序列(两)
以上排序算法都有一个性质:在排序的终于结果中,各元素的次序依赖于它们之间的比較。我们把这类排序算法称为比較排序。
不论什么比較排序的时间复杂度的下界是nlgn。
下面排序算法是用运算而不是比較来确定排序顺序的。因此下界nlgn对它们是不适用的。
键索引计数法(计数排序)
计数排序如果n个输入元素中的每个都是在0到k区间的一个整数,当中k为某个整数。
思想:对每个输入元素x,确定小于x的元素个数。利用这一信息,就能够直接把x放到它在输出数组中的位置了。
比如:
学生被分为若干组,标号为1,、2、3、4等,在某些情况下我们希望将全班同学按组序号排序分类。

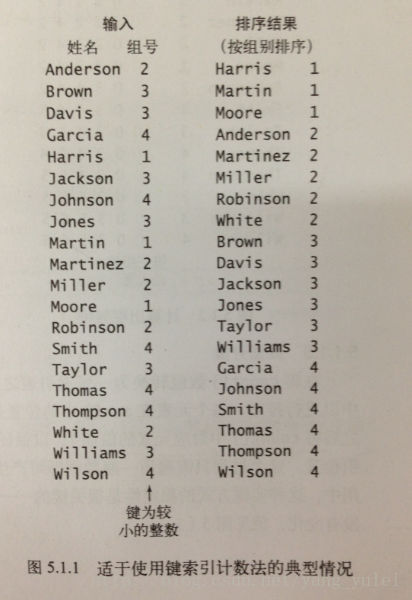
1.频率统计:
第一步就是使用int数组cout[]计算每一个键出现的频率。
对于数组中的每一个元素。都使用它的键訪问count[]中的对应元素并将其加1。(即把键值作为cout[]的索引)假设键值为r。则将count[r+1]加1.(为什么须要加1?稍后解释)
for (i=0; i<N; i++)
count[a[i].key()+1]++ ;
count[0~5]:0 0 3 5 6 6
2.将频率转换为索引:
接下来。我们会使用count[]来计算每一个键在排序结果中的起始索引位置。
在这个演示样例中。由于第一组中有3个人,第二组中有5个人,因此第三组中的同学在排序结果数组中的起始位置为8。
对于每一个键值r,小于r+1的键的频率之和为小于r的键的频率之和加上count[r],因此从左向右将count[]转化为一张用于排序的索引表是非常easy的。
for (int r=0; r<R; r++)
count[r+1] += count[r] ;
count[0~5]:0 0 3 8 14 20
3. 数据分类:
在将count[]数组转换为一张索引表之后,将全部元素(学生)移动到一个辅助数组aux[]中以进行排序。每一个元素在aux[]中的位置是由它的键(组别)相应的count[]值决定的,在移动之后将count[]中相应元素的值加1,以保证count[r]总是下一个键为r的元素在aux[]中的索引位置。这个过程仅仅需遍历一遍数据就可以产生排序结果。
(这样的实现方式的稳定性是非常关键的——键同样的元素在排序后会被聚集到一起,但相对顺序没有变化。)
for (int i=0; i<N; i++)
aux[count[a[i].key()]++] = a[i] ;
4. 回写:
因此我们在将元素移动到辅助数组的过程中完毕了排序。所以最后一步就是将排序的结果复制回原数组中。
for (int i=0; i<N; i++)
a[i] = aux[i] ;
特点:键索引计数法是一种对于小整数键排序很有效却经常被忽略的排序方法。
键索引计数法不须要比較,仅仅要当范围R在N的一个常数因子范围之内,它都是一个线性时间级别的排序方法。
基数排序
有时候,我们须要对长度都同样的字符串进行排序。
这样的情况在排序应用中非经常见——比方电话号码、银行账号、IP地址等都是典型的定长字符串。
将此类字符串排序能够通过低位优先的字符串排序来完毕。假设字符串的长度均为W。那就从右向左以每一个位置的字符作为键,用键索引计数法(或插入排序)将字符串排序W遍。
(为了确保基数排序的正确性,一位数排序算法必须是稳定的。比如:计数排序、插入排序)
特点:基数排序是否比基于比較的排序算法(如高速排序)更好呢?
