大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
11. 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?
1. 什么是Elasticsearch?
Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了具有 HTTP Web 界面和无架构 JSON 文档的分布式,多租户能力的全文搜索引擎。
Elasticsearch 是用 Java 开发的,根据 Apache 许可条款作为开源发布。
2. ES中的倒排索引是什么?
传统的检索方式是通过文章,逐个遍历找到对应关键词的位置。
倒排索引,是通过分词策略,形成了词和文章的映射关系表,也称倒排表,这种词典 + 映射表即为倒排索引。
其中词典中存储词元,倒排表中存储该词元在哪些文中出现的位置。
有了倒排索引,就能实现 O(1) 时间复杂度的效率检索文章了,极大的提高了检索效率。
加分项:
倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
Lucene 从 4+ 版本后开始大量使用的数据结构是 FST。FST 有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2)查询速度快。O(len(str)) 的查询时间复杂度。
3. ES是如何实现master选举的?
前置条件:
1)只有是候选主节点(master:true)的节点才能成为主节点。
2)最小主节点数(min_master_nodes)的目的是防止脑裂。
Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个RPC来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
获取主节点的核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。
选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值 discovery.zen.minimum_master_nodes;
第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
- 补充:
- 这里的 id 为 string 类型。
- master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
4. 如何解决ES集群的脑裂问题
所谓集群脑裂,是指 Elasticsearch 集群中的节点(比如共 20 个),其中的 10 个选了一个 master,另外 10 个选了另一个 master 的情况。
当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data 节点,避免脑裂问题。
5. 详细描述一下ES索引文档的过程?
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
第一步:客户端向集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演协调节点的角色。)
第二步:协调节点接受到请求后,默认使用文档 ID 参与计算(也支持通过 routing),得到该文档属于哪个分片。随后请求会被转到另外的节点。
bash
# 路由算法:根据文档id或路由计算目标的分片id shard = hash(document_id) % (num_of_primary_shards)
第三步:当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 1 秒)写入到F ilesystem Cache,这个从 Momery Buffer 到 Filesystem Cache 的过程就叫做 refresh;
第四步:当然在某些情况下,存在 Memery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
第五步:在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
第六步:flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512 M)时。


- 补充:关于 Lucene 的 Segement
- Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
- 段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
- 对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗 CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
- 为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。(段合并)
6. 详细描述一下ES更新和删除文档的过程?
删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更。
磁盘上的每个段都有一个相应的 .del 文件。当删除请求发送后,文档并没有真的被删除,而是在 .del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在 .del 文件中被标记为删除的文档将不会被写入新段。
在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在 .del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
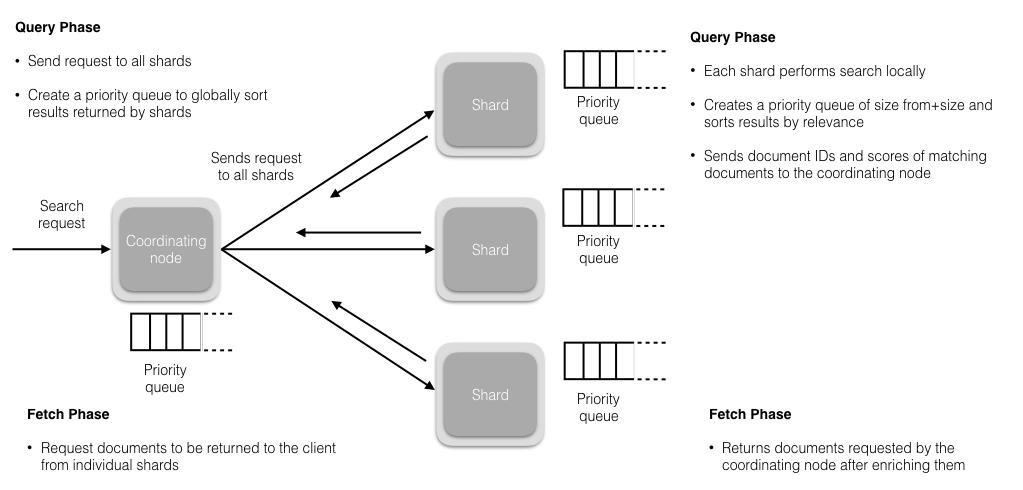
7. 详细描述一下ES搜索的过程?
