大家好,又见面了,我是你们的朋友全栈君。
本文图文并茂的描述了:zookeeper是什么,演示了Zookeeper集群如何搭建、Zookeeper常用命令的使用、如何查看Zookeeper日志;详细描述了Zookeeper数据模型、watch机制、ACL、集群选举机制。非常适合刚接触ZK的小伙伴哟,相信你读完之后,最基本也能描述出Zookeeper是个什么了。
ZooKeeper
一、ZooKeeper
1、Zookeeper概述
Zookeeper 是一个 分布式协调服务 的开源框架。主要作用是为分布式系统提供协调服务,包括但不限于:分布式锁、统一命名服务、配置管理、负载均衡、主控服务器选举以及主从切换等。
ZooKeeper本质上是一个分布式的小文件存储系统。提供类似与文件系统目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,实现基于数据的集群管理。
2、Zookeeper = 文件系统 + 监听通知机制 + ACL
1、文件系统
Zookeeper维护一个类似文件系统的数据结构(如下官方示意图),每一个子目录项(如app1)都被称作为znode(目录节点),和文件系统一样,我们能够自由的对一个znode进行CRUD,也可以在znode下进行子znode的CRUD,唯一不同的是,znode是可以存储数据的。
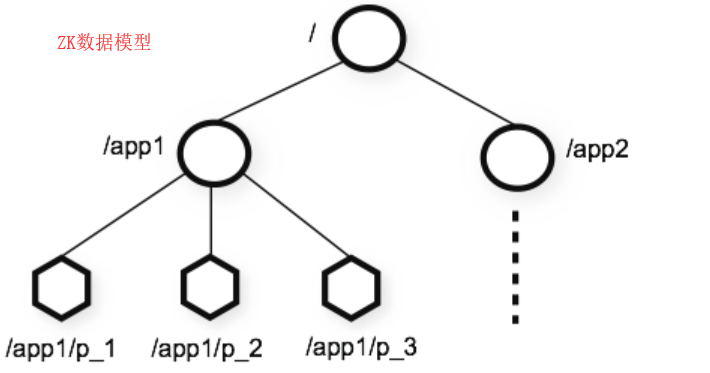

znode类型:
-
PERSISTENT:持久化节点
一旦客户端(client)在zookeeper服务器(server)上创建了一个持久化节点,只要客户端(client)不删除该节点,不论客户端(client)与zookeeper(server)断开/重连多少次,该节点依然存在。 -
PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点
一旦客户端(client)在zookeeper服务器(server)上创建了一个持久化节点,只要客户端(client)不删除该节点,不论客户端(client)与zookeeper(server)断开/重连多少次,该节点依然存在。只是zookeeper给该节点名多追加了一个编号(例如:/app123456,这个编号是zookeeper给的) -
EPHEMERAL:临时目录节点
客户端(client)在zookeeper(server)上创建了一个节点,但是,当客户端(client)与zookeeper(server)断开连接之后,该节点就会被zookeeper(server)删除。 -
EPHEMERAL_SEQUENTIAL:临时顺序编号目录节点
客户端(client)在zookeeper(server)上创建了一个节点,但是,当客户端(client)与zookeeper(server)断开连接之后,该节点就会被zookeeper(server)删除。只是zookeeper给该节点名多追加了一个编号
2、监听通知机制
简单来说:client 注册监听它所关心的目录节点,当该目录节点发生变化(节点被改变、被删除、其子目录节点有增删改情况)时,ZK server会通过watcher监听机制将消息推送给client。(详情请看 四、Zookeeper Watch )
3、ACL(access control list 访问控制列表)
zookeeper在分布式系统中承担中间件的作用,它管理的每一个节点上都可能存储着重要的信息,因为应用可以读取到任意节点,这就可能造成安全问题,ACL的作用就是帮助zookeeper实现权限控制。
-
zookeeper的权限控制基于节点,每个znode可以有不同的权限。
-
子节点不会继承父节点的权限,访问不了该节点,并不代表访问不到其子节点。
结构:schema :id :permission
一个 ACL 权限设置通常可以分为 3 部分,分别是:权限模式(Scheme)、授权对象(ID)、权限信息(Permission)。最终组成一条例如“scheme :id :permission”格式的 ACL 请求信息。下面我们具体看一下这 3 部分代表什么意思:Schema: 鉴权策略
schema 描述 world 默认方式,相当于全世界都能访问 digest 即: “用户名+密码” 这种认证方式,也是业务中常用的 ip 使用IP认证的方式 auth 代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户) 授权对象 ID
权限模式 授权对象 world 只有一个ID:“anyone” digest 自定义,通常是用户名:密码,在ACl中使用时,表达式将是username:base64编码的SHA1.例如”admin:u53OoA8hprX59uwFsvQBS3QuI00=”(明文密码为123456) ip 通常是一个Ip地址或者是Ip段, 例如192.168.xxx.xxx或者 192.168.xxx.xxx/xxx super 与digest模式一样 权限Permission
权限 简写 描述 create c 创建权限,授予权限的对象可以在数据节点下创建子节点; read r 读取权限,授予权限的对象可以读取该节点的内容以及子节点的信息; write w 更新权限,授予权限的对象可以更新该数据节点; delete d 删除权限,授予权限的对象可以删除该数据节点的子节点; admin a 管理者权限,授予权限的对象可以对该数据节点体进行 ACL 权限设置。 ps:这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限。每个节点都有维护自身的 ACL 权限数据,即使是该节点的子节点也是有自己的 ACL 权限而不是直接继承其父节点的权限
3、session会话机制
client请求和服务端建立连接,服务端会保留和标记当前client的session,包含 session过期时间、sessionId ,然后服务端开始在session过期时间的基础上倒计时,在这段时间内,client需要向server发送心跳包,目的是让server重置session过期时间。
4、Zookeeper特性
全局数据一致性(<—最重要的一个特性):
在一个ZK集群中,有可能有多台ZK server,但每台server保存的数据副本都是相同的,client无论连接到哪个server,获得的数据都是一样的。
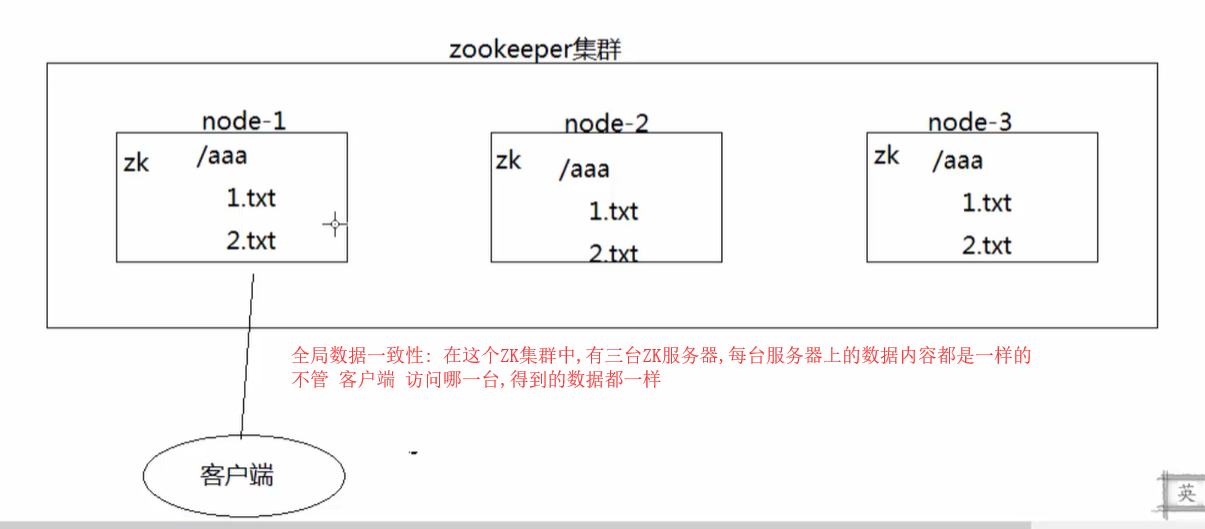
PS:ZK提供的一致性是弱一致性;ZK对数据的复制(将其中某一server最新的数据更新同步到其他server中)有一个规则:zookeeper确保每一次对znode树的修改都会复制到集群中的其他server对应的znode上,当半数以上的server成功复制、统一数据之后,zookeeper其实就已经默认本次的数据同步是成功的。那么也就可能产生一个问题:在某一时间段下,有些server的数据更新失败,此时该server数据不是最新的,恰巧又被client访问了,就会产生脏读。也就是说,ZK只是保证数据的最终一致性,但实时的一致性不保障。但用户也可以通过调用sync()来保证实时数据一致性
可靠性:
如果client对某一台server上的数据进行了CUD,那么zookeeper集群会对其他所有的server数据进行统一,这也保证了ZK的全局数据一致性。
顺序性:
若在一台server上,消息b在消息a之后发布,则其他所有的server中,消息b都将在消息a之后发布。
数据更新原子性:
联想事务原子性,一次数据更新要么都成功,要么都失败。在ZK中,对一次数据的更新,只有当半数以上节点都更新成功,才算本次数据更新成功,否则就是失败,不会有中间状态(一半成功一半失败)。
实时性:
在特定的一段时间内,client看到的server状态都是实时的,在此时间段内,sercer做任何的改变,都会推送到client。
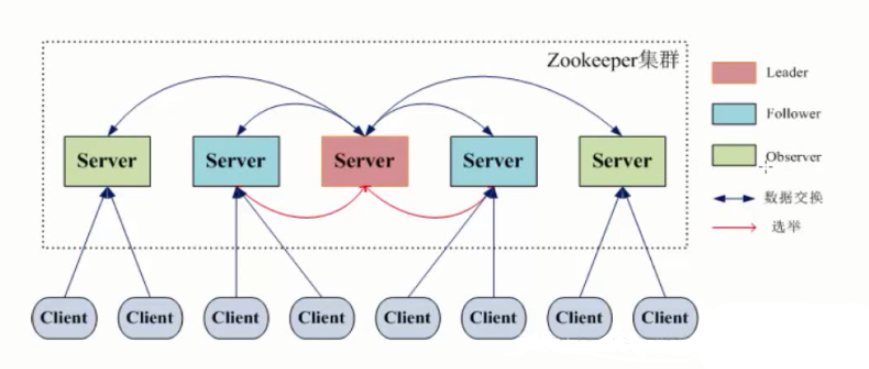
5、Zookeeper集群角色
Leader(主节点、领导):
Leader是整个ZK集群的核心,负责响应所有对Zookeeper状态变更的请求。它会将每个状态更新请求进行排序和编号,以便保证整个集群内部消息处理的FIFO(First Input First Output的缩写,先入先出队列)。
1、处理事务请求(CUD)和非事务请求。PS:Leader是ZK中唯一一个有权对事务请求进行调度和处理的角色,能够保证集群事务处理的顺序。如果client发送事务请求到其他从节点server上,最终这个事务请求也会被从节点转发至Leader节点处理,由Leader决定该事务编号、执行的操作。
2、集群内部各服务器的调度者
举个例子:
现有 Zookeeper集群:一个Leader,两个Follower(甲、乙),两个client(a、b)
client-a向follower-甲发送一个事务请求(删除znode-a节点),同一时刻client-b向follower-乙发送了一个事务请求(修改znode-a节点信息)。(所谓的事务请求就是一些create、update、delete等与写有关的操作)
如果这两个事务请求让follower处理,就有可能造成follower-甲先删除znode-a节点,然后follower-乙去修改已经被删除的znode-a节点。
当follower将事务请求转发给leader时,leader根据接收到请求先后原则将事务请求进行编号、执行,就能有效避免
Follower(从节点、跟随者、下属):
1、处理client非事务请求,如果client发出的请求是事务请求,会转发给Leader。
2、参与集群对Leader选举投票(ZK中leader是通过投票选举出来的)。
3、参与事务请求 Proposal 的投票(leader发起的提案,要求follower投票,需要半数以上follower节点通过,leader才会commit数据);
PS:在ZooKeeper的实现中,每一个事务请求都需要集群中过半机器投票认可才能被真正应用到ZooKeeper的内存数据库中去,这个投票与统计过程被称为“Proposal流程”。
Observer(从节点、观察者、下属):
Observer除了不参与Leader选举投票外,与Follower作用相同。
PS:通常用于在不影响集群事务处理能力的前提下,提升集群的非事务处理能力。简单来说,observer可以在不影响集群写(CUD)性能的情况下,提升集群读(R)性能,并且因为它不参与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们failed,或者从集群中断开,也不会影响集群的可用性。
6、Zookeeper集群搭建
Zookeeper集群搭建指的是Zookeeper分布式模式安装(多台机器上安装多个zookeeper服务,并将这些服务互相注册互相关联,形成一个集群)。通常由 奇数 台servers组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能够得到多数的支持,所以Zookeeper集群的server数量一般为奇数。(详解请看下方PS补充)
PS:为什么是奇数台servers,之前介绍中经常有说到一个关键词(半数以上)。在zookeeper中,半数以上机制比较重要。例如:半数以上服务器存活,该集群才可正常运行;半数以上投票,本次事务请求才可通过等。
简单举例:
假如现在有一个集群,集群中有6台server,现在要进行一个投票,根据zookeeper投票机制:必须要 半数以上 的服务投票才算成功。由此可知,必须要有4台机器参与投票才可成功,剩余两台机器可以不参与投票。
假如现在又有一个集群,这个集群中有5台server,现在要进行一个投票,根据zookeeper投票机制:必须要 半数以上 的服务投票才算成功。在这个集群中,只需要3台机器参与投票就可成功,剩余两台机器可以不参与投票。这两个集群对比,经济上来说5台server比6台花钱更少,运行投票速度上来说,都是剩余两台机器不参与投票,而5台服务集群的只需要投票3次即可得结果,6台服务集群的需要投票4次。
Zookeeper集群搭建步骤:
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装 Leader+follower 模式集群,大致步骤如下:
-
配置主机名称及IP地址映射配置
-
准备jdk环境
-
安装Zookeeper
-
修改Zookeeper配置文件
-
设置myid
-
启动Zookeeper集群
如果想要使用Observer模式,可在对应节点的配置文件添加如下配置:
peerTypeobserver
其次,必须在配置文件指定哪些节点被指定为Observer,如:
server.1:localhost:2181:3181:observer
1、准备三台及以上服务器
既然是搭建集群,那么就必须有三台以上的机器来作为集群载体,并确保三台服务器的时间都同步、防火墙都已关闭、三台服务器之间都能ping通
PS:Xshell 输入一次命令,同时操作多态服务器小技巧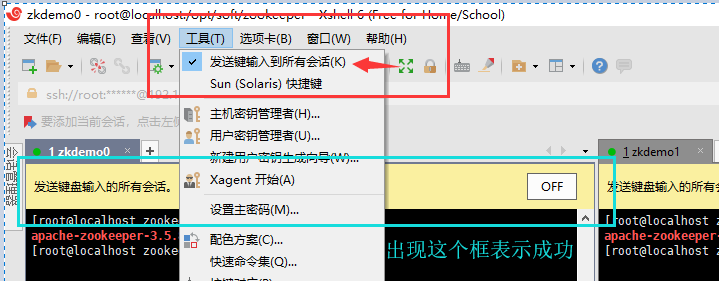
另外:
由于我搭建环境时,是同时操作的多台虚拟机,如果你 不想/不能 一次操作多台虚拟机,那么你也可以只操作一台虚拟机,在一台虚拟机上安装后zookeeper环境之后,在将zookeeper环境推送给其他虚拟机
例如:我在我zkdemo0机器上安装好了zookeeper,然后使用命令:【scp -r /opt/soft/zookeeper root@zkdemo1:/opt/soft】回车即可将zkdemo0中的ZK环境推送到zkdemo1虚拟机中(将一台虚拟机的文件copy到另一台虚拟机中)

