1、Location的语法规则
语法规则:location [=||*|^~] /uri/ {…}
下面详细解释上面出现的符号
| 符号 | 含义 |
|---|---|
| = | =开头表示精准匹配 |
| ^~ | ^~开头表示url以某个常规字符串开头,可理解为匹配url路径(禁止正则匹配) |
| ~ | ~ 开头表示区分大小写的正则匹配,区分大小写 |
| ~* | ~* 开头表示不区分大小写的正则匹配 |
| !和!* | !和!*分别为区分大小写不匹配及不区分大小写不匹配的正则 |
| / | !和!*分别为区分大小写不匹配及不区分大小写不匹配的正则 |
2、匹配流程图
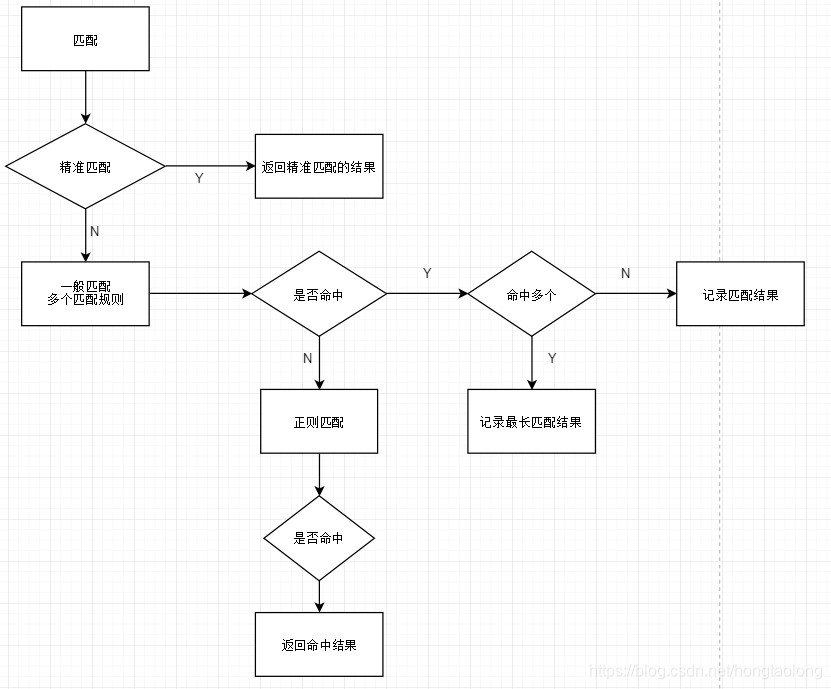

(1)精准匹配命中时,停止 location 动作,直接走精准匹配,
(2)一般匹配(含非正则)命中时,先收集所有的普通匹配,最后对比出最长的那一条
(3)如果最长的那一条普通匹配声明为非正则,直接此条匹配,停止 location
(4)如果最长的那一条普通匹配不是非正则,继续往下走正则 location
(5)按代码顺序执行正则匹配,当第一条正则 location 命中时,停止 location
3、安装echo
这里为了方便测试,使用了第三方的模块echo,方便输出结果,安装步骤如下:
(1)下载echo压缩包
wget https://github.com/openresty/echo-nginx-module/archive/v0.61.tar.gz
(2)解压
tar -zvxf
(3)配置
进入nginx的解压目录,输入如下命令,“=”号后面是echo的解压目录
./configure –add-module=/usr/local/src/echo-nginx-module-0.61/
(4)编译安装
make && make install
(5)验证
进入nginx的sbin目录(也可以配置环境变量,就不用进入sbin目录),输入./nginx -V查看

4、测试验证
server {
listen 10088;
server_name 123.25.95.148;
#精准匹配测试
#第1,2条虽然匹配,但第三条是精准匹配,出第三条结果
#测试路径/equal/a/b/c
location ~ /equal/(.*) {#被命中,但被下面的推断:location = /equal/a/b/c
echo '/equal/*';
}
location /equal/a/b {#被命中,但被下面的推断:location = /equal/a/b/c
echo '/equal/a/b';
}
location = /equal/a/b/c {#被命中,直接执行,不等待
echo '/equal/a/b/c';
}
#普通匹配测试
#第1,2条虽然匹配,第三条匹配更长,出第三条结果
#测试路径/match/a/b/c
location /match/a {#被命中,但不是最长
echo "/match/a";
}
location /match/a/b {#被命中,但不是最长
echo "/match/a/b";
}
location /match/a/b/c {#被命中,且最长
echo "/match/a/b/c";
}
location /match/a/b/c/d {#不命中
echo "/match/a/b/c/d";
}
#正则匹配覆盖普通匹配测试
#会覆盖普通匹配,不会覆盖=和^~
location =/re/a.js {#访问/re/a.js,不会被后面的正则覆盖
echo 'match =';
}
location ^~ /re/a/b {#访问/re/a/b开头的路径,不会被后面的正则覆盖
echo 'math ^~/re/a/b*';
}
location /re/a.htm {#访问/re/a.htm,会被后面的正则覆盖
echo 'match /re/a.htm';
}
location ~ /re/(.*)\.(htm|js|css)$ {#覆盖/re/a.htm路径
echo "cover /re/$1.$2";
}
#正则匹配成功一条后,便不再走其它正则
#最长正则匹配是第三个,但匹配第一个后便不往下走
#测试路径/rex/a/b/c.htm
location ~ /rex/.*\.(htm|js|css)$ {#覆盖/re/a.htm路径
echo "match first";
}
location ~ /rex/a/(.*)\.(htm|js|css)$ {#覆盖/re/a.htm路径
echo "match second";
}
location ~ /rex/a/b/(.*)\.(htm|js|css)$ {#覆盖/re/a.htm路径
echo "match third";
}
}
4、注意
网上有很多下面错误或者不完善的说法
1、正则匹配优先于匹配的一般匹配,其实这种说法是错误的,出现这种说法的原因是因为正则匹配在某些情况是会覆盖一般匹配,针对第二个问题,请详细查看我第2点描述的内容
2、当未使用=(严格匹配)时,如果url的内容刚好与localtion 的url内容完全一致的情况下,不会被正则覆盖,其实这种说法也是错误的,至少我做了实验测试过了。只有使用“=”、或者“^~”才不会使用正则匹配
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111215.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
