大家好,又见面了,我是你们的朋友全栈君。


前言
系统搭建初期,为对公司业务进行快速支持,往往搭建的系统非常加单,主要为了满足快速迭代的需求,使用公司初期的高速发展。 随着业务的越来越繁杂,系统会变得越来越复杂,除了需要在技术角度去满足系统的高性能,稳定性,高可用等需求外,设计可以满足业务需求迭代的架构同样重要。
常见痛点
为快速支撑复杂业务能力,系统代码往往采用类中写几千行代码,一个方法中到处if-else,如果再没有阅读性好的代码和注释,随着员工离职,接手的程序员很难快速介入代码进行开发,反过来则限制了系统业务能力的快速迭代。 最坏的结果可能造成因为越来越难以迭代,使得系统推翻重做。
通用业务系统实现
系统初期往往采用三层架构方式搭建,上层为controller,中间层为service,下层的数据访问为dao层。
Controller
Controller层往往推荐只作请求参数和响应参数的处理等一些浅逻辑,比如协议转换等。
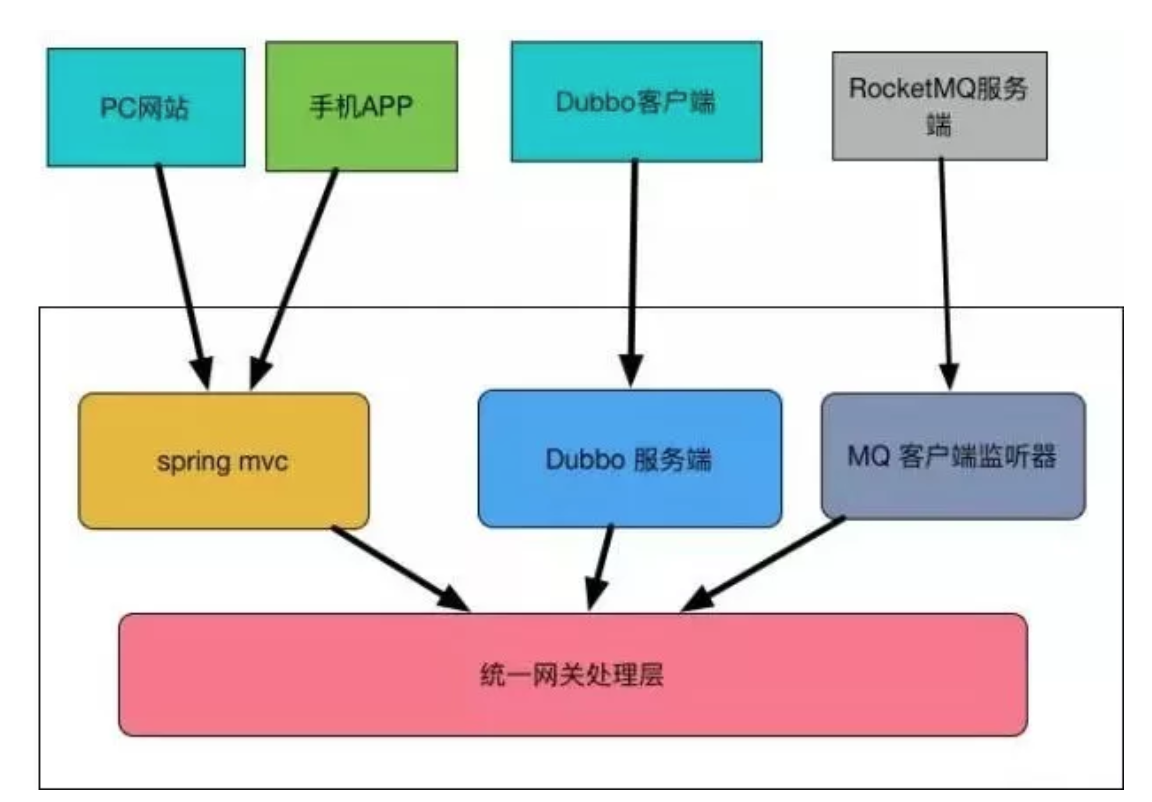

业务代码中,往往按照业务领域划分和组织代码结构,比如按照订单,会员等划分,这样同样可以在Controller层做好请求到领域内的映射。
比如:
- 将请求参数解析出来组装成内部参数
- 调用下层服务执行业务逻辑
- 组装返回响应结果,异常情况下,则对异常堆栈封装等
