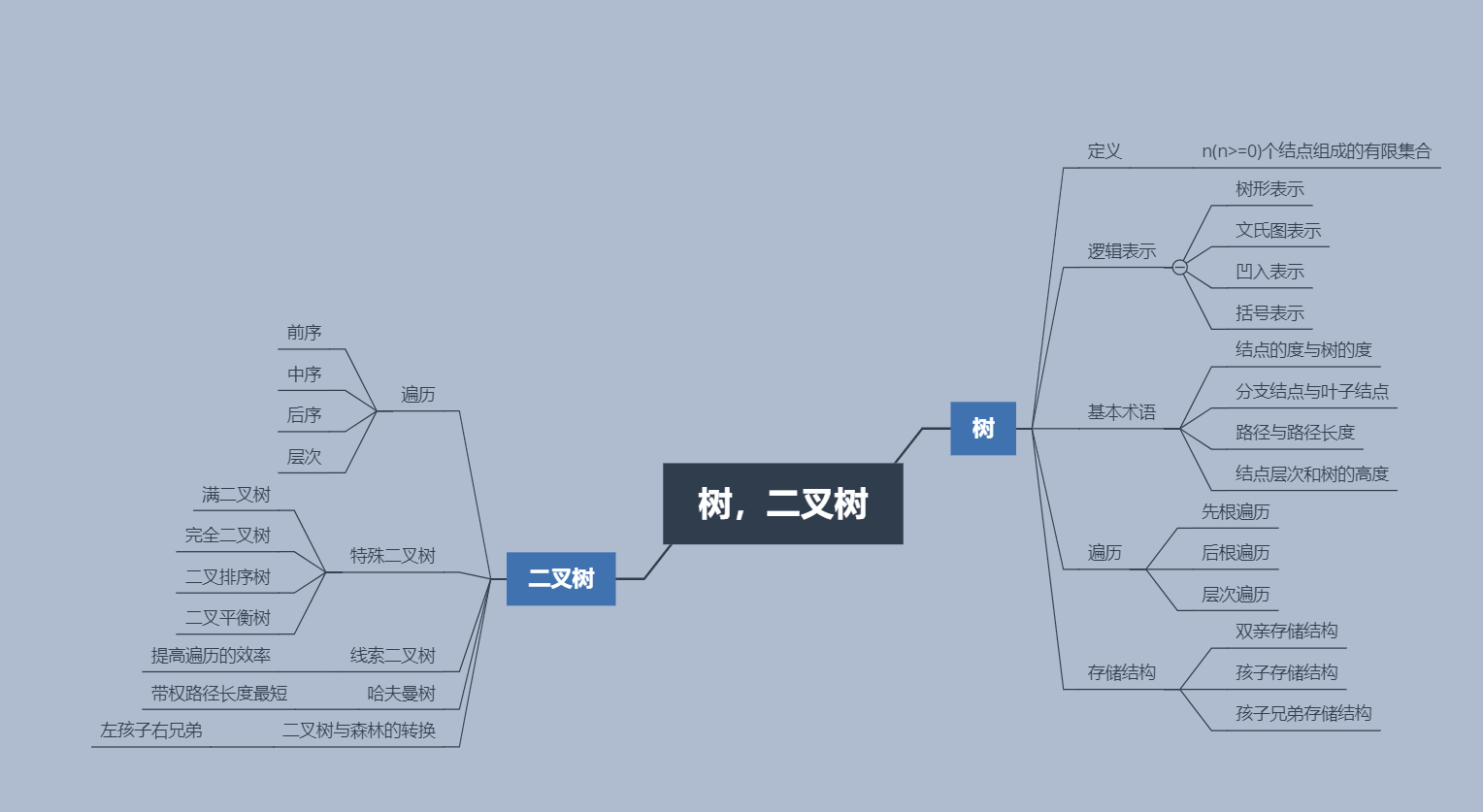
一.思维导图

二.重要概念的笔记
1. 树的基本术语
1.树中一个结点的子结点个数称为该结点的度。
树中结点的最大度数称为树的度。
2.度大于 0 的结点称为 分支结点(又称为非终端结点)。
度为 0 的(没有子女结点)的结点称为叶子结点(又称为终端结点)。
在分支结点中,每个结点的分支树就是该结点的度。
3.树中两个结点之间的路径是由这两个结点之间所经过的结点序列构成的.
