ConfigurationClassPostProcessor是spring框架中非常重要的一个PostProcessor,尤其是现在的项目基本上都是使用springboot和springcloud,那么更加离不开它。我们先来看看它实现了哪些功能
1.@Bean
2.@Import
3.@ComponentScan/@ComponentScans
4.@ImportResource
5.@PropertySource
你没有看错,上述的功能都是基于这个PostProcessor来实现的,如果你还不了解,那么跟我一起来探索吧,在阅读之前,希望对spring的ioc有一定的了解更佳。
一、ConfigurationClassPostProcessor类图
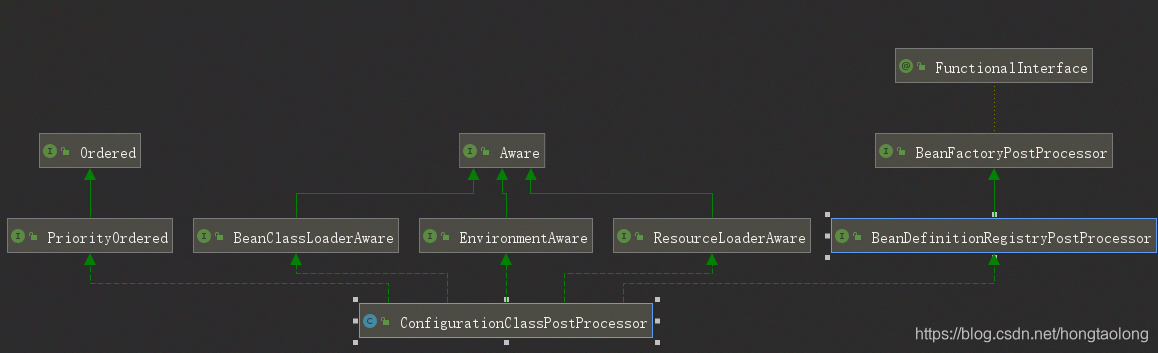

从这个图上面我们可以看到它实现了BeanDefinitionRegistryPostProcessor、PriorityOrdered知道这一点比较重要,后面会提到。
二、流程图
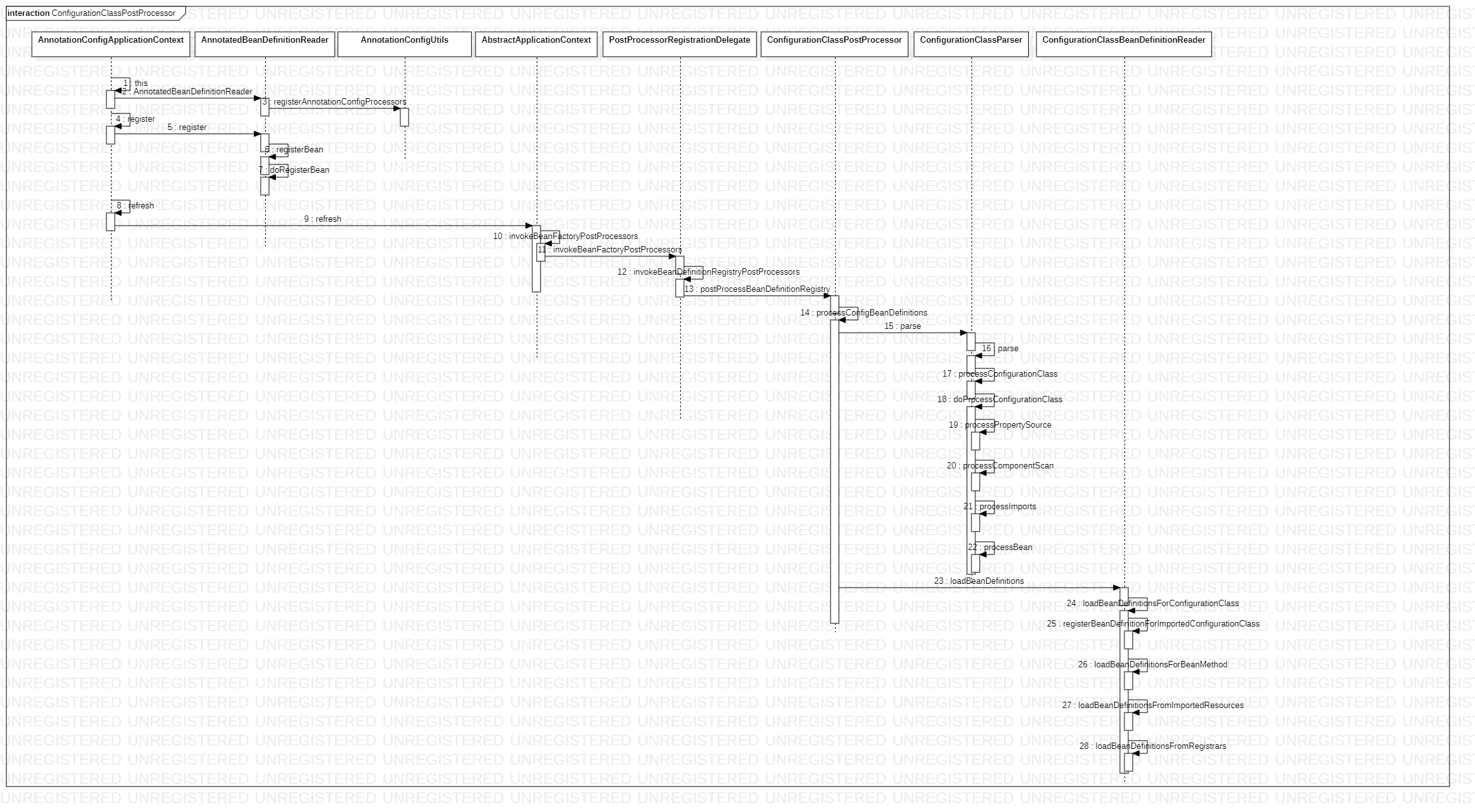
这个流程图的入口是如下代码
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MainConfig.class);
其中MainConfig是配置类,大家可自行编写,感兴趣的可以自己对着这个流程图进行debug分析。下面开始对上述的流程图核心逻辑进行分析。
流程1-7注册PostProcessor、配置类MainConfig,比较不详细讲了,只贴一下关键的代码做解释
1.AnnotationConfigUtils#registerAnnotationConfigProcessors()
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
}
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
//1.这里就是注册ConfigurationClassPostProcessor
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
try {
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
}
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
这里虽然很多,但是非常简单,主要的目的就是将一些需要PostProcessor封装成BeanDefinition,然后注册。我们知道spring实例化bean都是将需要实例化的bean先封装成BeanDefinition。比如我们ConfigurationClassPostProcessor就是在这个地方加入的,还有其他的postProcessor,感兴趣的可以自行研究,这里主要研究ConfigurationClassPostProcessor
2.AnnotatedBeanDefinitionReader#doRegisterBean()
private <T> void doRegisterBean(Class<T> beanClass, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, @Nullable Supplier<T> supplier,
@Nullable BeanDefinitionCustomizer[] customizers) {
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(beanClass);
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(supplier);
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
if (customizers != null) {
for (BeanDefinitionCustomizer customizer : customizers) {
customizer.customize(abd);
}
}
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
这里是从AnnotationConfigApplicationContext#register()方法进来的,主要是注册配置类,比如:new AnnotationConfigApplicationContext(MainConfig.class)我是从这个入口进来的,那么这里就是注册MainConfig,也是先封装成BeanDefinition。到这里我们至少是有两个BeanDefinition(还有其他),一个是MainConfig一个是ConfigurationClassPostProcessor。
我们继续开始spring的核心流程了refresh方法了,这里也是讲主要的流程,大家可以根据上面的流程图自行分析其他流程。接下来我们从refresh()方法中的invokeBeanFactoryPostProcessors()开始,这个方法最终会到PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors
3.PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set<String> processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
//1.ConfigurationClassPostProcessor会在这里实例化
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
//2.实例化之后会调用ConfigurationClassPostProcessor.postProcessBeanDefinitionRegistry
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}
