大家好,又见面了,我是你们的朋友全栈君。
本内容来自其他的人解析,参考链接在最后的注释。
1. 前言
目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下:


n是批量大小(batchsize),η是学习率(learning rate)。可知道除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看它们是影响模型性能收敛最重要的参数。
学习率直接影响模型的收敛状态,batchsize则影响模型的泛化性能,两者又是分子分母的直接关系,相互也可影响,因此这一次来详述它们对模型性能的影响。
2. 学习率如何影响模型性能?
通常我们都需要合适的学习率才能进行学习,要达到一个强的凸函数的最小值,学习率的调整应该满足下面的条件,i代表第i次更新。
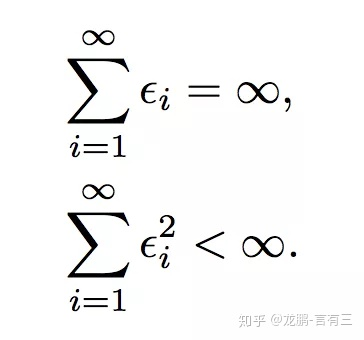
第一个式子决定了不管初始状态离最优状态多远,总是可以收敛。第二个式子约束了学习率随着训练进行有效地降低,保证收敛稳定性,各种自适应学习率算法本质上就是不断在调整各个时刻的学习率。
学习率决定了权重迭代的步长,因此是一个非常敏感的参数,它对模型性能的影响体现在两个方面,第一个是初始学习率的大小,第二个是学习率的变换方案。
2.1、初始学习率大小对模型性能的影响
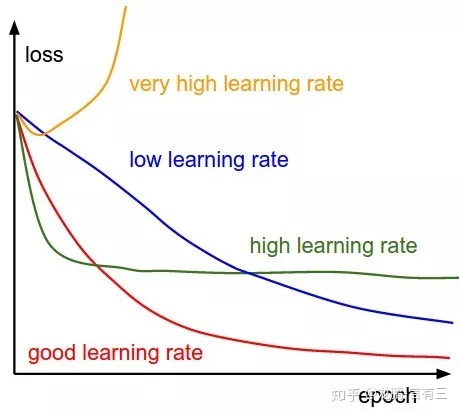
初始的学习率肯定是有一个最优值的,过大则导致模型不收敛,过小则导致模型收敛特别慢或者无法学习,下图展示了不同大小的学习率下模型收敛情况的可能性,图来自于cs231n。
那么在不考虑具体的优化方法的差异的情况下,怎样确定最佳的初始学习率呢?