搜索被执行成一个两阶段过程,即 Query Then Fetch;
Query阶段:
查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
Fetch阶段:
协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
8. 在并发情况下,ES如果保证读写一致?
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
9. ES对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
10. 对于GC方面,在使用ES时要注意什么?
1)倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
2)各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
3)避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
4)cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
5)想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
11. 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?
根据实际情况回答即可,如果是我的话会这么回答:
我司有多个ES集群,下面列举其中一个。该集群有20个节点,根据数据类型和日期分库,每个索引根据数据量分片,比如日均1亿+数据的,控制单索引大小在200GB以内。
下面重点列举一些调优策略,仅是我做过的,不一定全面,如有其它建议或者补充欢迎留言。
部署层面:
1)最好是64GB内存的物理机器,但实际上32GB和16GB机器用的比较多,但绝对不能少于8G,除非数据量特别少,这点需要和客户方面沟通并合理说服对方。
2)多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
3)尽量使用SSD,因为查询和索引性能将会得到显著提升。
4)避免集群跨越大的地理距离,一般一个集群的所有节点位于一个数据中心中。
5)设置堆内存:节点内存/2,不要超过32GB。一般来说设置export ES_HEAP_SIZE=32g环境变量,比直接写-Xmx32g -Xms32g更好一点。
6)关闭缓存swap。内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个100微秒的操作可能变成10毫秒。 再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是多么可怕。
7)增加文件描述符,设置一个很大的值,如65535。Lucene使用了大量的文件,同时,Elasticsearch在节点和HTTP客户端之间进行通信也使用了大量的套接字。所有这一切都需要足够的文件描述符。
8)不要随意修改垃圾回收器(CMS)和各个线程池的大小。
9)通过设置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
索引层面:
1)使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
2)段合并:Elasticsearch默认值是20MB/s,对机械磁盘应该是个不错的设置。如果你用的是SSD,可以考虑提高到100-200MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。另外还可以增加 index.translog.flush_threshold_size 设置,从默认的512MB到更大一些的值,比如1GB,这可以在一次清空触发的时候在事务日志里积累出更大的段。
3)如果你的搜索结果不需要近实时的准确度,考虑把每个索引的index.refresh_interval 改到30s。
4)如果你在做大批量导入,考虑通过设置index.number_of_replicas: 0 关闭副本。
5)需要大量拉取数据的场景,可以采用scan & scroll api来实现,而不是from/size一个大范围。
存储层面:
1)基于数据+时间滚动创建索引,每天递增数据。控制单个索引的量,一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
2)冷热数据分离存储,热数据(比如最近3天或者一周的数据),其余为冷数据。对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率。
比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日
递增 20+,索引:10 分片,每日递增 1 亿+数据,
每个通道每天索引大小控制:150GB 之内。
仅索引层面调优手段:
1.1、设计阶段调优
1、根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索
引;
2、使用别名进行索引管理;
3、每天凌晨定时对索引做 force_merge 操作,以释放空间;
4、采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink
操作,以缩减存储;
5、采取 curator 进行索引的生命周期管理;
6、仅针对需要分词的字段,合理的设置分词器;
7、Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。……..
1.2、写入调优
1、写入前副本数设置为 0;
2、写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
3、写入过程中:采取 bulk 批量写入;
4、写入后恢复副本数和刷新间隔;
5、尽量使用自动生成的 id。
1.3、查询调优
1、禁用 wildcard;
2、禁用批量 terms(成百上千的场景);
3、充分利用倒排索引机制,能 keyword 类型尽量 keyword;
4、数据量大时候,可以先基于时间敲定索引再检索;
5、设置合理的路由机制。
1.4、其他调优
部署调优,业务调优等。
3、elasticsearch 索引数据多了怎么办,如何调优,部署
面试官:想了解大数据量的运维能力。
解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,
这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户
检索或者其他业务受到影响。
如何调优,正如问题 1 所说,这里细化一下:
3.1 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索
引的模板格式为:blog_index_时间戳的形式,每天递增数据。
这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的
32 次幂-1,索引存储达到了 TB+甚至更大。
一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
3.2 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,
节省存储空间和检索效率。
3.3 部署层面
一旦之前没有规划,这里就属于应急策略。
结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注
意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194434.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