主要的原则是:网关内对协议进行处理,将业务逻辑进行收敛,不暴漏给外部,这样在内部逻辑进行重构时,不需要外界感知变化。
Service
业务层是承载业务流程和业务规则的地方,同样可以采用分层方式进行代码逻辑组织:
- 1.业务服务层
- 2.业务流程层
- 3.业务组件层
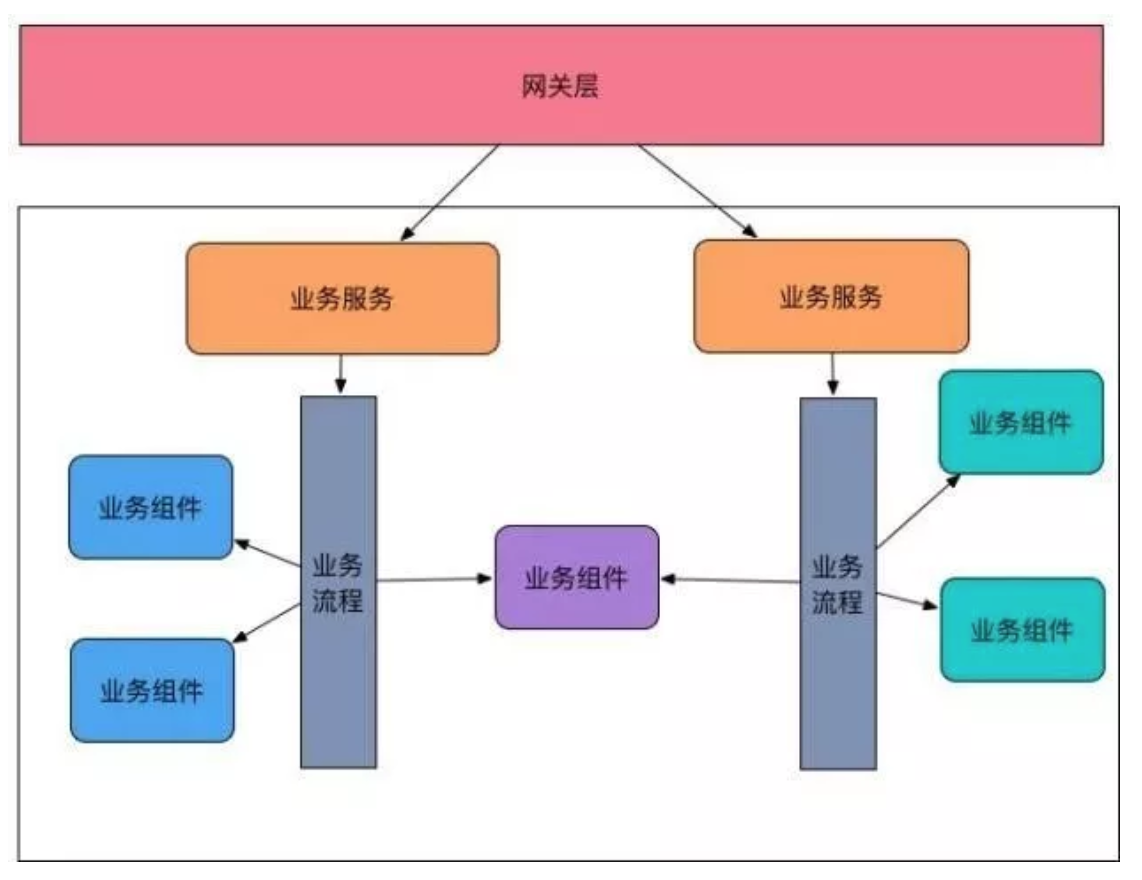
业务服务层
业务服务层可以作为按业务领域划分的领域对外的接口,每个接口代表一个领域业务,比如订单领域内逻辑统一放在Order Service,账户领域交给User Service。
在接口指责划分上,可以采用读写接口分离的原则,比如:Order Read Service和Order Write Service,这样在未来系统在技术角度需要做读写分离处理和流量管理时,可以减少极大的梳理成本。
接口中功能方法的名称尽量有意义,比如订单创建叫做cereate Order,取消订单叫做 cancel Order,而不是简单的增删改查名称。
参数组织上如:Request,DO,DTO等。
业务流程层
业务流程代表对于规则的解释和梳理,规则是将PM的需求翻译成代码的过程,所以同样可以通过多种标准化动作进行控制:
- 组装参数
- 规则判断分支
- 执行动作节点,每个动作节点包含业务功能代码
