使用了别的端口,必须指明,例如:192.168.3.111:8080,这里的8080就是端口 - path:访问资源的路径,如图中3所示/s (图中3是把path和请求参数放一起了)
- ?:url里面的?这个符号是个分割线,用来区分问号前面的是path,问号后面的是参数
- url-params:问号后面的是请求参数,格式:xxx=aaa,如图4区域就是请求参数
- &:多个参数用&符号连接
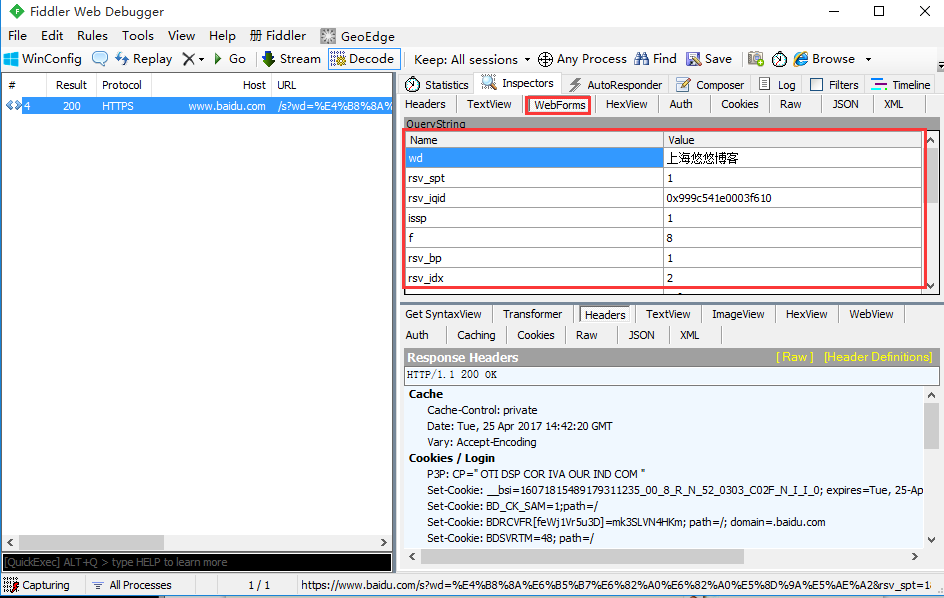
请求参数(params)
1.在url里面请求参数一般叫params,但是我们在fiddler抓包工具看到的参数是:QueryString
2.QueryString是像服务端提交的参数,其实跟params是一个意思,每个参数对应的都有name和value值
3.多个参数情况如下:
UrlEncode编码
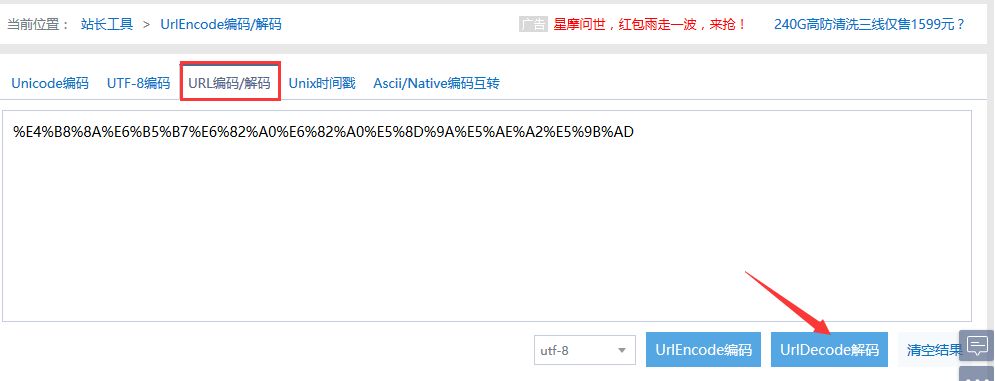
1.如果url地址的参数带有中文的,一般在url里面会是这样的,如第二点里的wd=%E4%B8%8A%E6%B5%B7%E6%…
像看到%E4这种编码的就是经过url编码过的,需要解码就能看到是什么中文了
2.用urlencode在线编码/解码工具,地址:http://tool.chinaz.com/tools/urlencode.aspx
post请求(body)
前言上一篇讲过get请求的参数都在url里,post的请求相对于get请求多了个body部分,本篇就详细讲解下body部分参数的几种形式。
注意:post请求的参数可以放在url,也可以放在body,也可以同时放在url和body,当然post请求也可以不带参数。
只是一般来说,post请求的参数习惯放到body部分
body数据类型
常见的post提交数据类型有四种:
1.第一种:application/json:这是最常见的json格式,也是非常友好的深受小伙伴喜欢的一种,如下
{
“input1”:”xxx”,”input2”:”ooo”,”remember”:false}
2.第二种:application/x-www-form-urlencoded:浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数
input1=xxx&input2=ooo&remember=false