在这里有个小坑:如果你的各个虚拟机之间没有配置主机名和IP映射,结果会是异常,例如我刚才的截图,就是没有配置主机名和IP映射(如果配置成功,不会出现ssh:xxxx一系列的异常提示,如果你不想配置,也可以使用ip来代替,如:scp -r /opt/soft/zookeeper/ root@192.168.xxx.xxx:/opt/soft)。
注意(重要):在完成zookeeper环境推送之后,你还需要在目标虚拟机上创建 ZK配置文件(zoo.cfg)中dataDir属性所指定的文件夹(当然,如果你的dataDir指定的文件夹在你推送的中间件中,你可以不创建)。然后将myid文件里面的内容修改为正确的映射关系。
1.1、配置主机名和IP映射
打开 /etc/hosts文件: vim /etc/hosts
输入内容:
192.168.xxx.xxx zkdemo0
192.168.xxx.xxx zkdemo1
192.168.xxx.xxx zkdemo2
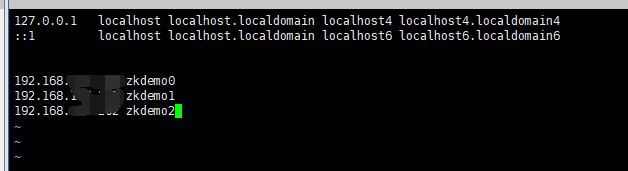
然后保存退出即可。(注意:每台机器都要配置哟)
配置完毕之后,第一次使用scp命令进行推送,系统会出现一个提示

这个提示的意思是虚拟机无法确定目标虚拟机的真实性巴拉巴拉,然后问你还要不要连接。输入【yes】即可。
连接上之后,还需要你输入目标虚拟机的密码,成功输入密码之后,即可开始推送。
2、安装jdk环境
由于Zookeeper运行需要jdk环境,因此要先给虚拟机安装上jdk环境
PS:自行安装

3、下载Zookeeper安装包至虚拟机
zookeeper下载地址:https://zookeeper.apache.org/releases.html 选一个你自己喜欢的版本,本次使用的是apache-zookeeper-3.5.8-bin.tar.gz
PS:如果你的虚拟机设置了连接外网,可以直接使用 wget https://mirror-hk.koddos.net/apache/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz 进行下载;如果没有联网,也可以本地下载完了之后,将压缩包上传到虚拟机上
方法1:直接将文件拖拽至虚拟机窗口界面(需要安装lrzsz【命令:# yum -y install lrzsz】(需要联网,要不然下载不了);
方法2:使用 FileZilla 等传输软件将文件上传到虚拟机;
方法3:将本地文件共享,通过共享等方式。
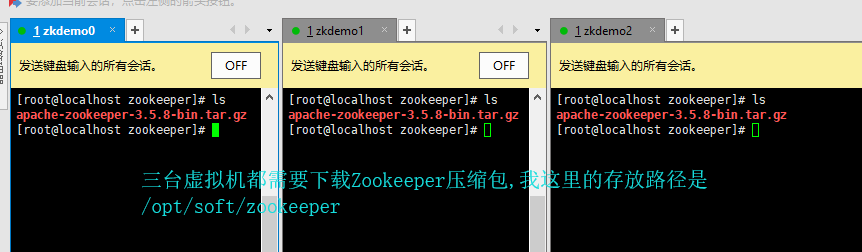
PS:建议各位都将安装的文件存放至/opt目录下的同一个文件夹中,方便管理。
4、解压Zookeeper压缩包
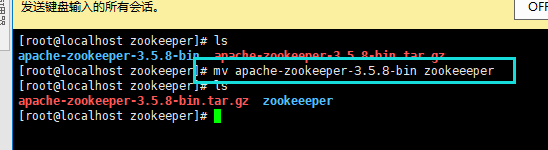
使用解压命令,解压压缩包:tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz(各位大佬下载的ZK压缩文件夹名)

