大家好,又见面了,我是全栈君。
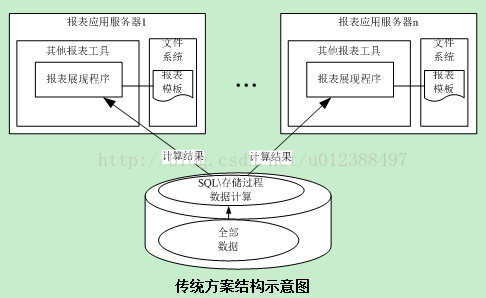
在报表项目中,经常会碰到数据库压力非常大影响整个系统性能的问题。由以下的传统方案的结构示意图能够看出。所有数据存储和源数据计算都放在数据库完毕。当并发訪问量较大的时候,尽管每一个报表的数据量不大,还是会造成数据库压力过大。成为性能的瓶颈。多数数据库厂商提供的jdbc接口数据传输比較缓慢。在并发量较大的情况,对报表系统性能的影响也非常明显。

这样的情况时能够考虑採用润乾集算报表提供的本地计算方案。
所谓本地计算,是将一部分计算任务从数据库中移出到报表server中完毕。
大多数有一定规模的应用系统中。数据库和应用server一般会部署在不同的物理机器上。当中,数据库处于中心地位,要为各个应用系统提供服务。假设运算大部分由数据库完毕,则会导致数据库压力过大。而数据库的扩容成本和难度都相当高。而应用server则不同,不同应用会有不同的应用server硬件,且easy集群扩容。
假设能将一部分运算移出数据库。转而由与应用server一起部署的报表server完毕,则会非常大程度地减小数据库压力,而且充分利用应用server所在机器的计算能力,提升系统性能。
集算报表方案结构示意图例如以下:
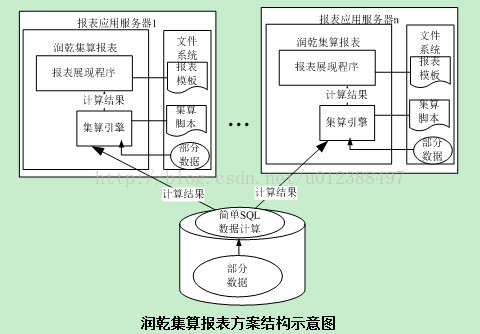
从上图能够看出,润乾集算报表能够将部分数据从数据库转移到报表应用server的本地硬盘。这部分数据能够是计算的中间结果。也能够是部分基础数据。
集算报表内置了集算引擎。能够通过简洁的脚本进行本地化的数据计算。因此。从数据存储和计算双方面都能够减少数据库压力。
部分数据和计算从数据库转移到报表应用server上,能够充分利用应用server集群的存储和计算能力。应用server不管是单机升级(纵向扩展)或者添加集群数量(横向扩展)都要比数据库server的成本低非常多。在本地硬盘上读取数据的速度要比数据库jdbc快非常多,能够解决这个瓶颈问题。
集算引擎还能够进行多线程的并行计算,能够充分发挥应用server多cpu、多核的计算能力。因此。润乾集算报表方案是低成本提高报表应用系统性能的优选方案。
以下,通过“某公司客户累计销售额与去年全年销售额对照报表”的制作。来看一下集算报表是怎样实现本地化计算的。报表例如以下图:
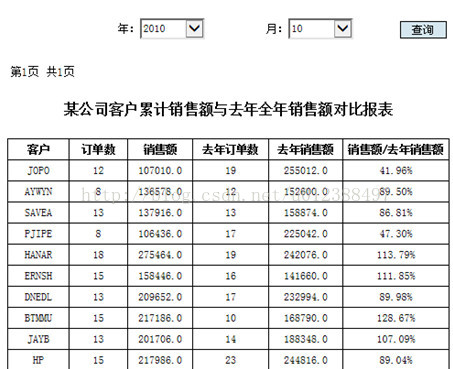
这张报表中的客户、订单数、销售额都是直接从数据库中计算的2010年1月-10月的数据。
2009年全年的订单数、销售额是从报表应用server文件系统中的temp2009sales.b文件里读取。“销售额/去年销售额”则是今年和去年的数据共同计算的。
报表上部的查询button是集算报表提供的“參数模板”功能,详细做法參见教程,这里不再赘述。
首先,要提前用集算器从数据库中读取2009年等各个年份的销售数据,计算好之后。以集算器的二进制编码导出到temp2009sales.b文件里,每年一个文件。中间数据制作好之后,数据库中2009年的数据就能够移除备份了,不再占用数据库的空间。
第二,编写集算器脚本salesProportion.dfx例如以下:
注意,脚本的參数是:argyear(要查询的年份),argmonth(要查询的月份)。
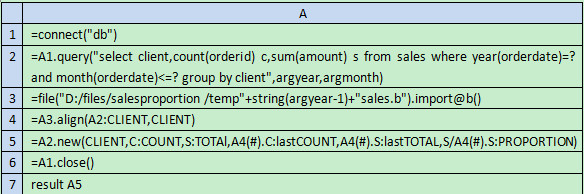
A1:连接预先配置好的数据源demo。
A2:从数据库中计算取出要查询的年份订单数、销售额。
A3:从前一年的数据文件里取出数据。
A4:将A3中的数据依照A2中的CLIENT字段对齐,A2中有A3中没有的补空行。
A5:利用A2来生成新的续表。
当中添加了A4的相应行数据,比方A4(#).C:lastCOUNT就是A4的相应行(#是A2的当前行号)中取出C字段。
A6:关闭数据库连接。
A7:向报表返回结果集。
第三,在集算报表中定义报表參数(argyear、argmonth)和计算数据集:
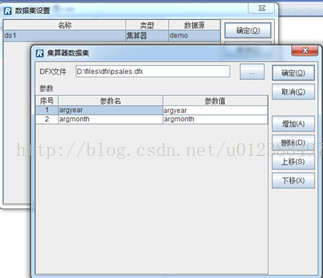
上图中。參数名是指dfx定义的參数名称,參数值是指报表提交给集算引擎的值。
这里是将报表的两个參数的值传递给集算器的同名參数。
第四,设计报表,例如以下图:

输入參数计算后。就可以得到前面希望的报表。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/108394.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