3.第三种:multipart/form-data:这一种是表单格式的,数据类型如下:
WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data;
name=”file”;
filename=”chrome.png”
Content-Type: image/png PNG
content of chrome.png
WebKitFormBoundaryrGKCBY7qhFd3TrwA
4.第四种:text/xml:这种直接传的xml格式
<!--?xml version="1.0"?-->
<methodcall>
<methodname>examples.getStateName</methodname>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params>
</methodcall>
json格式
1.打开博客园的登录页面,输入账号密码后抓包,查看post提交数据,点开Raw查看整个请求的原始数据
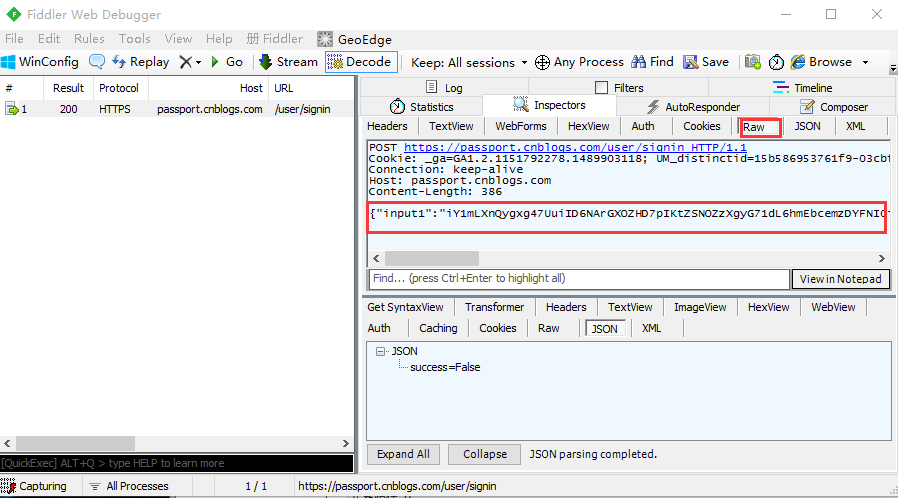
2.前面讲过post的请求多一个body部分,上图红色区域就是博客园登录接口的body部分,很明显这种格式是前面讲到的第一种json格式
3.查看json格式的树状结构,更友好,可以点开JSON菜单项
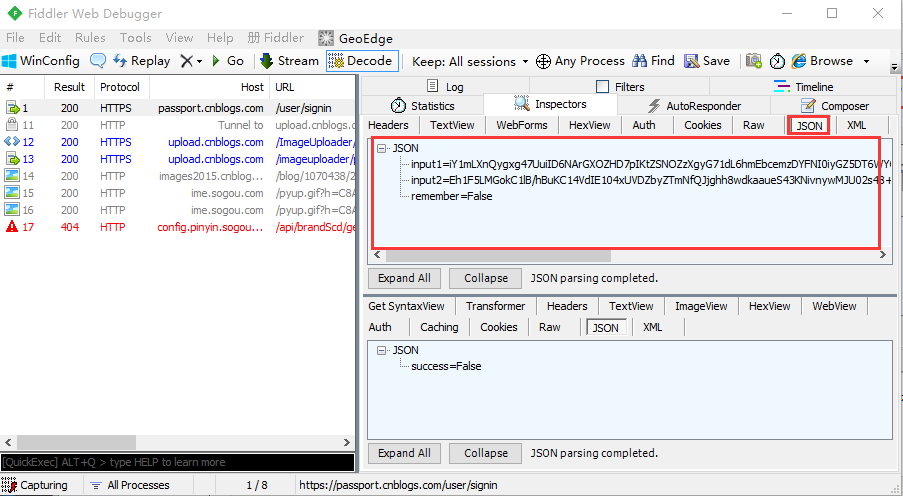
4.查看这里的json数据,很明显传了三个参数:
- input1:这个是登录的账号参数(加密过)
- input2:这个是登录的密码参数(加密过)
- remember:这个是登录页面的勾选是否记住密码的选项,False是不记住,True是记住
x-www-form-urlencoded
1.登录博客园后,打开新随笔,随便写一个标题和一个正文后保存,抓包数据如下
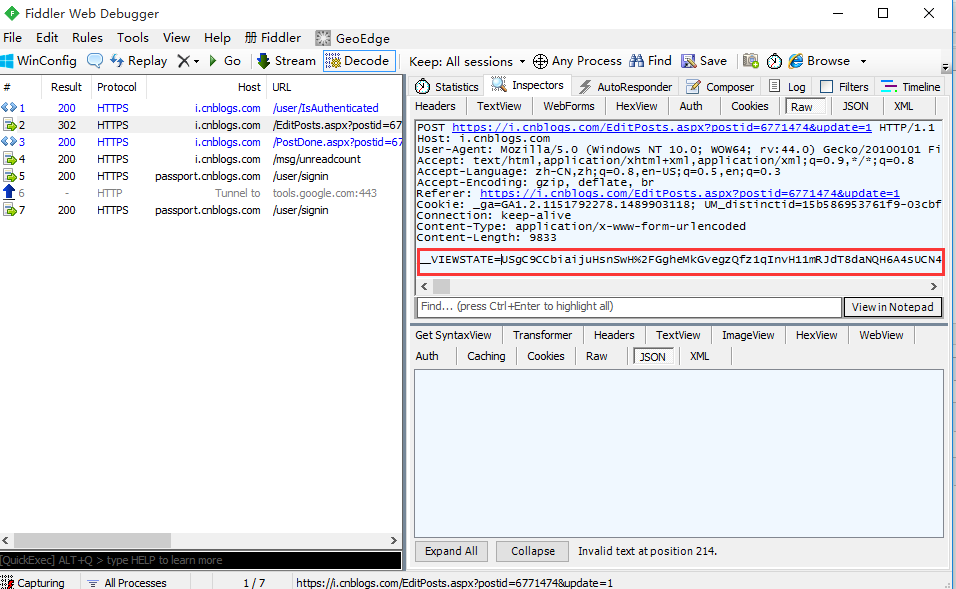
2.如上图的这种格式,很明显就属于第二种了,这种类型的数据查看,在WebFrom里面查看了
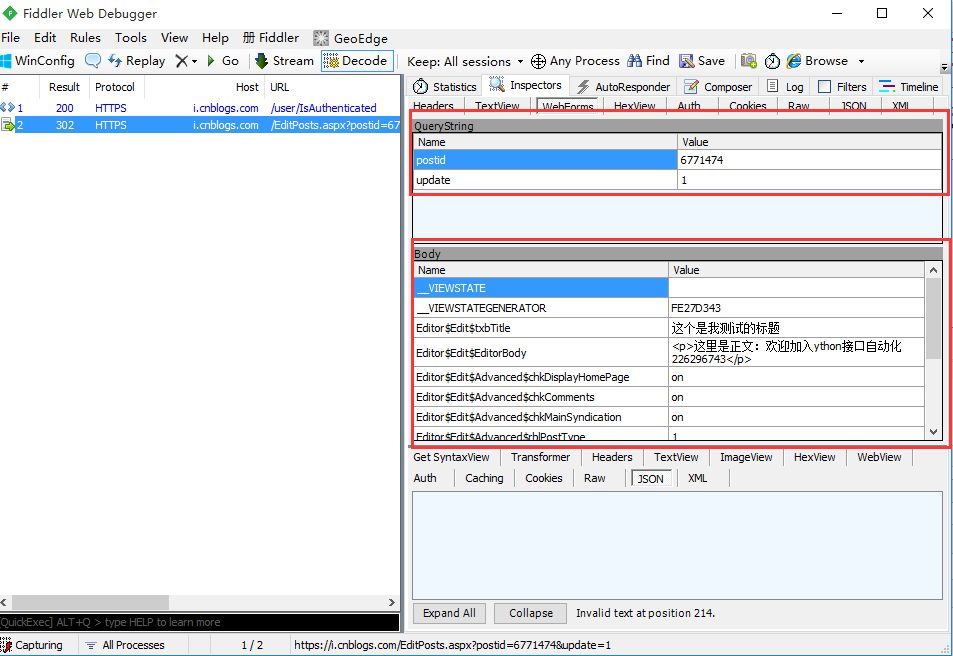
3.上面红色框框的Query String是url里面的参数,下面红色框框的body部分就是这次post提交的body参数部分了。
WebFrom
1.为什么登录请求的WebFrom的body部分为空呢?