通常可以采用最简单的搜索法,即从小到大开始训练模型,然后记录损失的变化,通常会记录到这样的曲线。
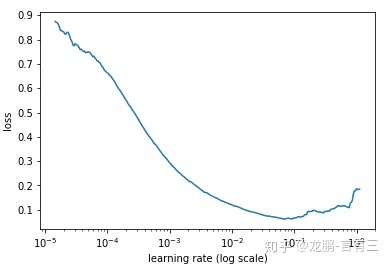
随着学习率的增加,损失会慢慢变小,而后增加,而最佳的学习率就可以从其中损失最小的区域选择。
有经验的工程人员常常根据自己的经验进行选择,比如0.1,0.01等。
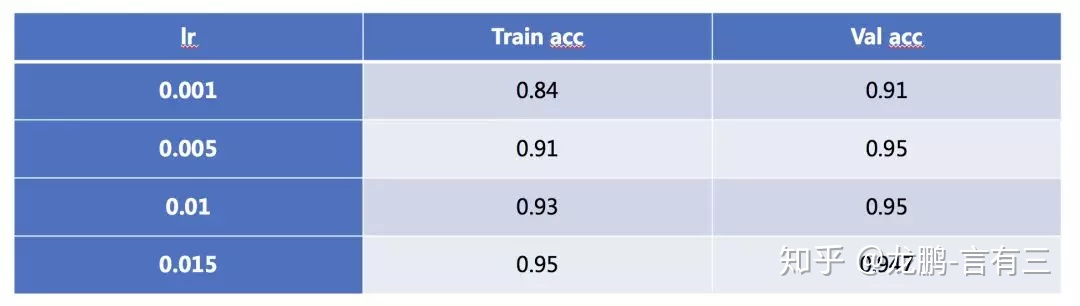
随着学习率的增加,模型也可能会从欠拟合过度到过拟合状态,在大型数据集上的表现尤其明显,笔者之前在Place365上使用DPN92层的模型进行过实验。随着学习率的增强,模型的训练精度增加,直到超过验证集。
2.2、学习率变换策略对模型性能的影响
学习率在模型的训练过程中很少有不变的,通常会有两种方式对学习率进行更改,一种是预设规则学习率变化法,一种是自适应学习率变换方法。
2.2.1 预设规则学习率变化法
常见的策略包括fixed,step,exp,inv,multistep,poly,sigmoid等,集中展示如下:
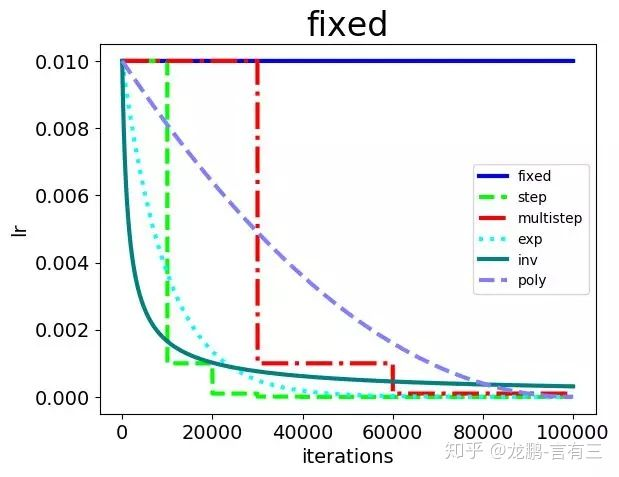
笔者之前做过一个实验来观察在SGD算法下,各种学习率变更策略对模型性能的影响,具体的结果如下:
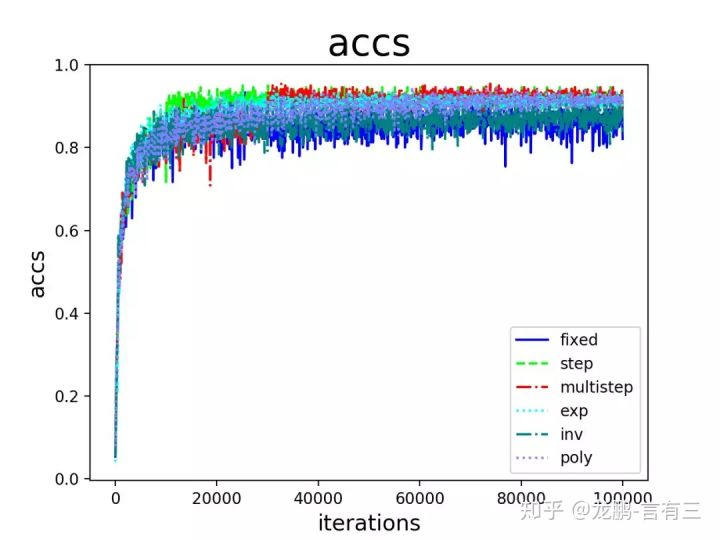
从结果来看:
- step,multistep方法的收敛效果最好,这也是我们平常用它们最多的原因。虽然学习率的变化是最离散的,但是并不影响模型收敛到比较好的结果。