路径长度是路径上所经过的边的个数。
注意:由于树中分支是有向的,即从双亲结点指向孩子结点,所以树中的路径是从上向下的,同一个 双亲, 结点的两个孩子结点之间不存在路径。
4.结点的层次从树根开始定义,根结点为第 1 层,它的子结点为第2 层,依次类推。
结点的深度是从根结点开始自顶向下逐层累加的。
结点的高度是从叶结点开始自底向上逐层累加的。
树的高度(又称为深度)是树中结点的最大层数。
2. 树的性质
- 树中的结点数等于所有结点的度数加1 。
- 度为 m 的树中第 i 层上至多有 m^(i-1) 个结点( i >= 1)。
- 高度为 h 的 m 叉树至多有 (m^h -1)/(m-1)个结点。
- 具有 n 个结点的 m 叉树的最小高度为 logm(n(m-1)+1) 。
3. 树的存储
1.双亲表示法:求父节点方便。
2.孩子表示法:求子节点方便。
3.孩子兄弟表示法:方便实现树和二叉树的相互转换。
4. 二叉树的性质
1.在二叉树的第i层上至多有2^(i-1)个结点(i>0)。
2.深度为k的二叉树至多有2^k-1个结点(k>0)。
3.对于任意一棵二叉树,如果其叶结点为N0,而度数为2的结点总数为N2,则N0=N2+1。
4.具有n个结点的完全二叉树的深度必为 log(2n)+1。
5.对完全二叉树,若从上至下、从左只右编号,则编号为i的节点,其左孩子编号必为2i,其有孩子编号必为2i+1;其双亲的编号必为i/2(i=1时为根 除外)。
5. B树
一个M阶的B树具有如下几个特征:
- 定义任意非叶子结点最多只有M个儿子,且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整;
- 非叶子结点的关键字个数=儿子数-1;
- 所有叶子结点位于同一层;
- k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。
6. B+树
m阶的B+树的特征:
- 有n棵子树的非叶子结点中含有n个关键字(B树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(B树是每个关键字都保存数据)。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
- 通常在B+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
- 同一个数字会在不同节点中重复出现,根节点的最大元素就是B+树的最大元素。
B+树相比于B树的查询优势:
- B+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
