Hadoop环境搭建
环境:
VMware® Workstation 14 Pro
Centos7.0
Hadoop 2.7.5
Xshell6
jdk8.0
一、搭建Hadoop虚拟主机
1 创建虚拟机,命名位master(需要linux基础,和虚拟机使用基础)
2 上传jdk 、Hadoop2.7.5
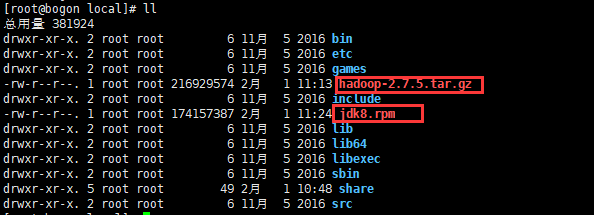

3 安装jdk
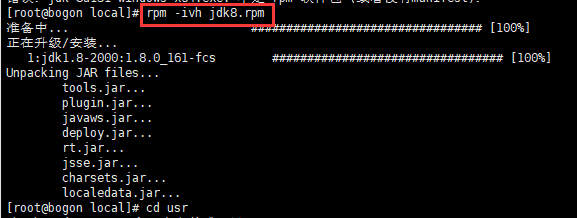
4 验证jdk安装是否正确:
5、解压hadoop

6、解压后,重命名hadoop
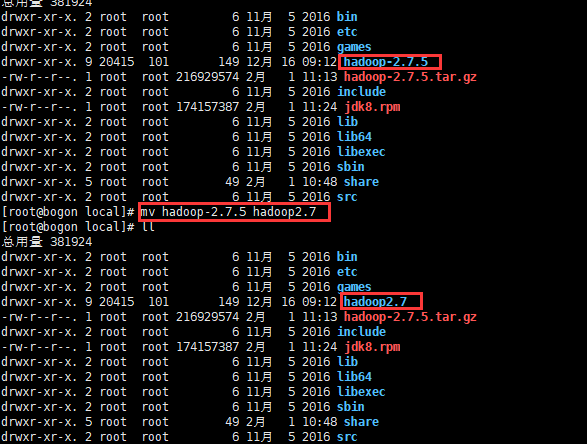
7、配置hadoop
进入etc目录
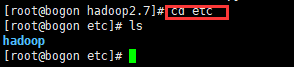
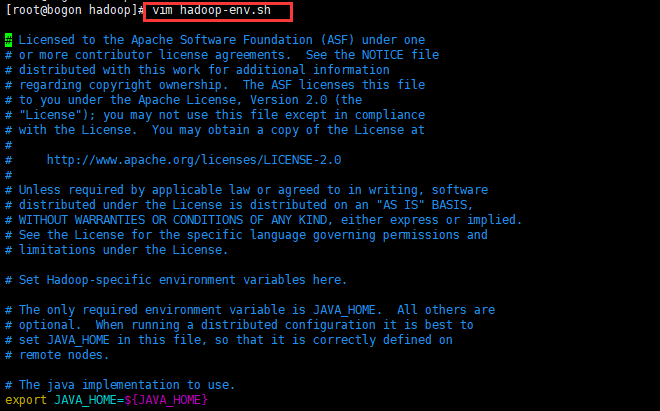
8、配置hadoop-env.sh