基数排序的时间复杂度为线性级(n),这一结果看上去要比高速排序的期望执行时间代价(nlgn)更好一些。可是,在这两个表达式中隐含在背后的常数项因子是不同的。
在处理的n个keyword时,虽然基数排序运行的循环轮数会比高速排序要少。但每一轮它所耗费的时间要长得多。且高速排序通常能够比基数排序更有效地使用硬件的缓存。
此外,利用计数排序作为中间稳定排序的基数排序不是原址排序。而非常多nlgn时间的比較排序是原址排序。因此,当主存的容量比較宝贵时,我们可能会更倾向于像高速排序这种原址排序。
桶排序
桶排序(bucket sort)如果输入数据服从均匀分布,其独立分布在[0,M)区间上。平均情况下它的时间代价为O(n)。
思想:桶排序将[0,M)区间划分为n个同样大小的子区间。或称为桶。
然后,将n个输入数分别放到各个桶中。
由于输入数据时均匀、独立地分布在[0,M)区间上,所以一般不会出现非常多数落在同一个桶中的情况。
为了得到输出结果。我们先对每一个桶中的数进行排序,然后遍历每一个桶。依照次序把各个桶中的元素列出来就可以。
(桶平排序算法还须要一个暂时数组B[0..n-1]来存放链表(即桶),并如果存在一种用于维护这些链表的机制)
(有点像哈希表的拉链法的处理方式。)

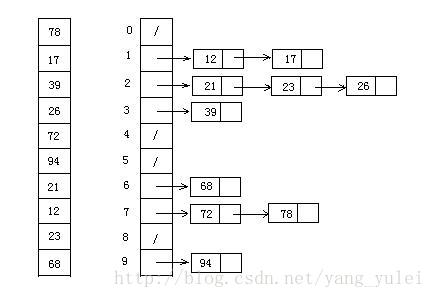
位示图
思想:用比特位的相对位置(索引)来表示一个数值。
即就像用数组的下标来表示一个数值那样。仅仅只是为了节省内存我们用一个bit的位置来标记一个数。
比如:我们能够将集合{1, 2, 3, 5,8, 13}存储在以下这个字符串中:0 1 1 1 0 10 0 1 0 0 0 0 1 0 0 0 0 0 0 集合中代表数字的各个位设置为1,而其它的位所有都设为0。
特点:位示图法适用的问题是(该情况在排序问题中不太常见):
输入的范围相对要小些,而且还不包括反复数据。且没有数据与记录相关联。
【应用举例】
考虑这样一个问题:给一个磁盘文件排序。(详细描写叙述例如以下)
输入:
所输入的是一个文件,至多包括n个不反复的正整数,每一个正整数都要小于n,这里n=10^7. 这些整数没有与之相应的记录相关联。
(即仅对这些整数排序)
输出:
以增序形式输出经过排序的整数列表。
约束:
至多仅仅有1MB的可用主存。可是可用磁盘空间很充足。10秒钟是最适宜的执行时间。
看到磁盘文件排序,我们首先想到经典的多路归并排序。
(后面会讲到)
一个整数为32位,我们能够在1MB空间中存储250000个数。因此,我们将使用一个在输入文件里带有40个通道的程序。在第一个通道中它将249999之间的随意整数读到内存中,并(至多)对250000个整数进行排序,然后将它们写到输出文件里。
第二个通道对250000到499999之间的整数进行排序,依此类推,直到第40个通道,它将排序9750000到9999999之间的整数。在内存中。我们用高速排序,然后把排序的有序序列进行归并,终于得到总体有序。
可是,此方式的效率较低。光是读取输入文件就须要40次,还有外部归并的IO开销。
如何减少IO操作的次数,来提高程序的效率?一次把这一千万个数字所有读入内存?