这里算是spring里面重要的思想,spring在实例化bean的时候会有先后顺序,整体的顺序如下
1、先实例化BeanFactoryPostProcessor
2、再实例化BeanPostProcessor
3、最后再实例化普通的bean
其中上述上面每个细节又会根据是否是否实现PriorityOrdered、Ordered等排序,那么spring为什么会这么做呢?个人理解如下:
1、BeanFactoryPostProcessor主要就是再生成bean,所以排最前面
2、BeanPostProcessor主要是bean实例化前后做拦截作用,所以它又比普通的bean早实例化,否则它都没实例化出来怎么去拦截处理其他的类
3、PriorityOrdered、Ordered表示又做了一次先后顺序,比如优先级高的实例化之后,可以拦截优先级更低的bean,所以普通的bean实例化会被所有的BeanPostProcessor拦截处理。
上面的方法的主要主要是先实例化BeanFactoryPostProcessor。因为从上面的ConfigurationClassPostProcessor类图中,我们可以看到它实现了BeanDefinitionRegistryPostProcessor、PriorityOrdered接口。
所以我们看上面代码的注释1和注释2,其他的部分感兴趣自行阅读
注释1:会实例化ConfigurationClassPostProcessor(当然同样实现了BeanDefinitionRegistryPostProcessor、PriorityOrdered接口都会被实例化),实例化的逻辑和普通的对象实例化一样,没什么区别
注释2:会调用BeanDefinitionRegistryPostProcessor#postProcessBeanDefinitionRegistry()代码如下
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
postProcessor.postProcessBeanDefinitionRegistry(registry);
}
}
所以接下来就会进入到ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry这个才是我们今天的主角
4.ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry()
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
int registryId = System.identityHashCode(registry);
//...省略代码
processConfigBeanDefinitions(registry);
}
5.processConfigBeanDefinitions()
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
String[] candidateNames = registry.getBeanDefinitionNames();
//1....省略代码部分代码start
//省略的部分就是找到被@Configuration标注的类,然后加入到configCandidates集合中
//1...省略部分代码end
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
//2.这里是核心逻辑,解析被@Configuration标注的类
parser.parse(candidates);
//...省略代码
//3.生成beanDefinition注册
this.reader.loadBeanDefinitions(configClasses);
//....省略代码
}
上述方法三个核心的逻辑,上面已经写了比较清洗的注释,其中最重要的逻辑就是注释2,这里面包含了@Bean、@ComponentScan、@Import的所有的实现逻辑。以咱们这个例子为例,configCandidates集合中只有MainConfig(其实是BeanDifinition)。接下来我们看parse()
6.ConfigurationClassParser.parse()
protected final void parse(@Nullable String className, String beanName) throws IOException {
Assert.notNull(className, "No bean class name for configuration class bean definition");
MetadataReader reader = this.metadataReaderFactory.getMetadataReader(className);
processConfigurationClass(new ConfigurationClass(reader, beanName), DEFAULT_EXCLUSION_FILTER);
}
上面还省略了一个parse方法,那里面比较简单只有for循环,我就直接略过了,直接到这个parse方法。这里只有几行代码,但是我们注意一下ConfigurationClass,这个类比较重要,一个ConfigClass实例(比如本文MainConfig)对应一个ConfigurationClass实例,最终spring会将@Import、@Bean等信息解析到该类的属性中。我们先看下这个类有哪些属性,让大家现有一个印象
final class ConfigurationClass {
private final AnnotationMetadata metadata;
private final Resource resource;
@Nullable
private String beanName;
private final Set<ConfigurationClass> importedBy = new LinkedHashSet<>(1);
private final Set<BeanMethod> beanMethods = new LinkedHashSet<>();