PS:解压后的文件名有点长,可以使用命令进行重命名一下:mv apache-zookeeper-3.5.8-bin zookeeper
5、修改Zookeeper配置文件
zookeeper在启动的时候,会默认去查找一个zoo.cfg的配置文件(PS:刚解压的zookeeper文件中,是没有这个文件的,需要我们去创建一个)
zookeeper提供了一个样例的配置文件,其路径在 zookeeper/config/zoo_sample.cfg 。我们只需要将这个文件复制并重命名为 zoo.cfg ,那么zookeeper启动时需要的 zoo.cfg 就有啦。(注意:复制完了之后,还需要去修改配置文件里面的内容,毕竟zookeeper提供的只是一个样例配置)
1、先打开zoo_sample.cfg文件,瞧瞧里面都有些什么。
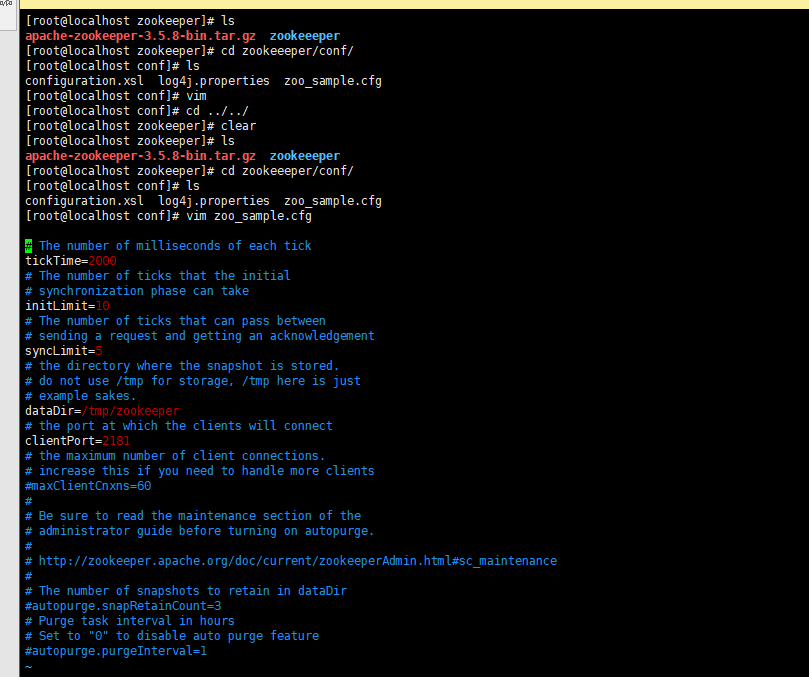
为了便于观看,我稍微对这个文件进行了简单的调整和解释
# Client-Server通信心跳时间
# Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
# Leader-Follower初始通信时限
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
# Leader-Follower同步通信时限
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 数据文件目录
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
dataDir=/tmp/zookeeper
# 客户端连接端口
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
# 对于一个客户端的连接数限制,默认是60,这在大部分时候是足够了。但是在我们实际使用中发现,在测试环境经常超过这个数,经过调查发现有的团队将几十个应用全部部署到一台机器上,以方便测试,于是这个数字就超过了。
# maxClientCnxns=60
# 服务器名称与地址:集群信息(server.服务器编号,服务器地址,LF通信端口,选举端口)这个配置项的书写格式比较特殊,规则如下:
# server.N=YYY:A:B
# server.1=zkdemo0:2888:3888
# server.2=zkdemo0:2888:3888
# server.3=zkdemo0:2888:3888
# autopurge.snapRetainCount、autopurge.purgeInterval -- 客户端在与zookeeper交互过程中会产生非常多的日志,而且zookeeper也会将内存中的数据作为snapshot保存下来,这些数据是不会被自动删除的,这样磁盘中这样的数据就会越来越多。不过可以通过这两个参数来设置,让zookeeper自动删除数据。autopurge.purgeInterval就是设置多少小时清理一次。而autopurge.snapRetainCount是设置保留多少个snapshot,之前的则删除。
# autopurge.snapRetainCount=3
# autopurge.purgeInterval=1
里面重点需要关注的配置项有:dataDir、clientPort(一般不用更改)、server.N=YYY:A:B
2、复制zoo_sample.cfg为zoo.cfg
-
在复制之前,我们需要创建一个ZK配置文件中 dataDir 属性需要的文件夹(不建议使用默认的)
命令:mkdir zkdata
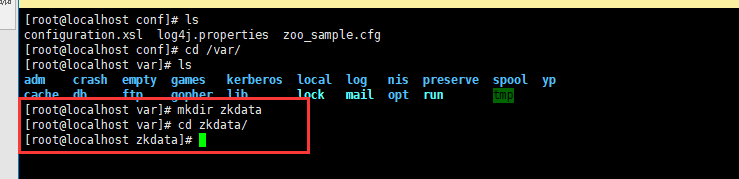
PS:我创建的路径是 /var/zddata 大佬可根据自己习惯创建这个文件夹,但要自己记得哟 -
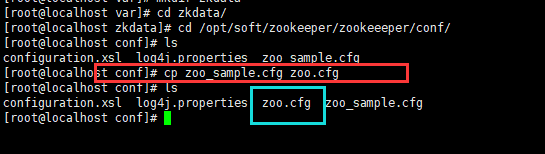
创建好dataDir之后,复制zoo.cfg
命令:cp zoo_sample.cfg zoo.cfg
-
修改zoo.cfg中的dateDir配置
命令:vim zoo.cfg 进入zoo.cfg编辑界面,对zoo.cfg文件进行编辑

将dataDir参数地址更改为刚才创建的文件夹地址。 -
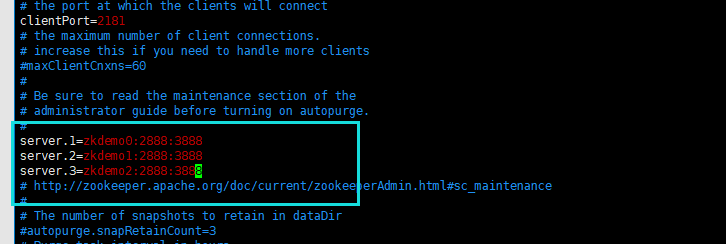
修改完dataDir配置之后,开始配置这个集群中其他机器的一些信息:server.N=YYY:A:B
在配置文件夹末尾添加配置信:
// server.机器编号=机器名/IP地址:2888:3888 (机器编号是步骤6设置的myid文件内容) server.1=zkdemo0:2888:3888 (zkdemo0 《= 这个填写你自己的机器名,如果没有做"主机名称与IP地址映射配置",则这里填写的就是IP地址,如: server.1=192.168.xxx.xxx:2888:3888) server.2=zkdemo1:2888:3888 server.3=zkdemo2:2888:3888
6、设置myid文件
给每台服务器指定编号
既然在配置文件中:server.N=YYY:A:B属性有一个N(服务器编号),那么我们也必须得手动的给服务器指定一个编号。
打开步骤5中 第2步创建的 zkdata 文件夹,在文件夹中创建一个名称为 myid 的文件,在文件中指定每台机器的编号(有多少台机器,就要给多少台机器指定编号,并且每台集合的编号要与server.N=YYY:A:B配置的一一对应。比如我的 zkdemo0机器,它的编号就为1、zkdemo1机器,它的编号就为2)

PS:如果你采用的推送方式创建集群,也需要手动的去修改myid文件
7、启动集群
当上诉步骤正确操作完成,表示ZK集群已基本搭建完成。
进入到安装zookeeper的目录中,使用命令:./bin/zkServer.sh start 来启动ZK(也可以使用全路径来启动 /opt/soft/zookeeper/zookeeper/bin/zsServer.sh start)
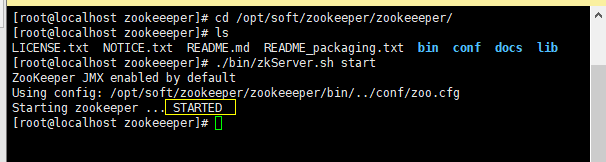
使用命令: ./bin/zkServer.sh status 来查看ZK状态
当出现一下界面,恭喜你,ZK启动成功(在线手动给你鼓掌)。
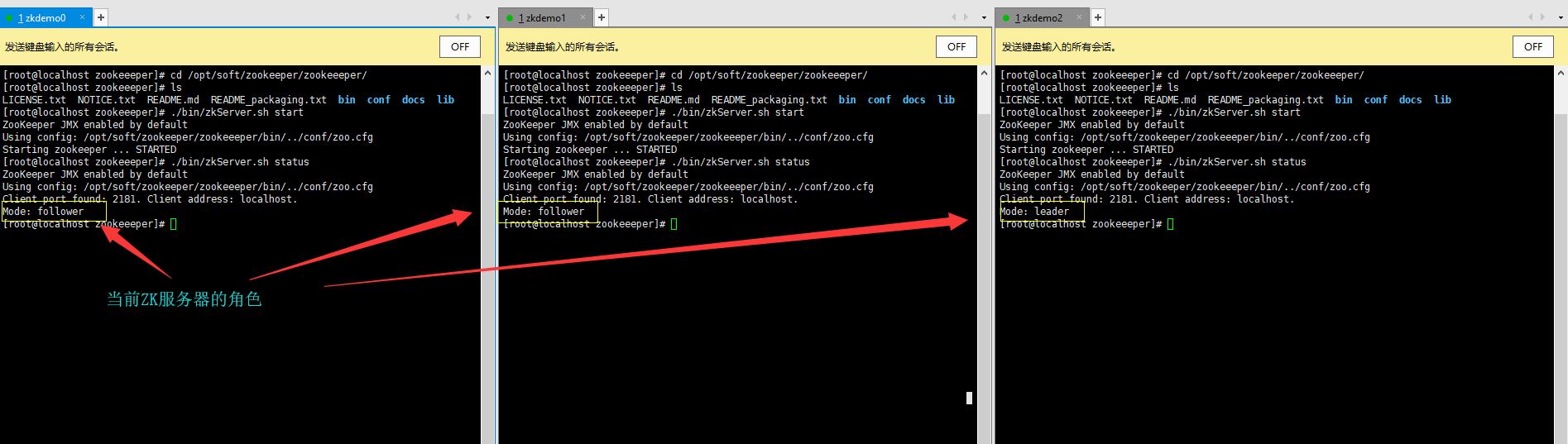
PS:如果出现以下提示,请检查你的防火墙是否未关闭(查看防火墙状态:firewall-cmd –state,关闭防火墙:systemctl stop firewalld.service,禁止防火墙开机启动:systemctl disable firewalld.service),关闭防火墙之后,再重新启动zookeeper集群即可