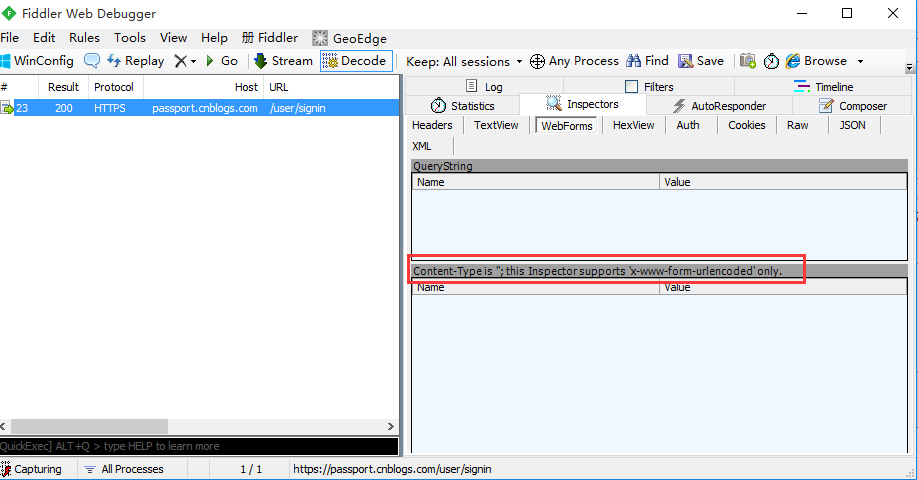
2.看上图红色框框的显示:这里只支持application/x-www-form-urlencoded这种格式的body参数,也就是说json格式的,需要在JOSN这一栏查看了。
打断点(bpu)
前言
先给大家讲一则小故事,在我们很小的时候是没有手机的,那时候跟女神聊天都靠小纸条。某屌丝A男对隔壁小王的隔壁女神C倾慕已久,于是天天小纸条骚扰,无奈中间隔着一个小王,这样小王就负责传小纸条了。有一天小王忍不住偷偷打开A男表白的纸条,把里面内容改了下,改成了:我的同桌小王喜欢你。最后女神C和小王走在了一起。。。这是一个悲伤的故事!
断点
1.为什么要打断点呢?
比如一个购买的金额输入框,输入框前端做了限制100-1000,那么我们测试的时候,需要测试小于100的情况下。很显然前端只能输入大于100的。这是我们可以先抓到接口,修改请求参数,绕过前端,传一个小于100的数,检查服务端的功能是否OK。
也就是说接口测试其实是不需要管前端的,主要测后端的功能。Fiddler作为代理服务器的作用其实就相当于上面故事里面的小王,传纸条的作用,Fiddler(小王)修改了请求参数(小纸条),是为了验证服务端功能(女神C)。
2.Fiddler可以修改以下请求
- Fiddler设置断点,可以修改HTTP请求头信息,如修改Cookie,User-Agent等
- 可以修改请求数据,突破表单限制,提交任意数字,如充值最大100,可以修改成10000
- 拦截响应数据,修改响应体,如修改服务端返回的页面数据
断点的两种方式
1.before response:这个是打在request请求的时候,未到达服务器之前
–屌丝A传给小王的时候,小王在这个时候拦截了小纸条,未传给女神C
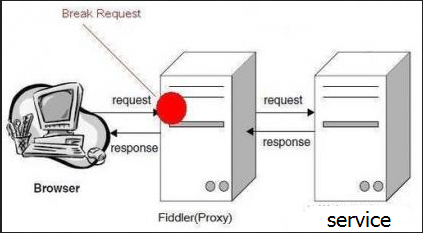
2.after response:也就是服务器响应之后,在Fiddler将响应传回给客户端之前。
–女神C回了小纸条,小王拿到后拦截了,未传给屌丝A
全局断点
1.全局断点就是中断fiddler捕获的所有请求,先设置下,点击rules-> automatic breakpoint ->before requests
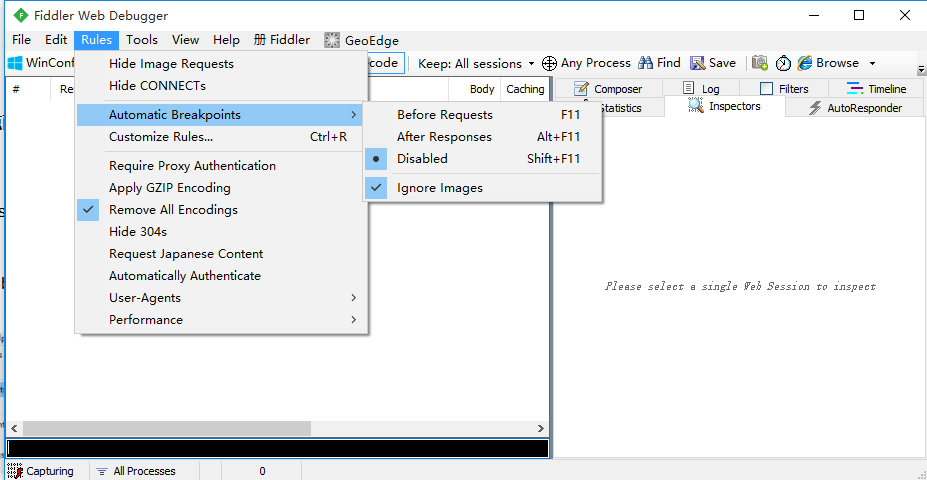
2.选中before requests选项后,打开博客园首页:http://www.cnblogs.com/yoyoketang/,看到如下T的标识,说明断点成功
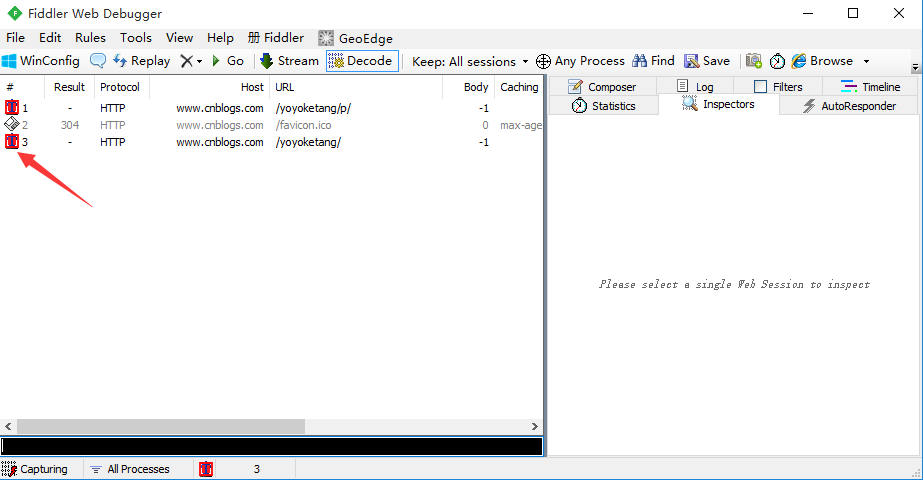