- B+树查询必须查找到叶子节点,B树只要匹配到即可不用管元素位置,因此B+树查找更稳定(并不慢);
- 对于范围查找来说,B+树只需遍历叶子节点链表即可,B树却需要重复地中序遍历,
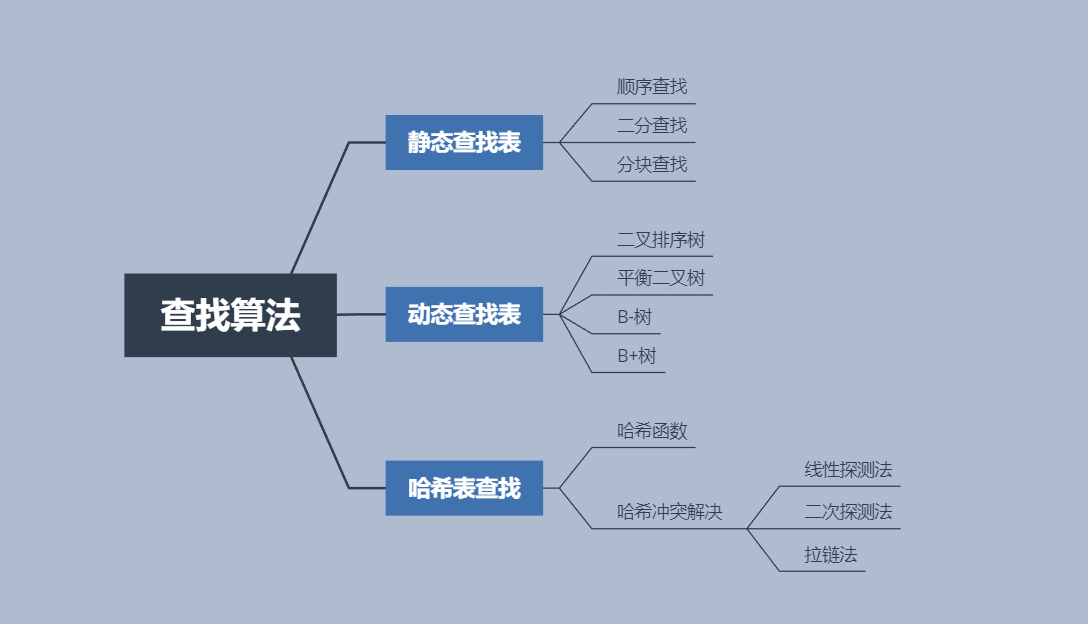
7. 哈希冲突的解决方法:
-
开放定址法:
线性探测法: 冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
二次探查法: 冲突发生时,在表的左右进行跳跃式探测,比较灵活。 -
拉链法:将所有关键字为同义词的结点链接在同一个单链表中。优点:
拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短。
由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况。
在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
三.疑难问题及解决方案
平衡二叉树刚开始构建的总会出错,不是很理解四种类型的构建方法,在老师讲解和练习下,已经可以熟练掌握。
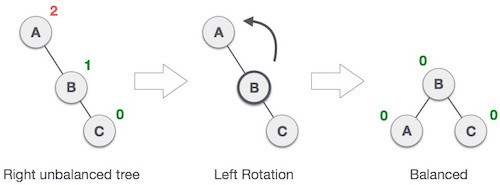
- 在结点的左孩子的左子树中插入数据(LL)
- 在结点的右孩子的右子树中插入数据(RR)
- 在结点的左孩子的右子树中插入数据(LR)
- 在结点的右孩子的左子树中插入数据(RL)
对于LL型的情况,要使用右旋来解决,将失衡点右旋到其左孩子的右孩子的位置,失衡点的左子树更新为其原来左孩子的右子树。
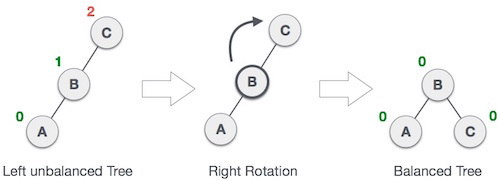

对于RR型的情况,要使用左旋来解决,将失衡点左旋到其右孩子的左孩子的位置,失衡点的右子树更新为其原来右孩子的左子树。

对于LR型的情况,要使用先对失衡点的左孩子进行左旋,然后再对失衡点进行右旋来解决。
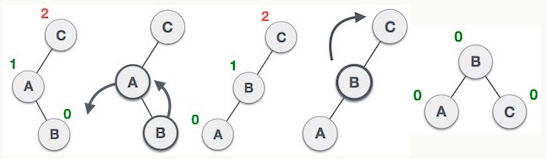
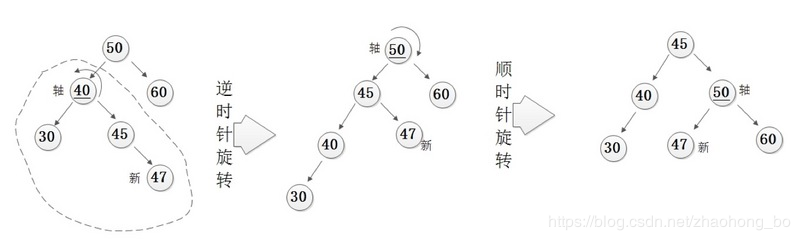
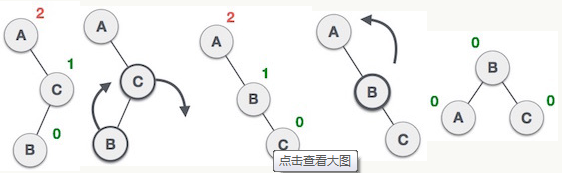
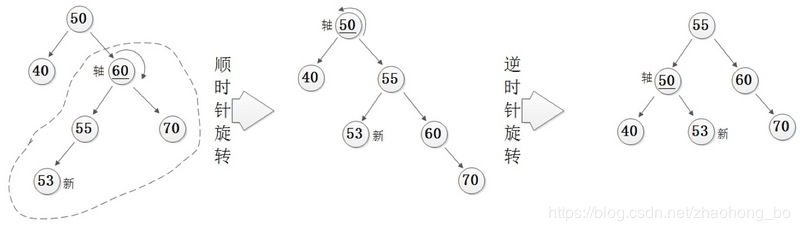
对于RL型的情况,要使用先对失衡点的右孩子进行右旋,然后再对失衡点进行左旋来解决。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/114448.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