PS:如果你觉得全路径启动ZK服务比较麻烦,你也可以配置ZK的环境变量 ( 跟jdk配置类似 )
1、编辑/etc/profile文件
vi /etc/profile
2、 在profile中添加如下内容
ZOOKEEPER_HOME=/opt/soft/zookeeper/zookeeper (你自己虚拟机中,ZK的文件路径)
PATH=$PATH:$ZOOKEEPER_HOME/bin
export ZOOKEEPER_HOME PATH
3、立即使配置生效
source /etc/profile
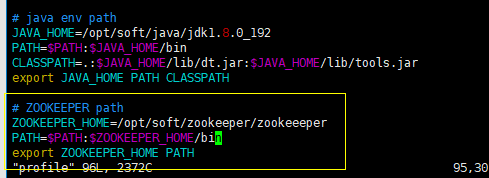
配置好了之后,就可以直接使用zkServer.sh start/sopt/status命令了;
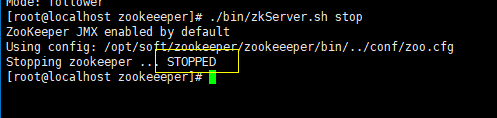
8、关闭服务
使用命令: ./bin/zkServer.sh stop来关闭ZK服务
单机版zookeeper服务搭建
额,单机版ZK服务搭建,步骤与集群版一致,搭建一台机器就可以了,只是配置文件(zoo.cfg)里不需要配置那么多其他集群机器
二、Zookeeper数据模型
概述:
Zookeeper具有分层的名称空间,在结构层次上与之最相近的就是Liunx的文件系统模型,都是采用的 树形层次结构:有一个根文件夹,下面可以有很多子文件夹。Zookeeper的数据模型也有一个 固定的根节点(/),我们可以在根节点下创建很多的子节点,并且在子节点下还可以继续创建子节点,每一个节点都被称为—Znode。在Zookeeper树中,每一层级都用斜杠(/)分隔开,并且 只能用绝对路径(如”get /tes/ctestt”)的方式获取Zookeeper节点及其信息,而 不能使用相对路径。
数据模型示例:
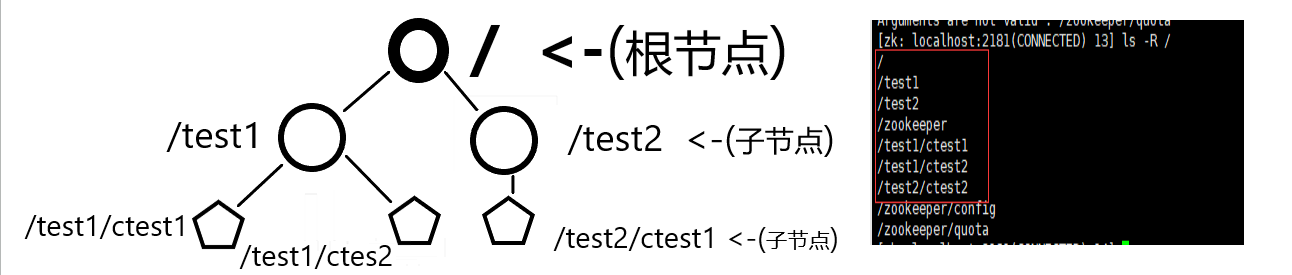
但与文件系统模型不同的是:
1、Zonde兼具文件和目录两种特点:即可以像文件一样维护数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分,并可以具有子Znode。并且在权限允许的情况下,用户对Znode具有增、删、改、查等操作。
2、Znode具有原子性操作:每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作(CRUD)。
节点名称要求:
1、空字符(\ u0000)不能是路径名的一部分。
2、不能使用特殊字符做为路径名,如:?、/、!@#¥等
3、“。” 字符可以用作其他名称的一部分,但“。” 和“ …”不能单独用于指示路径上的节点,因为ZooKeeper不使用相对路径。以下内容将无效:“ / a / b /./ c”或“ /a/b/…/c”。
节点类型:
知道了 ZooKeeper 的数据模型是一种树形结构之外,还需要知道ZK的节点类型。就像在 MySQL 中数据是存在于数据表中一样,ZooKeeper 中的数据是存储在每个节点上的。和我们在创建 MySOL 数据表时会定义不同类型的数据列字段一样,概括来说ZooKeeper 中的数据节点也分为**持久节点、临时节点和有序节点**三种类型:
1、持久节点:
这种节点是在 ZooKeeper 最为常用的、几乎所有业务场景中都会包含持久节点的创建。之所以叫作持久节点是因为一旦将节点创建为持久节点,该数据节点会一直存储在 ZooKeeper 服务器上,即使创建该节点的客户端与服务端的会话关闭了,该节点依然不会被删除。如果我们想删除持久节点,就要显式调用 delete 函数进行删除操作。
2、临时节点:
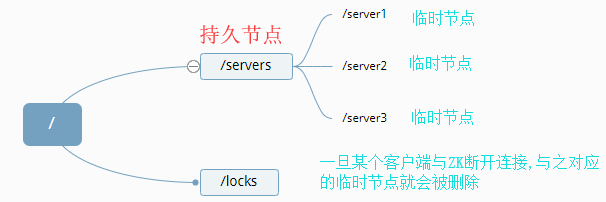
从名称上可以看出该节点的一个最重要的特性就是临时性。所谓临时性是指:如果将节点创建为临时节点,那么该节点数据不会一直存储在 ZooKeeper 服务器上。当创建该临时节点的客户端会话因超时或发生异常而关闭时,该节点也相应在 ZooKeeper 服务器上被删除。同样,我们可以像删除持久节点一样主动删除临时节点。值得注意的是:临时节点不允许有子节点。
示例场景:可以利用临时节点的这一特性来做服务器集群内机器运行情况的统计,将集群设置为“/servers”节点,并为集群下的每台服务器创建一个临时节点“/servers1”,当服务器下线时对应的临时节点自动被删除,最后统计临时节点个数就可以知道集群中的运行情况。
3、有序节点:
其实有序节点并不算是一种单独种类的节点,而是在之前提到的持久节点和临时节点特性的基础上,增加了一个节点有序的性质。所谓节点有序是说在我们创建有序节点的时候,ZooKeeper 服务器会自动使用一个单调递增的数字作为后缀(长度为10的数字,从0000000000开始自增),追加到我们创建节点的后边。例如一个客户端创建了一个路径为 test/ctest 的有序节点,那么 ZooKeeper 将会生成一个序号并追加到该节点的路径后,最后该节点的路径为 test/ctest0000000000。通过这种方式我们可以直观的查看到节点的创建顺序。
节点的数据结构:
综上所述,虽然Zookeeper有几种不同类型的节点,但每个节点维护的内容都相同:一个二进制数组(byte data[],用于存储数据,并且默认情况下最大存储限制为1MB)、ACL访问控制信息、子节点数据(因为临时节点不允许有子节点,所以其子节点数据为null)、记录自身状态信息的字段stat。
示例:
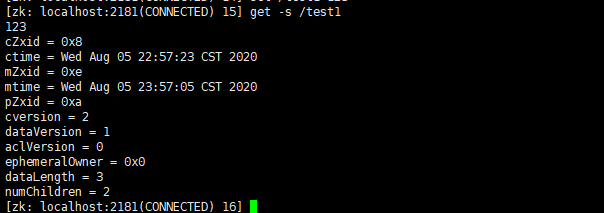
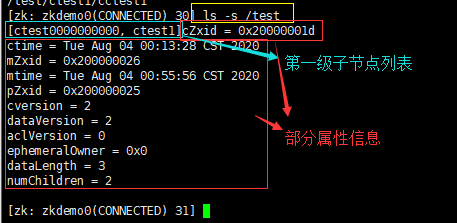
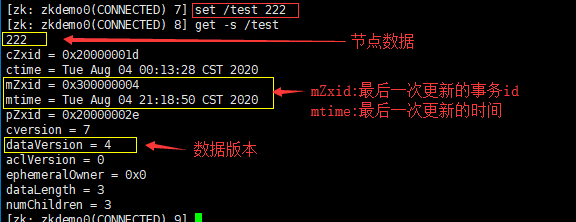
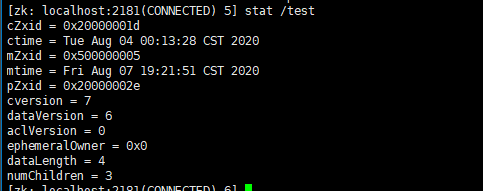
每一个节点都有一个自己的状态属性,记录了节点本身的一些信息,为方便阅读记忆,我将其整理了一下:
| 状态信息 | 说明 |
|---|---|
| cZxid | 该数据节点被创建时的事务ID |
| ctime | 该数据节点被创建的时间 |
| mZxid | 该数据节点最后一次被更新的事务ID |
| mtime | 该数据节点最后一次被更新的时间 |
| pZxid | 该数据节点的子节点列表最后一次被更新的事务ID(只有子节点新增/删除这个数据才会有变化) |
| cversion | 子节点版本号(只有子节点新增/删除这个数据才会有变化) |
| dataVersion | 该节点数据最后一次被更新的版本号(也就是该节点的版本号,只要被set,就会更新) |
| aclVersion | 该节点的ACL版本号 |
| ephemeralOwner | 创建临时节点,保存的会话SessionID,如果该节点为持久节点,那么这个属性值是0 |
| dataLength | 该节点的数据内容长度 |
| numChildren | 该节点的子节点个数 |
拓展:
结合数据模型特点,就可以解决一些分布式环境下一致性问题的啦,比如实现 锁 机制:
场景:高并发情况下,购物网站商品库存只剩一件,有两个客户A、B同时搜索到该商品并下单,为避免最后一件商品同时被两个人购买,我们可以在客户 A 对商品进行购买操作的时对这件商品进行锁定,从而避免B客户也购买成功,发生超卖现象。
实现锁的方式有很多中,这里通过ZK来实现悲观锁、乐观锁:
悲观锁:
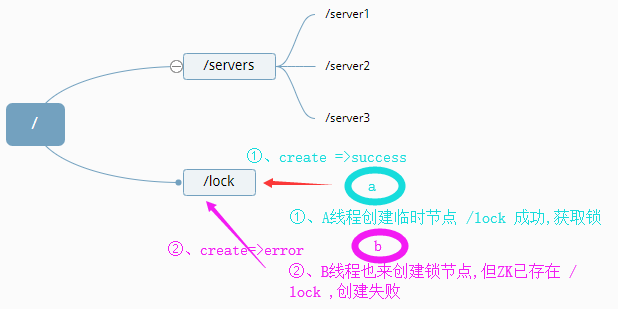
悲观锁认为进程对共享数据的冲突性操作总是会出现,为了保证进程在操作数据时,该条数据不被其他进程修改:数据会一直处于被锁定的状态。
实现:假设有A、B两个线程,同时访问了最后一件商品,我们通过线程在获取数据资源之前创建Zookeeper临时节点的方式,来对数据进行加锁、获取锁(ok,现在线程A成功创建了临时节点、获取了锁,对商品进行了锁定)。这时,线程B也来创建ZK临时节点对数据进行加锁、获取锁(因线程A已经成功创建了临时节点,根据节点不能重复创建原则,B线程创建必然失败,因此无法获取锁)。这样,一个简单的悲观锁就完成。
PS:为什么是创建临时节点而不是持久节点。这是因为,如果线程A创建好持久节点之后,突然死掉了,掉线了,那么这个持久节点会一直存在,数据就会一直被加锁,线程B无论如何也没办法创建节点获取锁了。但使用临时节点就不一样,就算A线程死掉、掉线。该临时节点会因为会话断开而被自动删除,这样B线程就能创建节点啦获取锁啦。
乐观锁:
乐观锁认为,进程对共享数据的冲突性操作一直不会出现,所以相对悲观锁而言。乐观锁不会全程都对数据进行加锁处理,而是在数据进行提交更新的时候,对数据的冲突与否进行检测,如果发现冲突了,则判定本次操作无效,拒绝操作。乐观锁的实现步骤基本可以分为读取、校验、写入(CAS(Compare-And-Swap))三个步骤:即获取、比较、替换,这就是一个乐观锁的实现。CAS 有 3 个操作数,旧的内存值 oldData,预期值newData,要修改的新值 upData。当且仅当预期值newData 和内存值 oldData相同时,将需要修改的值修改为 upData,否则什么都不做。
实现:在ZK上创建一个代表商品的节点,节点data就是商品的数量,每当商品被卖出去一次,该data就减一,并且该节点的版本号会加一(dataVersion);最终商品卖完之后,该节点data=0,dataVersion=商品数。当A线程操作商品之前,去读取ZK的商品节点,获取节点属性data与dataVersion(oldData)。卖商品(商品数减一,注意:此时商品数量虽然发生改变,但还没更新到数据库),在商品数更新到数据库之前,再去读取ZK的商品节点,获取新的节点属性data与dataVersion(newData),然后比较这两个数据是否相同,data是否还大于0等,条件都符号的情况下,先去更新节点数据,当更新节点数据成功,就可以刷新数据库商品数量了。
三、Zookeeper shell
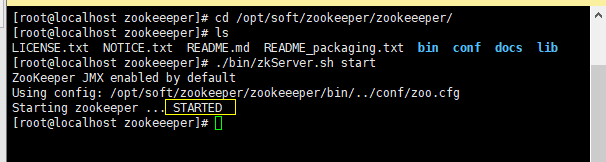
1、启动ZK服务器
通过Xshell连接虚拟机之后,在zookeeper文件目录下(如果配置了ZK环境变量的,直接启动就好),输入命令:./bin/zkServer.sh start。
2、启动客户端,连接服务器
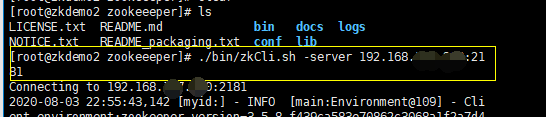
客户端连接服务端启动命令:zkCli.sh -server 【ip:port】
(如:ZK目录下 ./bin/zkCli.sh -server 192.168.xxx.xxx:2181 连接指定zk服务器。
也可以使用与IP映射的主机名来代替IP:ZK目录下 ./bin/zkCli.sh -server zkdemo0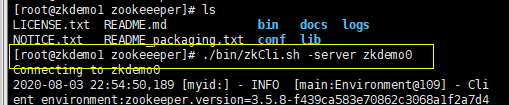
如果本机客户端连接本机服务器,可以直接输入:./bin/zkCli.sh即可)
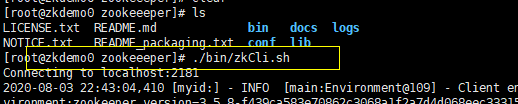
当显示如下界面,表示连接成功
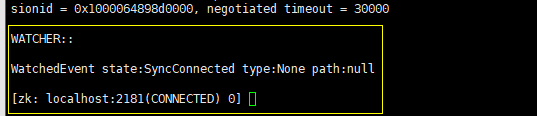
PS:我启动的是之前搭建的三台ZK服务器集群,为了更直观的体会到ZK服务集群的“全局一致性”这一特性,我这里的启动情况如下:
在“zkdemo0”机器上启动‘zkdemo0“客户端,连接到的“zkdemo0”服务器,
在“zkdemo1”机器上启动‘zkdemo1“客户端,连接到的“zkdemo0”服务器,
在“zkdemo2”机器上启动‘zkdemo2“客户端,连接到的“zkdemo2”服务器,
这样我通过“zkdemo0”客户端操作“zkdemo0”服务器上的节点之后,我在其他客户端看到的集群服务器上的节点数据应该就是一致的。(“全局一致性”)
Zookeeper基本操作-节点相关
创建节点
命令:create [-s] [-e] path data [acl]
解释:-s:指定节点特性:序列化(加编号);-e:指定节点特性:临时节点。若两个都不指定,则表示创建的一个 “非序列化的持久节点” 。path:节点的**完整路径**。data:该节点绑定的数据。acl:权限控制
PS:zookeeper中,节点的路径只有完整路径的概念,没有相对路径的概念,并且 不能出现同名同路径的节点
创建不同名路径节点情况:
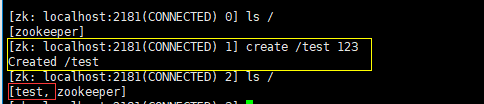
创建一个普通的持久节点(create /test 123):
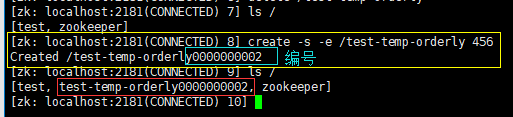
创建一个临时有序节点(create -s -e /test-temp-orderly 456):
测试:测试”持久节点/临时节点”特性:
刚才我是用”zkdemo0″客户端操作的”zkdemo0″服务端,现在断开“zkdemo0”客户端与“zkdemo0”服务端的连接(”ctrl+c”或”quit”命令)