3.打完断点后,会发现所有的请求都无法发出去了,这时候,点下Go按钮,就能走下一步了
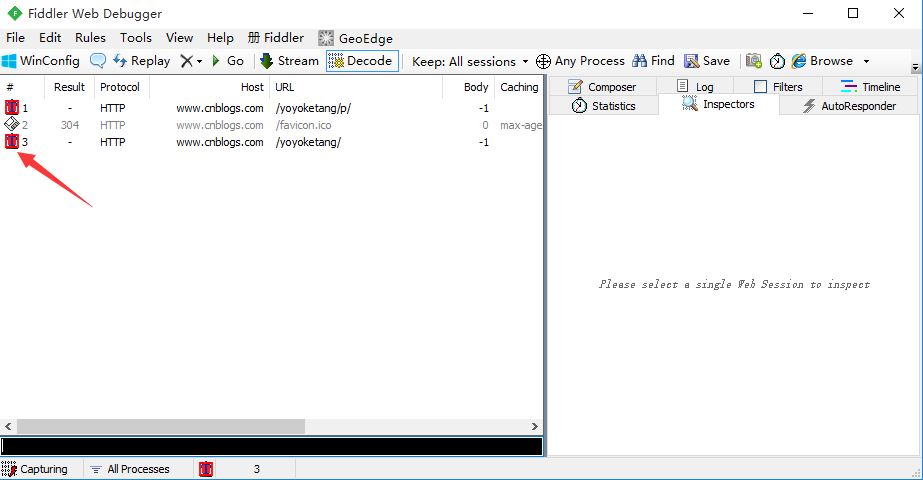
4.找到需要修改的请求后,选中该条会话,右侧打开WebFroms,这时候里面的参数都是可以修改的了
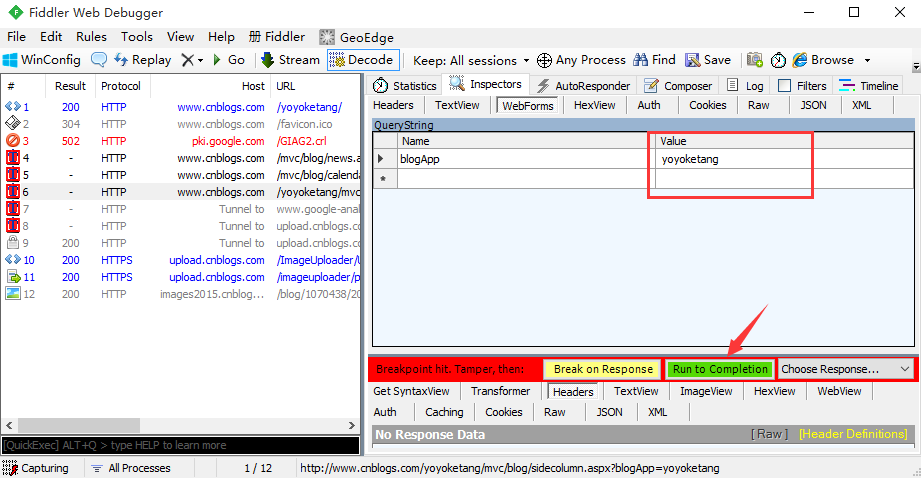
5.修改之后点Run to Completion就能提交了,于是就成功修改了请求参数了
6.打全局断点的话,是无法正常上网的,需要清除断点:rules-> automatic breakpoint ->disabled
单个断点
已经知道了某个接口的请求地址,这时候只需要针对这一条请求打断点调试,在命令行中输入指令就可以了
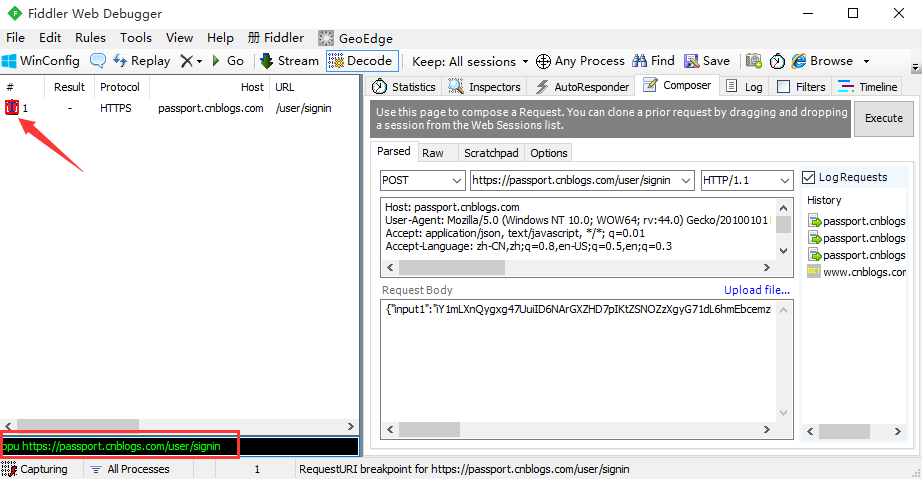
请求前断点(before response): bpu
- 论坛登录接口:https://passport.cnblogs.com/user/signin
- 命令行输入:bpu https://passport.cnblogs.com/user/signin 回车
- 请求登录接口的时候,就会只拦截登录这个接口了,此时可以修改任意请求参数
- 取消断点,在命令行输入: bpu 回车就可以了
响应后断点(after requests): bpafter
-
在命令行输入:bpafter https://passport.cnblogs.com/user/signin 回车
-
登录博客园,会发现已经拦截到登录后服务器返回的数据了,此时可以修改任意返回数据
-
取消断点,在命令行输入: bpafter 回车就可以了
拦截来自某个网站所有请求
1.在命令行输入:bpu www.cnblogs.com
2.打开博客园任意网页,发现都被拦截到了
3.打开博客园其他网站,其它网站可以正常请求
4.说明只拦截了来自部落论坛(www.cnblogs.com)的请求
5.清除输入bpu回车即可
命令行其它相关指令
Bpafter, Bps, bpv, bpm, bpu
这几个命令主要用于批量设置断点
Bpafter xxx: 中断 URL 包含指定字符的全部 session 响应
Bps xxx: 中断 HTTP 响应状态为指定字符的全部 session 响应
Bpv xxx: 中断指定请求方式的全部 session 响应
Bpm xxx: 中断指定请求方式的全部 session 响应 、、同于 bpv xxx
Bpu xxx:与bpafter类似
当这些命令没有加参数时,会清空所有设置了断点的HTTP请求。
更多的其他命令可以参考Fiddler官网手册
(赠言:打断点仅供测试需要,勿走歪门邪道!!!)