用位图的方式,我们将使用一个具有一千万个bit位来表示该文件。在该bit位串中,当且仅当整数i在该文件里时,第i位才打开(设为1)。
给定了表示文件里整数集合的位图数据结构后。我们能够将编写该程序的过程分为三个自然阶段。第一个阶段关闭全部的位,将集合初始化为空集。
第二个阶段读取文件里的每一个整数,并打开对应的位,建立该集合。
第三个阶段检查每一个位。假设某个位是1,就写出对应的整数,从而创建已排序的输出文件。
内部排序方法总结
稳定性
假设一个排序算法可以保留数组中反复元素的相对位置则可以被称为是稳定的。
这个性质在很多情况下非常重要。
(比如:
考虑一个须要处理大量含有地理位置和时间戳的事件的互联网商业程序。
首先,我们在事件发生时将它们挨个存储在一个数组中,这样在数组中它们已经是按时间排序好了的。
如今再依照地理位置切分,假设排序算法不是稳定的,排序后的每一个城市的交易可能不会再是依照时间顺序排序的了。
)
算法 是否稳定
选择排序 否
插入排序 是
希尔排序 否
高速排序 否
三向高速排序 否
归并排序 是
堆排序 否
键索引计数 是
基数排序 是
高速排序是最快的通用排序算法。
高速排序之所以快是由于它的内循环中的指令非常少(并且它还能利用缓存,由于它总是顺序地訪问数据),所以它的执行时间的增长数量级为~cNlgN,而这里的c比其它线性对数级别的排序算法的对应常数都要小。
且。在使用三向切分之后,高速排序对于实际应用中可能出现的某些分布的输入变成线性级别的了,而其它的排序算法仍然须要线性对数时间。
假设稳定性非常重要而空间又不是问题,归并排序可能是最好的。
———————————————————————-外部排序———————————————————————
(我们为什么要进行外部排序?为什么不在插入数据时就依照某种数据结构组织,方便查找且有序。这就像静态查找树那样,没什么有用功能)
外部排序基本上由两个相对独立的阶段组成。
首先,按可用内存大小,将外存上含有n个记录的文件分成若干长度为l的子文件,依次读入内存并利用有效的内部排序方法对它们进行排序。并将排序后得到的有序子文件又一次写入外存。通常称这些有序子文件为归并段。
然后。对这些归并段进行逐趟归并,使归并段逐渐由小至大。直到得到整个有序文件为止。
【例】如果有一个含有10000个记录的文件。首先通过10次内部排序得到10个初始归并段R1~R10。当中每一段都含有1000个记录。然后对它们作两两归并。直至得到一个有序文件为止。
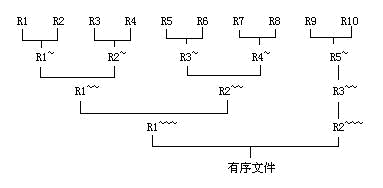
每一趟归并从m个归并段得到m/2个归并段。
这样的归并方法称为2-路平衡归并。
若对上例中所得的10个初始归并段进行5-路平衡归并,则从下图可见,仅需进行二趟归并。外排时总的IO读/写次数显著降低。
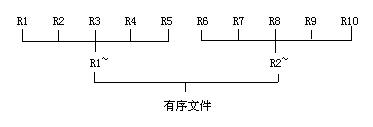
普通情况下,对m个初始归并段进行k-路平衡归并时,归并的趟数s = logkm
可见。若添加k或降低m便能降低s。
一般的归并merge,每得到归并后的有序段中的一个记录,都要进行k-1次比較。显然,为得到含u个记录的归并段需进行(u-1)(k-1)次比較。
内部归并过程中总的比較次数为:
logkm (k-1) (u-1)tmg =( log2m/ log2k)(k-1) (u-1)tmg
所以,要单纯地添加k将导致内部归并的时间,这将抵消因为增大k而降低外存信息读写时间所得效益。
然而,若在进行k-路归并时利用败者树(Tree of Loser),则可使在k个记录中选出keyword最小的记录时仅需进行log2k次比較。
则总的归并时间变为log2m (u-1)tmg此式与k无关。它不再随k的增长而增长。
败者树
它是树形选择排序的一种变型。
每一个非终端结点均表示其左、右孩子结点中的“败者”。
而让胜者去參加更高一层的比赛。便可得到一颗“败者树”(所谓“胜者”就是你想选出来的元素)。
以一颗实现5-路(k=5)归并的败者树为例:
数组ls[0…k-1]表示败者树中的非终端结点。败者树中根结点ls[1]的双亲结点ls[0]为“冠军”,其它结点记录的是其左右子树中的“败者”的索引值。b[0…k-1]是待比較的各路归并序列的首元素。
ls[]中除首元素外,其它元素表示为全然二叉树。
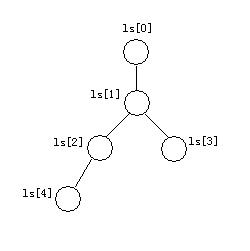
那表示叶子结点的b[]该怎样与之相应?
叶结点b[x]的父结点是ls[(x+k)/2]。
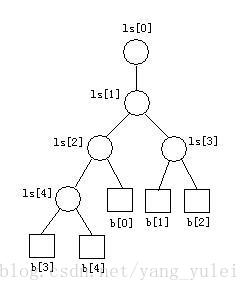
败者树的建立:
1、 初始化败者树:把ls[0..k-1]中全设置为MINKEY(可能的最小值,即“绝对的胜者”)
//我们设一个b[k]= MINKEY。ls[]中记录的是b数组中的索引值。故初始为5.
