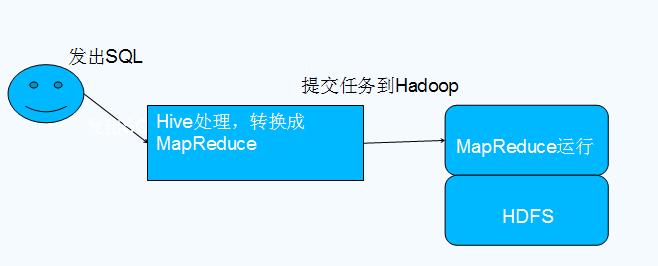
什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 – 本质是将SQL转换为MapReduce程序


Hive的特点
•可扩展Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
•延展性Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
•容错良好的容错性,节点出现问题SQL仍可完成执行
Hive与Hadoop的关系
hive环境搭建:
由于hive是基于Hadoop的。所以首先要保证你的hadoop环境是能够更正常运行的。对于haddop环境的搭建,请参照之前的文章。
1.hive的下载:http://mirror.bit.edu.cn/apache/hive/
2.上传
3.解压 tar -zxvf apache-hive-2.3.2-bin.tar /usr/local/hive
4.配置
① 配置环境变量
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HIVE_HOME/bin


<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
mkdir tmp

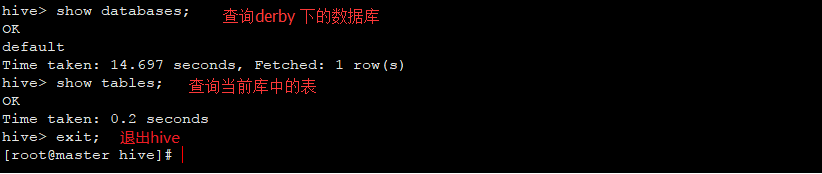

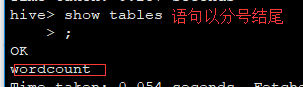
12、使用hive完成wordcount程序的功能:

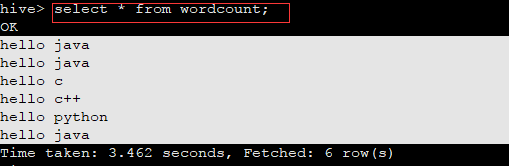
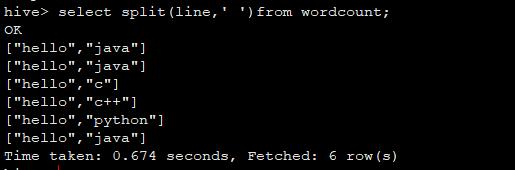
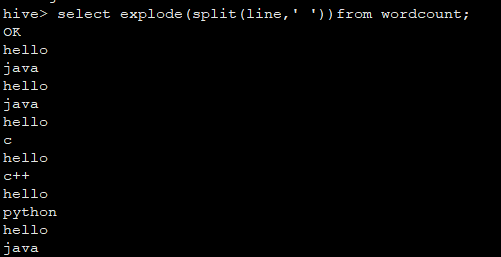
select explode(split(line,' '))from wordcount;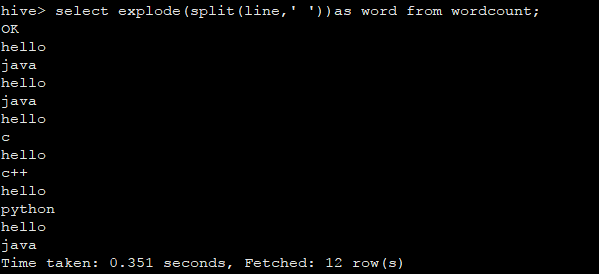
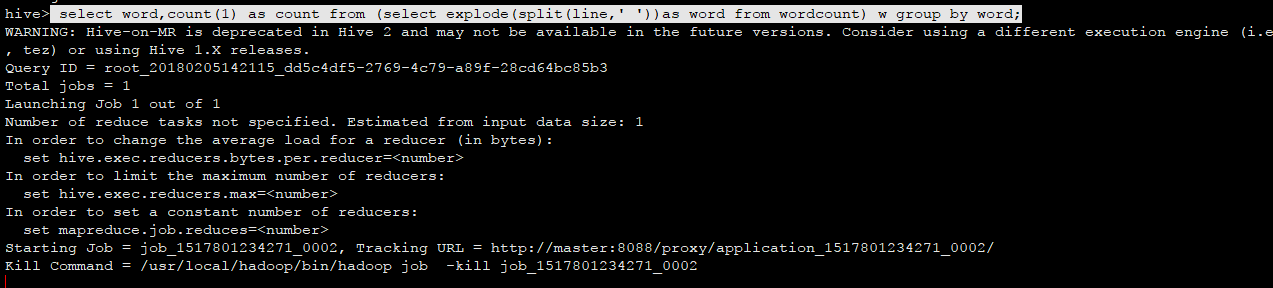

create table sqr(qtime string,qid string,qword string,a string, url string) row format delimited fields terminated by ',';

3 查看表结构
desc sqr; 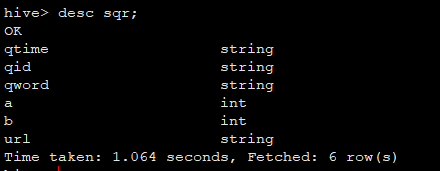
load data inpath '/sogou.dic' into table sqr; 
create table sql_result as select keyword,count(1) as count from (select qword as keyword from sqr) t group by keyword order by count desc;6 查询统计结果
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111285.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