会话保存
前言
为什么要保存会话呢?举个很简单的场景,你在上海测试某个功能接口的时候,发现了一个BUG,而开发这个接口的开发人员是北京的一家合作公司。
你这时候给对方开发提bug,如何显得专业一点,能让对方心服口服的接受这个BUG呢?如果只是截图的话,不是很方便,因为要截好几个地方还描述不清楚,不如简单粗暴一点把整个会话保存起来,发给对方。
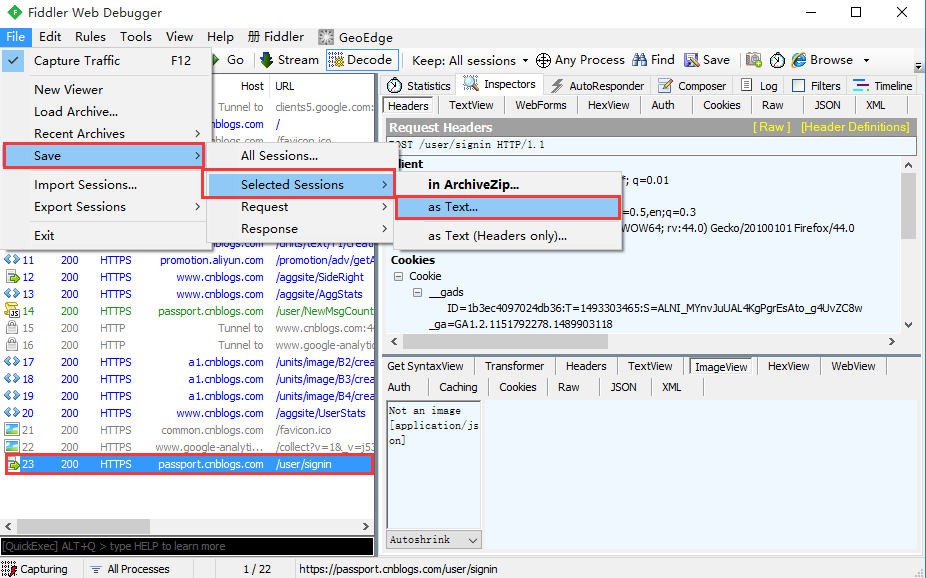
一、保存为文本
- 以博客园登录为例,抓到登录的请求会话
- 点左上角File>Save>Selected Sessions>as Text,保存到电脑上就是文本格式的
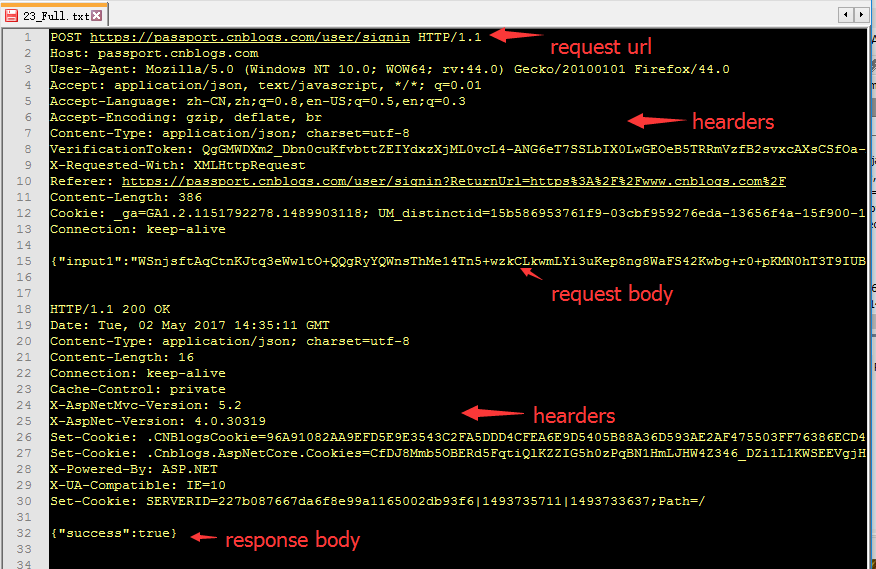
- 文本格式的可以直接打开,结果如下图
几种保存方式
- save-All Sessions :保存所有的会话,saz文件
- save-Selected Session:保存选中的会话
- in ArchiveZIP :保存为saz文件
- as Text :以txt文件形式保存整个会话包括Request和Response
- as Text (Headers only) :仅保存头部
- Request:保存请求
- Entir Request:保存整个请求信息(headers和body)
- Request Body:只保存请求body部分
- Response:保存返回
- Entir Response:保存整个返回信息(headers和body)
- Response Body:只保存返回body部分
- and Open as Local File:保存Response信息,并打开文件
乱码问题(decode)
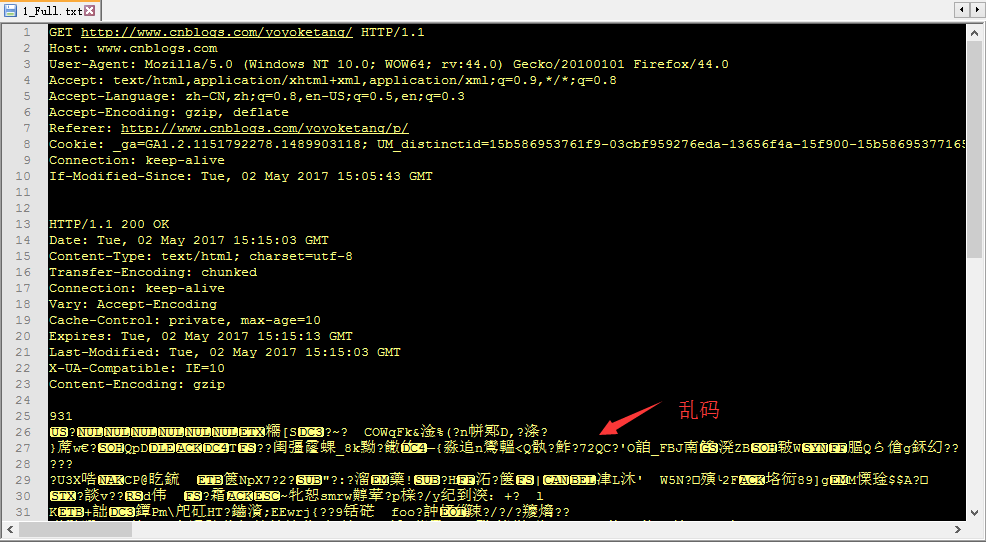
- 遇到这种情况,主要是需要解码,用前面学到的decode方法
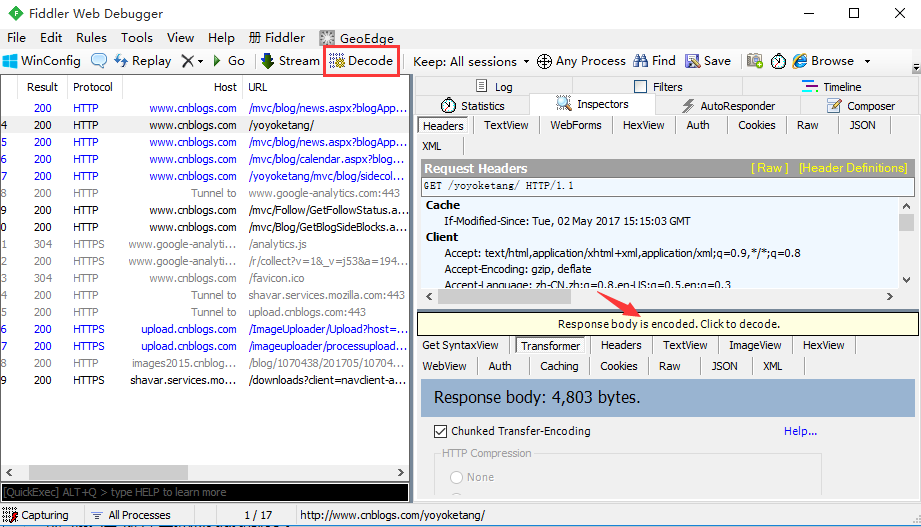
3. 点击箭头区域后,重新保存就没乱码了。
4. 还有一个最简单办法就是选中上图会话框上的decode按钮,这样就自动解码了。
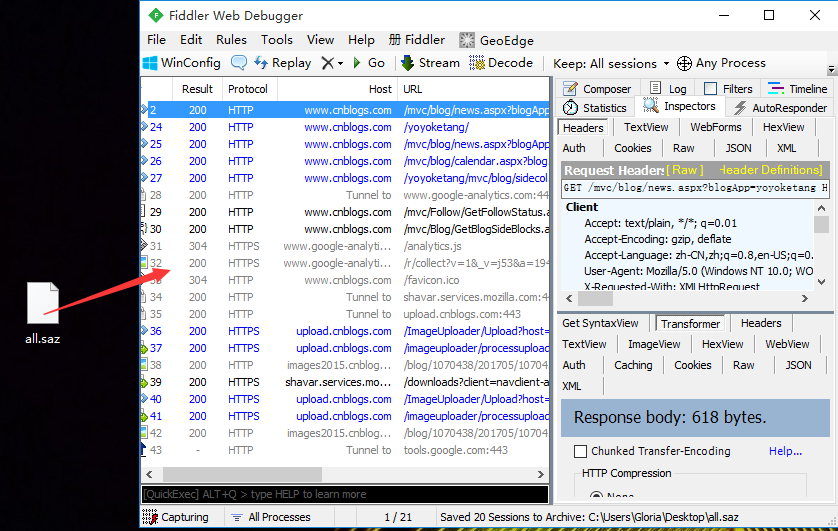
保存与导入全部会话
- 我们可以打开fiddler,操作完博客园后,选中save>All Sessions,保存全部会话
- 保存后,在fiddler打开也很方便,直接把刚才保存的会话按住拽进来就可以了
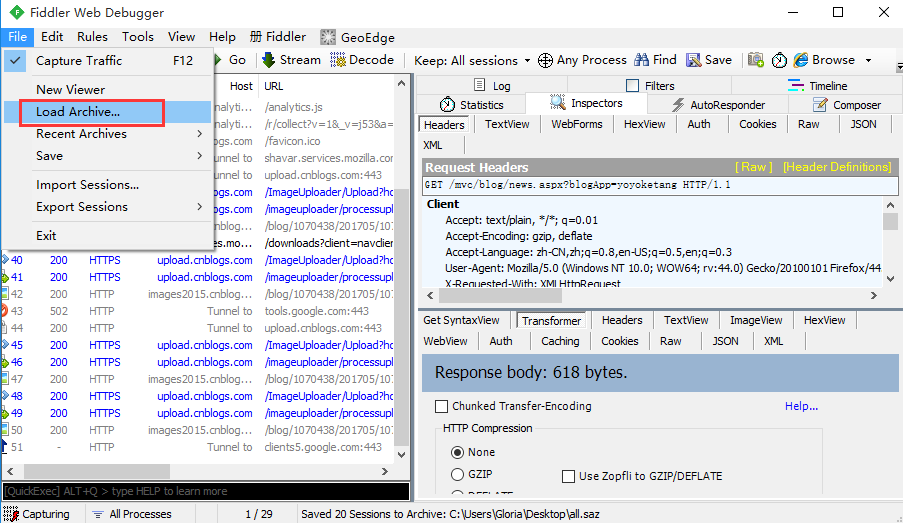
3. 也可以选择File>Load Archive导入这个文件
Repaly
- 导入请求后,可以选中某个请求,点击Repaly按钮,重新发请求
- 也可以ctrl+a全部选中后,点Repaly按钮,一次性批量请求