- 其次是exp,poly。它们能取得与step,multistep相当的结果,也是因为学习率以比较好的速率下降,虽然变化更加平滑,但是结果也未必能胜过step和multistep方法,在这很多的研究中都得到过验证,离散的学习率变更策略不影响模型的学习。
- inv和fixed的收敛结果最差。这是比较好解释的,因为fixed方法始终使用了较大的学习率,而inv方法的学习率下降过程太快。
从上面的结果可以看出,对于采用非自适应学习率变换的方法,学习率的绝对值对模型的性能有较大影响,研究者常使用step变化策略。
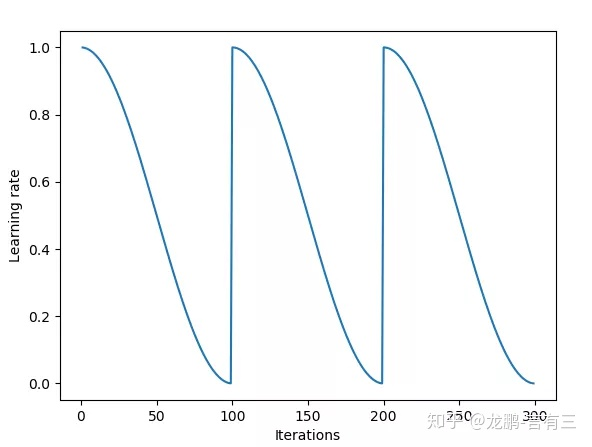
目前学术界也在探索一些最新的研究方法,比如cyclical learning rate,示意图如下:
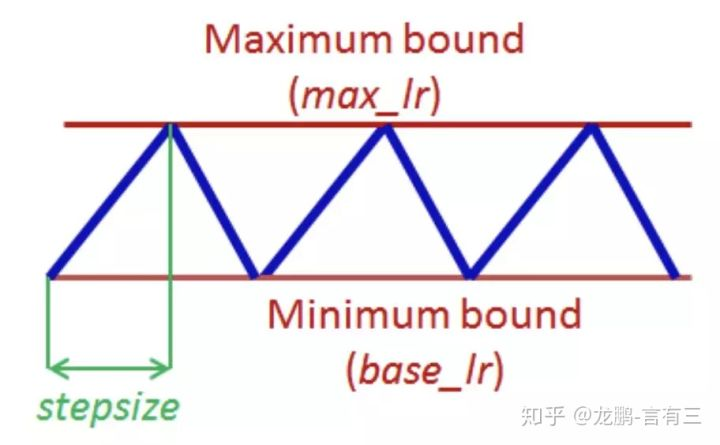
实验证明通过设置上下界,让学习率在其中进行变化,可以在模型迭代的后期更有利于克服因为学习率不够而无法跳出鞍点的情况。
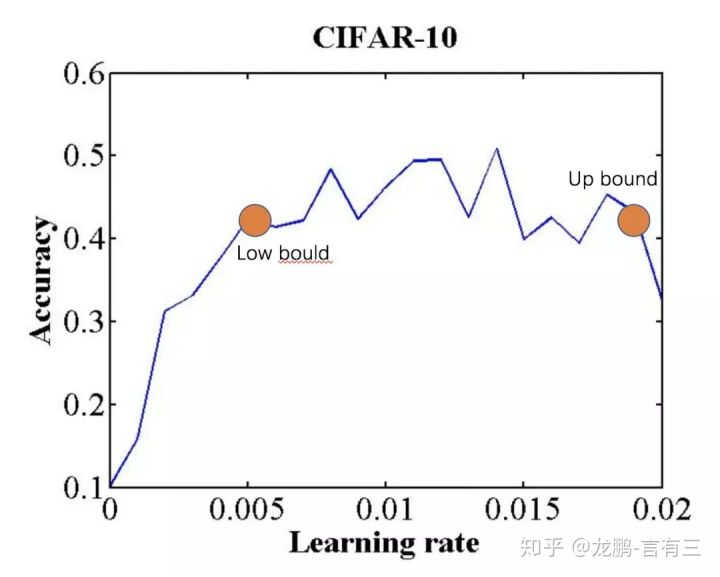
确定学习率上下界的方法则可以使用LR range test方法,即使用不同的学习率得到精度曲线,然后获得精度升高和下降的两个拐点,或者将精度最高点设置为上界,下界设置为它的1/3大小。
SGDR方法则是比cyclical learning rate变换更加平缓的周期性变化方法,如下图,效果与cyclical learning rate类似。
2.2.2 自适应学习率变化法
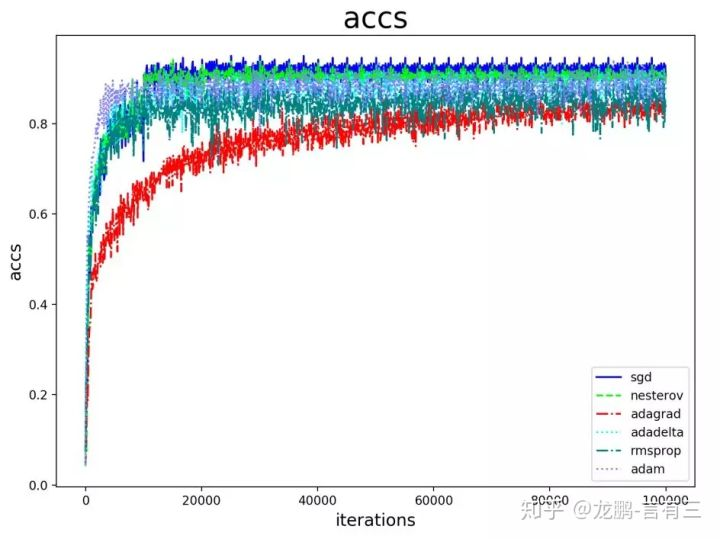
自适应学习率策略以Adagrad,Adam等为代表。
原理上各种改进的自适应学习率算法都比SGD算法更有利于性能的提升,但实际上精细调优过的SGD算法可能取得更好的结果,在很多的论文中都得到过验证,我们在实验中也多次证明过这一点,如下图。
