大家好,又见面了,我是全栈君。
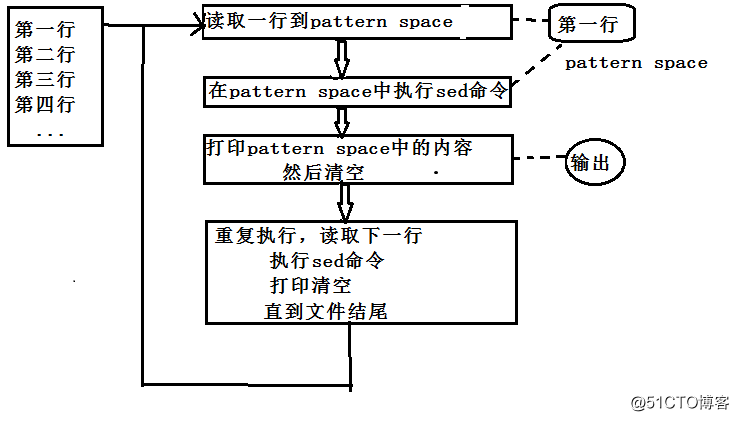
sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。注 :不给地址默认全文处理

常用选项有如下几个
-n:不输出模式空间内容到屏幕,即不自动打印
-f:-f<script文件>或–file=<script文件>:以选项中指定的script文件来处理输入的文本
-r: 支持使用扩展正则表达式
-i.bak: 备份文件并原处编辑 谨慎使用
-e: 多点编辑

参数
文件:指定待处理的文本文件列表。(内容较多,这会就不一 一举例了,常用的我给加了粗体。)
a\ 在当前行下面增加文本。
i\ 在当前行上面插入文本。
c\ 把选定的行替换为新的文本。
d 删除,删除选择的行。
D 删除模板块的第一行。
s 替换指定字符
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区。
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l 列表不能打印字符的清单。
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p 打印模板块的行。
P(大写) 打印模板块的第一行。
q 退出Sed。
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
r file 从file中读行。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
! 取前面匹配结果反面的意思。
= 打印当前行号码。
#把注释扩展到下一个换行符以前。
sed替换标记
g 表示行内全面替换。
p 表示打印替成功的行。
w 表示把行写入一个文件。
x 表示互换模板块中的文本和缓冲区中的文本。
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
\1 子串匹配标记
& 已匹配字符串标记 把前面第一个字符看做一个整体,替换时常用. &对应于之前所匹配到的单词
正则表达式基础
它是一个字符匹配标准,一些命令工具按此标准实现字符匹配,根据命令支持的匹配功能可分为基础正则表达式和扩展正则表达式,常用于支持正则表达式的工具,如sed,grep,awk…
有如下一些常用的匹配元字符:
字符匹配
\ 转义符 后面可以跟其它字符
. 匹配任意单个字符
* 匹配其前面一个字符出现任意次。包括0次
.* 任意长度的任意字符
? 匹配其前面的字符1次或0次
+ 匹配其前面一个字符出现至少一次(在扩展正则表达式中)
\? 匹配其前面的字符0或 1次
\+ 匹配其前面的字符至少1次
\| 或的关系 如C\|cat C或cat \(C\c)at:Cat或cat
\{,n\} 匹配前面的字符之多n次
\{n,\} 匹配前面的字符至少ng次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次 \{2,3\} 2-3位
*分组*
\(\) 如\(root\)\+ 这里root是一个整体来匹配
位置匹配
sed实例
[root@localhost /app]#cp /etc/passwd /app/
[root@localhost /app]#ls
di.sh man oo.txt passwd passwd22 ping.sh tongji.sh ttt.sh
1.全面替换标记g
打印paswdd文件第一行并把“root”全局替换成”ROOT”:

2.打印passwd文件第1行到第5行并在第三行后面追加内容”SIMITE”
第二题讲解一下这个分号;是用来做分隔处理的。;号不是固定代表也可用@或%,它们统一成为“分隔符”,前面处理前面的后面处理后面的。

3.统计centos安装光盘中Package目录下的所有rpm文件的以.分隔倒数第二个字段的重复次数
ls |sed -n ‘s;..(.).rpm$;\1;p’ | sort | uniq -c | sort -nr

总结
sed是流编辑器,可对文本/二进制文件进行:替换/删除/添加操作。
awk是文本分析工具,可对文件进行分析处理,尤其适合对文本文件进行数据提取、数据统计、数据比对等等分析处理操作。对大数据量的文件数据比对尤其令人印象深刻:几百万行的数据对比只要几分钟就能出结果,性能极好。
而grep是字符串以行查找工具
它们都支持“正则表达式”
转载于:https://blog.51cto.com/11566825/2068722
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107718.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
