大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
一、爬虫框架Scrapy的整体架构:
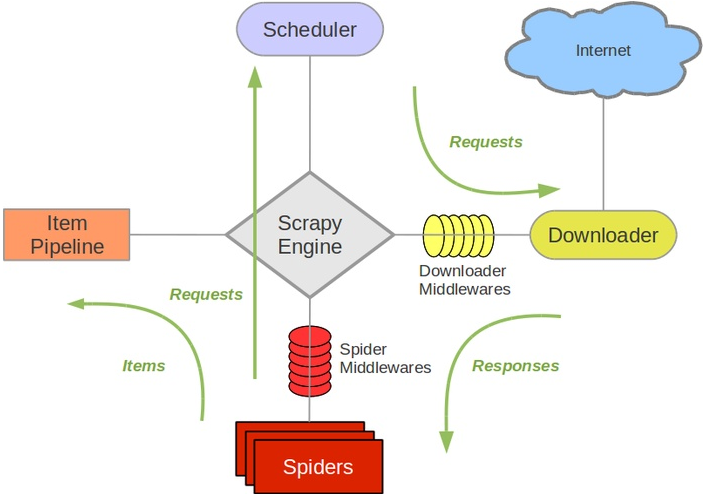

Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯、信号、数据传递等
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
Item Pipeline(管道):负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):可以扩展操作引擎和Spider中间通信的功能组件
二、模块说明:
items:数据传输对象 DTO
middlewares:爬虫中间件,在Scrapy中有两种中间件:下载器中间件(Downloader Middleware)和爬虫中间件(Spider Middleware)
pipelines:存储管道
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
1.验证爬取的数据(检查item包含某些字段,比如说name字段)
2.查重(并丢弃)
3.将爬取结果保存到文件或者数据库中
# 初始化
def __init__(self):
pass
# 处理数据对象
def process_item(self, item, spider):
return item
# 爬虫关闭时调用
def close_spider(self, spider):
self.file.close()settings:scrapy框架的项目设置位置
#它是一种可以用于构建用户代理机器人的名称,默认值:'scrapybot'
BOT_NAME = 'companyNews'
# 它是一种含有蜘蛛其中Scrapy将寻找模块列表,默认值: []
SPIDER_MODULES = ['companyNews.spiders']
# 默认: '',使用 genspider 命令创建新spider的模块。
NEWSPIDER_MODULE = 'companyNews.spiders'
#-----------------------日志文件配置-----------------------------------
# 默认: True,是否启用logging。
# LOG_ENABLED=True
# 默认: 'utf-8',logging使用的编码。
# LOG_ENCODING='utf-8'
# 它是利用它的日志信息可以被格式化的字符串。默认值:'%(asctime)s [%(name)s] %(levelname)s: %(message)s'
# LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
# 它是利用它的日期/时间可以格式化字符串。默认值: '%Y-%m-%d %H:%M:%S'
# LOG_DATEFORMAT='%Y-%m-%d %H:%M:%S'
#日志文件名
#LOG_FILE = "dg.log"
#日志文件级别,默认值:“DEBUG”,log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
LOG_LEVEL = 'WARNING'
# -----------------------------robots协议---------------------------------------------
# Obey robots.txt rules
# robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,
# 本网站哪些目录下的网页 不希望 你进行爬取收录。在Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,
# 然后决定该网站的爬取范围。
# ROBOTSTXT_OBEY = True
# -----------请求相关--------------
# 对于失败的HTTP请求(如超时)进行重试会降低爬取效率,当爬取目标基数很大时,舍弃部分数据不影响大局,提高效率
RETRY_ENABLED = False
#请求下载超时时间,默认180秒
DOWNLOAD_TIMEOUT=20
# 这是响应的下载器下载的最大尺寸,默认值:1073741824 (1024MB)
# DOWNLOAD_MAXSIZE=1073741824
# 它定义为响应下载警告的大小,默认值:33554432 (32MB)
# DOWNLOAD_WARNSIZE=33554432
# ------------------------全局并发数的一些配置:-------------------------------
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 默认 Request 并发数:16
# CONCURRENT_REQUESTS = 32
# 默认 Item 并发数:100
# CONCURRENT_ITEMS = 100
# The download delay setting will honor only one of:
# 默认每个域名的并发数:8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 每个IP的最大并发数:0表示忽略
# CONCURRENT_REQUESTS_PER_IP = 0
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY 会影响 CONCURRENT_REQUESTS,不能使并发显现出来,设置下载延迟
#DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
#禁用cookies,有些站点会从cookies中判断是否为爬虫
# COOKIES_ENABLED = True
# COOKIES_DEBUG = True
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 它定义了在抓取网站所使用的用户代理,默认值:“Scrapy / VERSION“
#USER_AGENT = ' (+http://www.yourdomain.com)'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'companyNews.middlewares.UserAgentmiddleware': 401,
'companyNews.middlewares.ProxyMiddleware':426,
}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'companyNews.middlewares.UserAgentmiddleware': 400,
'companyNews.middlewares.ProxyMiddleware':425,
# 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':423,
# 'companyNews.middlewares.CookieMiddleware': 700,
}
MYEXT_ENABLED=True # 开启扩展
IDLE_NUMBER=12 # 配置空闲持续时间单位为 360个 ,一个时间单位为5s
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# 在 EXTENSIONS 配置,激活扩展
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'companyNews.extensions.RedisSpiderSmartIdleClosedExensions': 500,
}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 注意:自定义pipeline的优先级需高于Redispipeline,因为RedisPipeline不会返回item,
# 所以如果RedisPipeline优先级高于自定义pipeline,那么自定义pipeline无法获取到item
ITEM_PIPELINES = {
#将清除的项目在redis进行处理,# 将RedisPipeline注册到pipeline组件中(这样才能将数据存入Redis)
# 'scrapy_redis.pipelines.RedisPipeline': 400,
'companyNews.pipelines.companyNewsPipeline': 300,# 自定义pipeline视情况选择性注册(可选)
}
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# ----------------scrapy默认已经自带了缓存,配置如下-----------------
# 打开缓存
#HTTPCACHE_ENABLED = True
# 设置缓存过期时间(单位:秒)
#HTTPCACHE_EXPIRATION_SECS = 0
# 缓存路径(默认为:.scrapy/httpcache)
#HTTPCACHE_DIR = 'httpcache'
# 忽略的状态码
#HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPERROR_ALLOWED_CODES = [302, 301]
# 缓存模式(文件缓存)
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#-----------------Scrapy-Redis分布式爬虫相关设置如下--------------------------