2.3、小结
不考虑其他任何因素,学习率的大小和迭代方法本身就是一个非常敏感的参数。如果经验不够,还是考虑从Adam系列方法的默认参数开始,如果经验丰富,可以尝试更多的实验配置。
3. Batchsize如何影响模型性能?
3.1 谈谈深度学习中的 Batch_Size
Batch_Size(批尺寸)是机器学习中一个重要参数。
首先,为什么需要有 Batch_Size 这个参数?
Batch 的选择,首先决定的是下降的方向。如果数据集比较小,完全可以采用全数据集 ( **Full
Batch Learning)**的形式,这样做有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确的朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。 Full Batch Learning 可以使用Rprop只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来RMSProp的妥协方案。
既然 Full Batch Learning 并不适用大数据集,那么走向另一个极端怎么样?
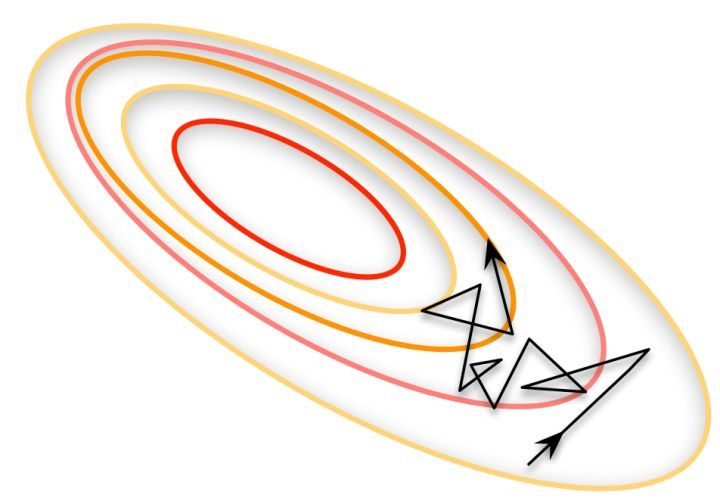
所谓另一个极端,就是每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(OnlineLearning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
可不可以选择一个适中的 Batch_Size 值呢?