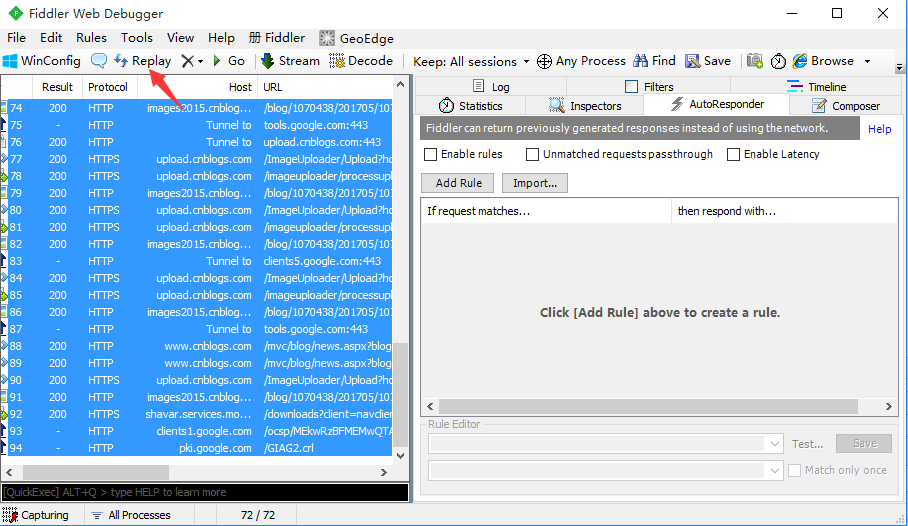
这里保存会话和replay功能其实就是相当于录制和回放了
自定义会话框
前言
在使用fiddler抓包的时候,查看请求类型get和post每次只有点开该请求,在Inspectors才能查看get和post请求,不太方便。于是可以在会话框直接添加请求方式。
添加会话框菜单
- 点会话框菜单(箭头位置),右键弹出选项菜单
2. 选择Customize columns选项,Collection选项选择Miscellaneous
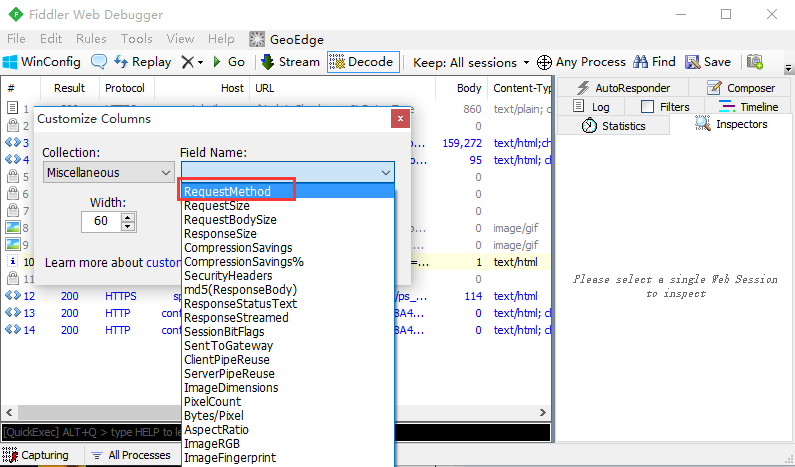
3. Field Name选择:RequestMethod
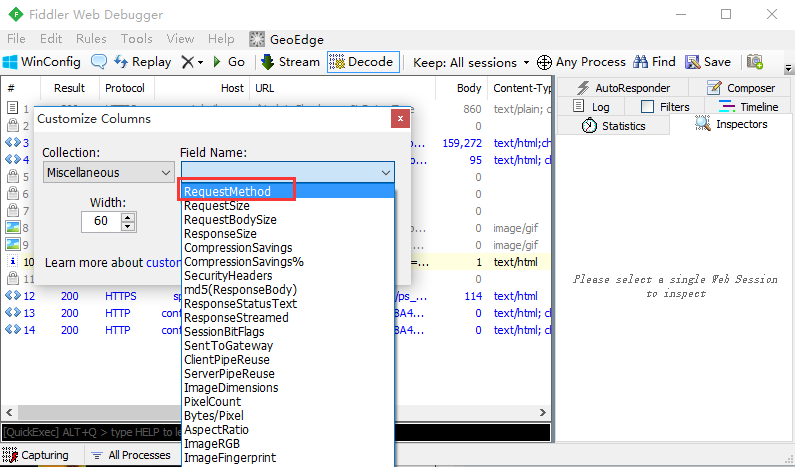
4. 点Add按钮即可添加成功
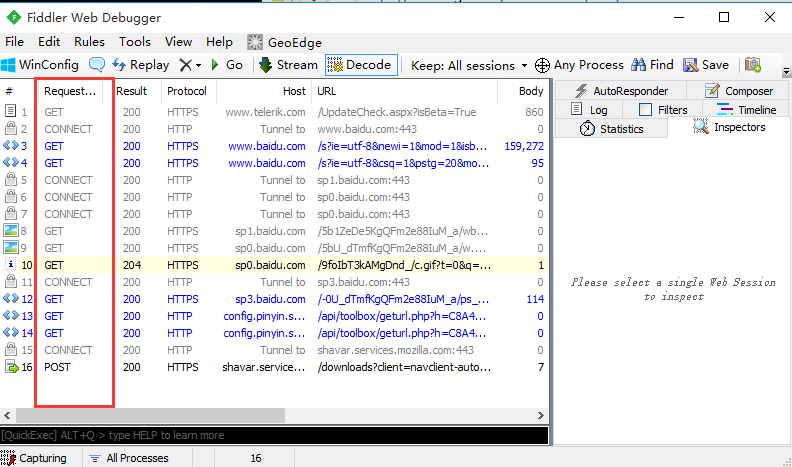
隐藏会话菜单
1.选择需要隐藏的菜单,右键。选择Hide this column
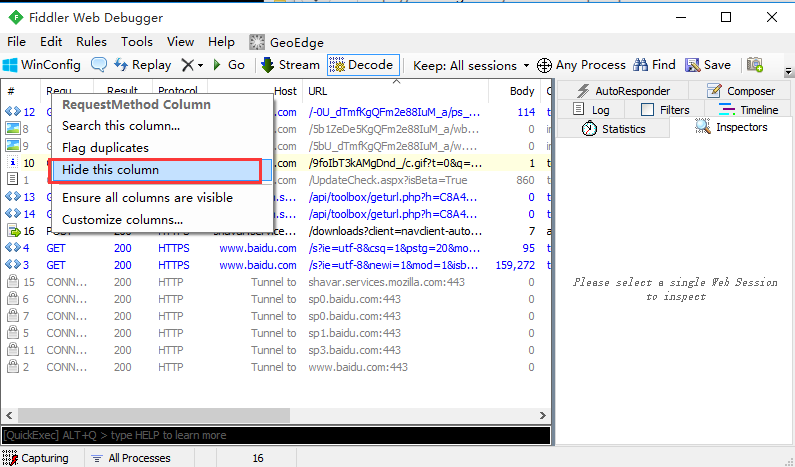
2.隐藏后也可以让隐藏的菜单显示出来:Ensure all columns are visble
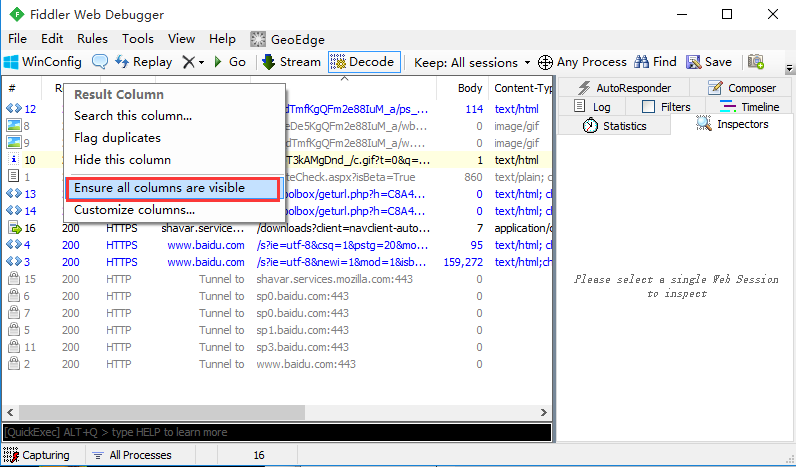
调整会话框菜单顺序
1.如果需要调整会话框菜单顺序,如:Content-Type菜单按住后往前移动,就能调整了
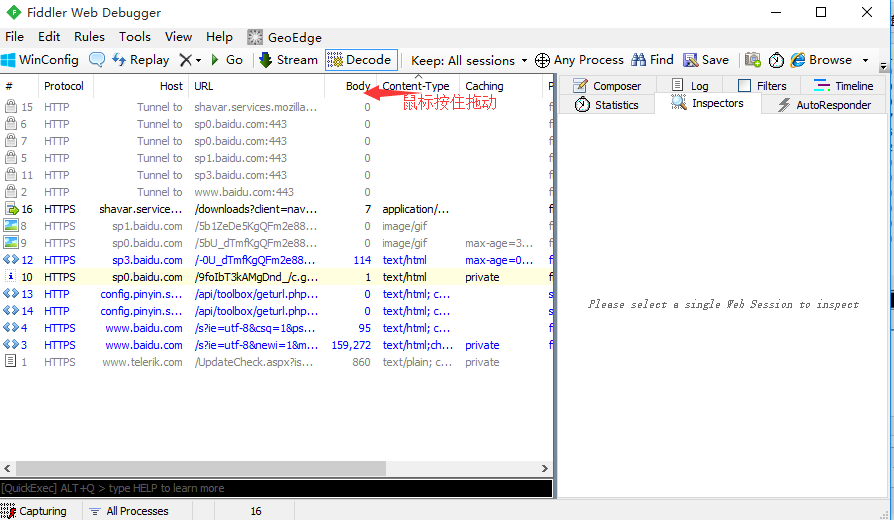
会话排序
1.点击会话框上的菜单,就能对会话列表排序了,如点body菜单
2.点完后上面有个上箭头(正序),或者下箭头(倒叙)。但是不能取消,取消的话关掉fiddler后重新打开就行了。
http协议简介
什么是http
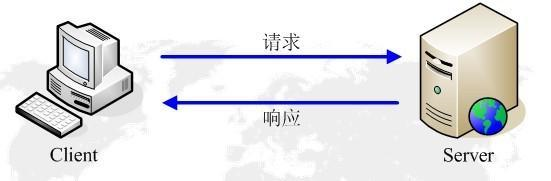
1.HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
2.HTTP(HyperText Transfer Protocol)协议是基于TCP的应用层协议,它不关心数据传输的细节,主要是用来规定客户端和服务端的数据传输格式,最初是用来向客户端传输HTML页面的内容。默认端口是80
3.http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议
二、请求报文
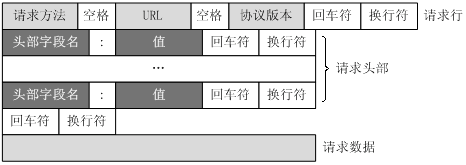
1.HTTP请求报文主要由请求行、请求头部、空一行、请求正文4部分组成
(当然,如果不算空的一行,那就是3个部分)
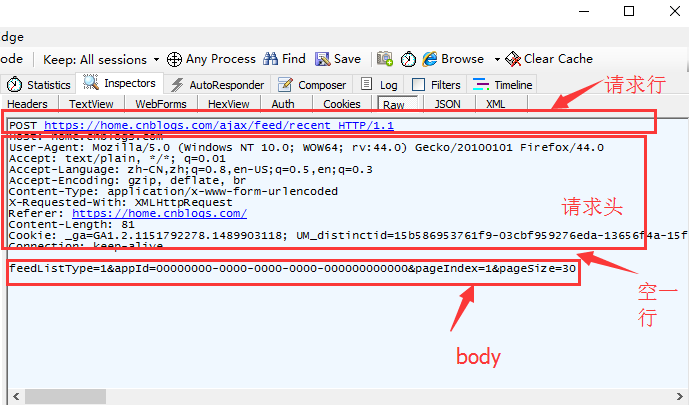