再去连接“zkdemo0”客户端与“zkdemo0”服务端,并查询“zkdemo0”服务端的节点目录:
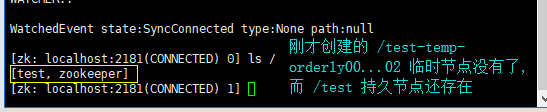
PS:若你是使用“ctrl+c”来断开服务器与客户端的连接,如果你重新连接的速度足够快,你会发现“/test-temp-orderly00…02”临时节点还存在,但过了几秒钟之后,该节点又不存在了。
原因:
1、每次ZK服务器与客户端连接时,都会创建一个唯一的session,当客户端创建临时节点的时候,会在该临时节点的状态属性(ephemeralOwner)保存这个session值。
2、ZK服务器是通过接收客户端每隔几秒钟发送的心跳数据包来确定该客户端是否还存活(心跳机制),当客户端异常下线时(例如“ctrl+c”,这里客户端没有主动告诉服务端我已经下线了,只是单方面的断开了连接),服务器不会立即知道该客户端下线断开连接了,所有没有立即删除该客户端在本次连接中创建的临时节点。当过了几秒钟之后,服务端没有接收到该客户端发送的心跳包,就断定该客户端下线(本次连接失效),然后才会去删除该客户端在本次连接中创建的临时节点。(心跳包中包含了session值,然后通过session值,找到服务器中所有与这个值相关的临时节点,删除)
3、在这里,虽然“zkdemo0”节点重新连接“zkdemo0”服务器的速度够快,但重连之后它们之间的session值已经更新了(与上次不同,每次连接都会创建一个新的),它们之间的心跳包数据也发生了变化(session值已经不同)。而服务器没有获取到上一次连接的心跳包(旧的心跳包,旧的session值),就会通过旧的心跳包中的session值去删除与这个值对应的临时节点。
4、使用“quit”命令来断开连接时,服务器会立即知道该客户端已下线,就会立即删除该客户端创建的临时节点。
创建同名路径节点情况:
创建两个同名同路径持久节点/临时节点(create [-e] /test 123):
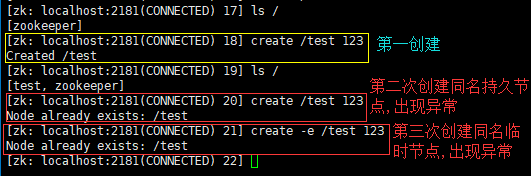
结论:不论是创建持久节点还是临时节点,都 不允许出现同名同路径节点。
创建两个同名同路径 有序 持久节点/临时节点(create -s [-e] /test-orderly):
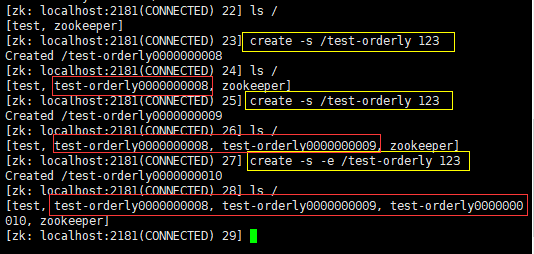
结论:创建有序节点时,ZK会自动给创建的节点进行编号(十位长度的数字,从0000000000开始编号,依次递增。如果根节点切换,编号数字又会从0000000000开始编),最终该节点的节点名称加上了编号,所以不会出现同名同路径的节点情况,并且可以通过这个编号知道哪个节点先创建,哪个节点后创建。

