大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Scaling and Benchmarking Self-Supervised Visual Representation Learning
Introduction
本篇文章介绍一篇自监督学习的论文《Scaling and Benchmarking Self-Supervised Visual Representation Learning》论文地址,通过介绍这篇文章,可以对当前自监督学习的效果有一个大概的认识。
本文从两个方面比较了自监督学习方法的性能:
- 通过变化数据集的规模、模型的容量和学习任务的难易程度来比较自监督学习的性能
- 列举了五种学习任务和六个数据集,分别比较自监督学习、ImageNet预训练和随机初始化三个方面的性能。
总的来说,本文的结论是自监督学习的性能提升与数据集规模、模型的容量和学习任务的难度呈正相关 (这个结论有点神棍文的味儿)。但是对于不同的任务,自监督学习的性能各不相同,对于分类这样的任务,自监督方法相比于随机初始化可以取得不错的提升,但是距离ImageNet预训练还是有挺大的差别;对于目标检测这样的任务,自监督方法和ImageNet预训练的结果相当。对于surface normal estimation任务,自监督方法比其他方法都要好。从我个人的实验的结果看,其实现在自监督学习方法还是一种方法的堆叠,有没有产生效果全看pretext task任务,也就是说现在自监督学习方法距离他的目标还很远。
目前为止,针对自监督学习的方法有很多,作者在这其中选了两种比较有代表性的方法,一种是针对拼图预测的方法,另一种是针对图片上色的方法,在后面的实验中,均以这两种方法为例评估自监督学习的效果。具体的验证环节,作者使用自监督网络提取特征,之后利用这些特征训练线性分类器,执行具体的任务,也就是说自监督模型在这里只是一个特征提取器。
Scaling Self-supervised Learning