2.下图是fiddler工具抓的post请求报文(工具使用看fiddler篇),可以对照上图,更清楚的理解http的请求报文内容。
响应报文
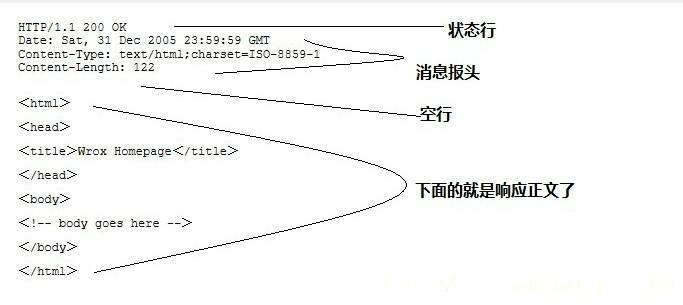
1.HTTP响应报文主要由状态行、消息报头、空一行、响应正文4部分组成
(当然,如果不算空的一行,那就是3个部分)

2.下图就是一个请求的响应内容,用fiddler抓包工具可以查看
完整的http内容
1.一个完整的http协议其实就两块内容,一个是发的请求,一个服务端给的响应。
2.以下是请求https://github.com/timeline.json 这个地址后,用fiddler抓包导出为文本,查看完整的http请求内容。(具体操作查看《fiddler 1.10会话保存》)
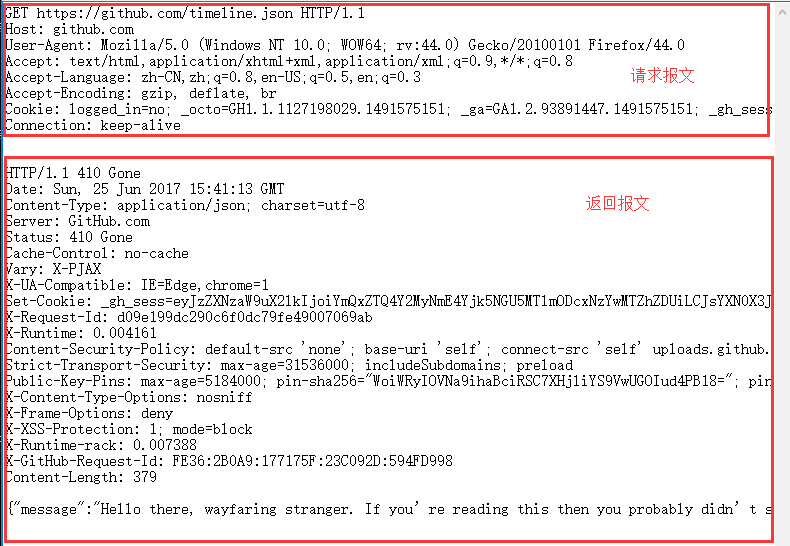
- 内容如下:
以下是请求报文
GET https://github.com/timeline.json HTTP/1.1
Host: github.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate, br
Cookie: xxx(已省略)
以下是请求报文
GET https://github.com/timeline.json HTTP/1.1
Host: github.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate, br
Cookie: xxx(已省略)
X-Request-Id: d09e199dc290c6f0dc79fe49007069ab
X-Runtime: 0.004161
Content-Security-Policy: xxx(已省略)
Strict-Transport-Security: xxx(已省略)
X-Content-Type-Options: nosniff
X-Frame-Options: deny
X-XSS-Protection: 1; mode=block
X-Runtime-rack: 0.007388
X-GitHub-Request-Id: FE36:2B0A9:177175F:23C092D:594FD998
Content-Length: 379
以下是响应正文(json格式)
{“message”:”Hello there, wayfaring stranger. If you’re reading this then you probably didn’t see our blog post a couple of years back announcing that this API would go away: http://git.io/17AROg Fear not, you should be able to get what you need from the shiny new Events API instead.”,”documentation_url”:”https://developer.github.com/v3/activity/events/#list-public-events”}