注意:
1、创建节点时,只能一级一级的创建,不能在不存在的节点上创建子节点(如:/test2节点不存在的情况下,create /test2/test1 123会出现异常)
2、临时节点不能有子节点
查询节点
命令:
ls [-s] [-w] [-R] path:列出该路径节点下的所有子节点(只能获取第一级的子节点列表);-s:指定:查询该路径节点时,除了子节点列表之外,还需要返回该节点的部分属性信息;-w:指定:查询该路径节点下的所有子节点,同时监听该节点,一旦该节点的子节点发生CUD(增删改)操作,立即推送消息给客户端;-R:指定:返回该路径节点下的所有的子节点列表
get [-s] [-w] path:获取该路径节点的数据内容(不会返回子节点列表);-s:指定:返回该节点的数据以及属性信息;-w:指定:当该节点数据/属性发生改变,立即推送消息给客户端。
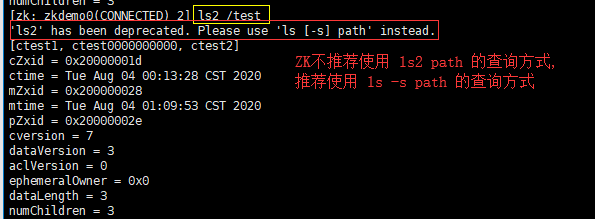
ls2 path [watch]:(该查询方式与ls -s path类似,不过ZK不推荐使用该查询方式)列出该路径节点下的所有子节点(只能获取第一级的子节点列表)以及部分属性信息;watch:指定:查询该路径节点下的所有子节点,同时监听该节点,一旦该节点的子节点发生CUD(增删改)操作,立即推送消息给客户端。
举例:
使用 ls [-s] [-w] [-R] path 命令:
ls /:查询 “/” 节点下的子节点列表:

ls -s /test:查询“/test”节点下的子节点列表及该节点的部分属性信息
ls -w /test:查询“/test”节点下的子节点列表并监听该节点,当该节点的子节点发生CUD,立即推送消息
①、监听:

②、修改子节点:

③、ZK的Watch机制推送消息:

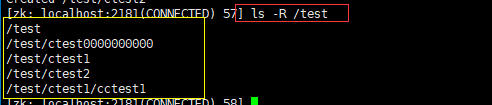
ls -R /test:查询”/test”节点下的所有的子节点列表
使用 get [-s] [-w] path 命令:
get /test:查询“/test”节点数据
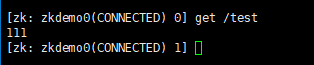
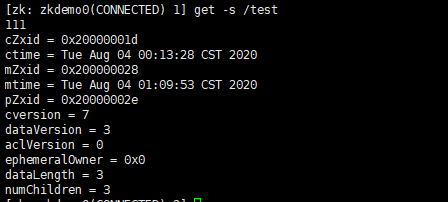
get -s /test:查询“/test”节点数据以及节点属性
使用 ls2 path [watch] 命令:
ls2 /test:查询“/test”节点下的所有子节点,以及部分属性信息
更新节点
命令:
set [-s] [-v version] path data:data:更新的内容;-s:指定,当修改成功之后,同时返回该节点的属性。-v version 表示数据版本( version值要与当前节点的 最新dataVersion 一致,否则会报错 )
示例:
更新前先查询(注意黄色框选区,这些都会随着每次更新而改变):
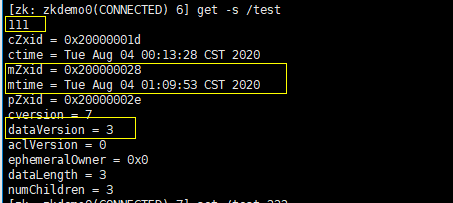
更新并查询:
删除节点
命令:
delete [-v version] path:删除指定路径节点(PS:如果要删除的节点存在子节点,那么必须先删除子节点,然后才能删除该节点)
deleteall path:删除该路径下的所有节点(递归删除节点)。
示例:
delete path:删除 ”/test-orderly0000000008“,由于该节点下没有子节点,所以可以直接删除

deleteall path:递归删除“/test-orderly0000000009”节点(删除含有子节点的节点)
1、先使用delete path命令测试:

2、使用deleteall path删除

Zookeeper基本操作-其他命令
xxxqutota:操作节点限制
setquota -n|-b val path:对节点添加限制。
-n:表示该节点下,其子节点的最大个数(该节点本身也要算进去);-b:表示该节点的空间大小(byte);val:指定的值
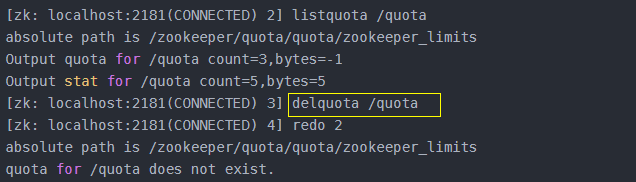
listquota path:列出指定节点的quota
delquota [-n|-b] path:删除目标节点的限制
示例:
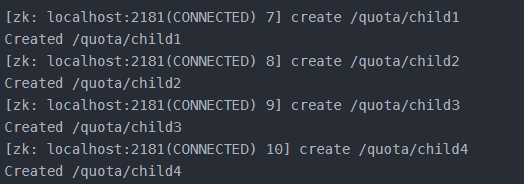
1、创建节点,并查询节点quota

2、设置:限制子节点个数为3

3、测试创建多个子节点
4、查询日志

PS:从日志中可以看出,在创建第三个节点时(count=4,quota节点本身也算一个。)就开始输出警告信息,但ZK并不会直接报错,继续创建节点也能成功(由此可看出quota是软限制)。(查看日志方法)
5、删除quota信息
PS:我在测试 “setquota -b 100 /quota”始终都会报错,百度捣鼓了很长时间都没搞出来,有没有大佬知道的留言一下,手动抱拳感谢
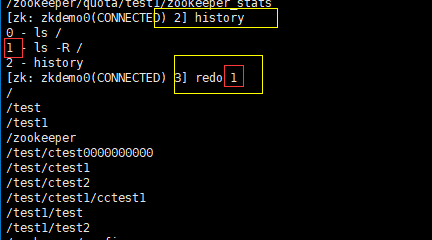
history:列出历史命令
redo cmdno:重新执行指定命令编号的历史命令
ps:一般与history连接使用
示例:
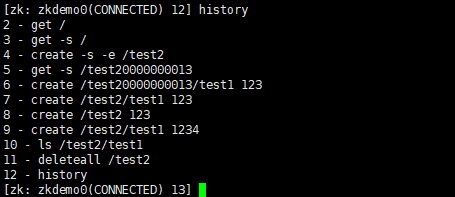
PS:只能列出最近十个
stat [-w] path:查询节点状态
getAcl [-s] path:查看ACL

setAcl [-s] [-v version] [-R] path acl:设置ACL

addauth:增加授权用户

注意:在给节点设置自定义用户ACL权限时,一定一定要注意:
auth模式与digest模式设置自定义用户ACL权限的不同:
auth 模式:
addauth digest <用户>:<明文密码> #添加认证用户,注意:密码是明文密码
setAcl <path> auth:<user>:<acl>

- 首先,需要给上下文添加一个认证用户 addauth,密码为明文密码
- 其次设置权限
- 查看节点数据之前,必须确保用有认证用户的上下文,否则会报:Authentication is not valid : xxx
digest模式
setAcl <path> digest:<用户>:<密文>:<acl>#注意:密码是密文密码(BASE64(SHA1(password))的字符串)
digest加密模式相对于auth来说要稍微麻烦特殊一些,需要对明文密码进行BASE64(SHA1(password))的处理。
ps:在shell中通过以下命令可以计算:
生成admin:123对应的加密密文

切记:生成的是admin:123对应的密文,如果将admin换为其它,密文则不一样。
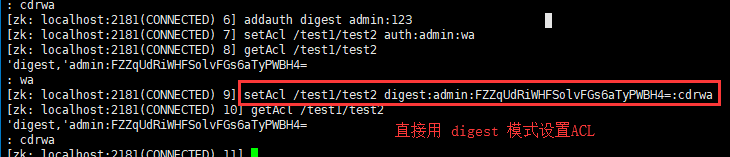
- 首先,获取密码加密后的密文
- 然后直接设置节点的ACL权限
- 查看节点数据之前,必须确保用有认证用户的上下文,否则会报:Authentication is not valid : xxx
切记:使用digest模式设置ACL的时候,密码一定一定一定不要用明文密码(如果你不小心用成明文密码了,莫慌,淡定,接着往下看)
PS:auth模式与digest模式的区别在于,前者需要先认证用户,然后设置ACL,后者在于直接用加密密文设置ACL,然后在认真用户
ip认证模式

设置超级管理员:
当我们一不小心,通过digest设置ACL的时候,密码弄错了,弄成明文的了。怎么也认证不了正确的用户,导致某znode节点无法被操作,这时候,我们就需要一个超级管理员角色。
以超级管理员: root:123456为例
先获取到 root:123456 的密文:u53OoA8hprX59uwFsvQBS3QuI00=
再去编辑zookeeper根文件夹中的/bin/zkServer.sh文件,添加超管配置(没有错,就是Zk的服务端启动文件,因此建议你修改之前,先备份哟,免得改错了还不回来)

打开文件之后,找到如下一行:
nohup “$JAVA” $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.xxxxx"
#有可能你的跟我的不一样,反正是"nohup "$JAVA" xxxx"开头就对了,这是脚本中启动zk的命令,我们在其中添加一个超级管理员的配置
"-Dzookeeper.DigestAuthenticationProvider.superDigest=root:u53OoA8hprX59uwFsvQBS3QuI00="
#注意格式.完事之后,保存,启动集群

集群启动完毕,启动客户端,连接集群。输入命令给上下文添加超级管理员认证
addauth digest root:123456 #这样,一个ZK超级管理员设置就完成,披着超管马甲,你将随心所欲
登上我的超管马甲,填平之前掉的坑(第一次用 digest 模式设置节点ACL,密码用成明文了,结果这个节点死活删不了)