首先作者实验自监督学习的伸缩性,即通过变化数据集的规模、增加模型的容量以及增加网络的复杂性,比较自监督学习的效果变化。
增加预训练数据集的规模
自监督学习是不需要人工标注数据的,因此我们可以很容易地将其数据集规模增加上百倍。这个部分作者使用了YFCC-100M数据集,这个数据集包含100万张图片,作者均匀采样得到【1,10,50,100】万的不同子数据集,用来验证预训练数据集规模与自监督性能的影响。
文章中使用Pascal VOC07 的分类任务来验证数据集增加对结果的影响。Backbone使用Resnet50和Alxnet,分类器使用线性SVM,实验效果如下图所示:
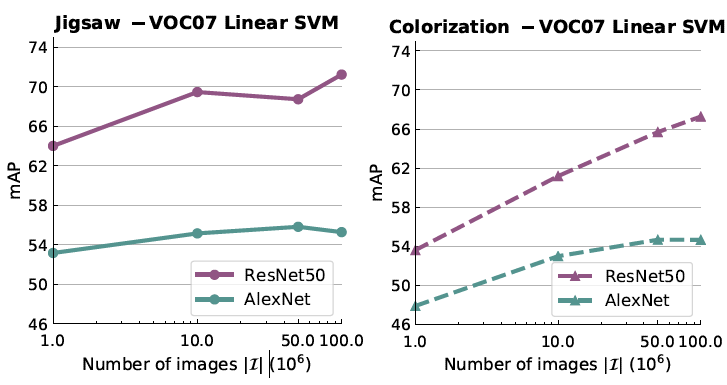

横坐标是数据集规模的变化,纵坐标是平均精度,可以看出,随着数据集规模的增加,自监督的性能总体上是上升的,但是上升的幅度不同。对于Resnet50,在数据集规模在100M时,似乎性能还可以上升,但是对于Alexnet,性能已经趋于稳定甚至略有下降,这里面可以看出模型的容量对于性能同样具有相当的影响。
增加模型的容量
增加模型容量的实验同样可以通过上图看出来,实际上增加模型的容量对于自监督方法的性能提升具有很大的影响,适当的选取更大容量的模型是很有必要的。
增加任务的复杂度
作者在这部分通过增加拼图和上色任务的复杂度,比较了自监督方法的性能变化,如下图所示:
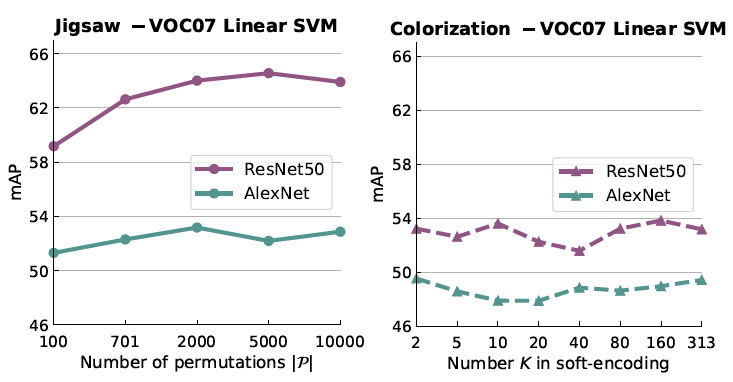
可以看出,增加问题复杂度总体上是有利于自监督方法的性能提升的。这可以理解为,增加任务的复杂度可以增加防止一定的过拟合,但是随着任务复杂度的提升,可能导致网络无法有效学习,有可能带来性能的下降,因此,任务的复杂度是一个需要调节的超参数。
另外,作者还分析了三者同时变化时的性能变化:
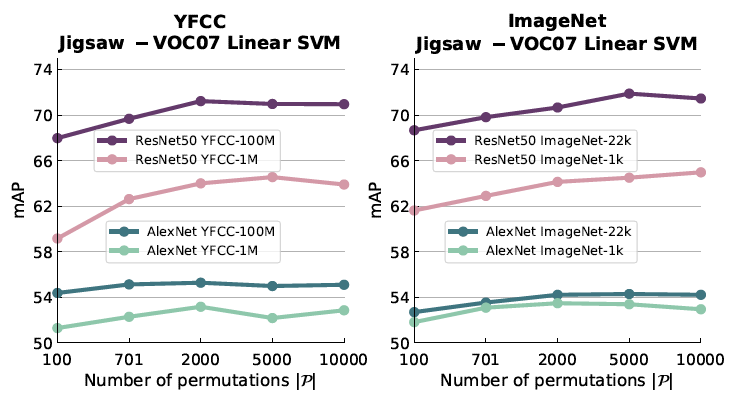
Benchmarking Suite for Self-supervision
这部分,作者对自监督学习应用到五种任务的性能进行了比较,这五种任务和数据集如下:
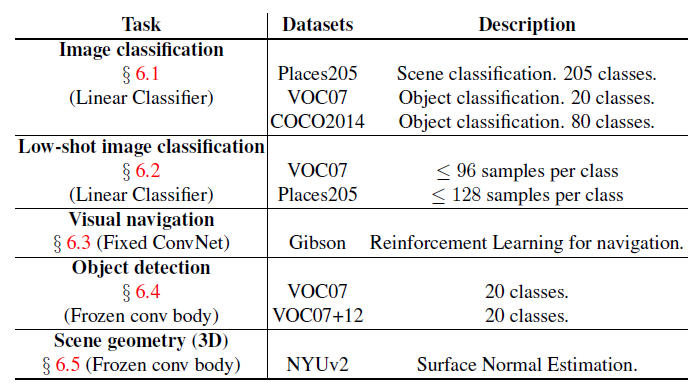
Image Classification
对于分类任务,作者在三个数据集上计算了分类的性能:Place205、 Voc07和COCO2014,使用了两种基准网络ResNet-50和AlextNet。
首先作者固定自监督学习网络,分别从不同的层提取特征,用线性SVM分类器进行分类,在VOC07上的结果如下面的两张图所示:
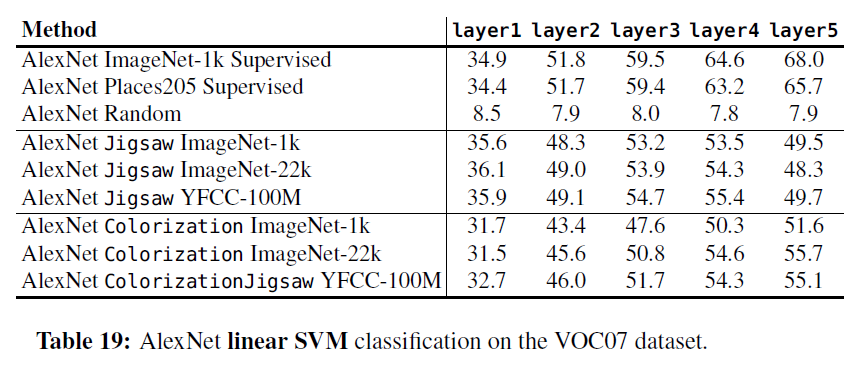
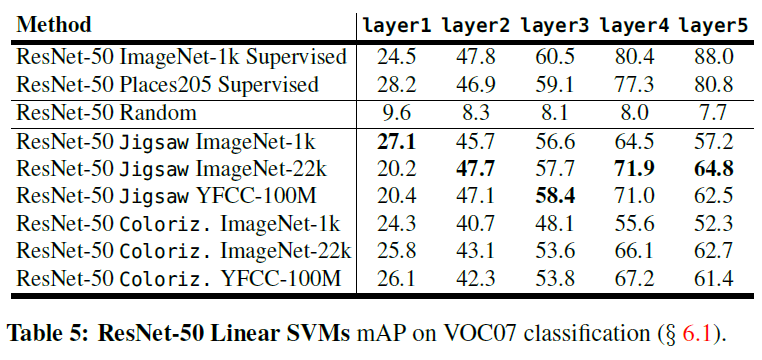
可以看出,在分类任务上,自监督学习和ImageNet 监督训练的效果还是有显著的差距,大概在10到20个百分点。但是这里对于随机初始化的比较不具有代表性,因为这里特征提取层是固定的而且是随机初始化,所以相当于随机初始化的时候特征层是完全乱的,为了更好的比较随机初始化与自监督的效果,这里也列出作者的另一个实验。在这个试验里,作者将自监督模型作为预训练模型,对整个网络进行微调,下面的结果:
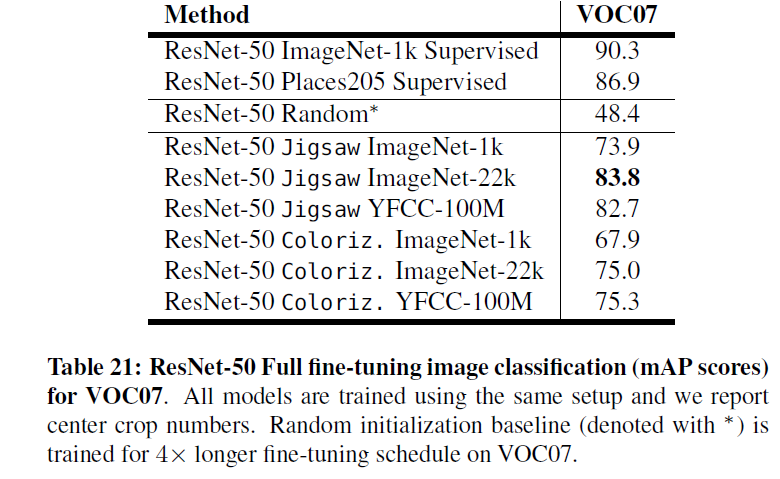
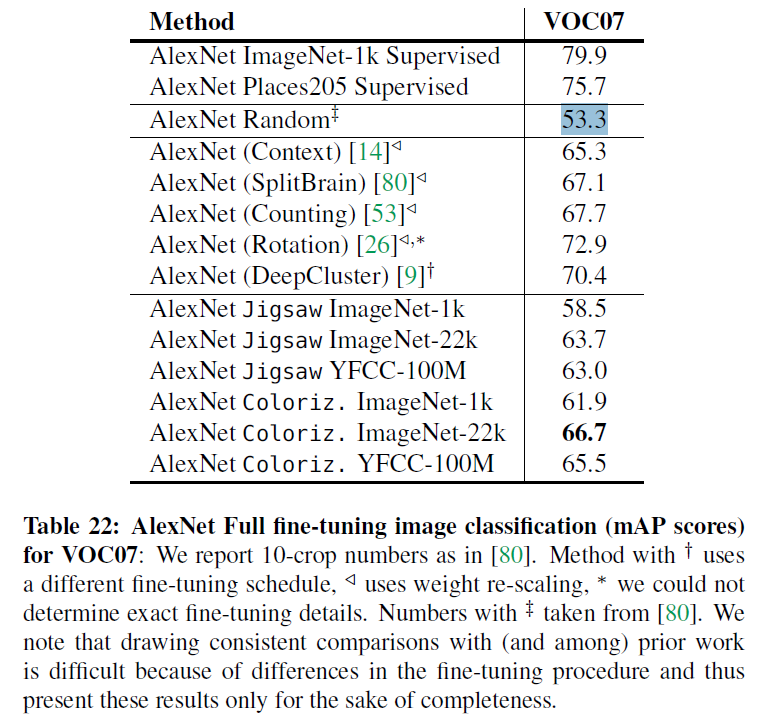
可以很明显的看出,尽管自监督方法距离ImageNet仍有显著的差距,但是其对随机初始化的优势也是比较明显的。也就是说自监督学习在分类任务上,比随机初始化效果好,比ImageNet初始化效果差,性能介于这两者之间。
Low-shot Image Classification
如果我们能通过自监督学习学习到一个好的图像特征表示,只需要很少的正样本我们就可以训练一个好的分类器。因此,本部分作者做了这样一个少样本下的图像分类的实验。作者在这里只是用了ResNet-50模型,数据集使用Place205和VOC07,实验的结果图下图所示:
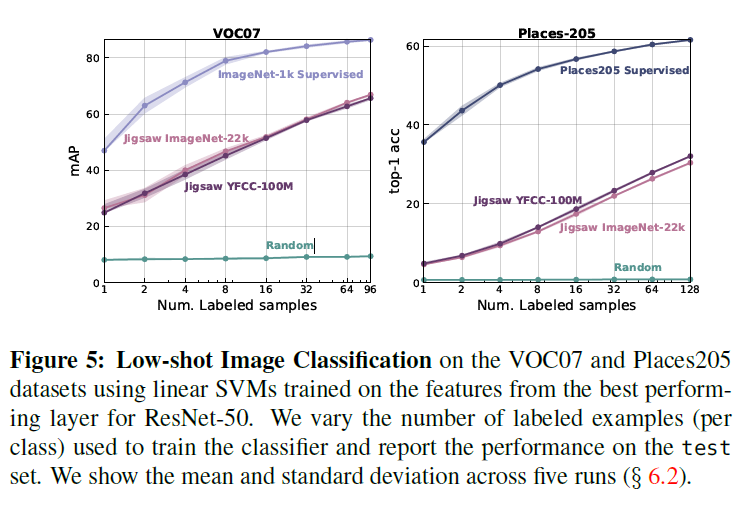
