大家好,又见面了,我是你们的朋友全栈君。
什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
换句话说,就是借鉴和你相关人群的观点来进行推荐,很好理解。
协同过滤的实现
要实现协同过滤的推荐算法,要进行以下三个步骤:
1)收集数据
2)找到相似用户和物品
3)进行推荐
1 收集数据
这里的数据指的都是用户的历史行为数据,比如用户的购买历史,关注,收藏行为,或者发表了某些评论,给某个物品打了多少分等等,这些都可以用来作为数据供推荐算法使用,服务于推荐算法。需要特别指出的在于,不同的数据准确性不同,粒度也不同,在使用时需要考虑到噪音所带来的影响。
2找到相似用户和物品
这一步也很简单,其实就是计算用户间以及物品间的相似度。以下是几种计算相似度的方法: 

3 进行推荐
在知道了如何计算相似度后,就可以进行推荐了。
在协同过滤中,有两种主流方法:
1)基于用户的协同过滤
2)基于物品的协同过滤
具体怎么来阐述他们的原理呢,看个图大家就明白了
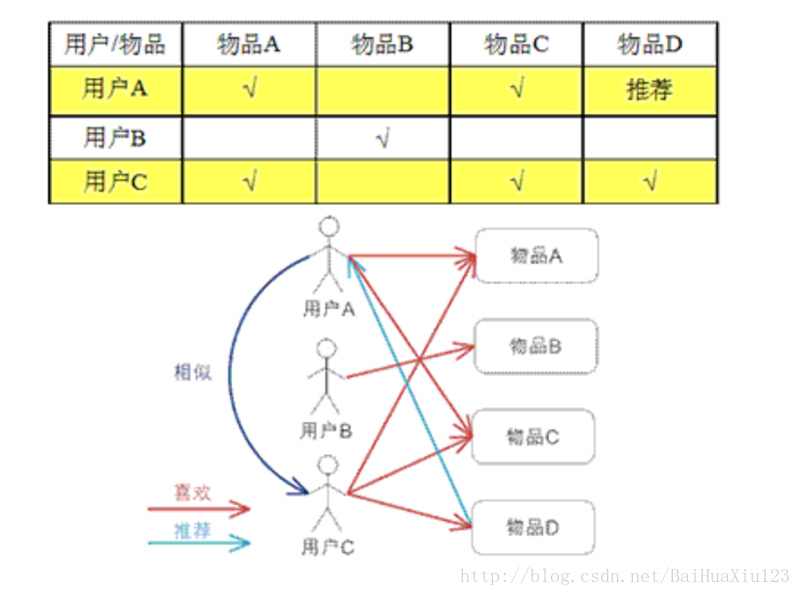
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
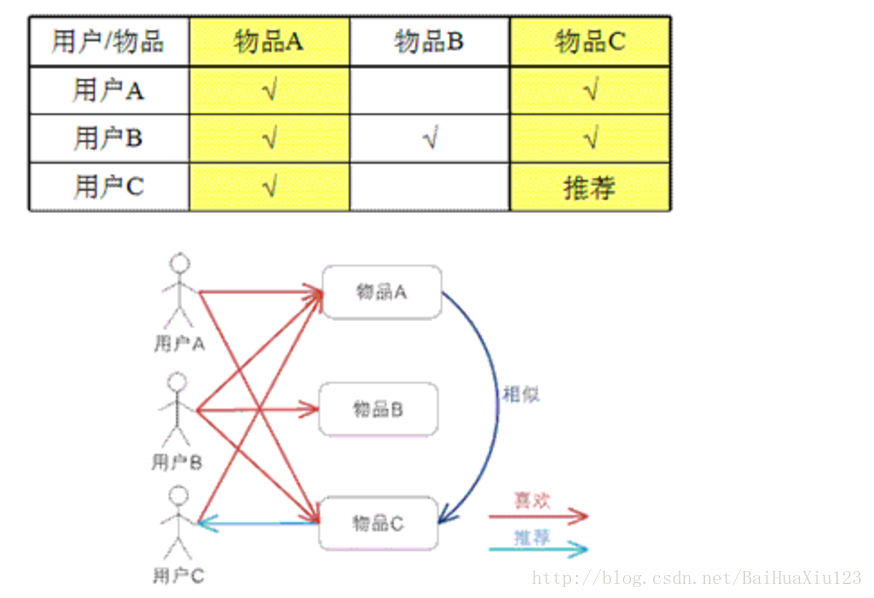
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
算法存在的问题
这个算法实现起来也比较简单,但是在实际应用中有时候也会有问题的。
比如一些非常流行的商品可能很多人都喜欢,这种商品推荐给你就没什么意义了,所以计算的时候需要对这种商品加一个权重或者把这种商品完全去掉也行。
再有,对于一些通用的东西,比如买书的时候的工具书,如现代汉语词典,新华字典神马的,通用性太强了,推荐也没什么必要了。
适用场景
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。
具体实现
# -*- coding=utf-8 -*-
import math
import sys
from texttable import Texttable
#
# 使用 |A&B|/sqrt(|A || B |)计算余弦距离
#
#
#
def calcCosDistSpe(user1,user2):
avg_x=0.0
avg_y=0.0
for key in user1:
avg_x+=key[1]
avg_x=avg_x/len(user1)
for key in user2:
avg_y+=key[1]
avg_y=avg_y/len(user2)
u1_u2=0.0
for key1 in user1:
for key2 in user2:
if key1[1] > avg_x and key2[1]>avg_y and key1[0]==key2[0]:
u1_u2+=1
u1u2=len(user1)*len(user2)*1.0
sx_sy=u1_u2/math.sqrt(u1u2)
return sx_sy
#
# 计算余弦距离
#
#
def calcCosDist(user1,user2):
sum_x=0.0
sum_y=0.0
sum_xy=0.0
for key1 in user1:
for key2 in user2:
if key1[0]==key2[0] :
sum_xy+=key1[1]*key2[1]
sum_y+=key2[1]*key2[1]
sum_x+=key1[1]*key1[1]
if sum_xy == 0.0 :
return 0
sx_sy=math.sqrt(sum_x*sum_y)
return sum_xy/sx_sy
#
#
# 相似余弦距离
#
#
#
def calcSimlaryCosDist(user1,user2):
sum_x=0.0
sum_y=0.0
sum_xy=0.0
avg_x=0.0
avg_y=0.0
for key in user1:
avg_x+=key[1]
avg_x=avg_x/len(user1)
for key in user2:
avg_y+=key[1]
avg_y=avg_y/len(user2)
for key1 in user1:
for key2 in user2:
if key1[0]==key2[0] :
sum_xy+=(key1[1]-avg_x)*(key2[1]-avg_y)
sum_y+=(key2[1]-avg_y)*(key2[1]-avg_y)
sum_x+=(key1[1]-avg_x)*(key1[1]-avg_x)
if sum_xy == 0.0 :
return 0
sx_sy=math.sqrt(sum_x*sum_y)
return sum_xy/sx_sy
#
# 读取文件
#
#
def readFile(file_name):
contents_lines=[]
f=open(file_name,"r")
contents_lines=f.readlines()
f.close()
return contents_lines
#
# 解压rating信息,格式:用户id\t硬盘id\t用户rating\t时间
# 输入:数据集合
# 输出:已经解压的排名信息
#
def getRatingInformation(ratings):
rates=[]
for line in ratings:
rate=line.split("\t")
rates.append([int(rate[0]),int(rate[1]),int(rate[2])])