当然可以,这就是批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少的更多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一模一样的。
在合理范围内,增大 Batch_Size 有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大 Batch_Size 有何坏处?
- 内存利用率提高了,但是内存容量可能撑不住了。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
- Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
大的batchsize导致模型泛化能力下降?
在一定范围内,增加batchsize有助于收敛的稳定性,但是随着batchsize的增加,模型的性能会下降,如下图:
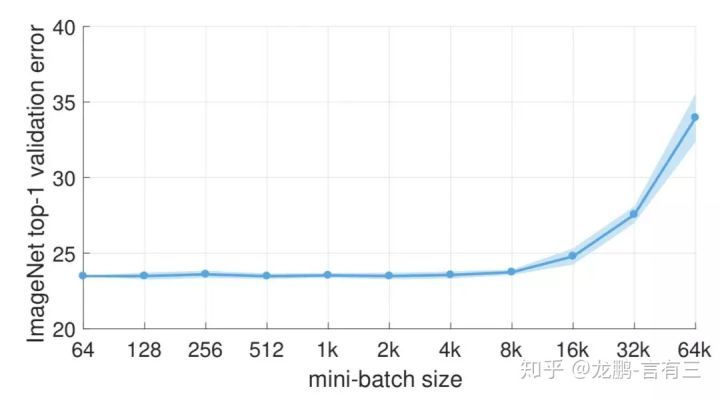
这是研究者们普遍观测到的规律,虽然可以通过一些技术缓解。这个导致性能下降的batch size在上图就是8000左右。
那么这是为什么呢?
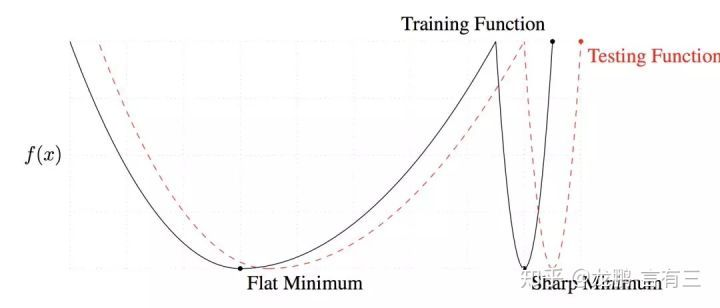
研究表明大的batchsize收敛到sharp minimum,而小的batchsize收敛到flat minimum,**后者具有更好的泛化能力。**两者的区别就在于变化的趋势,一个快一个慢,如下图,造成这个现象的主要原因是小的batchsize带来的噪声有助于逃离sharp minimum。
Hoffer等人的研究表明,大的batchsize性能下降是因为训练时间不够长,本质上并不少batchsize的问题,在同样的epochs下的参数更新变少了,因此需要更长的迭代次数。
3.2 小结
batchsize在变得很大(超过一个临界点)时,会降低模型的泛化能力。在此临界点之下,模型的性能变换随batch size通常没有学习率敏感。
4 学习率和batchsize的关系
通常当我们增加batchsize为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的N倍。但是如果要保证权重的方差不变,则学习率应该增加为原来的sqrt(N)倍,目前这两种策略都被研究过,使用前者的明显居多。
从两种常见的调整策略来看,学习率和batchsize都是同时增加的。学习率是一个非常敏感的因子,不可能太大,否则模型会不收敛。同样batchsize也会影响模型性能,那实际使用中都如何调整这两个参数呢?
研究表明,衰减学习率可以通过增加batchsize来实现类似的效果,这实际上从SGD的权重更新式子就可以看出来两者确实是等价的,文中通过充分的实验验证了这一点。
研究表明,对于一个固定的学习率,存在一个最优的batchsize能够最大化测试精度,这个batchsize和学习率以及训练集的大小正相关。
对此实际上是有两个建议:
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- 尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整。
参考
【AI不惑境】学习率和batchsize如何影响模型的性能?
谈谈深度学习中的 Batch_Size
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126990.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