private final Map<String, Class<? extends BeanDefinitionReader>> importedResources =
new LinkedHashMap<>();
private final Map<ImportBeanDefinitionRegistrar, AnnotationMetadata> importBeanDefinitionRegistrars =
new LinkedHashMap<>();
final Set<String> skippedBeanMethods = new HashSet<>();
//...省略
}
上面几个属性,相信大家一看名字就大概猜到作用是什么了,我们接着往下看
7.ConfigurationClassParser.processConfigurationClass()
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
//...省略代码,主要处理合并、去重、过滤
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
//1.核心逻辑
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
8.doProcessConfigurationClass()
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
上面代码很长,但是spring已经做了英文注释了,这里就是实现了@PropertySource、@ComponentScan、@Import 、@ImportResource、@Bean,下面简单的解析一下
1、@PropertySource:读取文件,然后将值放到environment中
2、@ComponentScan/@ComponentScans:扫面路径,扫描到的如果有特殊注解@Service、@Conponent等就会创建Beandifinition然后注册
3、@Import:分下面几种
(1)实现了ImportSelector,会调用其selectImports,然后递归…,注册
(2)实现了ImportBeanDefinitionRegistrar,反射实例化,然后加入到ConfigClass中
4、@ImportResource:加入到configClass中
5、@Bean:就是解析被@Configuration注释的类(MainConfig)中的@Bean标注的方法,解析出来,然后放到ConfigClass的beanMethods属性中
到这里,就算简单的把配置类的资源都算解析完了。我们回到ConfigurationClassPostProcessor#processConfigBeanDefinitions中,注释2已经解析完了,我们接着看注释3
9.ConfigurationClassPostProcessor.loadBeanDefinitions()
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
这个参数就是去解析后的所有的ConfigurationClass,我们注释2中解析的内容就是封装到这里面的,我们去看看它如何创建BeanDefinition
10.loadBeanDefinitionsForConfigurationClass
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
//1.注册@Import
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
//2.注册@Bean
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
//3.解析ImportResources
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
//4.注册ImportBeanDefinitionRegistrar
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
这几个方法不难,大家可以自行阅读,这里提一下注册@Bean有两点需要注意
(1)bean如果没有名字,会以方法名作为bean的name
(2)通过@Bean注释的方法创建bean,其实是通过factoryMethodName调用的,大家可以去看注释2,和最后创建bean的代码AbstractAutowireCapableBeanFactory#createBeanInstance
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
//...省略
//重点看这里
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
//...省略
// Candidate constructors for autowiring?
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// Preferred constructors for default construction?
ctors = mbd.getPreferredConstructors();
if (ctors != null) {
return autowireConstructor(beanName, mbd, ctors, null);
}
// No special handling: simply use no-arg constructor.
return instantiateBean(beanName, mbd);
}
感兴趣的可以自行研究吧,spring的源码还是非常庞大,需要一点点啃,共勉,加油!!!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111199.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