return rates
#
# 生成用户评分的数据结构
#
# 输入:所以数据 [[2,1,5],[2,4,2]...]
# 输出:1.用户打分字典 2.电影字典
# 使用字典,key是用户id,value是用户对电影的评价,
# rate_dic[2]=[(1,5),(4,2)].... 表示用户2对电影1的评分是5,对电影4的评分是2
#
def createUserRankDic(rates):
user_rate_dic={}
item_to_user={}
for i in rates:
user_rank=(i[1],i[2])
if i[0] in user_rate_dic:
user_rate_dic[i[0]].append(user_rank)
else:
user_rate_dic[i[0]]=[user_rank]
if i[1] in item_to_user:
item_to_user[i[1]].append(i[0])
else:
item_to_user[i[1]]=[i[0]]
return user_rate_dic,item_to_user
#
# 计算与指定用户最相近的邻居
# 输入:指定用户ID,所以用户数据,所以物品数据
# 输出:与指定用户最相邻的邻居列表
#
def calcNearestNeighbor(userid,users_dic,item_dic):
neighbors=[]
#neighbors.append(userid)
for item in users_dic[userid]:
for neighbor in item_dic[item[0]]:
if neighbor != userid and neighbor not in neighbors:
neighbors.append(neighbor)
neighbors_dist=[]
for neighbor in neighbors:
dist=calcSimlaryCosDist(users_dic[userid],users_dic[neighbor]) #calcSimlaryCosDist calcCosDist calcCosDistSpe
neighbors_dist.append([dist,neighbor])
neighbors_dist.sort(reverse=True)
#print neighbors_dist
return neighbors_dist
#
# 使用UserFC进行推荐
# 输入:文件名,用户ID,邻居数量
# 输出:推荐的电影ID,输入用户的电影列表,电影对应用户的反序表,邻居列表
#
def recommendByUserFC(file_name,userid,k=5):
#读取文件数据
test_contents=readFile(file_name)
#文件数据格式化成二维数组 List[[用户id,电影id,电影评分]...]
test_rates=getRatingInformation(test_contents)
#格式化成字典数据
# 1.用户字典:dic[用户id]=[(电影id,电影评分)...]
# 2.电影字典:dic[电影id]=[用户id1,用户id2...]
test_dic,test_item_to_user=createUserRankDic(test_rates)
#寻找邻居
neighbors=calcNearestNeighbor(userid,test_dic,test_item_to_user)[:k]
recommend_dic={}
for neighbor in neighbors:
neighbor_user_id=neighbor[1]
movies=test_dic[neighbor_user_id]
for movie in movies:
#print movie
if movie[0] not in recommend_dic:
recommend_dic[movie[0]]=neighbor[0]
else:
recommend_dic[movie[0]]+=neighbor[0]
#print len(recommend_dic)
#建立推荐列表
recommend_list=[]
for key in recommend_dic:
#print key
recommend_list.append([recommend_dic[key],key])
recommend_list.sort(reverse=True)
#print recommend_list
user_movies = [ i[0] for i in test_dic[userid]]
return [i[1] for i in recommend_list],user_movies,test_item_to_user,neighbors
#
#
# 获取电影的列表
#
#
#
def getMoviesList(file_name):
#print sys.getdefaultencoding()
movies_contents=readFile(file_name)
movies_info={}
for movie in movies_contents:
movie_info=movie.split("|")
movies_info[int(movie_info[0])]=movie_info[1:]
return movies_info
#主程序
#输入 : 测试数据集合
if __name__ == '__main__':
reload(sys)
sys.setdefaultencoding('utf-8')
movies=getMoviesList("/Users/wuyinghao/Downloads/ml-100k/u.item")
recommend_list,user_movie,items_movie,neighbors=recommendByUserFC("/Users/wuyinghao/Downloads/ml-100k/u.data",179,80)
neighbors_id=[ i[1] for i in neighbors]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(['t', # text
't', # float (decimal)
't']) # automatic
table.set_cols_align(["l", "l", "l"])
rows=[]
rows.append([u"movie name",u"release", u"from userid"])
for movie_id in recommend_list[:20]:
from_user=[]
for user_id in items_movie[movie_id]:
if user_id in neighbors_id:
from_user.append(user_id)
rows.append([movies[movie_id][0],movies[movie_id][1],""])
table.add_rows(rows)
print table.draw()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
推荐结果
movie name release
=======================================================
Contact (1997) 11-Jul-1997
Scream (1996) 20-Dec-1996
Liar Liar (1997) 21-Mar-1997
Saint, The (1997) 14-Mar-1997
English Patient, The (1996) 15-Nov-1996
Titanic (1997) 01-Jan-1997
Air Force One (1997) 01-Jan-1997
Star Wars (1977) 01-Jan-1977
Conspiracy Theory (1997) 08-Aug-1997
Toy Story (1995) 01-Jan-1995
Fargo (1996) 14-Feb-1997 发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126545.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