可以看到,实验结果和图像分类类似,自监督学习的效果不如ImageNet但是明显好于随机初始化。
Visual Navigation
这个任务不太了解,可以参考原论文。
Object Detection
作者在VOC07和VOC07+12上实验自监督方法用于目标检测的性能,作者固定Faster R-CNN的卷积层,只调整RoI Heads,得到的实验结果如下:
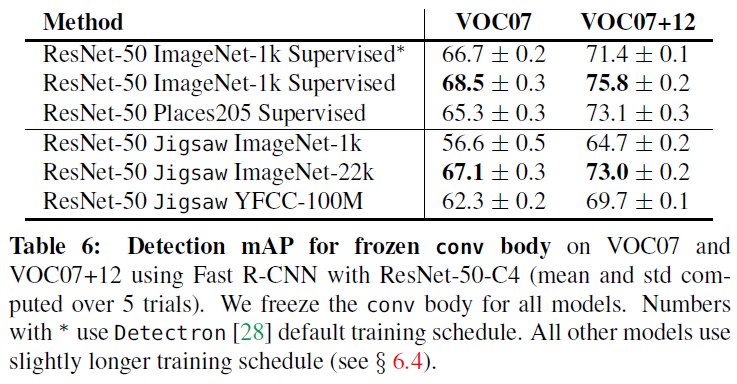
差距依然比较显著,但是当我们增加预训练数据集的规模后,差距就变得很小了。
Surface Normal Estimation
这一类任务同样不是很了解,详细可以参考原文。作者在这个实验中,得出的结论是自监督方法要由于ImageNet预训练,这也是本文中唯一自监督取得最好效果的实验
Conclusion
尽管作者在这篇文章中没有提出什么创新的方法,但是作者对于自监督方法的详细的实验,对于快速了解自监督方法目前的现状是很有用处的,虽然这篇文章是2019年5月发布出来的,但是实验的结论在现在依然是对的。以下是我根据作者的结论和实验,结合自己的理解总结的本文的主要结论:
- 总体上看,自监督学习方法是有一定的效果的,但是其在一些经典的任务上(分类、检测等)相对于ImageNet预训练还有相当大的差距。造成这一现象的原因,我觉得有可能是目前的自监督学习方法通过构造Pretext task来实现,实际上就是把无监督变成有监督来学习,但是这种方法是很具有和分类标签同样的信息量的,不可避免的会出现过拟合现象,而且比有监督要严重,这也是自监督效果追不上有监督的原因。
- 增加模型容量、增加数据集规模和增加问题的复杂度是提高自监督学习性能的有效的方法。
- 自监督文章在设计实验的时候,可以做的有:图像分类、目标检测,固定特征层只训练分类器等。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193940.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