请求行
8种请求方法
1.请求行有三个主要参数:请求方法、url、协议版本。
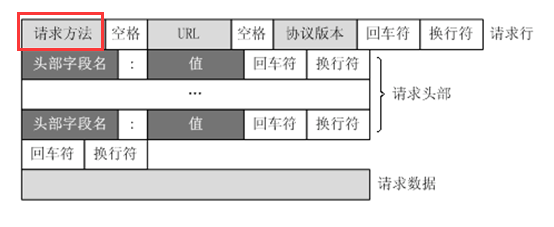
请求方法包含:
| 请求方式 | 简介 |
|---|---|
| get | 请求指定的页面信息,并返回实体主体。 |
| post | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性 |
| PUT | 向指定资源位置上传其最新内容 |
| DELETE | 请求服务器删除Request-URL所标识的资源 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
注意:
1)方法名称是区分大小写的。
2)最常见的的就是通常说的get和post方法。
url详解
1.打开百度,在搜索框输入任意文字,搜索后,复制地址栏的url地址:
https://www.baidu.com/s?wd=%E4%B8%8A%E6%B5%B7%E6%82%A0%E6%82%A0%E5%8D%9A%E5%AE%A2&rsv_spt=1&rsv_iqid=0x91baaabd00070ba2&issp=1&f=8&rsv_bp=1&rsv_idx=2
2.那么一个完整的url地址,基本格式如下:
https://host:port/path?xxx=aaa&ooo=bbb
- http/https:这个是协议类型,如图中1所示
- host:服务器的IP地址或者域名,如图中2所示
- port:HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如:192.168.3.111:8080,这里的8080就是端口
- path:访问资源的路径,如图中3所示/s (图中3是把path和请求参数放一起了)
- ?:url里面的?这个符号是个分割线,用来区分问号前面的是path,问号后面的是参数
- url-params:问号后面的是请求参数,格式:xxx=aaa,如图4区域就是请求参数
- &:多个参数用&符号连接
协议版本
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127478.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...

评论列表(1条)
很详细 对新手非常友好 真心点赞