主要原则是将容易变动的地方做到易修改,易测试,减少新功能迭代时的理解成本。 将不易变动的功能进行拆分,固化,变成可维护的业务组件。
业务组件层
业务组件层是将一些可服用的逻辑,可固化的功能进行内聚封装,可以有参数组件,规则判断组件,动作行为组件等。
业务组件的形成往往是在对业务理解深刻之后演进出来的,过早的抽象往往效果不好。
组件内聚之后可能产生如:短信组件,下单组件扽。
多种组件可以组合产生业务流程的能力。
Dao
数据访问层同样可以由两部分组成:接口定义,技术组件。
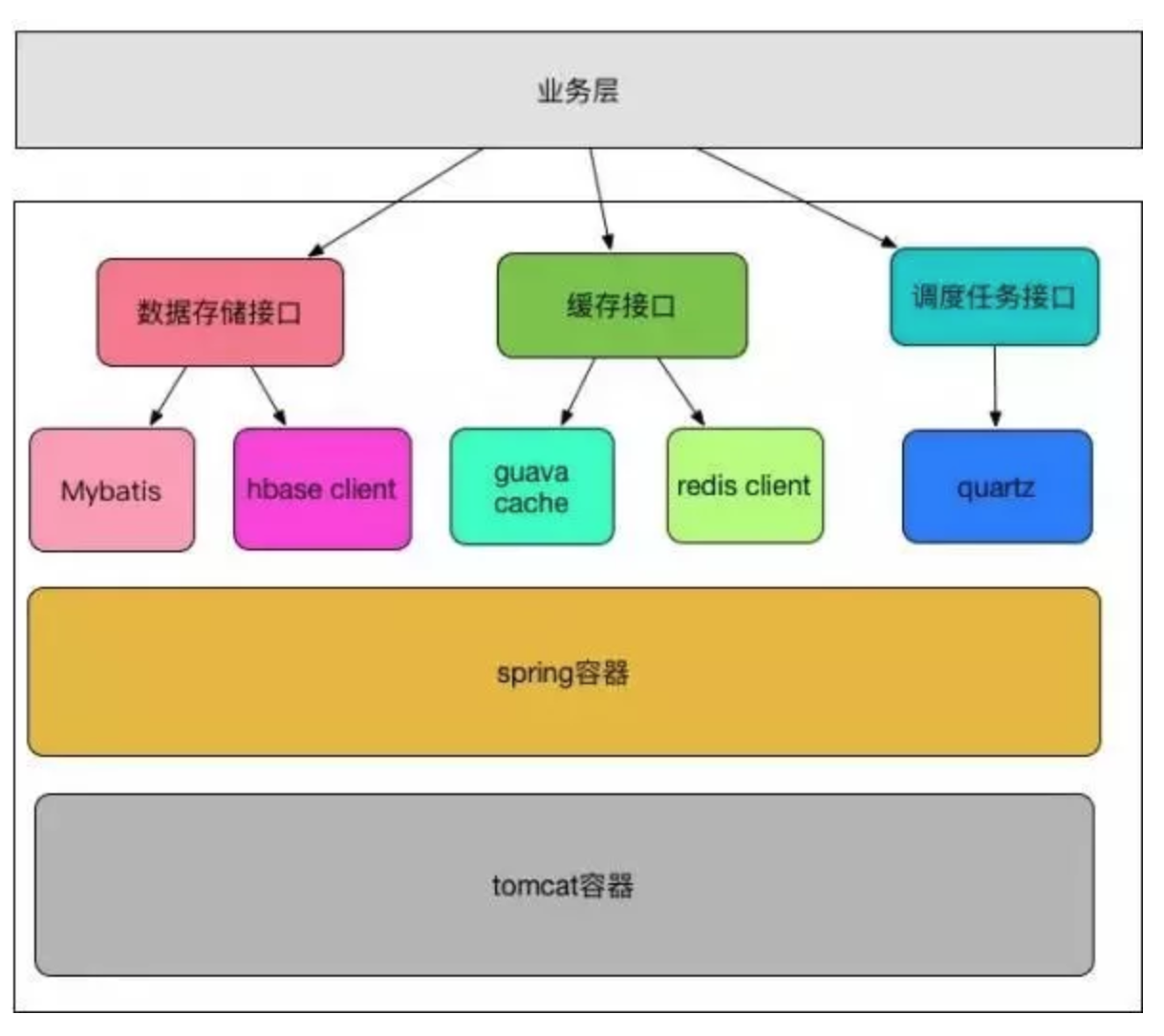
接口定义
底层数据能力需要和上层业务能力分离,通过设计合理的接口,向业务层屏蔽底层复杂度。 可以基于面向接口编程的思想设计数据库访问接口和缓存访问接口等。
技术组件
系统随着业务发展和需要承载的用户越来越多,需要经历单机,集群,服务化等多个阶段,所以需要沉淀下来一些技术组件,来将多个阶段问题进行固化封装,达到系统发展而业务无需感知的能力。 可以沉淀的技术组件包括:数据存储,缓存,消息,调度任务,事务,锁机制等。
数据存储,底层可以封装访问关系数据库,日志系统HBase,文件系统HDFS,本地文件系统等。
缓存,可以按照不同的超时时间纬度或数据量进行选择,比如本地内存的Encache,集中式缓存Memcache,集中式可持久化的Redis集群等,同时可以将缓存击穿处理等逻辑进行集成。
消息,在系统中常常用来解决异步处理能力,消息的消费往往和调度任务组合起来,可以按照调度规则,配置一次或者多次业务逻辑的处理。
事务,往往采用数据库实现,单机的事务依赖于数据库事务,可以使用spring-tx的事务进行事务控制,业务逻辑中,事务应该尽量小,可以将业务逻辑紧密的数据库操作放在一起。在分布式场景下可以根据不同的业务需求选择不同的分布式事务处理机制。
锁,主要有两种:乐观锁和悲观锁。
- 乐观锁:往往采用数据库加版本字段实现,粒度较小;
- 悲观锁:可以采用基于JDK的Lock实现,粒度较粗;
- 分布式场景下可以基于Redis集群和Zookeeper实现;
总结
通过以上方式我们可以提炼出针对于业务系统所需要具备的通用能力,在一定程度上满足了业务系统规则易变的特点,当然不同业务场景有自己的要求,很难有银弹,还需要根据自己的业务场景进行提炼和补充。
转载于:https://my.oschina.net/u/1000241/blog/3014150
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106981.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...