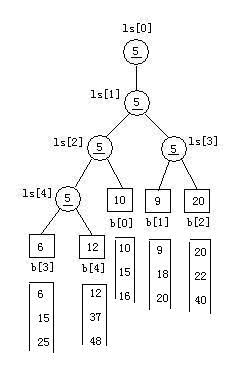
2、从各叶子结点溯流而上,调整败者树中的值。
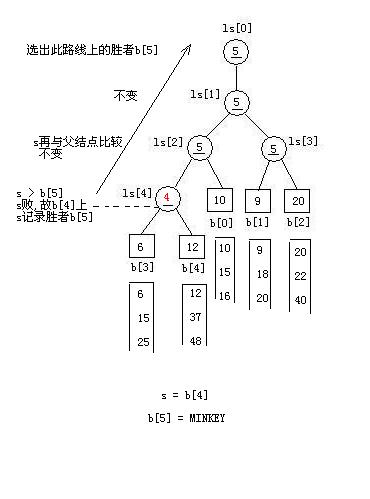
拿胜者s(初始为叶结点值)与其父结点中值比較,谁败(较大的)谁上位(留着父结点中),胜者被记录在s中。(决出胜者,记录败者,胜者向上走)
//对于叶结点b[4]。调整的结果例如以下:
//对于叶结点b[3],调整的结果例如以下
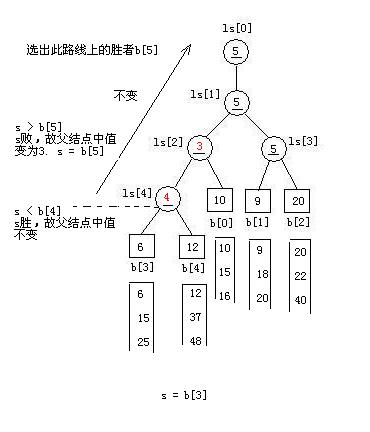
//同理,对于叶结点b[2],调整的结果例如以下
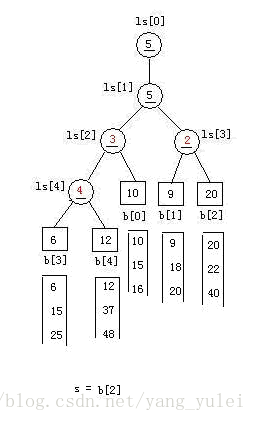
//同理,对于叶结点b[1],调整的结果例如以下
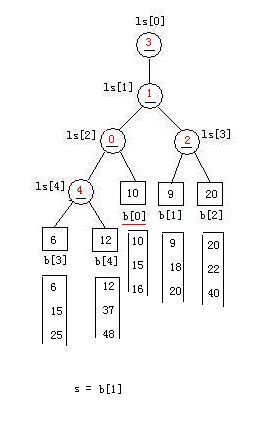
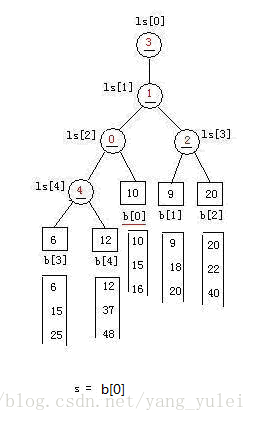
//同理,对于叶结点b[0]。调整的结果例如以下
void CreateLoserTree(LoserTree &ls)
{
b[k].key = MINKEY ;
//设置ls中“败者”的初值
for (i=0; i<k; ++i)
ls[i] = k ;
//依次从b[k-1]...b[0]出发调整败者
for (i=k-1; i>=0; --i)
Adjust(ls, i) ;
}
void Adjust(LoserTree &ls, int m)
{
//沿从叶节点b[m]到根结点ls[0]的路径 调整败者树
for (i = (m + k)/2; i>0; i=i/2) //ls[i]是b[m]的双亲结点
{
if (b[m].key > b[ls[i]].key)
exch(m, ls[i]) ; //m保存新的胜者的索引
}
ls[0] = m ;
}
【后记】
从n个数中选出最小的,我们为什么要用败者树?
首先,我们想到用优先队列。但其应对这样的多路归并的情况。效率并不高。
堆结构:其待处理的元素都在树结点中(在叶节点和非叶子节点中)
败者树:其待处理的元素都在树的叶子结点上,其非叶子结点上记录上次其子结点比較的结果。
这种话,堆结构的某个叶子结点不是相应固定的某个待归并序列。一次选出最值之后,还得取出各归并序列的首元素,重建堆再调整。不能利用之前比較的结果。
而败者树。一个叶结点固定地相应一个归并序列。这样,若其序列的首元素被选出。则序列的下个元素能够直接增补进入结点。然后沿树的路径向上比較。
总结:堆叠结构是适于插入不规则,选择最值。
败者树适用于插入多个序列,选择最值。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/109408.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...