四、Zookeeper Watch
在Zookeeper中,所有的读操作,包括getData()、getChildren()和exists(),都有一个开关,可以在操作的同时设置一个watch。在ZooKeeper中,Watch是一个一次性触发器,会在被设置watch的数据发生变化的时候,发送给设置watch的客户端。
ps:类似于设计模式中的观察者模式,但与观察者模式是有区别的,观察者模式最核心或者说关键的代码就是创建一个列表来存放观察者。而在 ZooKeeper 中则是在客户端和服务器端分别实现两个存放观察者列表,即:ZKWatchManager 和 WatchManager。其核心操作就是围绕着这两个展开的。
watch的三个关键点:
-
一次性触发:
被监听的节点数据发生改变后,ZK的watch机制将发送一个监视事件给客户端。例如,如果客户端执行get -w ./test,然后/ test的数据被更改或删除,则客户端将获得/ test的监视事件。如果/ test再次更改,则除非客户端进行了另一次读取来设置新的监视,否则不会发送任何监视事件。如:

-
发送给客户:
Watch事件是 异步发送 到客户端的,这一特性也导致不同的客户端,收到watch的时间有可能不一样。但Zookeeper保证了顺序性:客户端在第一次看到监视事件之前,永远不会看到它设置过watch的值的变动。例如/test=123,此时在/test上设置了一次watch。如果/test突然变成了456,那么客户端会先收到watch事件的通知,然后才会看到/test=456。 Zookeeper 客户端和服务端是通过 Socket 进行通信的,网络时延和其他因素可能会导致不同的客户端看到watch和更新返回值的时间不同。关键在于,不同的客户端看到的内容,顺序都是一样的。
-
为其设置watch数据:
这意味着 znode 节点本身具有不同的改变方式。你也可以想象 Zookeeper 维护了两条监视链表: 数据监视和子节点监视(data watches and child watches) 。getData()和exists()设置data watch,而getChildren()设置child watch。或者,你也可以想象 Zookeeper 设置了不同的监视器,并且返回的数据都不同。getData()和exists()返回节点本身相关的信息,而getChildren()返回子节点的列表。因此,setData()会触发znode上设置的data watch(如果set成功的话)。一次成功的 create() 操作则会触发当前节点上所设置的data watch以及父节点的child watch。而一个成功的delete()操作将会同时触发当前节点的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
Watch由客户端连接上的ZooKeeper服务器在本地维护。这样可以减小设置、维护和分发watch的开销。当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。(简单来说就是在客户端与服务器断开的这个短暂瞬间创建了一个节点(注册watch),之后,客户端与服务端在重连之前,这个节点又被删除了。那么节点对于的watch事件就可能会被丢失)
- 注册watcher:get [-s] [-w] path 、exists、ls [-s] [-w] path
- 触发watcher create、delete、set
watch流程步骤:
Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听,通知给客户端:
1、客户端注册Watcher到服务端;
2、服务端发生数据变更;
3、服务端通知客户端数据变更;
4、客户端回调Watcher处理变更应对逻辑;
watch事件类型和通知状态:
Zookeeper使用WatchEvent对象来封装服务端事件并传递,WatchEvent中包含了每一个事件的三个基本属性:
通知状态(state)、事件类型(type)、目标节点(path)
统一个事件类型在不同的通知状态中,代表的含义是不同的。如下表所示:
| 通知状态(state) | 事件类型(type) | 触发条件 | 说明 |
|---|---|---|---|
| SyncConnected(0) | None(-1) | 客户端与服务端成功建立连接 | 客户端与服务器处于连接状态 |
| SyncConnected(0) | NodeCreated(1) | Watcher监听的节点被创建 | 客户端与服务器处于连接状态 |
| SyncConnected(0) | NodeDeleted(2) | Watcher监听的节点被删除 | 客户端与服务器处于连接状态 |
| SyncConnected(0) | NodeDataChange(3) | Watcher监听的节点数据发生改变 | 客户端与服务器处于连接状态 |
| SyncConnected(0) | NodeChildChange(4) | Watcher监听的节点其子节点列表(CD)发生改变 | 客户端与服务器处于连接状态 |
| Disconnected(0) | None(-1) | 客户端与服务器断开连接 | 客户端与服务器处于断开连接状态 |
| Expired(-112) | Node(-1) | 会话超时 | 此时客户端会话失效,通常同时也户收到SessionExpiredException异常 |
| AuthFailed(4) | None(-1) | 两种情况: 1、使用错误的schema进行权限检查 2、SASL权限检查失败 |
通常同时也会收到AuthFailedException异常 |
注意:
1、Watches通知是一次性的,接收到watch通知之后,必须再次重新注册。
2、同一个ZK客户端,反复对同一个ZK节点(znode)注册相同的watcher,是无效的,最终只会有一个生效。
3、客户端会话失效之后,所有这个会话中创建的Watcher都会被移除。
4、对某个节点注册了watcher,但是节点被删除了,那么注册在这个节点上的watcher都会被移除。
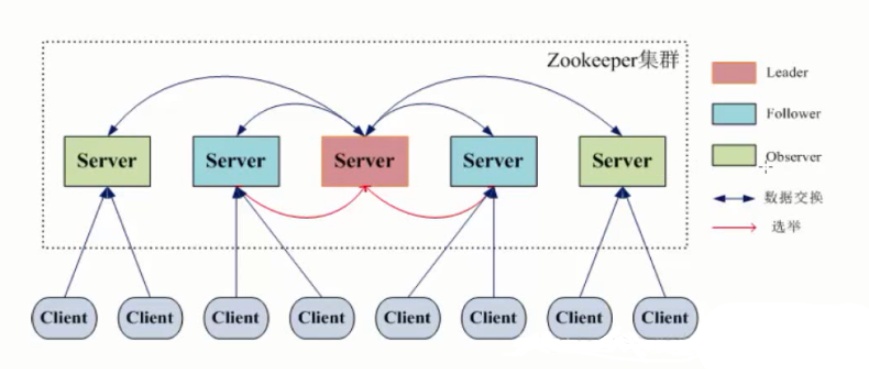
五、Zookeeper集群选举机制
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
1、服务器初始化启动
2、服务器运行期间无法和Leader保持连接(Leader挂掉了)
在Zookeeper中,它提供了三中选举算法:
- LeaderElection
- AuthFastLeaderElection
- FastLeaderElection(最新默认):采用 投票数大于半数则胜出 的逻辑
选举消息内容:
在选举过程中,需要将投票信息发送给集群中的所有服务器,它包含如下内容:
myid(服务器ID):在同一集群中,每一台服务器都有自己的myid,并且该id不能重复。该id编号越大,在选举算法中,该服务器的权重就越大(越容易成为leader)。
选举状态:zookeeper节点选举状态
ZXID(服务器最新事务id):初始值0,每一个服务器值发生变化,该值会递增。若该值越大,说明该服务器的数据越新,在选举算法中数据越新,其权重就越大。
epoch(逻辑时钟):也叫投票次数,从0开始递增。同一轮投票过程中,各个机器的逻辑时钟值是相同的。每投完一次票,该值就会增加,然后与接收到的其他服务器返回的投票信息中的数据相对比。以此来判断其他机器的投票信息是否是最新的。(举个栗子:某台服务器在投票选举过程中,突然在某轮投票时因网络延迟,暂时挂掉了,投票未成功。那么该服务器逻辑时钟值肯定就会小于其他正常的服务器,也因此,该服务器的选举权重变小了。)
zookeeper节点选举状态
| 状态 | 描述 |
|---|---|
| LOOKING | 竞选状态:此时集群中还没有leader,所有机器都各自发起投票。 |
| Leading | 主节点状态:此时投票选举结束,被其他机器投票选举为Leader的机器状态就为Leading |
| Following | 从节点状态:此时投票选举结束,已经有机器被选举为了Leader,其他机器就是Follower,此时机器状态为Following |
| Observe | 观察者状态:此时投票选举结束,已经有机器被选举为了Leader,其他机器就是Follower,如果该机器被设置为Observer类型,其状态就是Observe。 |
最初的时候,每个server的最初状态都是LOOKING,然后每台server开始选举投票。当leader服务器选举出来后,leader服务器状态变为LEADING,其他服务器变为Following(如果server的类型是Observer,则该机器状态为Observe)。当leader服务器挂掉之后,所有的Follower状态都改为LOOKING,又重新开始新的选举。
核心选举原则:
1、Zookeeper集群中,只有超过半数以上的机器正常运行,集群才能正常运行。
2、集群最开始启动时,每个服务器既可以给自己投票,也可以给其他服务器投票,myid小的服务器给myid大的服务器投票,直到选出Leader,服务开始正常运行。(可以理解为每个服务器都是自私的,都想自己当领导,所有搭都会投自己一票,如果发现自己myid比其他服务器小,就会与id大的服务器进行结果交换,将自己的票投给myid大的服务器。)
3、选出Leader之后,服务器状态发生改变。
Leader选举:
由于ZK选举机制很牛皮,FastLeader算法会根据集群服务器发出的选举消息包内容状态不同,做不同的事,最终选举出集群中的最优Leader。因此作为菜鸡的我,在这里只描述了其逻辑中的大概流程,如果你对其选举机制感兴趣,可以多去百度and阅读源码。
Leader选举分两种情况:服务器初始化启动、服务器运行时期的Leader选举
服务器初始化启动:
若进行Leader选举,则至少需要两台机器,这里以5台机器组成的集群为例,它们的myid分别是1-5;同时,它们也是第一次同时启动,并且假设它们的启动顺序是1 –> 5
根据集群正常运行原则:只有超过半数以上的服务器启动运行,集群才能正常运行。也就是说,目前最少需要启动3台服务器。
-
服务器①启动,发起一次选举Leader请求:
(1)、每个server都发出投票信息:
在发起投票时,服务器都会将自己作为Leader服务器来进行投票,将(myid 、 zxid 、 选举状态、epoch)作为投票信息,发送给集群中的其他机器。由于是初始情况,zxid与epoch都为0,
此时服务器①将自己的投票信息(1,0,Looking,0)发送给集群中已启动的其他机器。
PS:每次的投票信息会包含所推举的服务器的 (myid 、 zxid 、 选举状态、epoch),由于集群服务刚启动,Leader还未选举出来,所以每台机器此时的ZXID都为0;epoch的值也是从0开始递增)
(2)、集群中,已启动机器接收投票信息:
没有接收到其他机器的投票信息
(3)、处理投票信息:
没有投票信息