编辑hadoop-env.sh
修改JAVA_HOME:export JAVA_HOME指向自己的Java安装目录下的default目录
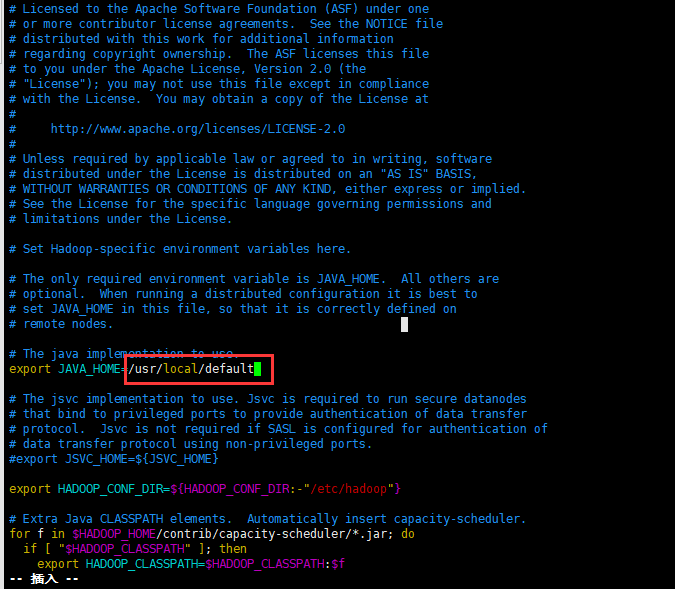
保存退出–:wq
9、将hadoop的执行命令路径加入环境变量:编辑/etc/profile文件
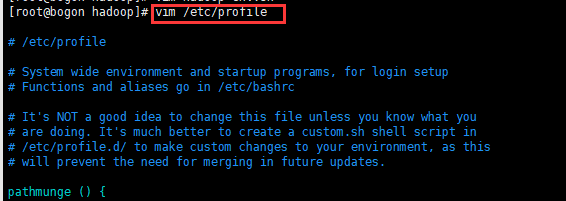
加入Hadoop命令路径
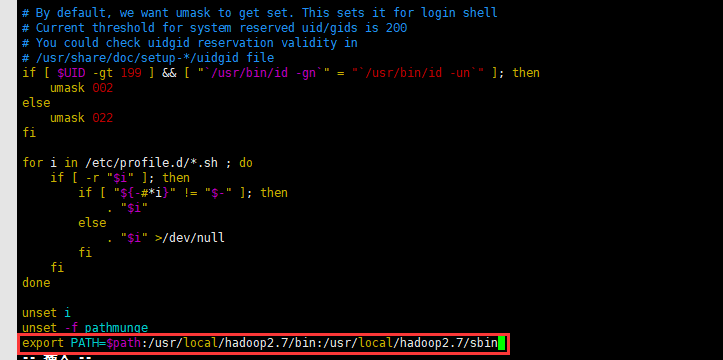
重新加载profile文件
source /etc/profile检验hadoop安装是否正确
输入hadoop
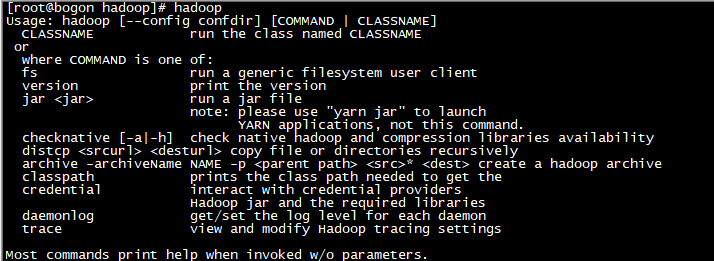
当看到以上输出时,此时hadoop搭建成功
二、搭建Hadoop集群
采用克隆的方式
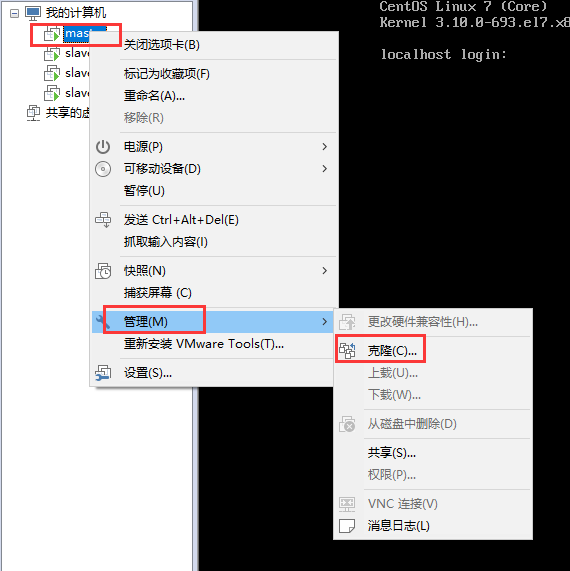
直接下一步
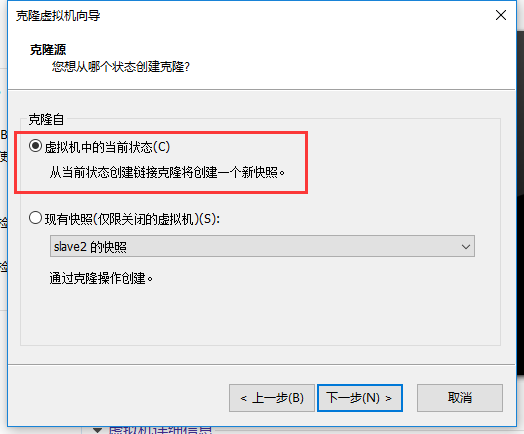
下一步:选择完整克隆
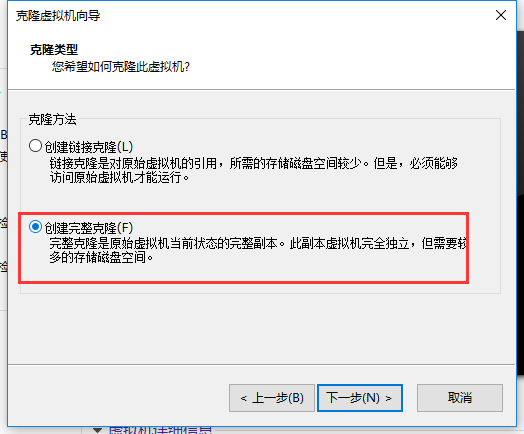
直接下一步,完成。
运用同样的方式克隆三台从机,一次命名位slave1,slave2,slave3,最终的结构如下图
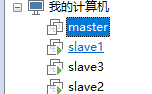
同在xshell中创建所有虚拟机的session连接。
至此,环境搭建完成。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111293.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