# Enables scheduling storing requests queue in redis.
#启用Redis调度存储请求队列,使用Scrapy-Redis的调度器,不再使用scrapy的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
#确保所有的爬虫通过Redis去重,使用Scrapy-Redis的去重组件,不再使用scrapy的去重组件
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 默认请求序列化使用的是pickle 但是我们可以更改为其他类似的。PS:这玩意儿2.X的可以用。3.X的不能用
# SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 使用优先级调度请求队列 (默认使用),
# 使用Scrapy-Redis的从请求集合中取出请求的方式,三种方式择其一即可:
# 分别按(1)请求的优先级/(2)队列FIFO/(先进先出)(3)栈FILO 取出请求(先进后出)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 可选用的其它队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
# Don't cleanup redis queues, allows to pause/resume crawls.
#不清除Redis队列、这样可以暂停/恢复 爬取,
# 允许暂停,redis请求记录不会丢失(重启爬虫不会重头爬取已爬过的页面)
#SCHEDULER_PERSIST = True
#----------------------redis的地址配置-------------------------------------
# Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
# 指定用于连接redis的URL(可选)
# 如果设置此项,则此项优先级高于设置的REDIS_HOST 和 REDIS_PORT
# REDIS_URL = 'redis://root:密码@主机IP:端口'
# REDIS_URL = 'redis://root:123456@192.168.8.30:6379'
REDIS_URL = 'redis://root:%s@%s:%s'%(password_redis,host_redis,port_redis)
# 自定义的redis参数(连接超时之类的)
REDIS_PARAMS={'db': db_redis}
# Specify the host and port to use when connecting to Redis (optional).
# 指定连接到redis时使用的端口和地址(可选)
#REDIS_HOST = '127.0.0.1'
#REDIS_PORT = 6379
#REDIS_PASS = '19980309'
#-----------------------------------------暂时用不到-------------------------------------------------------
# 它定义了将被允许抓取的网址的长度为URL的最大极限,默认值:2083
# URLLENGTH_LIMIT=2083
# 爬取网站最大允许的深度(depth)值,默认值0。如果为0,则没有限制
# DEPTH_LIMIT = 3
# 整数值。用于根据深度调整request优先级。如果为0,则不根据深度进行优先级调整。
# DEPTH_PRIORITY=3
# 最大空闲时间防止分布式爬虫因为等待而关闭
# 这只有当上面设置的队列类是SpiderQueue或SpiderStack时才有效
# 并且当您的蜘蛛首次启动时,也可能会阻止同一时间启动(由于队列为空)
# SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 序列化项目管道作为redis Key存储
# REDIS_ITEMS_KEY = '%(spider)s:items'
# 默认使用ScrapyJSONEncoder进行项目序列化
# You can use any importable path to a callable object.
# REDIS_ITEMS_SERIALIZER = 'json.dumps'
# 自定义redis客户端类
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
# 如果为True,则使用redis的'spop'进行操作。
# 如果需要避免起始网址列表出现重复,这个选项非常有用。开启此选项urls必须通过sadd添加,否则会出现类型错误。
# REDIS_START_URLS_AS_SET = False
# RedisSpider和RedisCrawlSpider默认 start_usls 键
# REDIS_START_URLS_KEY = '%(name)s:start_urls'
# 设置redis使用utf-8之外的编码
# REDIS_ENCODING = 'latin1'
# Disable Telnet Console (enabled by default)
# 它定义是否启用telnetconsole,默认值:True
#TELNETCONSOLE_ENABLED = False
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
# 开始下载时限速并延迟时间
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#高并发请求时最大延迟时间
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
#禁止重定向
#除非您对跟进重定向感兴趣,否则请考虑关闭重定向。 当进行通用爬取时,一般的做法是保存重定向的地址,并在之后的爬取进行解析。
# 这保证了每批爬取的request数目在一定的数量, 否则重定向循环可能会导致爬虫在某个站点耗费过多资源。
# REDIRECT_ENABLED = False三、响应常见属性:
一个Response对象表示的HTTP响应,这通常由下载器提供给到爬虫进行处理
常见属性:
url:代表由当前地址层跳往下一层的地址路由
status:表示响应的HTTP状态的整数。如:200,404等状态码
headers:请求头的字典对象
body:正文
meta:meta参数对应的值必须是一个字典,它的主要作用是用来传递数据的,meta是通过request产生时传进去,通过response对象中取出来
喜欢小编的关注、点赞走一波呦,后期会不定期分享更多Python爬虫相关知识
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234604.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