(4)、统计投票、得出结果:
总投票数只有自己一票、投票数没有过半(3票),因此选举失败,,服务器状态继续保持Looking,选举请求结束。
-
服务器②启动,发起一次选举Leader请求:
(1)、每个server都发出投票信息:
服务器①投票信息(1,0,Looking,epoch)、服务器②投票信息(2,0,Looking,epoch),此时各自将投票信息发送给集群中其他已启动的机器。
(2)、集群中,已启动机器接收投票信息:
每个服务器都会接收到其他机器的投票信息,判断该投票信息的有效性(根据epoch判断是否是本轮,根据选举状态判断是否来自Looking状态的服务器),然后会根据其投票信息内容的不同,对投票信息做不同处理。(我这里描述的是:默认epoch相同)
服务器①接收到(2,0,Looking,epoch),服务器②接收到(1,0,Looking,epoch)
(3)、处理投票信息:
有效性判断完毕,各服务器都需要将自己的投票信息和别人的投票信息进行对比PK,如果PK失败,会将自己的投票信息更新为胜者的投票信息,然后重新发送投票信息,而PK成功的机器,只是再次像集群中的机器发出上一次的投票信息即可:
对于服务器①而言,它的投票是(1,0,Looking,epoch),接收到服务器②的投票信息(2,0,Looking,epoch),经过PK,服务器①失败,于是更新自己的投票信息为(2,0,Looking,epoch)并重新将其发出。对于服务器②而言,接收到服务器①的投票信息进行PK,PK胜出,无需更改自己的投票信息,只是再次像集群中的机器发出上一次的投票信息即可。
PS:投票规则:优先比较epoch,逻辑时钟小的选举结果会被忽略,重新投票;在epoch相同的情况下,则比较ZXID,ZXID大的服务器则胜出。当ZXID相同,那就比较myid,myid大的服务器则胜出。在集群初始启动时,由于zxid都为0,因此直接比较的是myid
(4)、统计投票、得出结果
每次投票后,服务器都会统计投票信息,判断自己得票数是否过半,然后根据判断结果做出结论。
本次选举请求中,一共有两轮投票:第一轮投票服务器①接收到的投票信息是(2,0,Looking,epoch),服务器②接收到的投票信息是(1,0,Looking,epoch);经过对比判断,服务器①更改自己的选票,统计投票结果,两个服务器得到的票数都没有过半,因此这两个服务器状态保存为Looking。然后开始了第二轮的投票。第二轮投票两个服务器接收到的投票信息都是(2,0,Looking,epoch),统计投票结果后发现服务器②得到的票数没有过半,两个服务器状态依然保持为Looking,选举请求结束。
-
服务③启动,发起一轮选举Leader请求:
(1)、每个server都发出投票信息:
服务器①投票信息(1,0,Looking,epoch)、服务器②投票信息(2,0,Looking,epoch)、服务器③投票信息(3,0,Looking,epoch),此时各自将投票信息发送给集群中其他已启动的机器。
(2)、集群中,已启动机器接收投票信息:
服务器①接收到(2,0,Looking,epoch)、(3,0,Looking,epoch),服务器②接收到(1,0,Looking,epoch)、(3,0,Looking,epoch),服务器③接收到(1,0,Looking,epoch)、(2,0,Looking,epoch)
(3)、处理投票信息:
经过PK,最终:服务器①更新自己的投票信息为(3,0,Looking,epoch);服务器②更新自己的投票信息为(3,0,Looking,epoch);服务器③投票信息不变。三台服务器将新的投票信息重新发出。
(4)、统计投票、得出结果:
第一轮接收到投票信息之后,每台服务器统计发现自己的票数都没有过半数,服务器状态保持Looking;第二轮接收到投票信息之后,服务器③发现自己票数超过半数,因此服务器③设置自己的状态为Leading,并告诉其他两个服务器,我已经是Leader了。因此服务器①、②根据自己机器类型,将自己状态设置为Follower。(如果机器类型为Observer,则状态会设置为Observe)
-
服务器④启动,发起一轮Leader请求:
(1)、每个server都发出投票信息:
服务器①投票信息(1,0,Follower,epoch)、服务器②投票信息(2,0,Follower,epoch)、服务器③投票信息(3,0,Leader,epoch),此时各自将投票信息发送给集群中其他已启动的机器。
(2)、集群中,已启动机器接收投票信息:
服务器①接收到(2,0,Follower,epoch)、(3,0,Leader,epoch)、(4,0,Looking,epoch),服务器②接收到(1,0,Follower,epoch)、(3,0,Leader,epoch)、(4,0,Looking,epoch),服务器③接收到(1,0,Follower,epoch)、(2,0,Follower,epoch)、(4,0,Looking,epoch),服务器④接收到(1,0,Follower,epoch)、(2,0,Follower,epoch)、(3,0,Leader,epoch)
(3)、处理投票信息:
服务器④发现服务器③已经是Leader
(4)、统计投票、得出结果:
根据自己服务器类型修改自己服务的状态Follower/Observer
-
服务器⑤启动,发起一轮Leader请求:
逻辑与服务器④类似,最终结果:根据自己服务器类型修改自己服务的状态Follower/Observer
服务器运行时期的Leader选举
当Leader宕机后,余下的所非Observer的服务器都会将自己的状态变更为Looking,然后开启新的Leader选举流程。
还是以5台服务器为例,假设服务器③死掉了,那么服务器①、②、④、⑤都会将自己的状态从Follower变成Looking,然后发起一轮选举投票:
-
变成状态:
服务器③宕机,服务器①、②、④、⑤都会将自己的状态从Follower变成Looking
-
每个Server会发出一个投票:
由于集群已经运行过一段时间,那么服务器中的zxid肯定是有值的,并且此时服务器还是会将自己作为Leader服务器来进行投票,将(myid 、 zxid 、 选举状态、epoch)作为投票信息,发送给集群中的其他机器。
服务器①投票信息(1,zxid ,Looking,epoch)、服务器②投票信息(2,zxid ,Looking,epoch)、服务器④投票信息(4,zxid ,Looking,epoch)、服务器⑤投票信息(5,zxid ,Looking,epoch),此时各自将投票信息发送给集群中除Observer的其他正常运行的机器。
PS:每由于集群服务已经运行过一段时间,所以每台机器此时的ZXID都有值
-
接收各个服务器的投票信息:
每个服务器都会接收到其他机器的投票信息,先判断该投票信息的有效性(根据epoch判断是否是本轮,根据选举状态判断是否来自Looking状态的服务器),然后会根据其投票信息内容的不同,对投票信息做不同处理。(我这里描述的是:默认epoch相同)
服务器①接收到(2,zxid ,Looking,epoch)、(4,zxid ,Looking,epoch)、(5,zxid ,Looking,epoch),服务器②接收到(1,0,Looking,epoch)、(4,zxid ,Looking,epoch)、(5,zxid ,Looking,epoch),服务器④接收到(1,zxid ,Looking,epoch)、(2,zxid ,Looking,epoch)、(5,zxid ,Looking,epoch),服务器⑤接收到(1,zxid ,Looking,epoch)、(2,zxid ,Looking,epoch)、(4,zxid ,Looking,epoch)。
-
处理投票:
与启动时过程类似。
-
统计投票、得出结果:
与启动时过程类似。
PS:服务器初始化启动/服务器运行时期的Leader选举两种选举类型正常情况下的大概逻辑如上所述,当然实际代码逻辑更优更细化,如需深入了解的,可以尝试阅读源码哟。
附录:
Zookeeper常用命令
// 以下命令,都在 zookeeper目录 下执行
./bin/zkServer.sh start (启动zk服务器)
./bin/zkServer.sh status (查看zk服务器状态)
./bin/zkServer.sh stop (停止zk服务器)
./bin/zkServer.sh restart (重启zk服务器)
./bin/zkCli.sh -server 【ip:port】 (使用客户端连接服务端,如:./bin/zkCli.sh -server 127.0.0.1:2181。连接本机zk服务器)
// 以下命令,都在zk客户端执行
// 节点操作相关
create [-s] [-e] path data [acl] 创建节点
ls [-s] [-w] [-R] path 查询节点下的子节点列表
get [-s] [-w] path 获取目标节点的值以及属性
set [-s] [-v version] path data 更新节点数据
delete [-v version] path 删除目标节点(该目标节点不能有子节点)
deleteall path 删除目标节点以及目标节点的子节点
// 其他命令
客户端状态下 ctrl+c 退出客户端
quit (退出客户端)
help (查看客户端帮助命令)
setquota -n|-b val path 给节点添加限制
listquota path 列出目标节点的限制
delquota [-n|-b] path 删除目标节点的限制
history 列出最近十次的历史命令
redo cmdno 重新执行指定命令编号的历史命令(一般与history连接使用)
stat [-w] path 查询节点状态
getAcl [-s] path 查询节点ACL权限
addauth digest <user>:<password> 给上下文添加一个认真用户
setAcl [-s] [-v version] [-R] path auth:<user>:<acl>
auth模式设置节点ACL权限
setAcl [-s] [-v version] [-R] path digest:<用户>:<密文>:<acl>
digest模式设置节点ACL权限
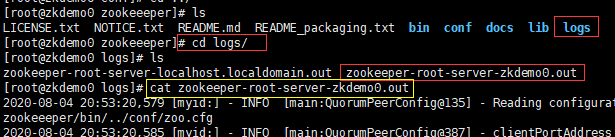
ZK查看日志
在zookeeper的服务器文件目录下,有一个logs文件夹,里面存储的就是日志文件
如果对您有帮助请帮忙转发让更多小伙伴看见【https://blog.csdn.net/qq_43530416/article/details/107944942】
如果有疑问、描述有误、内容更新,请各位大佬留言,我会及时更新。
PS:手动感谢
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/125581.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
